






In der heutigen datengesteuerten Landschaft ist die Fähigkeit, eine skalierbare und effiziente Analyseplattform aufzubauen, nicht nur vorteilhaft, sondern unverzichtbar. Bei SnapLogic, wo jeden Monat Milliarden von Pipeline-Ausführungen riesige Datenmengen generieren, sind wir direkt mit dieser Herausforderung konfrontiert worden. Der Bedarf ging über die reine Visualisierung hinaus: Wir benötigten tiefgreifende Analysen und umsetzbare Erkenntnisse. In diesem Blogbeitrag gehen wir näher auf unseren innovativen Ansatz ein, bei dem wir die Medallion-Architektur nutzen, um eine skalierbare Analyseplattform zu entwerfen und zu implementieren, die es Benutzern ermöglicht, wertvolle Erkenntnisse zu gewinnen und fundierte Entscheidungen zu treffen.
Problemstellung
Die bisherige Datenanalyse von SnapLogic, die hauptsächlich auf MongoDB basierte, hatte mit den riesigen Datenmengen aus Milliarden von monatlichen Pipeline-Ausführungen zu kämpfen, was zu Skalierbarkeits- und Kostenproblemen führte. Die Einschränkungen von MongoDB behinderten komplexe analytische Abfragen, Datentransformation, Governance und effiziente Datenmodellierung. Diese Herausforderungen erforderten einen Wechsel zu einer skalierbareren und kostengünstigeren Lösung wie der Medallion-Architektur mit S3 und Trino, um das wachsende Datenvolumen und die zunehmende Komplexität zu bewältigen und so bessere analytische Erkenntnisse und Entscheidungsfindungen zu ermöglichen.
Die Architektur
Unsere Architektur umfasst den Medaillon-Ansatz in Kombination mit verschiedenen Technologien zur Verbesserung der Datenverarbeitung und -analyse.
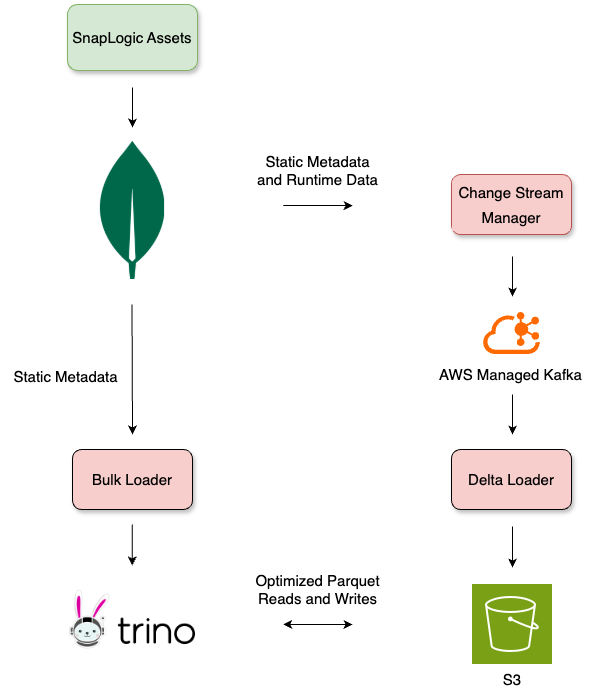
Datenquellen und -erfassung
MongoDB dient als unsere primäre Datenquelle, und wir verwenden zwei Methoden zur Datenextraktion, wobei die Daten im Parquet-Format in S3 gespeichert werden. Beim Bulk Loading wird zu einem bestimmten Zeitpunkt ein Snapshot von MongoDB erfasst und mit Trino in die Bronze-Schicht der Medallion-Architektur übernommen. SnapLogic unterstützt über 1000 Organisationen und verarbeitet täglich rund 64 Millionen Echtzeit-Datenaktualisierungen über MongoDB Change Streams. Um einen hohen Durchsatz und eine hohe Fehlertoleranz zu gewährleisten, werden diese Change Streams von Delta-Loadern verarbeitet und über Apache Kafka (MSK) übertragen. Die extrahierten Daten werden partitioniert und in S3 gespeichert, um eine kostengünstige und skalierbare Speicherung zu gewährleisten, und anschließend mit Trino abgerufen.
Medaillonarchitektur / Transformationen
Die Medaillon-Architektur ist ein Daten-Designmuster, das Daten logisch organisiert, um ihre Struktur und Qualität schrittweise zu verbessern. Die Architektur organisiert Daten in verschiedene Ebenen (Bronze, Silber, Gold), um den Anforderungen verschiedener Interessengruppen gerecht zu werden. Medaillon-Architekturen werden manchmal auch als Multi-Hop-Architekturen bezeichnet. Dies bietet einen gut kontrollierten, umfassenden Überblick über die Daten, von der Rohdatenerfassung bis hin zu verbrauchsfähigen Formaten für Analysen und Berichte.
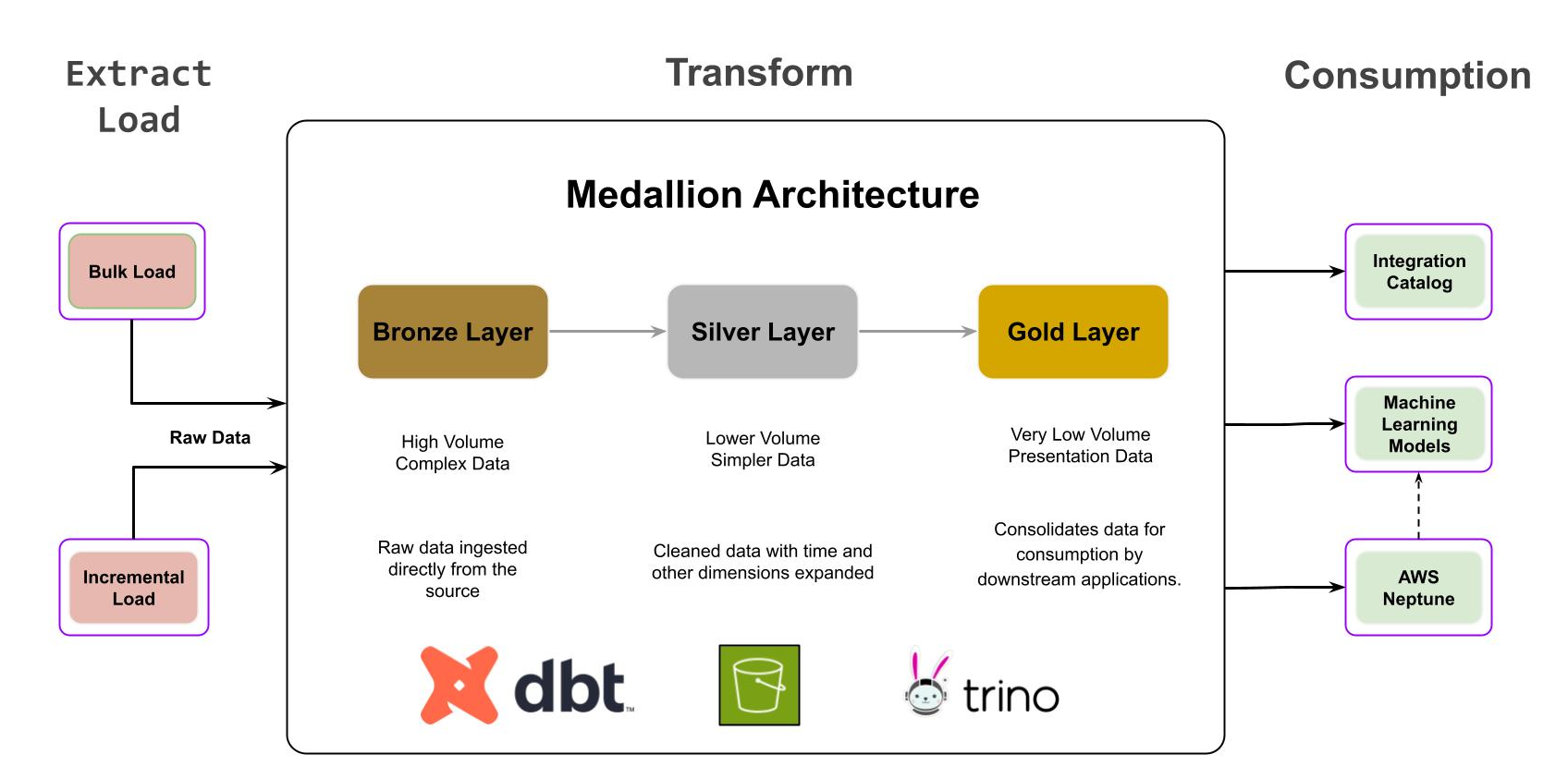
Die durch Pipeline-Ausführungen generierten Laufzeitdaten und die statischen Metadaten-Änderungsströme werden mit Trino analysiert, einer verteilten SQL-Abfrage-Engine, die in S3 gespeicherte Daten effizient abfragt. Wir haben das Datenschema in S3 für eine effiziente Abfrage durch Trino optimiert und dabei Faktoren wie Datenpartitionierung und Datenkomprimierung berücksichtigt.
Um den medaillonbasierten Ansatz für Transformationen zu implementieren, verwenden wir DBT-basierte SnapLogic-Pipelines, die verschiedene Ebenen darstellen. Diese Pipelines laufen auf benutzerdefinierten DBT Ground-Plexen, um die Daten zu transformieren und zu verfeinern, die Datenqualität sicherzustellen und sie für die Verwendung durch nachgelagerte Anwendungen wie Asset Catalog und Wissensgraphen vorzubereiten, um unsere nachgelagerten ML-Modelle anzureichern.
Die Medallion-Architektur besteht aus verschiedenen Schichten, die jeweils bestimmte Funktionen haben. Die Bronze-Schicht nimmt Daten aus S3 auf und überträgt sie an die Silber-Schicht, wo die Daten durch Normalisierung bereinigt und verfeinert werden. Anschließend konsolidiert die Gold-Schicht die Daten mithilfe von Verknüpfungen, die auf der Silber-Schicht durchgeführt werden, sodass sie für nachgelagerte Anwendungen leicht zugänglich sind.
Verbrauch
Die Goldschicht, die als Präsentationsschicht fungiert, enthält faktische, operative und abgeleitete Daten, die von zwei primären Systemen genutzt werden.
Der Asset-Katalog dient als zentrales System of Record (SoR) für alle SnapLogic-Pipelines und ermöglicht die Ermittlung, das Verständnis und die Verwaltung von Integrations-Assets durch offengelegte Metadaten (faktische, abgeleitete und ergänzte Attribute zu Aufgaben, Pipelines und Konten).
Die Daten in den Goldschicht-Tabellen werden mit einem graphbasierten Datenmodell in Amazon Neptune synchronisiert. Dieses graphbasierte Modell stellt die Beziehungen zwischen Assets dar, darunter Pipelines, Konten, Snaps und Dateien. Jeder Asset-Typ wird durch Knoten dargestellt, und Kanten symbolisieren Abhängigkeiten und Beziehungen.
Wichtige Überlegungen bei der Umsetzung
- Datenauszugs-Overhead-
Die anfängliche Datenextraktion und die fortlaufende Erfassung von Änderungsdaten erfordern eine sorgfältige Planung und Optimierung. - Datenkonsistenz-
Die Aufrechterhaltung der Datenkonsistenz zwischen MongoDB und der neuen Architektur ist von entscheidender Bedeutung.
der Architekturkomplexität Die Verwaltung einer aus mehreren Komponenten bestehenden Architektur erfordert Fachwissen und kontinuierliche Wartung.
Vorteile der neuen Architektur
- Kostenreduzierung: S3 Data Lakehouse minimiert Speicher- und Abfragekosten, wobei die Kosten in erster Linie mit der Infrastruktur von Trino verbunden sind.
- Skalierbarkeit und Leistung: Die Medallion-Architektur mit S3 und Trino ermöglicht eine effiziente Verarbeitung und Analyse großer Datensätze und übertrifft damit frühere MongoDB-basierte Analysen.
- Optimiertes Datenmanagement: Die Medallion-Architektur verbessert die Datenorganisation durch definierte Ebenen (Bronze, Silber, Gold) und sorgt so für Ausfallsicherheit, Wiederverwendbarkeit und optimierte Leistung für bestimmte Anwendungsfälle.
- Verbesserte Dateneinblicke: Das Graphenmodell von Neptune ermöglicht komplexe Beziehungsanalysen und verbessert so die Folgenabschätzung und die Rückverfolgbarkeit. Optimierte S3-Schemas für Trino steigern die Abfragegeschwindigkeit zusätzlich.
- Verbesserte Datenverwaltung und Compliance: Der mehrschichtige Ansatz sorgt für eine klare Sichtbarkeit der Datenherkunft und unterstützt so die Datenverwaltung und Compliance.
- Erhöhte Wiederverwendbarkeit von Daten und Entwicklungsgeschwindigkeit: Gut modellierte Silber- und Gold-Schichten können projektübergreifend wiederverwendet werden, wodurch Redundanzen reduziert und die Erstellung von Geschäftseinheiten beschleunigt werden.
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass wir eine robuste und skalierbare Analyseplattform unter Verwendung der Medallion-Architektur implementiert haben und von einer MongoDB-zentrierten Analyse zu einem effizienteren, kostengünstigeren und datengesteuerten Ansatz mit S3 und Trino übergegangen sind. Diese Architektur hat das Datenmanagement verbessert, die Leistung gesteigert, eine tiefere Datenmodellierung ermöglicht und die Datenverwaltung gestärkt. Mit Blick auf die Zukunft wollen wir die Transformationspipelines weiter automatisieren und mehr Machine-Learning-Modelle in unsere Datenverarbeitungsebenen integrieren, um die prädiktive Analyse voranzutreiben. Darüber hinaus untersuchen wir Verbesserungen der Echtzeit-Datenverarbeitung und erweitern unsere Data-Lakehouse-Fähigkeiten, um eine größere Bandbreite an Datenquellen und analytischen Workloads zu unterstützen und sicherzustellen, dass unsere Plattform an der Spitze der Dateninnovation bleibt.








