






Dans le contexte actuel axé sur les données, la capacité à créer une plateforme d'analyse évolutive et efficace plateforme pas seulement avantageuse, elle est essentielle. Chez SnapLogic, avec un volume massif de données générées par des milliards d'exécutions de pipelines chaque mois, nous avons été confrontés à ce défi. Le besoin allait au-delà de la simple visualisation ; nous avions besoin d'analyses approfondies et d'informations exploitables. Cet article de blog se penche sur notre approche innovante, qui s'appuie sur l'architecture Medallion, pour concevoir et mettre en œuvre une plateforme d'analyse évolutive plateforme permet aux utilisateurs d'extraire des informations précieuses et de prendre des décisions éclairées.
Problématique
Les analyses de données précédentes de SnapLogic, principalement sur MongoDB, avaient du mal à traiter les données massives provenant de milliards d'exécutions mensuelles de pipelines, ce qui entraînait des problèmes d'évolutivité et de coût. Les limites de MongoDB entravaient les requêtes analytiques complexes, la transformation des données, la gouvernance et la modélisation efficace des données. Ces défis ont nécessité le passage à une solution plus évolutive et plus rentable, telle que l'architecture Medallion avec S3 et Trino, afin de gérer le volume et la complexité croissants des données pour améliorer les analyses et la prise de décision.
L'architecture
Notre architecture intègre l'approche médaillon avec une combinaison de technologies visant à améliorer le traitement et l'analyse des données.
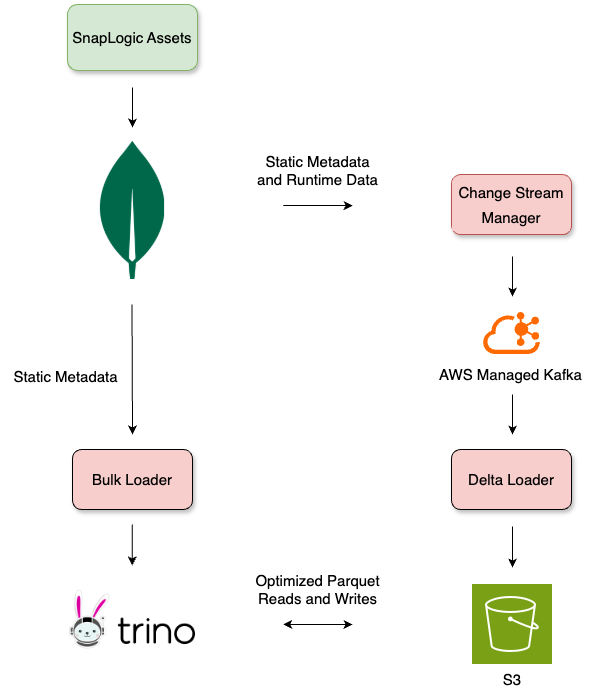
Sources de données et ingestion
MongoDB est notre principale source de données, et nous utilisons deux méthodes pour extraire les données, que nous stockons dans S3 au format Parquet. Le chargement en masse consiste à capturer un instantané de MongoDB à un moment donné et à l'ingérer dans la couche bronze de l'architecture Medallion à l'aide de Trino. SnapLogic prend en charge plus de 1 000 organisations et traite environ 64 millions de mises à jour de données en temps réel chaque jour via MongoDB Change Streams. Afin de garantir un débit élevé et une tolérance aux pannes, ces flux de modifications sont traités par des chargeurs delta et transmis via Apache Kafka (MSK). Les données extraites sont partitionnées et stockées dans S3 pour un stockage rentable et évolutif, puis accessibles à l'aide de Trino.
Architecture médaillon / Transformations
L'architecture Medallion est un modèle de conception de données qui organise les données de manière logique afin d'améliorer progressivement leur structure et leur qualité. L'architecture organise les données en différentes couches (Bronze, Argent, Or) afin de répondre aux besoins des différentes parties prenantes. Les architectures Medallion sont parfois également appelées architectures multi-sauts. Elles offrent une vue complète et bien gérée des données, depuis l'ingestion des données brutes jusqu'aux formats prêts à l'emploi pour l'analyse et le reporting.
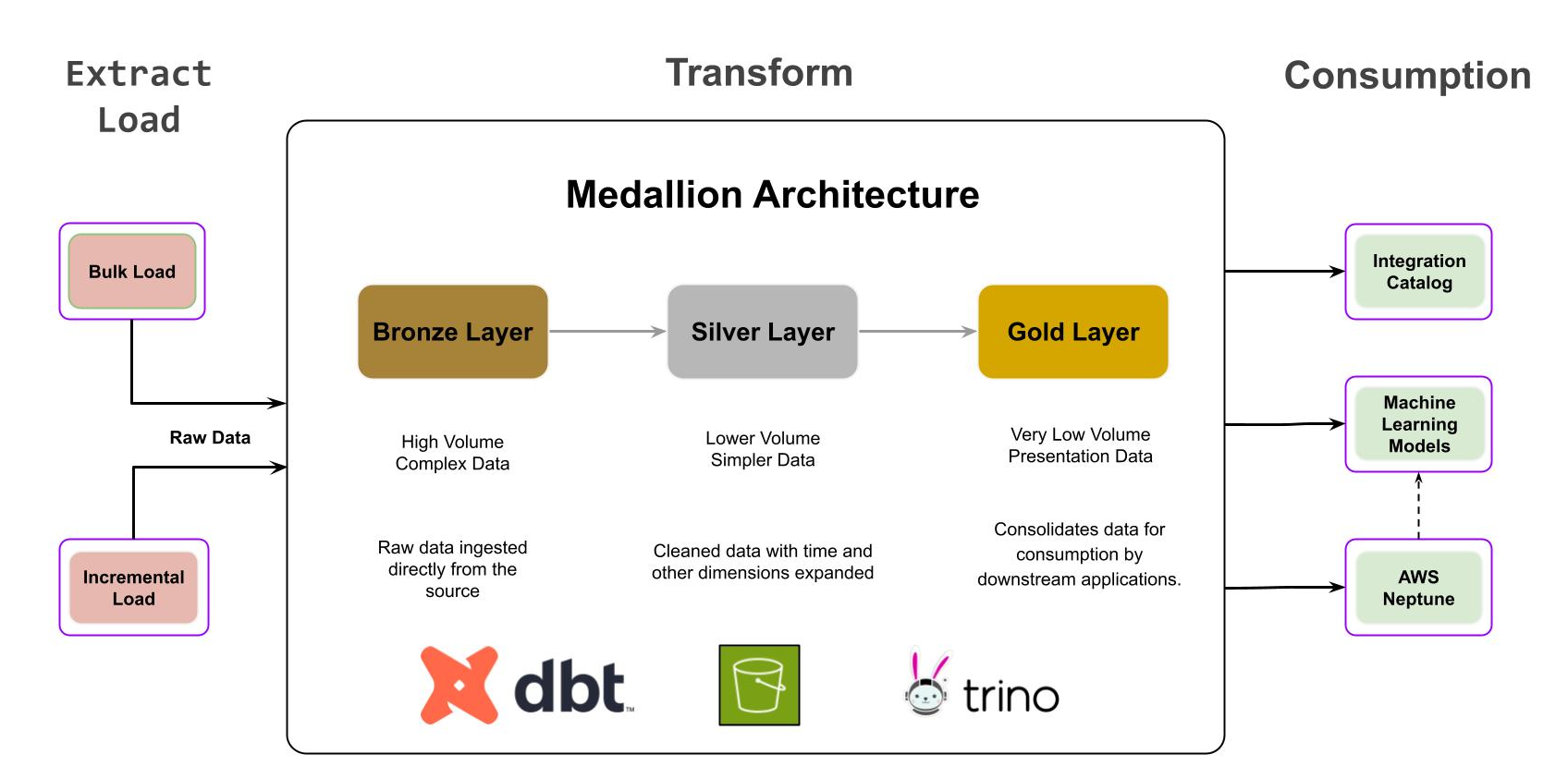
Les données d'exécution générées par les exécutions de pipelines et les flux de modification des métadonnées statiques sont analysées à l'aide de Trino, un moteur de requêtes SQL distribué qui interroge efficacement les données stockées dans S3. Nous avons optimisé le schéma de données dans S3 pour permettre une interrogation efficace par Trino, en tenant compte de facteurs tels que le partitionnement et la compression des données.
Pour mettre en œuvre l'approche basée sur les médailles pour les transformations, nous utilisons des pipelines SnapLogic basés sur DBT qui représentent différentes couches. Ces pipelines s'exécutent sur des complexes DBT Ground personnalisés afin de transformer et d'affiner les données, garantissant ainsi leur qualité et les préparant pour leur utilisation par des applications en aval telles que le catalogue d'actifs et les graphes de connaissances afin d'enrichir nos modèles ML en aval.
L'architecture Medallion comprend plusieurs couches distinctes, chacune ayant des fonctions spécifiques. La couche Bronze ingère les données provenant de S3 et les transfère vers la couche Silver, où elles sont nettoyées et affinées par normalisation. Ensuite, la couche Gold consolide les données à l'aide de jointures effectuées sur la couche Silver, les rendant ainsi facilement accessibles pour être utilisées par les applications en aval.
Consommation
La couche or, qui sert de couche de présentation, contient des données factuelles, opérationnelles et déduites utilisées par deux systèmes principaux.
Le catalogue d'actifs sert de système d'enregistrement central (SoR) pour tous les pipelines SnapLogic, permettant la découverte, la compréhension et la gouvernance des actifs d'intégration grâce à des métadonnées exposées (attributs factuels, déduits et complétés concernant les tâches, les pipelines et les comptes).
Les données contenues dans les tables de la couche Gold sont synchronisées avec un modèle de données basé sur un graphe dans Amazon Neptune. Ce modèle basé sur un graphe représente les interrelations entre les actifs, notamment les pipelines, les comptes, les instantanés et les fichiers. Chaque type d'actif est représenté par des nœuds, et les arêtes symbolisent les dépendances et les relations.
Considérations clés lors de la mise en œuvre
- Frais généraux liés à l'extraction des données
L'extraction initiale des données et la capture continue des données modifiées nécessitent une planification et une optimisation minutieuses.
de cohérence des données Il est essentiel de maintenir la cohérence des données entre MongoDB et la nouvelle architecture.
de la complexité architecturale La gestion d'une architecture à composants multiples nécessite une expertise et une maintenance continue.
Avantages de la nouvelle architecture
- Réduction des coûts : le data lakehouse S3 minimise les dépenses liées au stockage et aux requêtes, les coûts étant principalement liés à l'infrastructure Trino.
- Évolutivité et performances : l'architecture Medallion avec S3 et Trino permet un traitement et une analyse efficaces de grands ensembles de données, surpassant les analyses précédentes basées sur MongoDB.
- Gestion rationalisée des données : l'architecture Medallion améliore l'organisation des données grâce à des couches définies (Bronze, Argent, Or) pour une résilience, une réutilisabilité et des performances optimisées pour des cas d'utilisation spécifiques.
- Amélioration des informations sur les données : le modèle graphique de Neptune permet une analyse complexe des relations, améliorant ainsi l'évaluation de l'impact et le suivi de la traçabilité. Les schémas S3 optimisés pour Trino augmentent encore la vitesse des requêtes.
- Amélioration de la gouvernance des données et de la conformité : l'approche par couches offre une visibilité claire sur la traçabilité des données, facilitant ainsi les efforts en matière de gouvernance et de conformité.
- Réutilisation accrue des données et accélération du développement : les couches Silver et Gold bien modélisées peuvent être réutilisées dans différents projets, ce qui réduit la redondance et accélère la création d'entités commerciales.
Conclusion
En résumé, nous avons mis en place une plateforme d'analyse robuste et évolutive plateforme l'architecture Medallion, passant d'une analyse centrée sur MongoDB à une approche plus efficace, plus rentable et axée sur les données utilisant S3 et Trino. Cette architecture a amélioré la gestion des données, optimisé les performances, permis une modélisation plus approfondie des données et renforcé la gouvernance des données. À l'avenir, nous souhaitons automatiser davantage les pipelines de transformation et intégrer davantage de modèles d'apprentissage automatique dans nos couches de traitement des données afin de favoriser l'analyse prédictive. De plus, nous explorons des améliorations du traitement des données en temps réel et élargissons les capacités de notre lac de données afin de prendre en charge un éventail plus large de sources de données et de charges de travail analytiques, garantissant ainsi que notre plateforme à la pointe de l'innovation en matière de données.








