






Im sich schnell entwickelnden Bereich der generativen KI (GenAI) kann grundlegendes Wissen Sie weit bringen, aber erst die Beherrschung fortgeschrittener Muster versetzt Sie wirklich in die Lage, anspruchsvolle, skalierbare und effiziente Anwendungen zu entwickeln. Mit zunehmender Komplexität KI-gesteuerter Aufgaben wächst auch der Bedarf an robusten Strategien, die vielfältige Szenarien bewältigen können – von der Aufrechterhaltung des Kontexts in mehrteiligen Gesprächen bis hin zur dynamischen Generierung von Inhalten auf der Grundlage von Benutzereingaben.
Dieser Leitfaden befasst sich eingehend mit diesen fortgeschrittenen Mustern und bietet einen tiefen Einblick in die Strategien, mit denen Sie Ihre GenAI-Anwendungen verbessern können. Ganz gleich, ob Sie als Administrator Ihre KI-Systeme optimieren möchten oder als Entwickler die Grenzen des Möglichen erweitern wollen – wenn Sie diese Muster verstehen und umsetzen, können Sie komplexe Herausforderungen souverän bewältigen und lösen.
1. Fortgeschrittene Prompt-Entwicklung
1.1 Umfassende Kontrolle des Antwortformats
In GenAI-Anwendungen ist die Kontrolle des Ausgabeformats entscheidend, um sicherzustellen, dass die Antworten den spezifischen Anforderungen der Benutzer entsprechen. Mit Hilfe von Advanced Prompt Engineering können Sie Prompts erstellen, die präzise Anweisungen dazu enthalten, wie die KI ihre Ausgabe strukturieren soll. Dieser Ansatz verbessert nicht nur die Konsistenz der Antworten, sondern sorgt auch dafür, dass sie besser auf die gewünschten Ziele abgestimmt sind.
Sie können beispielsweise Prompts mit einer detaillierten Struktur entwerfen, die mehrere Elemente wie Kontext, Ziel, Stil, Zielgruppe und gewünschte Antwortlänge umfasst. Diese Methode ermöglicht eine detaillierte Kontrolle über die Ausgabe. Ein Beispiel für einen Prompt könnte wie folgt aussehen:
- Kontext: Geben Sie Hintergrundinformationen zum Thema, um den Rahmen zu schaffen.
- Ziel: Den Zweck der Reaktion klar definieren.
- Stil: Geben Sie an, ob die Antwort formell, informell, technisch oder kreativ sein soll.
- Zielgruppe: Identifizieren Sie die Zielgruppe, die Einfluss auf die Sprache und die Tiefe der Erläuterungen hat.
- Antwortformat: Weisen Sie die KI an, eine Antwort zu generieren, deren Lesezeit etwa 3 Minuten beträgt und die tiefgehend und umfassend ist und in der Regel 4–5 Absätze umfasst.
Dieser Detaillierungsgrad beim Prompt Engineering stellt sicher, dass die KI-generierten Inhalte spezifischen Anforderungen entsprechen und somit für verschiedene Anwendungsfälle geeignet sind, beispielsweise für die Erstellung von Unterrichtsmaterialien, detaillierten Berichten oder Kundenkommunikation.
1.2 Few-Shot-Lernen
Few-Shot-Lernenist eine fortgeschrittene Technik, bei der dem KI-Modell eine kleine Anzahl von Beispielen (oft nur wenige) innerhalb der Eingabeaufforderung zur Verfügung gestellt wird, um seine Ausgabe zu steuern. Diese Methode ist besonders leistungsstark bei Aufgaben, bei denen das Modell komplexe Muster oder Formate mit minimalem Input verstehen und reproduzieren muss.
Durch die direkte Einbindung von Beispielen in die Eingabeaufforderung können Sie das Modell so trainieren, dass es auch in Szenarien, in denen keine großen Mengen an Trainingsdaten verfügbar sind, genauere und kontextuell angemessenere Antworten liefert.
Dieser Ansatz ist von unschätzbarem Wert für die Anpassung des Verhaltens der KI an Nischenanwendungen, bei denen allgemeine Trainingsdaten möglicherweise nicht ausreichen.
Beispielaufgabe:
„Erstellen Sie eine Produktbeschreibung für die folgenden Artikel. Die Beschreibung sollte prägnant sein, die wichtigsten Merkmale hervorheben und eine Zielgruppe ansprechen, die an Qualität und Innovation interessiert ist.
Beispiel 1:
- Produktname: SmartHome WiFi-Thermostat
- Beschreibung: „Der SmartHome WiFi Thermostat ist die ultimative Lösung für eine energieeffiziente Temperaturregelung. Durch die nahtlose Integration in Ihr Smart-Home-Ökosystem bietet er intuitive Bedienelemente, anpassbare Einstellungen und Echtzeit-Energieverbrauchsberichte. Er wurde für modernes Wohnen entwickelt und sorgt für Komfort, während Sie gleichzeitig Energiekosten sparen.“
Beispiel 2:
- Produktname: EcoBrew Edelstahl-Kaffeemaschine
- Beschreibung: „Die EcoBrew Edelstahl-Kaffeemaschine verbindet Nachhaltigkeit mit erstklassiger Leistung. Diese umweltfreundliche Kaffeemaschine aus strapazierfähigem Edelstahl brüht jedes Mal die perfekte Tasse Kaffee und belastet dabei die Umwelt nur minimal. Sie ist ideal für den bewussten Kaffeeliebhaber und bietet präzises Brühen und ein elegantes Design, das zu jeder Küche passt.“
Neuer Artikel:
- Produktname: Ultraleichter Reiserucksack
Beschreibung:
KI-generierte Ausgabe:
„UltraLight Travel Backpack: Der UltraLight Travel Backpack wurde für den modernen Abenteurer entwickelt. Mit einem Gewicht von knapp einem Pfund bietet er unübertroffene Tragbarkeit, ohne dabei an Stauraum einzubüßen. Mit wasserabweisendem Material, mehreren Fächern und ergonomischen Schultergurten ist dieser Rucksack für alle gedacht, die unterwegs Wert auf Langlebigkeit und Komfort legen. Der UltraLight Travel Backpack eignet sich perfekt für Tageswanderungen, Wochenendausflüge oder den täglichen Gebrauch und ist Ihr zuverlässiger Begleiter auf jeder Reise.“
Erklärung:
In diesem Beispiel wurden der KI zwei Produktbeschreibungen vorgelegt, die den gewünschten Stil, Ton und Aufbau der Ausgabe veranschaulichen. Als sie gebeten wurde, eine neue Beschreibung für den „UltraLight Travel Backpack“ zu generieren, verwendete die KI die Muster aus den vorgelegten Beispielen, um eine ähnliche, kontextuell passende Produktbeschreibung zu erstellen. Obwohl ihr nur zwei Beispiele gezeigt wurden, erfasste das Modell effektiv die Schlüsselelemente, die für die Generierung einer neuen, hochwertigen Ausgabe erforderlich waren.
Dieser Ansatz ist besonders vorteilhaft, wenn die KI bei ähnlichen Aufgaben konsistente Ergebnisse liefern soll, insbesondere in Szenarien, in denen die Erstellung umfangreicher Trainingsdaten nicht praktikabel ist. Durch die Bereitstellung nur weniger Beispiele lenken Sie das Verständnis der KI und ermöglichen ihr, das gelernte Muster auf neue, aber verwandte Aufgaben anzuwenden.
1.3 Gedankenkette
Die Kette von Denkmustern regt die KI dazu an, Antworten zu generieren, die einer logischen Abfolge folgen und menschliches Denken widerspiegeln. Diese Technik ist besonders nützlich in komplexen Szenarien, in denen die KI Entscheidungen treffen, Probleme lösen oder Konzepte Schritt für Schritt erklären muss.
Durch die Strukturierung von Eingabeaufforderungen, die die KI durch eine Reihe von Denkprozessen führen, können Sie sie dazu anleiten, kohärentere und rationalere Ergebnisse zu liefern. Dies ist besonders effektiv in Anwendungen, die detaillierte Erklärungen erfordern, wie z. B. wissenschaftliche Argumentation, technische Problemlösung oder jede Situation, in der die KI ihre Schlussfolgerungen begründen muss. Eine Eingabeaufforderung könnte die KI beispielsweise anweisen, ein komplexes Problem in kleinere, überschaubare Teile zu zerlegen und diese nacheinander anzugehen. Die KI würde zunächst die Schlüsselkomponenten des Problems identifizieren, dann jede einzelne bearbeiten und dabei ihre Überlegungen bei jedem Schritt erläutern. Diese Methode verbessert nicht nur die Klarheit der Antwort, sondern auch die Genauigkeit und Relevanz der Schlussfolgerungen der KI.
2. Multimodale Verarbeitung
Die multimodale Verarbeitung in der generativen KI ist ein innovativer Ansatz, der es KI-Systemen ermöglicht, mehrere Arten von Daten – wie Text, Bilder, Audio und Video – gleichzeitig zu integrieren und zu verarbeiten. Diese Fähigkeit ist entscheidend für Anwendungen, die ein tiefes Verständnis von Inhalten über verschiedene Modalitäten hinweg erfordern, was zu genaueren und kontextuell angereicherten Ergebnissen führt.
Wenn eine KI beispielsweise die Aufgabe hat, eine Beschreibung einer Szene aus einem Video zu erstellen, kann sie dank multimodaler Verarbeitung sowohl die visuellen Elemente als auch den begleitenden Ton analysieren, um eine Beschreibung zu erstellen, die nicht nur das Gesehene, sondern auch den durch den Ton vermittelten Kontext widerspiegelt. Ebenso kann die KI bei der gemeinsamen Verarbeitung von Text und Bildern, beispielsweise bei der Erstellung von Untertiteln, die Beziehung zwischen den Wörtern und dem visuellen Inhalt besser verstehen, was zu präziseren und relevanteren Untertiteln führt.
Dieses fortschrittliche Muster ist besonders vorteilhaft in komplexen Umgebungen, in denen das Verständnis der Nuancen verschiedener Datentypen entscheidend für die Bereitstellung hochwertiger Ergebnisse ist. In der medizinischen Diagnostik können KI-Systeme beispielsweise mithilfe multimodaler Verarbeitung medizinische Bilder zusammen mit Patientenakten und gesprochenen Notizen analysieren, um genauere Diagnosen zu erstellen. Im Kundenservice kann KI Kundenanfragen interpretieren und beantworten, indem sie gleichzeitig Text und Tonfall analysiert und so die Qualität der Interaktionen verbessert.
Darüber hinaus verbessert die multimodale Verarbeitung die Fähigkeit der KI, aus verschiedenen Datenquellen zu lernen, sodass sie robustere Modelle erstellen kann, die sich besser auf verschiedene Aufgaben übertragen lassen. Dies macht sie zu einem unverzichtbaren Werkzeug bei der Entwicklung von KI-Anwendungen, die in realen Szenarien eingesetzt werden müssen, in denen Daten selten homogen sind.
Durch die Nutzung multimodaler Verarbeitung können KI-Systeme Antworten generieren, die nicht nur umfassender sind, sondern auch auf die spezifischen Anforderungen der jeweiligen Aufgabe zugeschnitten sind, wodurch sie in einer Vielzahl von Anwendungsbereichen äußerst effektiv sind. Mit der Weiterentwicklung dieser Technologie eröffnen sich neue Möglichkeiten in so unterschiedlichen Bereichen wie Unterhaltung, Bildung, Gesundheitswesen und darüber hinaus.
Beispiel
In vielen Situationen können Daten sowohl Bilder als auch Text enthalten, die gemeinsam analysiert werden müssen, um umfassende Erkenntnisse zu gewinnen. Um diese unterschiedlichen Datentypen effektiv zu verarbeiten und zu integrieren, können Sie in SnapLogic eine multimodale Verarbeitungs-Pipeline nutzen. Dieser Ansatz ermöglicht es dem generativen KI-Modell, Daten aus beiden Quellen gleichzeitig zu analysieren und dabei die Integrität jeder Modalität zu bewahren.

Diese Pipeline besteht aus zwei unterschiedlichen Phasen. In der ersten Phase werden Bilder aus den Quelldaten extrahiert und in das Base64-Format konvertiert. In der zweiten Phase wird mithilfe fortschrittlicher Prompt-Engineering-Techniken eine Eingabeaufforderung generiert, die dann in das Large Language Model (LLM) eingespeist wird. Die visuelle Darstellung dieses Prozesses ist, wie in der Abbildung oben gezeigt, in zwei Teile gegliedert.
Extrahieren Sie das Bild aus der Quelle.
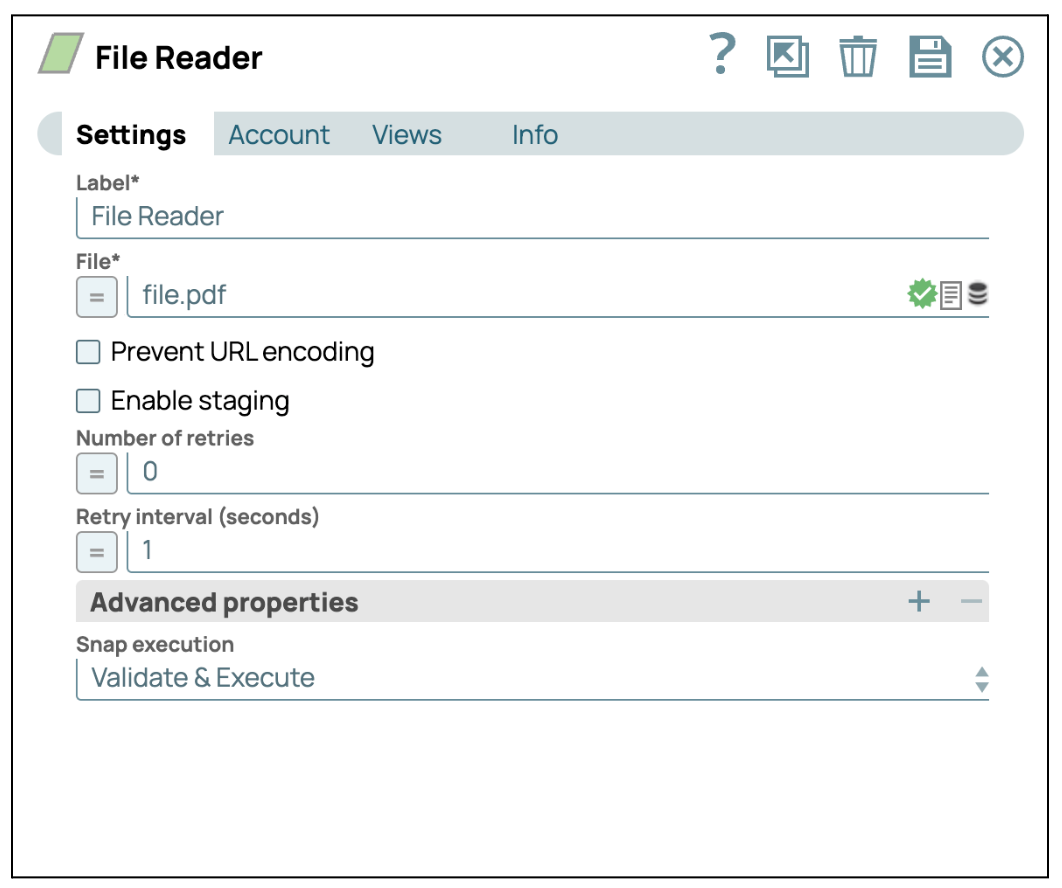
- Fügen Sie den Snap „Dateileser“ hinzu: Ziehen Sie den Snap „Dateileser“ per Drag & Drop in den Designer.
- Konfigurieren Sie den Dateileser-SnapKlicken Sie auf das Snap-Modul „Dateireader“, um dessen Einstellungsfenster zu öffnen. Wählen Sie dann eine Datei aus, die Bilder enthält. In diesem Fall wählen wir eine PDF-Datei aus.
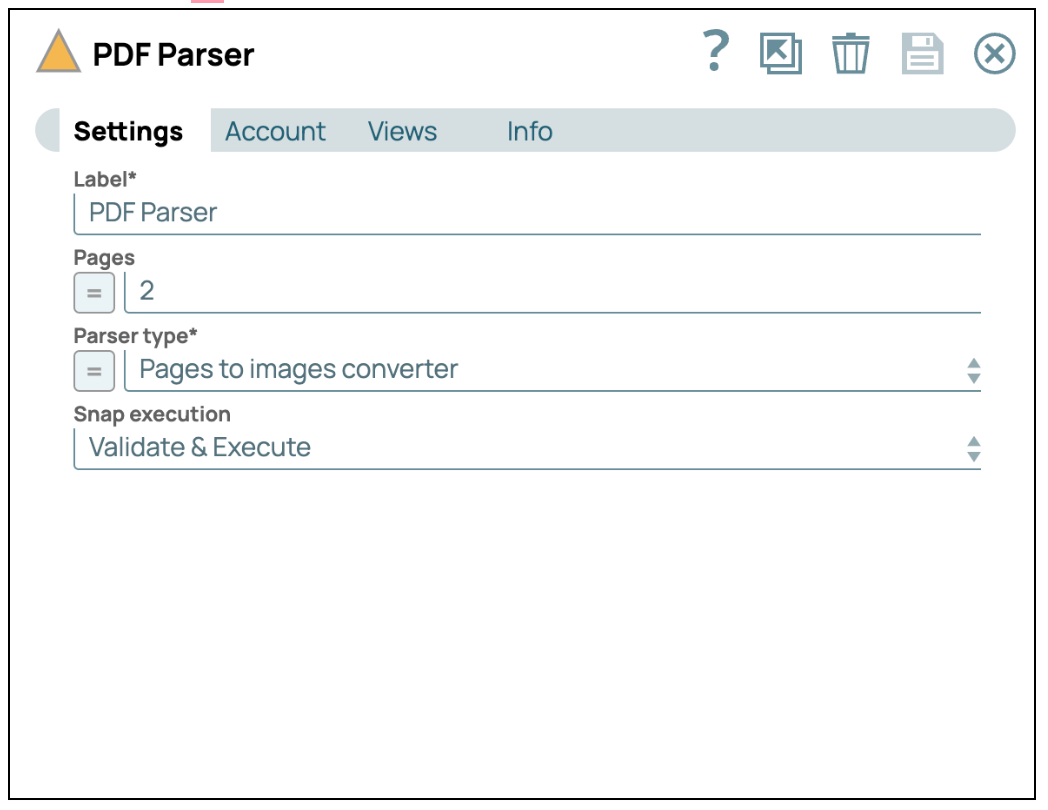
- Fügen Sie den PDF-Parser-Snap hinzu: Ziehen Sie den „PDF Parser“ Snap per Drag & Drop auf den Designer und stellen Sie den Parser-Typ auf „Seiten in Bilder konvertieren“ ein.
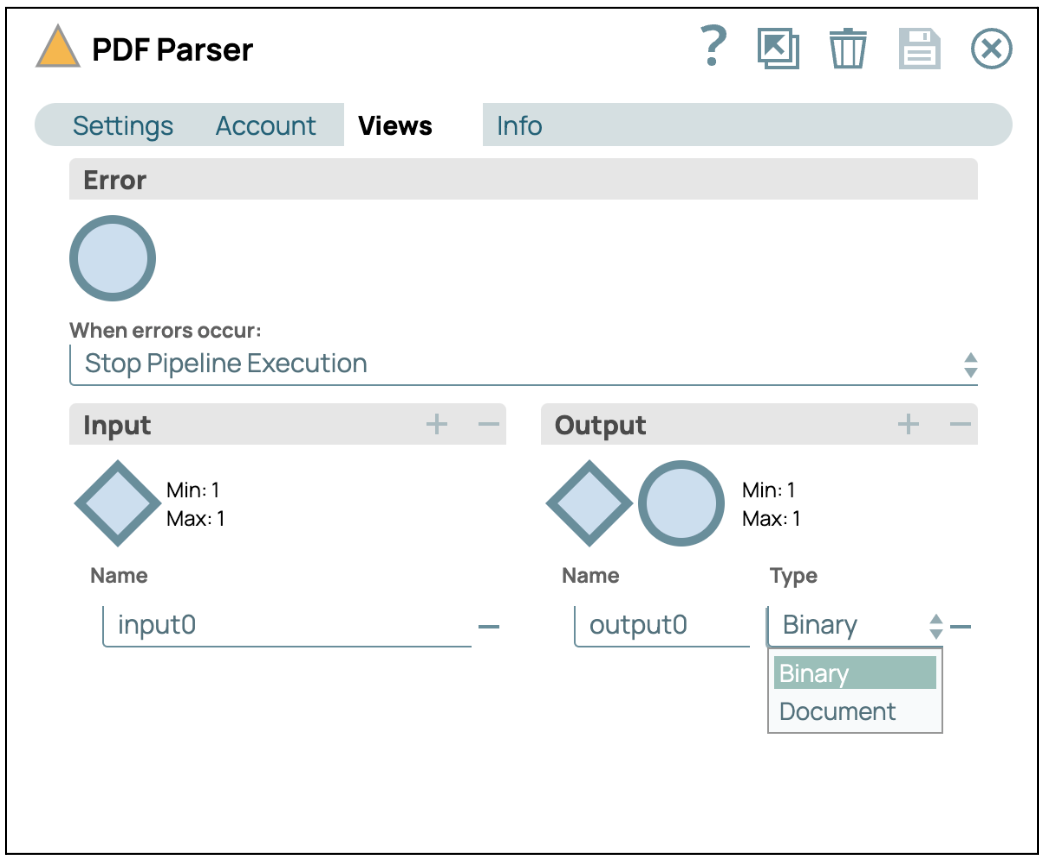
- Ansichten konfigurieren: Klicken Sie auf die Registerkarte „Ansichten“ und wählen Sie als Ausgabe „Binär“ aus.
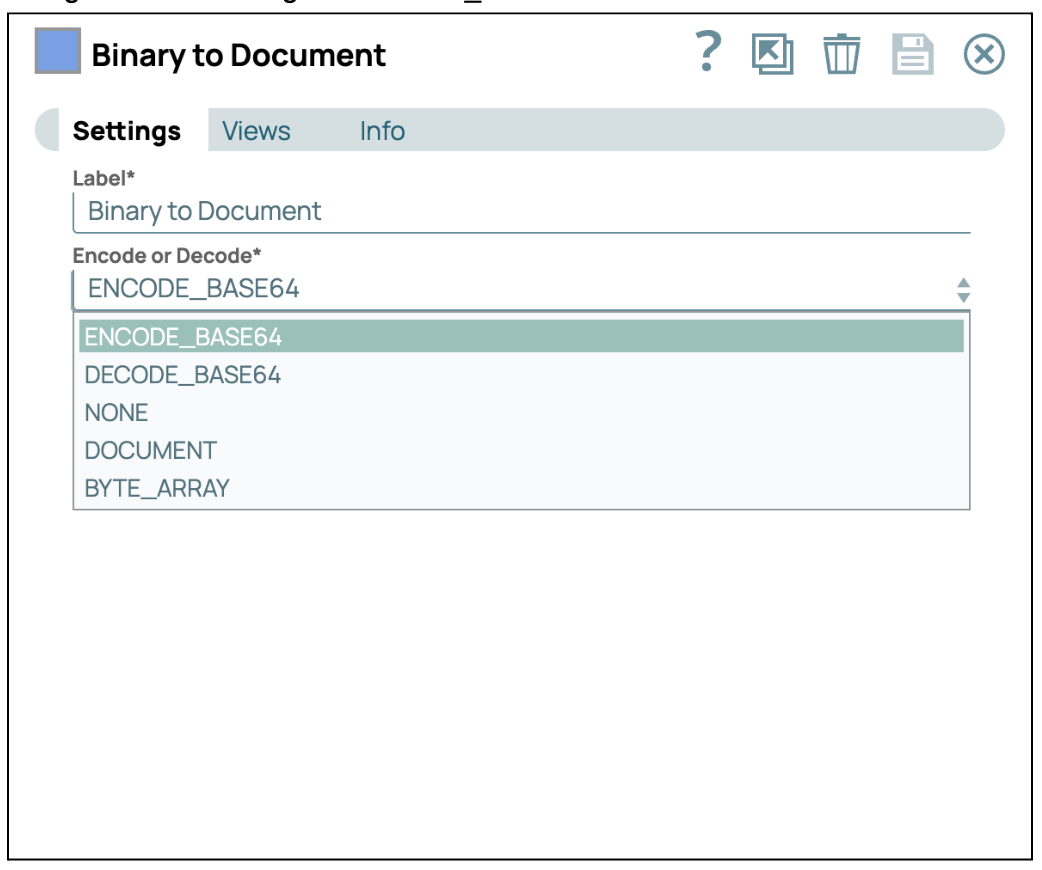
- In Base64 konvertieren: Fügen Sie den Snap „Binary to Document“ hinzu und verbinden Sie ihn mit dem Snap „PDF Parser“. Konfigurieren Sie anschließend die Kodierung auf ENCODE_BASE64.
Erstellen Sie die Eingabeaufforderung und senden Sie sie an GenAI.
- Fügen Sie einen JSON-Generator-Snap hinzu: Ziehen Sie den JSON-Generator-Snap und verbinden Sie ihn mit dem vorhergehenden Mapper-Snap. Klicken Sie dann auf „JSON bearbeiten“, um die JSON-Zeichenfolge im JSON-Editor-Modus zu ändern. Mit AWS Claude on Message können Sie Bilder über die Eingabeaufforderung senden, indem Sie das Quellattribut innerhalb des Inhalts konfigurieren. Sie können die Bild-Eingabeaufforderung wie im Screenshot gezeigt erstellen.

- Anweisungen mit dem Prompt Generator bereitstellen: Fügen Sie den Prompt-Generator Snap hinzu und verbinden Sie ihn mit dem JSON-Generator Snap. Aktivieren Sie anschließend das Kontrollkästchen „Erweiterte Prompt-Ausgabe“, um die erweiterte Prompt-Nutzlast zu aktivieren. Klicken Sie abschließend auf „Prompt bearbeiten“, um Ihre spezifischen Anweisungen einzugeben.
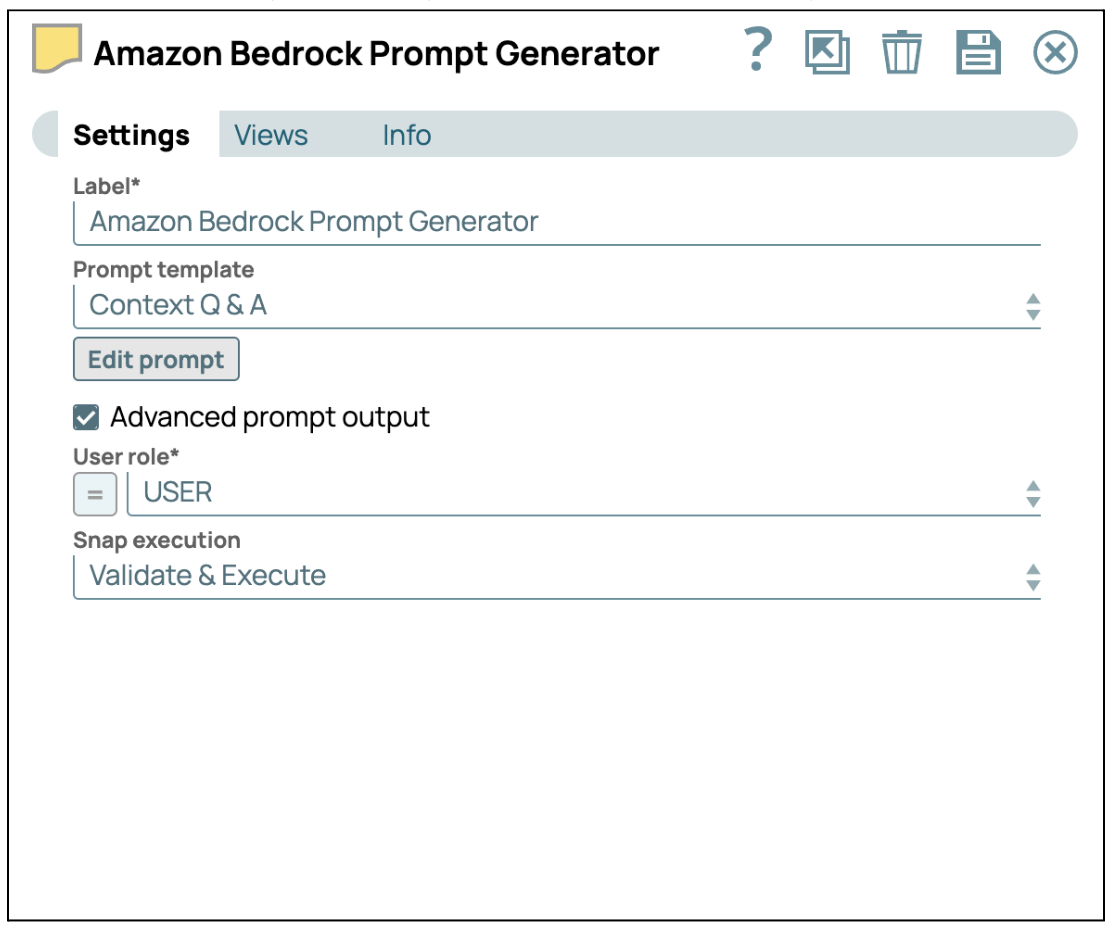
Die erweiterte Eingabeaufforderung wird als Array von Meldungen strukturiert sein, wie in der folgenden Abbildung dargestellt.
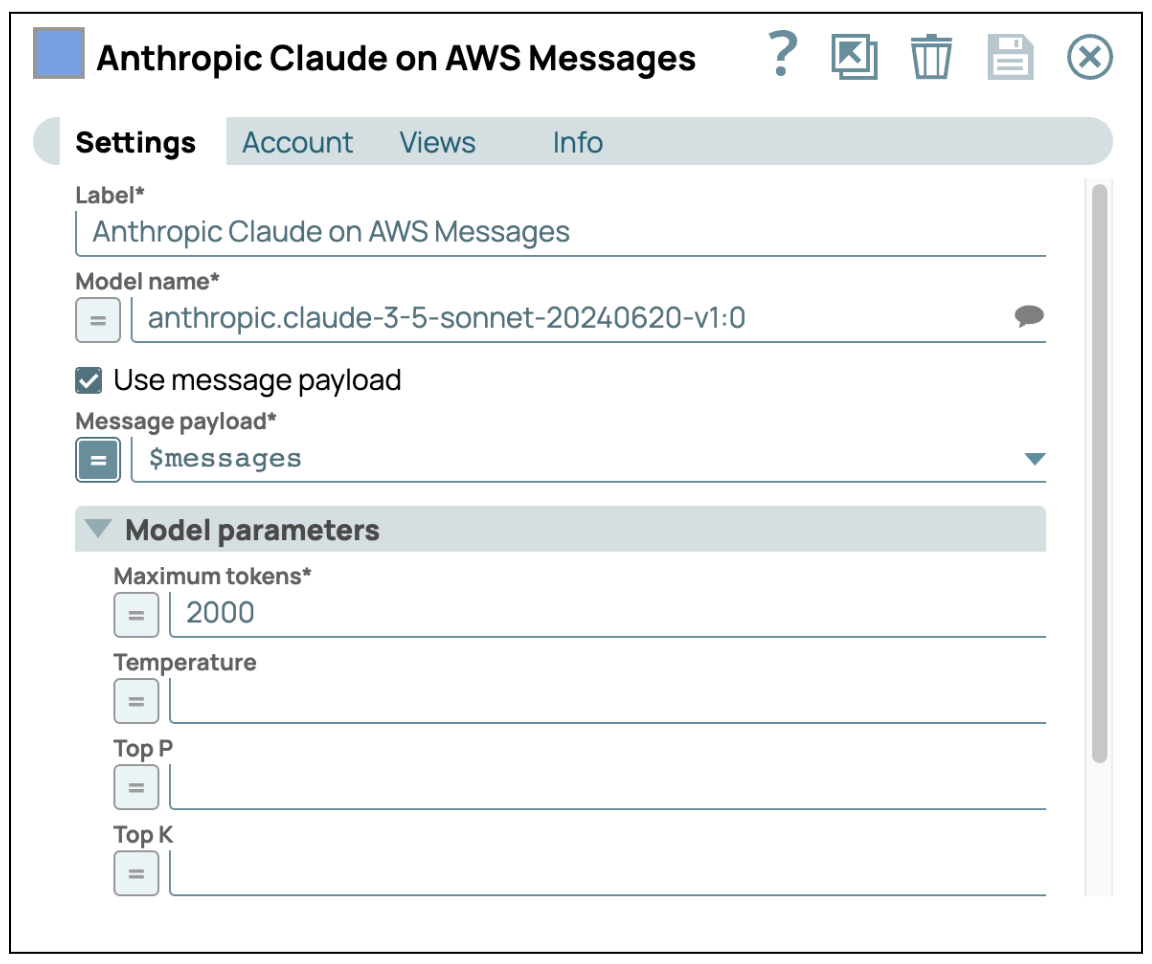
- An GenAI senden: Fügen Sie AWS Claude auf AWS Message Snap hinzu und geben Sie Ihre Anmeldedaten ein, um auf den AWS Bedrock-Dienst zuzugreifen. Stellen Sie sicher, dass das Kontrollkästchen „Use Message Payload“ (Nachrichten-Nutzlast verwenden) aktiviert ist, und konfigurieren Sie dann die Nachrichten-Nutzlast mit $messages, der Ausgabe aus dem vorherigen Snap.
Nachdem Sie diese Schritte abgeschlossen haben, können Sie das Bild mit dem LLM unabhängig verarbeiten. Dieser Ansatz ermöglicht es dem LLM, sich auf die Extraktion detaillierter Informationen aus dem Bild zu konzentrieren. Sobald das Bild verarbeitet wurde, können Sie diese Daten mit anderen Quellen wie Text oder strukturierten Daten kombinieren, um eine umfassendere und genauere Analyse zu erstellen. Diese multimodale Integration stellt sicher, dass die aus verschiedenen Datentypen gewonnenen Erkenntnisse effektiv synthetisiert werden, was zu reichhaltigeren und präziseren Ergebnissen führt.
3. Semantisches Caching
Um sowohl die Kosten als auch die Reaktionszeit im Zusammenhang mit der Verwendung von Large Language Models (LLMs) zu optimieren, ist die Implementierung eines semantischen Caching-Mechanismus eine äußerst effektive Strategie. Beim semantischen Caching werden die vom Modell generierten Antworten gespeichert und wiederverwendet, wenn das System auf Anfragen mit derselben oder einer ähnlichen Bedeutung stößt. Dieser Ansatz verbessert nicht nur die Gesamteffizienz des Systems, sondern senkt auch die mit der Modellnutzung verbundenen Betriebskosten erheblich.
Das Grundprinzip hinter dem semantischen Caching besteht darin, dass viele Benutzeranfragen oft semantisch ähnlich sind, auch wenn sie unterschiedlich formuliert sind. Durch die Identifizierung und Zwischenspeicherung der Antworten auf diese semantisch gleichwertigen Anfragen kann das System die wiederholte Aufrufung des LLM umgehen, was ressourcenintensiv ist. Stattdessen kann das System die zwischengespeicherte Antwort schnell abrufen und zurückgeben, was zu schnelleren Antwortzeiten und einer nahtloseren Benutzererfahrung führt.
Aus Kostensicht führt semantisches Caching direkt zu Einsparungen. Jedes Mal, wenn das System eine Antwort aus dem Cache liefert, anstatt die LLM abzufragen, werden die mit der Generierung einer neuen Antwort verbundenen Rechenkosten vermieden. Diese Verringerung der Anzahl der LLM-Aufrufe steht in direktem Zusammenhang mit niedrigeren Servicekosten, wodurch die Lösung insbesondere in Umgebungen mit hohem Abfragevolumen wirtschaftlicher wird.
Darüber hinaus trägt semantisches Caching zur Skalierbarkeit des Systems bei. Bei steigender Nachfrage nach LLM hilft der Caching-Mechanismus dabei, die Last effektiver zu verwalten, sodass die Antwortzeiten auch bei einer Skalierung des Systems konsistent bleiben. Dies ist entscheidend für die Aufrechterhaltung der Servicequalität, insbesondere in Echtzeitanwendungen, bei denen die Latenz ein kritischer Faktor ist.
Die Implementierung von semantischem Caching als Teil der LLM-Bereitstellungsstrategie bietet einen doppelten Vorteil: Optimierung der Antwortzeiten für Endbenutzer und Minimierung der Betriebskosten für die Modellnutzung. Dieser Ansatz verbessert nicht nur die Leistung und Skalierbarkeit von KI-gesteuerten Systemen, sondern stellt auch sicher, dass sie bei steigender Benutzeranforderung kosteneffizient und reaktionsschnell bleiben.
Implementierungskonzept für semantisches Caching
Semantisches Caching ist ein strategischer Ansatz zur Optimierung sowohl der Reaktionszeit als auch der Recheneffizienz in KI-gesteuerten Systemen. Die Implementierung von semantischem Caching umfasst die folgenden wichtigen Schritte:
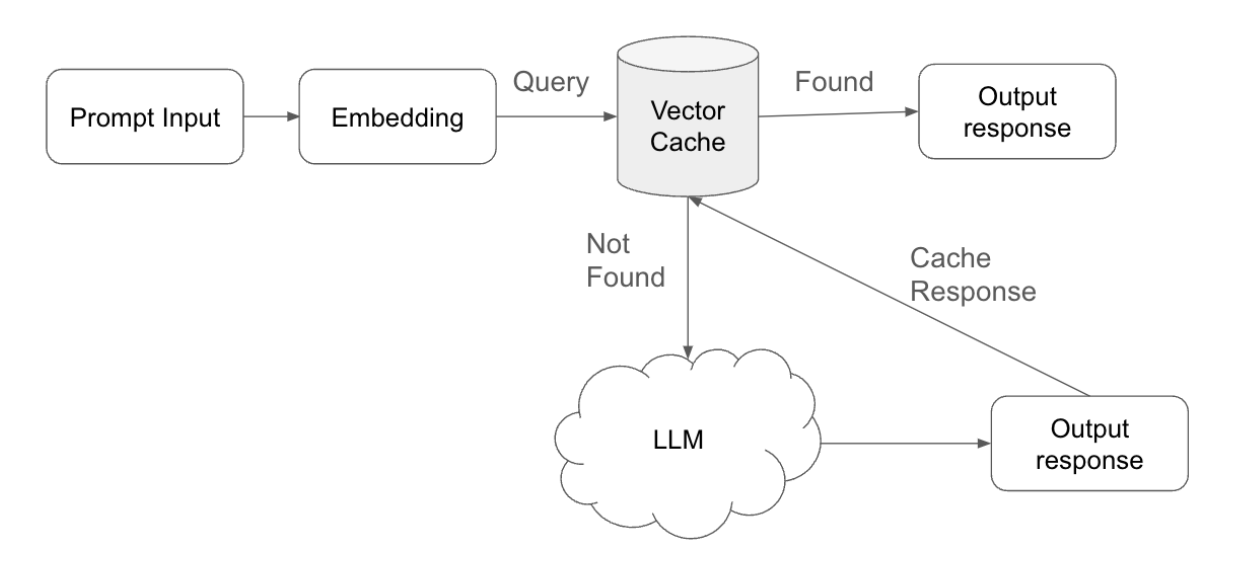
- Abfrageübermittlung und Vektorisierung: Wenn ein Benutzer eine Abfrage übermittelt, verarbeitet das System diese Eingabe zunächst, indem es sie in eine Einbettung umwandelt – eine vektorisierte Darstellung der Abfrage. Diese Einbettung erfasst die semantische Bedeutung der Abfrage und ermöglicht einen effizienten Vergleich mit zuvor gespeicherten Daten.
- Cache-Abfrage und -AbgleichDas System führt dann eine Suche im Vektor-Cache durch, der Einbettungen früherer Abfragen zusammen mit den entsprechenden Antworten enthält. Während dieser Suche sucht das System nach einer vorhandenen Einbettung, die der Einbettung der neuen Abfrage möglichst genau entspricht.
- Übereinstimmungsschwelle: Ein wichtiger Bestandteil dieses Prozesses ist die Übereinstimmungsschwelle, die angepasst werden kann, um die Empfindlichkeit des Übereinstimmungsalgorithmus zu steuern. Diese Schwelle bestimmt, wie genau die neue Abfrage mit einer gespeicherten Einbettung übereinstimmen muss, damit der Cache sie als Übereinstimmung betrachtet.
- Cache-Treffer und Abruf der Antwort: Wenn das System innerhalb des definierten Schwellenwerts eine Übereinstimmung feststellt, ruft es die entsprechende Antwort aus dem Cache ab. Dieser „Cache-Treffer“ ermöglicht es dem System, die Antwort schnell an den Benutzer zu übermitteln, ohne dass eine weitere Verarbeitung erforderlich ist. Durch die direkte Bereitstellung von Antworten aus dem Cache spart das System Rechenressourcen und reduziert die Antwortzeiten.
- Cache-Fehler und LLM-Verarbeitung: Wenn im Cache keine passende Übereinstimmung gefunden wird – ein „Cache-Fehler“ –, leitet das System die Anfrage an das Large Language Model (LLM) weiter. Das LLM verarbeitet die Anfrage und generiert eine neue Antwort, sodass der Benutzer auch bei neuen Anfragen eine relevante und genaue Antwort erhält.
- Antwortspeicherung und Cache-VerwaltungNachdem das LLM eine neue Antwort generiert hat, übermittelt das System diese Antwort nicht nur an den Benutzer, sondern speichert sie auch zusammen mit der zugehörigen Abfrageeinbettung wieder im Vektor-Cache. Dieser Schritt stellt sicher, dass das System bei einer ähnlichen Abfrage in der Zukunft die Antwort direkt aus dem Cache bereitstellen kann, wodurch die Effizienz des Systems weiter optimiert wird.
- Time-to-Live (TTL)-Anpassung: Um die Relevanz und Genauigkeit der zwischengespeicherten Antworten zu gewährleisten, kann das System die Time-to-Live (TTL) für jeden Eintrag im Cache anpassen. Die TTL bestimmt, wie lange eine Antwort im Cache gültig bleibt, bevor sie als veraltet gilt und automatisch entfernt wird. Durch die Feinabstimmung der TTL-Einstellungen stellt das System sicher, dass nur aktuelle und kontextbezogene Antworten bereitgestellt werden, wodurch die Verwendung veralteter oder irrelevanter Daten verhindert wird.
Semantisches Caching in SnapLogic implementieren
Das Konzept des semantischen Cachings lässt sich mithilfe der robusten Pipeline-Funktionen von SnapLogic effektiv umsetzen. Nachfolgend finden Sie eine Übersicht darüber, wie diese Umsetzung erreicht werden kann:

- Einbetten der Abfrage: Der Prozess beginnt mit dem Einbetten der Abfrage (Eingabeaufforderung) des Benutzers. Mithilfe der Funktionen von SnapLogic wird ein Einbettungsprogramm wie Amazon Titan Embedder verwendet, um die Eingabeaufforderung in eine vektorisierte Darstellung umzuwandeln. Diese Einbettung erfasst die semantische Bedeutung der Eingabeaufforderung und eignet sich somit für den Vergleich mit zuvor gespeicherten Einbettungen.
- Vektor-Cache-Suche: Sobald die Eingabeaufforderung eingebettet wurde, sucht das System nach einem passenden Eintrag im Vektor-Cache. In dieser Implementierung dient die Snowflake-Vektordatenbank als Vektor-Cache, in dem Einbettungen früherer Abfragen zusammen mit den entsprechenden Antworten gespeichert werden. Diese Suche ist entscheidend, um festzustellen, ob eine ähnliche Abfrage bereits zuvor verarbeitet wurde.
- Flow-Routing mit Router SnapNach der Suche verwendet das System einen Router Snap, um den Ablauf basierend darauf zu verwalten, ob eine Übereinstimmung (Cache-Treffer) gefunden wurde oder nicht (Cache-Fehler). Der Router Snap leitet den Workflow wie folgt weiter:
- Cache-Treffer: Wenn im Vektor-Cache eine passende Einbettung gefunden wird, leitet der Router Snap den Prozess so weiter, dass die zwischengespeicherte Antwort sofort an den Benutzer zurückgegeben wird. Dadurch werden schnelle Antwortzeiten gewährleistet, da unnötige Verarbeitungsschritte vermieden werden.
- Cache-Fehler: Wenn keine Übereinstimmung gefunden wird, leitet der Router Snap den Workflow weiter, um eine neue Antwort vom Large Language Model (LLM) anzufordern. Das LLM verarbeitet die Eingabeaufforderung und generiert eine neue, relevante Antwort.
- Speichern und Antworten: Im Falle eines Cache-Fehlers sendet das System, nachdem das LLM eine neue Antwort generiert hat, diese Antwort nicht nur an den Benutzer, sondern speichert auch die neue Einbettung und Antwort in der Snowflake Vector Database für die zukünftige Verwendung. Dieser Schritt verbessert die Effizienz nachfolgender Abfragen, da ähnliche Eingabeaufforderungen direkt aus dem Cache verarbeitet werden können.
4. Multiplexing von KI-Agenten
Multiplexing-KI-Agenten bezeichnet eine Strategie, bei der mehrere generative KI-Modelle, die jeweils auf eine bestimmte Aufgabe spezialisiert sind, parallel eingesetzt werden, um komplexe Anfragen zu bearbeiten. Dieser Ansatz ähnelt der Zusammenstellung eines Expertengremiums, in dem jeder Agent sein Fachwissen einbringt, um eine umfassende Lösung zu finden. Hier sind die wichtigsten Merkmale des Einsatzes von Multiplexing-KI-Agenten
- Spezialisierung: Ein zentraler Vorteil der Multiplexing-KI-Agenten ist die Spezialisierung jedes Agenten auf bestimmte Aufgaben oder Bereiche. Multiplexing sorgt dafür, dass die Antworten relevanter und genauer sind, indem jedes KI-Modell einem bestimmten Fachgebiet zugeordnet wird. So kann beispielsweise ein Agent für das Verstehen natürlicher Sprache optimiert sein, ein anderer für die Lösung technischer Probleme und ein dritter für die Zusammenfassung komplexer Daten. Auf diese Weise kann das System mehrdimensionale Anfragen effektiv bearbeiten, da sich jeder Agent auf das konzentriert, was er am besten kann. Diese Spezialisierung reduziert die Wahrscheinlichkeit von Fehlern oder irrelevanten Antworten erheblich, da die KI-Agenten auf ihre spezifischen Aufgaben zugeschnitten sind.
In Szenarien, in denen eine Anfrage mehrere Bereiche umfasst – beispielsweise eine technische Frage mit einem geschäftlichen Aspekt –, kann das System verschiedene Teile der Anfrage an den entsprechenden Agenten weiterleiten. Dieser strukturierte Ansatz ermöglicht die Extraktion relevanterer und genauerer Informationen, was zu einer Lösung führt, die alle Facetten des Problems berücksichtigt. - Parallelverarbeitung: Multiplexing-KI-Agenten nutzen die Vorteile der Parallelverarbeitung voll aus. Durch den gleichzeitigen Einsatz mehrerer Agenten kann das System verschiedene Aspekte einer Anfrage gleichzeitig bearbeiten und so die Gesamtantwortzeit verkürzen. Dieser parallele Ansatz verbessert sowohl die Leistung als auch die Skalierbarkeit, da die Arbeitslast auf mehrere Agenten verteilt wird, anstatt sich auf ein einziges Modell zur Bearbeitung der gesamten Aufgabe zu verlassen.
In einer Kundensupport-Anwendung könnte beispielsweise ein Agent die Analyse der bisherigen Interaktionen eines Kunden übernehmen, während ein anderer Agent eine Antwort auf ein technisches Problem generiert und ein weiterer einen Folgeaktionsplan erstellt. Jeder Agent arbeitet parallel an seiner jeweiligen Aufgabe, und das System integriert die Ergebnisse zu einer einheitlichen Antwort. Diese Methode beschleunigt nicht nur die Problemlösung, sondern stellt auch sicher, dass verschiedene Dimensionen des Problems gleichzeitig angegangen werden. - Dynamische Aufgabenverteilung: In einem Multiplexing-System ist die dynamische Aufgabenverteilung entscheidend für die effiziente Verteilung von Aufgaben unter den spezialisierten Agenten. Ein größeres Allzweckmodell wie AWS Claude 3 Sonet kann als Orchestrator fungieren, der den Kontext der Anfrage bewertet und bestimmt, welche Teile der Aufgabe an kleinere, spezialisiertere Agenten delegiert werden sollten. Der Orchestrator stellt sicher, dass jede Aufgabe dem Modell zugewiesen wird, das für ihre Bearbeitung am besten geeignet ist.
Wenn ein Benutzer beispielsweise eine komplexe Anfrage zu gesetzlichen Vorschriften und Datensicherheit stellt, kann das allgemeine Modell die Anfrage aufschlüsseln und rechtliche Fragen an einen auf Rechtsanalyse spezialisierten KI-Agenten und sicherheitsbezogene Fragen an einen auf Sicherheit fokussierten Agenten wie TinyLlama oder ein ähnliches Modell weiterleiten. Diese dynamische Delegierung ermöglicht es, die relevantesten Modelle zum richtigen Zeitpunkt einzusetzen, was sowohl die Effizienz als auch die Genauigkeit der Gesamtantwort verbessert. - Integration der Ergebnisse: Nachdem die spezialisierten Agenten ihre jeweiligen Aufgaben bearbeitet haben, muss das System ihre Ergebnisse integrieren, um eine zusammenhängende und umfassende Antwort zu erstellen. Diese Integration ist ein entscheidendes Merkmal des Multiplexings, da sie sicherstellt, dass alle Aspekte einer Anfrage ohne Überschneidungen oder Widersprüche behandelt werden. Das System kombiniert die von jedem Agenten generierten Erkenntnisse und erstellt eine endgültige Ausgabe, die den gesamten Umfang der Anfrage des Benutzers widerspiegelt.
In vielen Fällen umfasst der Integrationsprozess auch das Filtern oder Verfeinern der Ergebnisse, um Unstimmigkeiten oder Redundanzen zu beseitigen und sicherzustellen, dass die Antwort logisch und kohärent ist. Dieser kollaborative Ansatz erhöht die Zuverlässigkeit des Systems, da er es verschiedenen Agenten ermöglicht, sich gegenseitig mit ihrem Wissen und ihrer Expertise zu ergänzen.
Darüber hinaus verringert Multiplexing die Wahrscheinlichkeit von Halluzinationen – fehlerhaften oder unsinnigen Ausgaben, die manchmal bei einzelnen, groß angelegten Modellen auftreten können. Durch die Aufteilung der Aufgaben auf spezialisierte Agenten stellt das System sicher, dass jeder Teil des Problems von einer KI bearbeitet wird, die speziell für diesen Bereich trainiert wurde, wodurch die Wahrscheinlichkeit fehlerhafter oder kontextfremder Antworten minimiert wird. - Verbesserte Genauigkeit und Kontextverständnis: Multiplexing-KI-Agenten tragen zu einer verbesserten Gesamtgenauigkeit bei, indem sie Aufgaben an Modelle verteilen, die besser auf bestimmte Kontexte oder Themen abgestimmt sind. Dieser Ansatz stellt sicher, dass das KI-System die Nuancen einer Anfrage besser verstehen und bearbeiten kann, insbesondere wenn die Eingabe komplexe oder hochspezialisierte Informationen enthält. Die intensive Konzentration jedes Agenten auf eine bestimmte Aufgabe führt zu einer höheren Präzision und damit zu einem genaueren Endergebnis.
Darüber hinaus ermöglicht Multiplexing dem System ein detaillierteres Verständnis des Kontexts. Da verschiedene Agenten für unterschiedliche Elemente einer Aufgabe verantwortlich sind, kann das System detailliertere und kontextbezogene Antworten zusammenstellen. Diese ganzheitliche Sichtweise ist entscheidend, um sicherzustellen, dass die bereitgestellte Lösung nicht nur korrekt ist, sondern auch für die spezifische Situation des Benutzers relevant ist.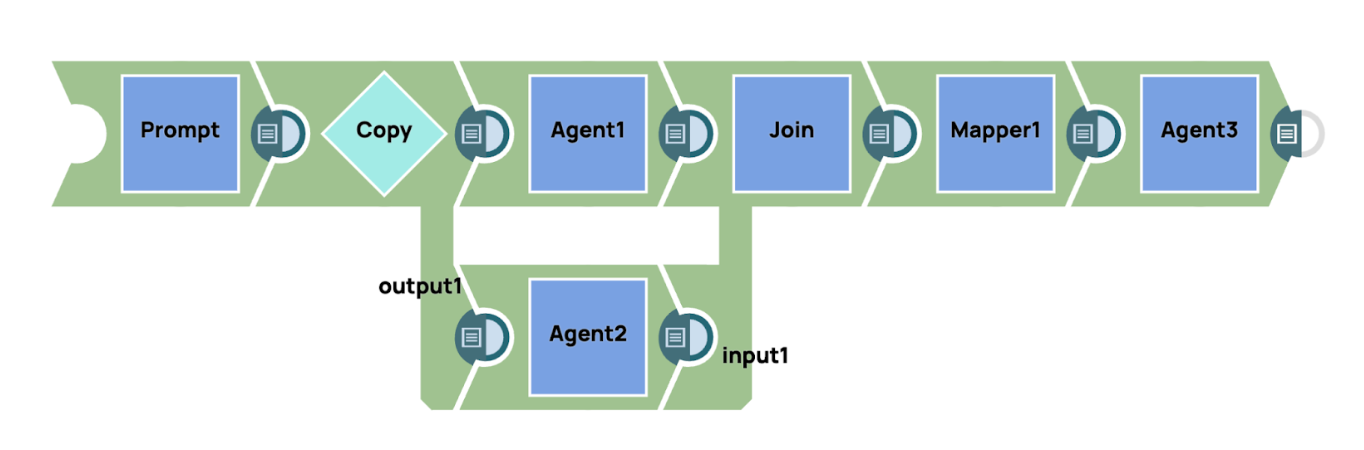
In SnapLogic bieten wir umfassende Unterstützung für die Erstellung fortschrittlicher Workflows durch die Integration unseres GenAI Builder Snap. Mit dieser Funktion können Benutzer generative KI-Funktionen nahtlos in ihre Workflow-Automatisierungsprozesse integrieren. Durch die Nutzung des GenAI Builder Snap können Benutzer die Leistungsfähigkeit künstlicher Intelligenz nutzen, um komplexe Entscheidungsfindungs-, Datenverarbeitungs- und Inhaltsgenerierungsaufgaben innerhalb ihrer bestehenden Workflows zu automatisieren. Diese Integration bietet einen optimierten Ansatz für die Einbettung KI-gesteuerter Funktionen und verbessert sowohl die Effizienz als auch die Präzision in verschiedenen Betriebsbereichen. Beispielsweise können Benutzer Workflows entwerfen, in denen der GenAI Builder Snap mit anderen SnapLogic-Komponenten wie Datenpipelines und Transformationsprozessen zusammenarbeitet, um eine intelligente, kontextbezogene Automatisierung zu liefern, die auf ihre individuellen Geschäftsanforderungen zugeschnitten ist.
In den Beispiel-Pipelines sendet das System gleichzeitig eine Eingabeaufforderung an mehrere KI-Agenten, von denen jeder über ein spezielles Fachgebiet verfügt. Diese Agenten verarbeiten unabhängig voneinander die spezifischen Aspekte der Eingabeaufforderung, die mit ihrem Fachgebiet zusammenhängen. Sobald die Agenten ihre jeweiligen Ergebnisse generiert haben, werden diese zu einer zusammenhängenden Antwort zusammengefügt. Um die Klarheit und Prägnanz des Endergebnisses weiter zu verbessern, wird ein Zusammenfassungsagent eingesetzt. Dieser Zusammenfassungsagent aggregiert und verfeinert die detaillierten Antworten der einzelnen spezialisierten Agenten und destilliert die Informationen zu einer prägnanten, einheitlichen Zusammenfassung, die die wichtigsten Punkte aller Agenten erfasst und so eine kohärente und gut strukturierte endgültige Antwort gewährleistet.
5. Multi-Agenten-Konversation
Multi-Agenten-Konversation bezieht sich auf die Interaktion und Kommunikation zwischen mehreren autonomen Agenten, in der Regel KI-Systemen, die zusammenarbeiten, um ein gemeinsames Ziel zu erreichen. Dieses Framework wird häufig in Bereichen wie kollaborativer Problemlösung, Multi-User-Systemen und komplexer Aufgabenkoordination eingesetzt, in denen mehrere Perspektiven oder Fachgebiete erforderlich sind. Im Gegensatz zu einer Single-Agent-Konversation, bei der eine KI alle Ein- und Ausgänge verarbeitet, verteilt ein Multi-Agent-System die Aufgaben auf mehrere spezialisierte Agenten, was eine höhere Effizienz, ein tieferes Kontextverständnis und verbesserte Problemlösungsfähigkeiten ermöglicht. Hier sind die wichtigsten Merkmale der Verwendung von Multi-Agent-Konversationen.
- Spezialisierung und Fachwissen: Jeder Agent in einem Multi-Agenten-System ist für eine bestimmte Rolle oder einen bestimmten Fachbereich ausgelegt. Dadurch kann das System Agenten mit speziellen Fähigkeiten einsetzen, um verschiedene Aspekte einer Aufgabe zu bewältigen. Beispielsweise kann sich ein Agent auf die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) konzentrieren, um Eingaben zu verstehen, während ein anderer komplexe Berechnungen durchführt oder Daten aus externen Quellen abruft. Diese Arbeitsteilung stellt sicher, dass Aufgaben von den fähigsten Agenten bearbeitet werden, was zu genaueren und effizienteren Ergebnissen führt. Spezialisierung verringert die Fehlerwahrscheinlichkeit und ermöglicht ein tieferes, domänenspezifisches Verständnis des Problems.
- Zusammenarbeit und Koordination: In einer Multi-Agenten-Konversation arbeiten Agenten nicht isoliert, sondern arbeiten zusammen, um ein gemeinsames Ziel zu erreichen. Jeder Agent trägt mit seinen Ergebnissen zur Gesamtkonversation bei, tauscht Informationen aus und koordiniert Maßnahmen, um sicherzustellen, dass die Gesamtaufgabe erfolgreich abgeschlossen wird. Diese Zusammenarbeit ist entscheidend bei der Bewältigung komplexer Probleme, die Beiträge aus mehreren Bereichen erfordern. Eine effektive Koordination stellt sicher, dass Agenten keine Doppelarbeit leisten oder Konflikte verursachen. Durch vordefinierte Protokolle oder Verhandlungsmechanismen sind Agenten in der Lage, harmonisch zusammenzuarbeiten und eine kohärente Lösung zu erarbeiten, die ihre verschiedenen Beiträge integriert.
- Skalierbarkeit: Multi-Agenten-Systeme sind von Natur aus skalierbar und eignen sich daher ideal für die Bewältigung immer komplexerer Aufgaben. Wenn das System an Komplexität zunimmt oder vor neuen Herausforderungen steht, können zusätzliche Agenten mit spezifischen Fähigkeiten eingeführt werden, ohne das System zu überlasten. Jeder Agent kann unabhängig arbeiten, und der modulare Aufbau des Systems ermöglicht eine reibungslose Erweiterung. Die Skalierbarkeit stellt sicher, dass das System mit der Weiterentwicklung der Umgebung größere Datensätze, vielfältigere Eingaben oder komplexere Aufgaben bewältigen kann. Diese Anpassungsfähigkeit ist in dynamischen Umgebungen, in denen sich Arbeitslasten oder Anforderungen im Laufe der Zeit ändern, von entscheidender Bedeutung.
- Verteilte Entscheidungsfindung: In einem Multi-Agenten-System ist die Entscheidungsfindung oft dezentralisiert, was bedeutet, dass jeder Agent die Autonomie hat, Entscheidungen auf der Grundlage seines Fachwissens und der ihm zur Verfügung stehenden Informationen zu treffen. Dieser verteilte Entscheidungsprozess ermöglicht es den Agenten, Aufgaben parallel zu bearbeiten, ohne dass eine ständige Überwachung durch eine zentrale Steuerung erforderlich ist. Da die Agenten unabhängig voneinander arbeiten können, werden Entscheidungen schneller getroffen und Engpässe vermieden. Dieser dezentrale Ansatz erhöht auch die Ausfallsicherheit des Systems, da er eine übermäßige Abhängigkeit von einem einzigen Entscheidungspunkt vermeidet und eine anpassungsfähigere und lokalisierte Problemlösung ermöglicht.
- Fehlertoleranz und Redundanz: Multi-Agenten-Systeme sind von Natur aus widerstandsfähig gegen Fehler und Ausfälle. Da jeder Agent unabhängig arbeitet, stört der Ausfall eines Agenten nicht das gesamte System. Andere Agenten können ihre Aufgaben fortsetzen oder bei Bedarf die Arbeit eines ausgefallenen Agenten übernehmen. Diese integrierte Redundanz stellt sicher, dass das System auch dann weiter funktioniert, wenn einige Agenten Probleme haben. Fehlertoleranz ist besonders in komplexen Systemen von großem Wert, da sie die Zuverlässigkeit erhöht und Ausfallzeiten minimiert, sodass das System auch unter widrigen Bedingungen seine Leistung aufrechterhalten kann.
SnapLogic bietet leistungsstarke Funktionen für die Integration von Workflow-Automatisierung mit generativer KI (GenAI), sodass Benutzer nahtlos fortschrittliche Multi-Agent-Konversationssysteme erstellen können, indem sie den GenAI Snap mit anderen Snaps innerhalb ihrer Pipeline kombinieren. Diese Integration ermöglicht es Benutzern, komplexe Workflows zu erstellen, in denen mehrere KI-Agenten mit jeweils unterschiedlichen Spezialisierungen zusammenarbeiten, um komplexe Anfragen und Aufgaben zu bearbeiten.
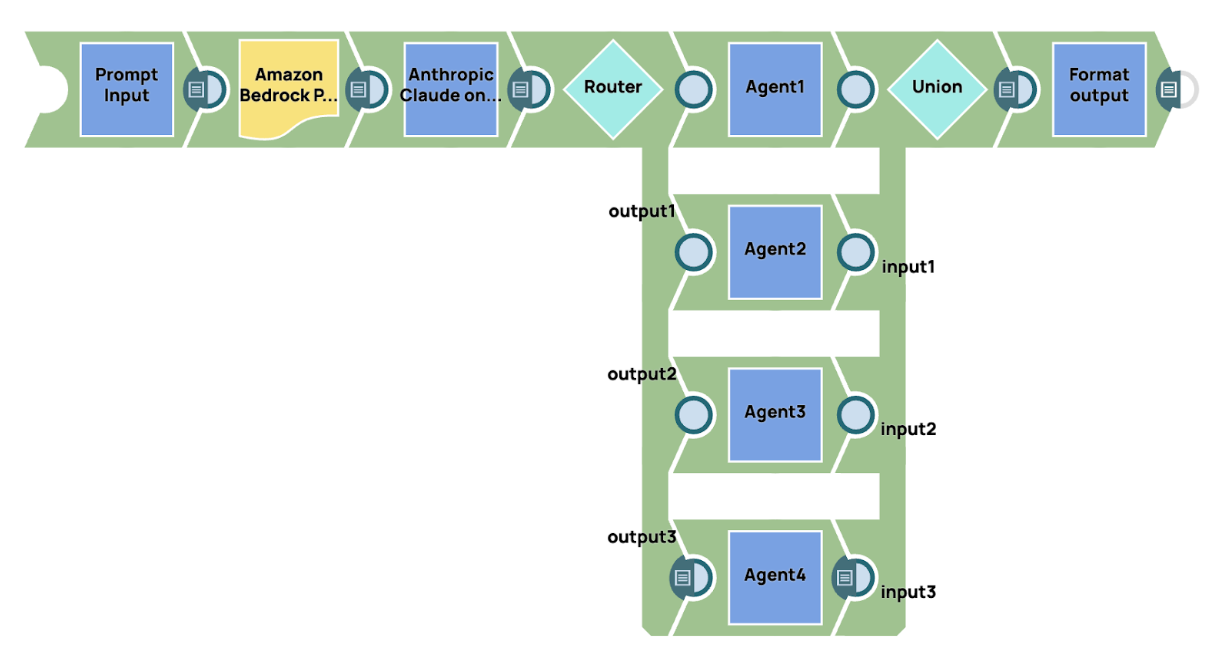
In diesem Beispiel zeigen wir eine einfache Implementierung eines Multi-Agenten-Konversationssystems, bei dem ein Manager-Agent den Arbeitsablauf überwacht und steuert. Der Prozess beginnt mit der Übermittlung einer Eingabeaufforderung an ein großes Basismodell, in diesem Fall AWS Claude 3 Sonet. Dieses Modell fungiert als Manager-Agent, der für die Interpretation der Eingabeaufforderung und die Festlegung der geeigneten Weiterleitung für verschiedene Teile der Aufgabe verantwortlich ist. Basierend auf dem Inhalt und Kontext der Eingabeaufforderung trifft der Manager-Agent Entscheidungen darüber, wie die Arbeitslast auf spezialisierte Agenten verteilt wird.
Nachdem die erste Eingabeaufforderung verarbeitet wurde, verwenden wir den Router Snap, um die Ausgabe dynamisch an die entsprechenden spezialisierten Agenten weiterzuleiten. Jeder Agent ist auf einen bestimmten Bereich oder eine bestimmte Aufgabe zugeschnitten, wie z. B. Datenanalyse, Verarbeitung natürlicher Sprache oder Wissensabruf, um sicherzustellen, dass jeder Teil der Anfrage vom relevantesten und spezialisiertesten Agenten bearbeitet wird.
Sobald die spezialisierten Agenten ihre jeweiligen Aufgaben erledigt haben, werden ihre Ergebnisse gesammelt und konsolidiert. Das System sendet dann das endgültige, aggregierte Ergebnis an den Ausgabezielort. Dieser Ansatz stellt sicher, dass alle Aspekte der Anfrage effizient und genau behandelt werden, wobei jeder Agent sein Fachwissen zur Gesamtlösung beiträgt.
Die Flexibilität der SnapLogic-Plattform in Kombination mit der Integration von GenAI-Modellen und Snaps erleichtert es Anwendern, komplexe Multi-Agent-Konversationsworkflows zu entwerfen, zu skalieren und zu optimieren. Durch die Automatisierung der Aufgabenverteilung und der Zusammenarbeit zwischen Agenten ermöglicht SnapLogic intelligentere, skalierbarere und kontextsensitive Lösungen für eine Vielzahl von Anwendungsfällen, von der Automatisierung des Kundenservice bis hin zur erweiterten Datenverarbeitung.
6. Retrieval Augment Generation (RAG)
Um die Spezifität und Relevanz der von einem generativen KI-Modell (GenAI) generierten Antworten zu verbessern, ist es entscheidend, dem Modell ausreichend Kontext zur Verfügung zu stellen. Kontextinformationen helfen dem Modell, die Nuancen der jeweiligen Aufgabe zu verstehen, sodass es genauere und aussagekräftigere Ergebnisse generieren kann. In vielen Fällen übersteigt jedoch die Menge an Kontext, die erforderlich ist, um das Modell vollständig zu informieren, die Token-Grenze, die das Modell in einer einzigen Eingabe verarbeiten kann. Hier kommt eine Technik namens Retrieval-Augmented Generation (RAG) zum Einsatz, die besonders wertvoll ist.
RAG wurde entwickelt, um die Art und Weise zu optimieren, wie Kontext in das GenAI-Modell eingespeist wird. Anstatt zu versuchen, alle notwendigen Informationen in den begrenzten Eingaberaum zu packen, nutzt RAG einen Abrufmechanismus, der relevante Informationen dynamisch aus einer externen Wissensdatenbank bezieht. Dieser Ansatz ermöglicht es Benutzern, die Herausforderung der Token-Begrenzung zu überwinden, indem nur die relevantesten Informationen zum Zeitpunkt der Abfrageerstellung abgerufen werden, wodurch sichergestellt wird, dass der dem Modell bereitgestellte Kontext fokussiert und prägnant bleibt.
Das RAG-Framework lässt sich in zwei Hauptphasen unterteilen:
- Einbetten von Wissen in eine Vektordatenbank: In der Anfangsphase werden die relevanten Inhalte mithilfe eines maschinellen Lernmodells, das Textdaten in ein für Ähnlichkeitsabgleiche geeignetes Format umwandelt, in einen Vektorraum eingebettet. Dieser Einbettungsprozess wandelt Text effektiv in Vektoren um, wodurch er später anhand seiner semantischen Bedeutung leichter gespeichert und abgerufen werden kann. Nach der Einbettung wird das Wissen in einer Vektordatenbank gespeichert, um später darauf zugreifen zu können.
 In SnapLogic kann das Einbetten von Wissen in eine Vektordatenbank über eine optimierte Pipeline erfolgen, die auf Effizienz und Skalierbarkeit ausgelegt ist. Der Prozess beginnt mit dem Lesen einer PDF-Datei mithilfe der Datei-Reader-Snap, gefolgt vom Extrahieren des Inhalts mit dem PDF-Parser-Snap, das das Dokument in ein strukturiertes Textformat umwandelt. Sobald der Text verfügbar ist, wird der Chunker-Schnappverschluss wird verwendet, um den Inhalt intelligent in kleinere, überschaubare Einheiten zu segmentieren. Diese Einheiten sind speziell auf die Eingabebeschränkungen des Modells abgestimmt, um eine optimale Leistung in späteren Phasen der Abfrage zu gewährleisten.
In SnapLogic kann das Einbetten von Wissen in eine Vektordatenbank über eine optimierte Pipeline erfolgen, die auf Effizienz und Skalierbarkeit ausgelegt ist. Der Prozess beginnt mit dem Lesen einer PDF-Datei mithilfe der Datei-Reader-Snap, gefolgt vom Extrahieren des Inhalts mit dem PDF-Parser-Snap, das das Dokument in ein strukturiertes Textformat umwandelt. Sobald der Text verfügbar ist, wird der Chunker-Schnappverschluss wird verwendet, um den Inhalt intelligent in kleinere, überschaubare Einheiten zu segmentieren. Diese Einheiten sind speziell auf die Eingabebeschränkungen des Modells abgestimmt, um eine optimale Leistung in späteren Phasen der Abfrage zu gewährleisten.
Nach der Aufteilung des Textes in Segmente wird jedes Segment verarbeitet und in eine Vektordarstellung eingebettet, die dann in der Vektordatenbank gespeichert wird. Dies ermöglicht eine effiziente, auf Ähnlichkeit basierende Suche, sodass das System bei Bedarf schnell auf relevante Informationen zugreifen kann. Durch die Verwendung dieser Pipeline in SnapLogic können Benutzer große Wissensmengen auf eine Weise verwalten und speichern, die leistungsstarke, kontextgesteuerte KI-Anwendungen unterstützt. - Kontextabruf durch Ähnlichkeitsabgleich: Wenn eine Anfrage eingeht, führt das System einen Ähnlichkeitsabgleich durch, um die relevantesten Inhalte aus der Vektordatenbank abzurufen. Durch die Bewertung der Ähnlichkeit zwischen der eingebetteten Anfrage und den gespeicherten Vektoren identifiziert RAG die relevantesten Informationen, die dann zur Ergänzung der Eingabeaufforderung verwendet werden. Dieser Schritt stellt sicher, dass das GenAI-Modell fokussierte und kontextuell angereicherte Daten erhält, wodurch es aufschlussreichere und genauere Antworten generieren kann.

Um relevante Kontextinformationen aus der Vektordatenbank in SnapLogic abzurufen, können Benutzer eine Einbettungs-Snap, wie beispielsweise die AWS Titan Einbettungsprogramm, um die eingehende Eingabeaufforderung in eine Vektordarstellung umzuwandeln. Dieser Vektor dient als Schlüssel für die Durchführung einer ähnlichkeitsbasierten Suche innerhalb der Vektordatenbank, in der das zuvor eingebettete Wissen gespeichert ist. Der Vektorsuchmechanismus identifiziert effizient die relevantesten Informationen und stellt sicher, dass nur die kontextuell am besten passenden Inhalte abgerufen werden.
Sobald das relevante Wissen abgerufen wurde, kann es nahtlos in den gesamten Prozess der Prompt-Generierung integriert werden. Dies wird in der Regel erreicht, indem der abgerufene Kontext in eine Promptgenerator snap, das die Informationen in einem für die Verwendung durch das generative KI-Modell optimierten Format strukturiert. In diesem Fall wird die endgültige Eingabeaufforderung, angereichert mit dem relevanten Kontext, an das GenAI-Schnappschuss, wie zum Beispiel Anthropischer Claude innerhalb der AWS-Nachrichten-SnapDieser Ansatz stellt sicher, dass das Modell hochspezifische und relevante Informationen erhält, wodurch letztlich die Genauigkeit und Relevanz der generierten Antworten verbessert wird.
Durch die Implementierung von RAG können Nutzer das Potenzial von GenAI-Modellen voll ausschöpfen, selbst bei komplexen Abfragen, die einen erheblichen Kontext erfordern. Dieser Ansatz verbessert nicht nur die Genauigkeit der Antworten des Modells, sondern stellt auch sicher, dass das Modell effizient und skalierbar bleibt, was es zu einem leistungsstarken Werkzeug für eine Vielzahl von Anwendungen in der Praxis macht.
7. Toolaufruf und kontextbezogene Anweisungen
Herkömmliche GenAI-Modelle sind durch die Daten begrenzt, mit denen sie trainiert wurden. Nach dem Training können diese Modelle nicht auf neue oder aktualisierte Informationen zugreifen, es sei denn, sie werden neu trainiert. Diese Einschränkung bedeutet, dass Modelle ohne externe Eingaben nur Antworten generieren können, die auf den statischen Inhalten ihres Trainingskorpus basieren. In einer Welt, in der sich Daten ständig weiterentwickeln, ist es jedoch oft unzureichend, sich auf statisches Wissen zu verlassen, insbesondere bei Aufgaben, die aktuelle oder Echtzeitinformationen erfordern. In vielen realen Anwendungen benötigen generative KI-Modelle (GenAI) Zugriff auf Echtzeitdaten, um kontextbezogene, genaue und relevante Antworten zu generieren. Wenn ein Benutzer beispielsweise nach dem aktuellen Wetter an einem bestimmten Ort fragt, kann sich das Modell nicht ausschließlich auf vorab trainiertes Wissen stützen, da diese Daten dynamisch sind und sich ständig ändern. In solchen Szenarien sind traditionelle Prompt-Engineering-Techniken unzureichend, da sie sich in erster Linie auf statische Informationen stützen, die zum Zeitpunkt des Modelltrainings verfügbar waren. Hier kommt die Tool-Calling-Technik ins Spiel.
Tool Calling bezeichnet die Fähigkeit eines GenAI-Modells, mit externen Tools, APIs oder Datenbanken zu interagieren, um bestimmte Informationen in Echtzeit abzurufen. Anstatt sich auf sein internes Wissen zu verlassen, das möglicherweise veraltet oder unvollständig ist, kann das Modell aktuelle Daten aus externen Quellen anfordern und diese verwenden, um eine Antwort zu generieren, die sowohl genau als auch kontextuell relevant ist. Dieser Prozess erweitert die Fähigkeiten von GenAI erheblich und ermöglicht es ihm, über statische, vortrainierte Inhalte hinauszugehen und dynamische Daten aus der realen Welt in seine Antworten einzubeziehen.
Wenn ein Benutzer beispielsweise nach aktuellen Wetterdaten, Börsenkursen oder Verkehrsinformationen fragt, kann das GenAI-Modell einen Tool-Aufruf an eine externe API – beispielsweise einen Wetterdienst, einen Finanzdatenanbieter oder einen Kartendienst – auslösen, um die erforderlichen Daten abzurufen. Diese abgerufenen Daten werden dann in die Antwort des Modells integriert, sodass es eine genaue und zeitnahe Antwort geben kann, die mit statischen Eingabeaufforderungen allein nicht möglich gewesen wäre.
Kontextbezogene Anweisungen spielen beim Aufruf von Tools eine entscheidende Rolle. Bevor ein externes Tool aufgerufen wird, muss das GenAI-Modell die Art der Anfrage des Benutzers verstehen und erkennen, wann externe Daten benötigt werden. Wenn ein Benutzer beispielsweise fragt: „Wie ist das Wetter derzeit in Paris?“, erkennt das Modell, dass die Frage Echtzeit-Wetterinformationen erfordert und dass diese nicht allein auf der Grundlage interner Kenntnisse beantwortet werden kann. Das Modell ist daher so programmiert, dass es einen Tool-Aufruf an eine relevante Wetterdienst-API auslöst, die Live-Wetterdaten für Paris abruft und diese in die endgültige Antwort einbezieht. Diese Fähigkeit, zwischen statischem Wissen (das mit vorab trainierten Daten beantwortet werden kann) und dynamischen Echtzeitinformationen (die den Aufruf externer Tools erfordern) zu unterscheiden, ist für GenAI-Modelle unerlässlich, um in komplexen, realen Umgebungen effektiv zu arbeiten.
Anwendungsfälle für Tool Calling
- Echtzeit-Datenabruf: GenAI-Modelle können externe APIs aufrufen, um Echtzeitdaten wie Wetterbedingungen, Aktienkurse, aktuelle Nachrichten oder Live-Sportergebnisse abzurufen. Diese Tool-Aufrufe stellen sicher, dass die KI aktuelle und genaue Antworten liefert, die die neuesten Informationen widerspiegeln.
- Komplexe Berechnungen und spezialisierte Aufgaben: Durch den Aufruf von Tools können KI-Modelle Aufgaben bewältigen, die spezifische Berechnungen oder Fachwissen erfordern. So kann beispielsweise ein KI-Modell, das eine Finanzanfrage bearbeitet, ein externes Finanzanalyse-Tool aufrufen, um komplexe Berechnungen durchzuführen oder historische Börsendaten abzurufen.
- Integration in Unternehmenssysteme: In Geschäftsumgebungen können GenAI-Modelle mit externen Systemen wie CRM-Plattformen, ERP-Systemen oder Datenbanken interagieren, um Informationen in Echtzeit abzurufen oder zu aktualisieren. Beispielsweise kann ein GenAI-gesteuerter Kundendienst-Bot Kontoinformationen aus einem CRM-System abrufen oder den Status von Bestellungen in einem externen Bestellverwaltungstool überprüfen.
- Zugang zu Fachwissen: Durch Tool-Aufrufe können KI-Modelle Fachinformationen aus Datenbanken oder Wissensspeichern abrufen, die außerhalb ihres Trainingsbereichs liegen. Beispielsweise könnte ein medizinischer KI-Assistent eine externe Datenbank mit medizinischen Forschungsarbeiten aufrufen, um die aktuellsten Behandlungsmöglichkeiten für eine bestimmte Erkrankung bereitzustellen.
Implementierung von Tool Calling in generativen KI-Systemen
Das Aufrufen von Tools ist zu einer integralen Funktion in vielen fortschrittlichen generativen KI-Modellen (GenAI) geworden, wodurch diese ihre Funktionalität durch die Interaktion mit externen Systemen und Diensten erweitern können. Beispielsweise unterstützt AWS Anthropic Claude das Aufrufen von Tools über die Message API und bietet Entwicklern damit eine strukturierte Möglichkeit, externe Daten und Funktionen direkt in den Antwort-Workflow des Modells zu integrieren. Dank dieser Funktion kann das Modell seine Antworten verbessern, indem es Echtzeitinformationen einbezieht, bestimmte Funktionen ausführt oder externe APIs nutzt, die über das Training des Modells hinausgehende Spezialdaten bereitstellen.
Um den Tool-Aufruf mit AWS Anthropic Claude zu implementieren, können Benutzer die Message API nutzen, die eine nahtlose Integration mit externen Systemen ermöglicht. Der Tool-Aufrufmechanismus wird durch das Senden einer Nachricht mit einem bestimmten „tools”-Parameter aktiviert. Dieser Parameter definiert, wie das externe Tool oder die API aufgerufen wird, wobei ein JSON-Schema zur Strukturierung des Funktionsaufrufs verwendet wird. Dieser Ansatz ermöglicht es dem GenAI-Modell, zu erkennen, wann externe Eingaben erforderlich sind, und einen Tool-Aufruf auf der Grundlage der bereitgestellten Anweisungen zu initiieren.
Implementierungsprozess
- Definition des WerkzeugschemasUm einen Tool-Aufruf zu initiieren, müssen Benutzer eine Anfrage mit dem „Werkzeuge“ Parameter. Dieser Parameter ist in einem strukturierten JSON-Schema definiert, das Details zu dem externen Tool oder der API enthält, die das GenAI-Modell aufrufen wird. Das JSON-Schema beschreibt, wie das Tool verwendet werden soll, einschließlich des Funktionsnamens, der Parameter und aller erforderlichen Eingaben für den Aufruf.

Wenn es sich bei dem Tool beispielsweise um eine Wetter-API handelt, könnte das Schema Parameter wie Standort und Zeit definieren, sodass das Modell die API mit diesen Eingaben abfragen kann, um aktuelle Wetterdaten abzurufen.
- Nachrichtenstruktur und Anforderungsinitiierung: Sobald das Tool-Schema definiert ist, kann der Benutzer eine Nachricht an AWS Anthropic Claude senden, die neben der Eingabeaufforderung oder Abfrage den Parameter „tools” enthält. Das Modell interpretiert dann die Anfrage und bestimmt anhand des Kontexts der Konversation oder Aufgabe, ob es das im Schema angegebene externe Tool aufrufen muss. Wenn ein Tool-Aufruf erforderlich ist, antwortet das Modell mit einem „stop_reason”-Wert von „tool_use”. Diese Antwort zeigt an, dass das Modell seine Generierung unterbricht, um das externe Tool aufzurufen, anstatt die Antwort nur mit seinem internen Wissen zu vervollständigen.
- Tool-Aufrufausführung: Wenn das Modell mit „stop_reason”: „tool_use” antwortet, signalisiert dies, dass die externe API oder Funktion mit den bereitgestellten Eingaben aufgerufen werden soll. An diesem Punkt wird die externe API (wie im JSON-Schema angegeben) ausgelöst, um die erforderlichen Daten abzurufen oder die festgelegte Aufgabe auszuführen. Wenn der Benutzer beispielsweise fragt: „Wie ist das Wetter gerade in New York?“, und das JSON-Schema ein Wetter-API-Tool definiert, pausiert das Modell und ruft die API mit dem Standortparameter „New York“ und dem Zeitparameter „aktuell“ auf.
- Verarbeitung der API-Antwort: Nachdem das externe Tool die Anfrage verarbeitet und das Ergebnis zurückgegeben hat, sendet der Benutzer (oder das System) eine Folge-Nachricht mit dem „tool_result“. Diese Nachricht enthält die Ausgabe des Tool-Aufrufs, die dann in die laufende Konversation oder Aufgabe integriert werden kann. In der Praxis könnte dies beispielsweise eine Wetter-API sein, die ein JSON-Objekt mit Temperatur, Luftfeuchtigkeit und Wetterbedingungen zurückgibt. Die Antwort wird über eine Benutzernachricht, die die „tool_result“-Daten enthält, an das GenAI-Modell zurückgegeben.
- Erstellung der endgültigen Antwort: Sobald das Modell das „tool_result” erhält, verarbeitet es die Daten und erstellt die Antwort. Auf diese Weise kann das GenAI-Modell eine endgültige Antwort liefern, die Echtzeit- oder Spezialinformationen aus dem externen System enthält. In unserem Wetterbeispiel könnte die endgültige Antwort lauten: „Das aktuelle Wetter in New York ist 22 °C bei klarem Himmel.”
Derzeit bietet SnapLogic noch keine native Unterstützung für Tool-Aufrufe innerhalb des GenAI Snap Pack. Wir sind uns jedoch des immensen Potenzials und Nutzens dieser Funktion für die Anwender bewusst, da sie eine nahtlose Integration mit externen Systemen und Diensten für Echtzeitdaten und erweiterte Funktionen ermöglicht. Wir arbeiten aktiv daran, Tool-Aufruf-Funktionen in zukünftige Updates der Plattform zu integrieren. Diese Verbesserung wird die Anwender in die Lage versetzen, dynamischere und intelligentere Workflows zu erstellen und damit die Möglichkeiten der Automatisierung und KI-gesteuerter Lösungen zu erweitern. Wir sind begeistert von dem Potenzial, das darin steckt, und freuen uns darauf, diese Innovationen bald vorstellen zu können.
8. Gedächtniswahrnehmung für LLMs
Die meisten großen Sprachmodelle (LLMs) arbeiten innerhalb einer Kontextfensterbeschränkung, was bedeutet, dass sie zu einem bestimmten Zeitpunkt nur eine begrenzte Anzahl von Tokens (Wörtern, Phrasen oder Symbolen) verarbeiten und analysieren können. Diese Beschränkung stellt eine erhebliche Herausforderung dar, insbesondere bei komplexen Aufgaben, längeren Dialogen oder Interaktionen, die ein langfristiges Kontextverständnis erfordern. Wenn beispielsweise eine Konversation oder Aufgabe über die Token-Grenze hinausgeht, verliert das Modell das Bewusstsein für frühere Teile der Interaktion, was zu Antworten führen kann, die unzusammenhängend, repetitiv oder kontextuell irrelevant sind.
Diese Einschränkung wird besonders problematisch in Anwendungen, in denen die Aufrechterhaltung von Kontinuität und Kohärenz über lange Interaktionen hinweg entscheidend ist. In Kundendienstszenarien, Projektmanagement-Tools oder Bildungsanwendungen ist es oft notwendig, sich detaillierte Informationen aus früheren Gesprächen zu merken oder den Fortschritt im Laufe der Zeit zu verfolgen. Traditionelle Modelle, die durch ein festes Token-Fenster eingeschränkt sind, haben jedoch Schwierigkeiten, in solchen Situationen relevant zu bleiben, da sie sich frühere Teile der Konversation nicht „merken“ oder darauf zugreifen können, sobald das Kontextfenster überschritten ist.
Um diese Einschränkungen zu beheben und LLMs in die Lage zu versetzen, längere und komplexere Interaktionen zu verarbeiten, setzen wir eine Technik ein, die als Gedächtniskognition bekannt ist. Diese Technik erweitert die Fähigkeiten von LLMs durch die Einführung von Mechanismen, die es dem Modell ermöglichen, vergangene Interaktionen oder Informationen zu speichern, abzurufen und dynamisch zu integrieren, selbst wenn diese Interaktionen außerhalb des unmittelbaren Kontextfensters liegen.
Komponenten der Gedächtniswahrnehmung in generativen KI-Anwendungen
Um die Gedächtniswahrnehmung in Generative-AI-Anwendungen (GenAI) erfolgreich zu implementieren, ist ein umfassender und strukturierter Ansatz erforderlich. Dazu gehört die Integration verschiedener Gedächtniskomponenten, die zusammenarbeiten, damit das KI-System relevante Informationen über verschiedene Interaktionen hinweg speichern, abrufen und nutzen kann. Die Gedächtniswahrnehmung ermöglicht es dem KI-Modell, über die zustandslose, kurzfristige Verarbeitung hinauszugehen und ein kontextbewussteres, anpassungsfähigeres und intelligenteres System zu schaffen, das zu langfristiger Interaktion und Entscheidungsfindung fähig ist. Hier sind die wichtigsten Komponenten der Gedächtniskognition, die bei der Entwicklung einer GenAI-Anwendung berücksichtigt werden müssen:
- Kurzzeitgedächtnis (Sitzungsgedächtnis)
Das Kurzzeitgedächtnis, allgemein als Sitzungsgedächtnis bezeichnet, umfasst die Fähigkeit des Modells, Kontext und Informationen während einer einzelnen Interaktion oder Sitzung zu speichern. Diese Komponente ist für die Aufrechterhaltung der Kohärenz in mehrteiligen Gesprächen und kurzfristigen Aufgaben von entscheidender Bedeutung. Sie ermöglicht es dem Modell, die Kontinuität seiner Antworten aufrechtzuerhalten, indem es auf frühere Teile des Gesprächs Bezug nimmt und so verhindert, dass der Benutzer zuvor bereitgestellte Informationen wiederholen muss.
In der Regel ist das Kurzzeitgedächtnis auf die Dauer der Interaktion beschränkt. Sobald die Sitzung beendet ist oder eine neue Sitzung beginnt, wird das Gedächtnis entweder zurückgesetzt oder allmählich abgebaut. Dadurch wird sichergestellt, dass das Modell relevante Details aus früheren Teilen derselben Sitzung abrufen kann, was zu einem nahtloseren und flüssigeren Gesprächserlebnis führt. In einem Kundenservice-Chatbot beispielsweise ermöglicht das Kurzzeitgedächtnis der KI, sich während des gesamten Gesprächs an das Problem eines Kunden zu erinnern, sodass das Problem konsequent behandelt wird, ohne dass der Benutzer es mehrfach wiederholen muss.
In großen Sprachmodellen ist das Kurzzeitgedächtnis jedoch häufig durch das Kontextfenster des Modells begrenzt, das durch die maximale Anzahl von Tokens eingeschränkt ist, die es in einer einzigen Eingabe verarbeiten kann. Wenn während des Gesprächs neue Eingaben hinzukommen, können ältere Dialogteile je nach Token-Limit verworfen oder vergessen werden. Dies erfordert eine sorgfältige Verwaltung des Kurzzeitgedächtnisses, um sicherzustellen, dass wichtige Informationen während der gesamten Sitzung erhalten bleiben. - Langzeitgedächtnis-
Das Langzeitgedächtnis verbessert die Leistungsfähigkeit des Modells erheblich, da es Informationen über den Rahmen einer einzelnen Sitzung hinaus speichern kann. Im Gegensatz zum Kurzzeitgedächtnis, das auf eine einzelne Interaktion beschränkt ist, bleibt das Langzeitgedächtnis über mehrere Interaktionen hinweg bestehen, sodass die KI wichtige Informationen über Benutzer, deren Präferenzen, vergangene Gespräche oder aufgabenspezifische Details abrufen kann, unabhängig von der zwischen den Sitzungen verstrichenen Zeit. Diese Art von Gedächtnis wird in der Regel in einer externen Datenbank oder einem Wissensspeicher gespeichert, wodurch sichergestellt wird, dass es über einen längeren Zeitraum zugänglich bleibt und nicht nach Beendigung einer Sitzung verfällt.
Das Langzeitgedächtnis ist besonders wertvoll in Anwendungen, die die Speicherung kritischer oder personalisierter Informationen erfordern, wie z. B. Benutzerpräferenzen, Verlauf oder wiederkehrende Aufgaben. Es ermöglicht hochgradig personalisierte Interaktionen, da die KI auf gespeicherte Informationen zurückgreifen kann, um ihre Antworten auf der Grundlage der früheren Interaktionen des Benutzers anzupassen. In Anwendungen mit virtuellen Assistenten beispielsweise ermöglicht das Langzeitgedächtnis der KI, sich die Präferenzen eines Benutzers zu merken – wie seine Lieblingsmusik oder regelmäßige Terminzeiten – und diese Informationen zu nutzen, um maßgeschneiderte Antworten und Empfehlungen zu geben.
In Unternehmensumgebungen, wie z. B. Kundensupportsystemen, ermöglicht das Langzeitgedächtnis der KI, auf frühere Probleme oder Anfragen desselben Benutzers zurückzugreifen, sodass sie fundiertere und maßgeschneiderte Hilfe anbieten kann. Diese Fähigkeit verbessert die Benutzererfahrung, indem sie die Notwendigkeit von Wiederholungen reduziert und die Gesamteffizienz und -effektivität der Interaktion verbessert. Das Langzeitgedächtnis spielt daher eine entscheidende Rolle dabei, KI-Systemen zu ermöglichen, konsistente, kontextbezogene und personalisierte Antworten über mehrere Sitzungen hinweg zu liefern. - Speicherverwaltung
Dynamische Speicherverwaltung bezieht sich auf die Fähigkeit des KI-Modells, gespeicherte Informationen intelligent zu verwalten und zu priorisieren, indem es kontinuierlich anpasst, was aufgrund seiner Relevanz für die jeweilige Aufgabe beibehalten, verworfen oder abgerufen wird. Diese Fähigkeit ist entscheidend für die Optimierung der kurz- und langfristigen Speichernutzung, um sicherzustellen, dass das Modell reaktionsschnell und effizient bleibt, ohne durch irrelevante oder veraltete Informationen belastet zu werden. Eine effektive dynamische Speicherverwaltung ermöglicht es dem KI-System, seine Speicherzuweisung in Echtzeit an die unmittelbaren Anforderungen der Konversation oder Aufgabe anzupassen.
In der Praxis ermöglicht die dynamische Speicherverwaltung der KI, wichtige Informationen wie wichtige Fakten, Benutzerpräferenzen oder kontextkritische Daten zu priorisieren, während triviale oder veraltete Details verworfen oder depriorisiert werden. Beispielsweise kann sich das System während einer laufenden Konversation darauf konzentrieren, wichtige Informationen zu speichern, auf die häufig Bezug genommen wird oder die für die aktuelle Anfrage des Benutzers hochrelevant sind, während weniger relevante Informationen verfallen oder entfernt werden können. Dieser Prozess stellt sicher, dass die KI sich klar auf das Wesentliche konzentrieren kann, was sowohl die Genauigkeit als auch die Effizienz verbessert.
Um dies zu erleichtern, verwendet das System häufig Relevanzbewertungsmechanismen, um die Bedeutung gespeicherter Erinnerungen zu bewerten und zu ordnen. Jeder Speicher kann eine Prioritätsbewertung erhalten, die auf Faktoren wie der Häufigkeit der Referenzierung oder der Bedeutung für die aktuelle Aufgabe basiert. Speicher mit höherer Priorität werden länger aufbewahrt, während Einträge mit niedrigerer Priorität oder veraltete Einträge zum Löschen markiert werden können. Dieses Bewertungssystem hilft, eine Überlastung des Speichers zu verhindern, indem sichergestellt wird, dass nur die relevantesten Informationen über einen längeren Zeitraum aufbewahrt werden.
Die dynamische Speicherverwaltung umfasst auch Mechanismen zum Speicherabbau, bei denen ältere oder weniger relevante Informationen allmählich „verblassen“ oder automatisch aus dem Speicher entfernt werden, um eine Speicherüberlastung zu verhindern. Dadurch wird sichergestellt, dass die KI nur die wichtigsten Daten behält, wodurch Ineffizienzen vermieden und eine optimale Leistung gewährleistet werden, insbesondere bei groß angelegten Anwendungen, die erhebliche Datenmengen oder speicherintensive Vorgänge umfassen.
Um die Ressourcennutzung weiter zu optimieren, können automatisierte Prozesse implementiert werden, um Speichereinträge zu „vergessen”, die seit längerer Zeit nicht mehr referenziert wurden oder für laufende Aufgaben nicht mehr relevant sind. Diese Prozesse stellen sicher, dass Speicherressourcen wie Speicherplatz und Rechenleistung effizient zugewiesen werden, insbesondere in Umgebungen mit großem Speicherbedarf. Durch die dynamische Speicherverwaltung kann die KI weiterhin kontextbezogene, genaue und zeitnahe Antworten liefern und gleichzeitig ein ausgewogenes und effizientes Speichersystem aufrechterhalten.
Implementierung der Gedächtniskognition in Snaplogic
SnapLogic bietet robuste Funktionen für die Integration mit Datenbanken und Speichersystemen und ist damit eine ideale Plattform für die Erstellung von Workflows zur Verwaltung der Gedächtniswahrnehmung in KI-Anwendungen. Im folgenden Beispiel zeigen wir ein grundlegendes Muster der Gedächtniswahrnehmung unter Verwendung von SnapLogic zur Verarbeitung von Kurzzeit- und Langzeitgedächtnis.
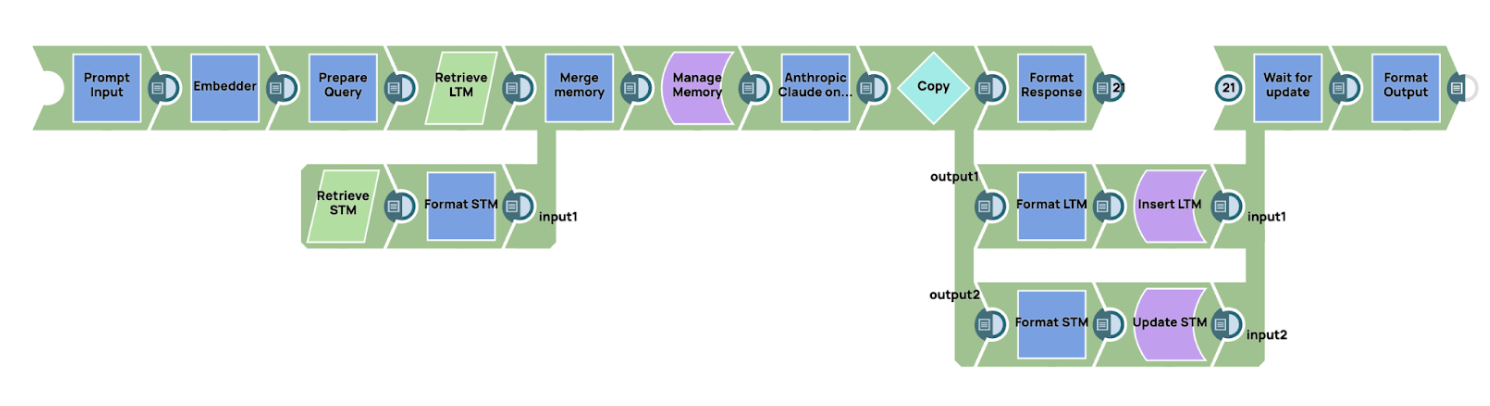
Übersicht über den Arbeitsablauf
Der Workflow beginnt mit der Einbettung der Eingabeaufforderung in eine Vektordarstellung. Dieser Vektor wird dann verwendet, um relevante Erinnerungen aus dem Langzeitgedächtnis abzurufen. Das Langzeitgedächtnis kann in einer Vektordatenbank gespeichert werden, die sich gut für die ähnlichkeitsbasierte Suche eignet, oder in einer herkömmlichen Datenbank oder einem Schlüsselwertspeicher, je nach den Anforderungen der Anwendung. In ähnlicher Weise kann das Kurzzeitgedächtnis in einer regulären Datenbank oder einem Schlüsselwertspeicher gespeichert werden, um die letzten Interaktionen zu verfolgen.
- Abrufen von Erinnerungen
Sobald die Eingabeaufforderung eingebettet ist, rufen wir relevante Informationen sowohl aus dem Kurzzeit- als auch aus dem Langzeitgedächtnis ab. Der Abrufprozess basiert auf einer Ähnlichkeitsbewertung, wobei der Ähnlichkeitswert die Relevanz des gespeicherten Gedächtnisses für die aktuelle Eingabeaufforderung angibt. Für das Langzeitgedächtnis umfasst dies in der Regel die Abfrage einer Vektordatenbank, während das Kurzzeitgedächtnis aus einer herkömmlichen relationalen Datenbank oder einem Schlüsselwertspeicher abgerufen werden kann. Nachdem die relevanten Erinnerungen aus beiden Systemen abgerufen wurden, werden die Daten in ein Speicherverwaltungsmodul eingespeist. In diesem Beispiel implementieren wir einen einfachen Speicherverwaltungsmechanismus mithilfe eines Skripts innerhalb von SnapLogic. - Speicherverwaltungs
Das Speicherverwaltungsmodul verwendet eine Sliding-Window-Technik, eine einfache, aber effektive Methode zur Speicherverwaltung. Wenn neuer Speicher hinzugefügt wird, werden ältere Speicher nach und nach ausgeblendet, bis sie aus dem Speicherstapel entfernt werden. Dadurch wird sichergestellt, dass die KI die aktuellsten und relevantesten Informationen behält und veraltete oder weniger nützliche Speicher verwirft. Der Sliding-Window-Mechanismus priorisiert neuere oder relevantere Speicher und platziert sie oben im Speicherstapel, während ältere Speicher im Laufe der Zeit verdrängt werden. - Generieren der endgültigen Eingabeaufforderung und Interaktion mit dem LLM-
Sobald das Speicherverwaltungsmodul den vollständigen Kontext durch die Kombination von Kurzzeit- und Langzeitspeicher erstellt hat, generiert das System die endgültige Eingabeaufforderung. Diese Eingabeaufforderung wird dann zur Verarbeitung an das Sprachmodell gesendet. In diesem Fall verwenden wir AWS Claude über die Message API als großes Sprachmodell (LLM), um eine Antwort basierend auf dem bereitgestellten Kontext zu generieren. - Speicher aktualisieren
Nach Erhalt einer Antwort vom LLM aktualisiert der Workflow sowohl das Kurzzeit- als auch das Langzeitgedächtnis, um Kontinuität und Relevanz bei zukünftigen Interaktionen sicherzustellen:- Langzeitgedächtnis: Das Langzeitgedächtnis wird aktualisiert, indem die ursprüngliche Eingabeaufforderung mit der Antwort des LLM verknüpft wird. In diesem Zusammenhang entspricht der Abfrageschlüssel der ursprünglichen Eingabeaufforderung, während der Wert die vom Modell generierte Antwort ist. Durch diese Aktualisierung kann das System relevante Informationen speichern, auf die bei zukünftigen Interaktionen zugegriffen werden kann, sodass im Laufe der Zeit fundiertere und kontextbezogene Antworten gegeben werden können.
- Kurzzeitgedächtnis: Das Kurzzeitgedächtnis wird aktualisiert, indem die Antwort des LLM an den neuesten Speicherstapel angehängt wird. Dieser Prozess stellt sicher, dass der unmittelbare Kontext der aktuellen Konversation beibehalten wird, was nahtlose Übergänge und Konsistenz bei nachfolgenden Interaktionen innerhalb der Sitzung ermöglicht.
Dieses Beispiel zeigt, wie SnapLogic effektiv zur Verwaltung der Gedächtniswahrnehmung in KI-Anwendungen eingesetzt werden kann. Durch die Integration mit Datenbanken und die Nutzung der leistungsstarken Workflow-Automatisierung von SnapLogic können wir ein intelligentes Speicherverwaltungssystem schaffen, das sowohl das Kurzzeit- als auch das Langzeitgedächtnis verwaltet. Der Sliding-Window-Mechanismus sorgt dafür, dass die KI kontextbezogen bleibt und gleichzeitig eine Überlastung des Speichers vermieden wird. AWS Claude liefert die Rechenleistung, um auf der Grundlage eines umfassenden Kontextverständnisses Antworten zu generieren. Dieser Ansatz bietet eine skalierbare und flexible Lösung für die Verwaltung der Gedächtniswahrnehmung in KI-gesteuerten Workflows.






