Nach Angaben von Gartner kostet schlechte Datenqualität Unternehmen jedes Jahr durchschnittlich 12,9 Millionen Dollar. Eine erstaunliche Summe, die jedoch nicht überrascht, wenn man bedenkt, dass Daten von schlechter Qualität zu ungenauen Analysen und schlechten Entscheidungen führen.
ETL-Datenpipelines helfen, die Qualität Ihrer Daten zu verbessern. Sie helfen Unternehmen bei einer Vielzahl von Anwendungsfällen - wie Cloud-Migration, Datenbankreplikation und Data Warehousing.
Was ist eine ETL-Datenpipeline?
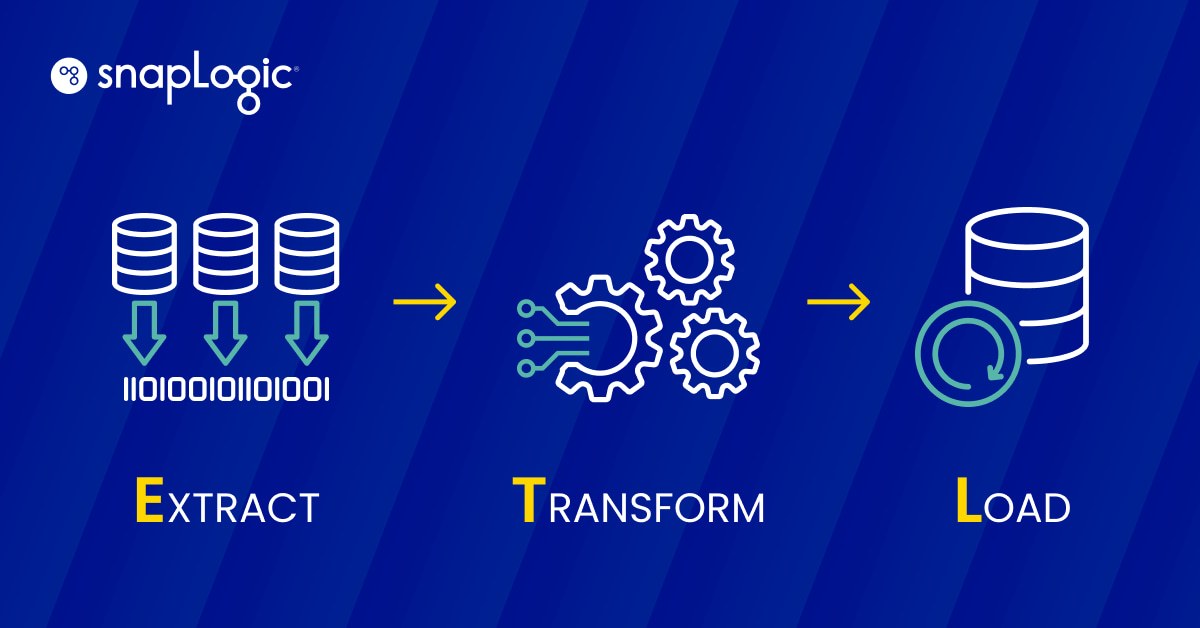
Eine ETL-Datenpipeline ist ein dreistufiger Prozess, bei dem Daten extrahiert (E), transformiert (T) und in einen Datenspeicher geladen (L) werden, um von einem Business Intelligence-Tool oder einem Algorithmus für maschinelles Lernen verwendet zu werden.
- Extraktion: Strukturierte und unstrukturierte Daten aus einer oder mehreren Quellen werden kopiert oder in einen Staging-Bereich verschoben.
- Umwandlung: Die Daten im Staging-Bereich werden für den vorgesehenen Verwendungszweck aufbereitet. Diese Datenverarbeitung kann je nach Anwendungsfall Bereinigung, Filterung, Deduplizierung, Konvertierung, Verschlüsselung und viele andere Prozesse umfassen.
- Laden: Die transformierten Daten werden in ein Lagerhaus geladen.
Die ETL-Anwendungsfälle reichen von einfach bis hochkomplex.
Ein Geschäft mit mehreren Standorten kann beispielsweise eine ETL-Datenpipeline einrichten, um Verkaufsinformationen von allen Standorten zu sammeln und täglich an ein zentrales Repository zu senden. Das ist ein relativ einfaches Beispiel im Vergleich zu dem von Netflix.
Netflix stützt sich auf den ETL-Prozess, um seine Echtzeit-Dateninfrastruktur zu unterstützen. ETL hilft Netflix bei der Verarbeitung von Daten, die später verwendet werden, um seinen Abonnenten hoch personalisierte Empfehlungen zu geben. Bis 2015 verließ sich das Unternehmen bei der Verwaltung seiner Daten auf die Stapelverarbeitung. Daten, die aus internen Prozessen generiert wurden, sowie Nutzerdaten flossen durch herkömmliche ETL-Pipelines und landeten in Daten-Repositories.
Aber Netflix wuchs rasant, und die Stapelverarbeitung war einfach keine nachhaltige Lösung. Das Unternehmen generierte täglich mehr als 10 PB an Daten und erwartete, dass es noch mehr werden würden. Daher wechselte es zur Stream-Datenintegration, einer anderen Art von ETL. Netflix entwickelte Keystone, eine Datenplattform zur Verarbeitung von Echtzeitdatenströmen für analytische Anwendungsfälle, und Mantis, eine ähnliche Plattform zur Verarbeitung von operativen Anwendungsfällen.
Der Übergang von der Stapelverarbeitung zur Stream-Verarbeitung war ein iterativer Prozess - Netflix benötigte fünf Jahre, um vollständig auf ein Stream-Verarbeitungsmodell umzustellen. Die ETL-Pipelines bieten nicht nur personalisierte Empfehlungen, sondern helfen dem Unternehmen auch, die betriebliche Effizienz zu verbessern.
ETL vs. andere Datenpipelines: Was sind die Unterschiede?
Eine ETL-Datenpipeline ist eine Art von Datenpipeline, aber nicht jede Datenpipeline ist ETL. Eine Datenpipeline ist ein Prozess, bei dem ein Softwareprogramm Daten von einer Quelle übernimmt und sie an ein Ziel sendet. Einige der anderen Arten von Datenpipelines neben ETL sind:
ELT
Eine ELT-Pipeline ist wie ETL, aber die Daten werden vor dem Umwandlungsprozess in einen Datenspeicher geladen. ELT-Pipelines werden verwendet, um große Mengen unstrukturierter Daten für Anwendungsfälle des maschinellen Lernens zu verarbeiten.
Datenerfassung ändern (CDC)
CDC ist eine Art Daten-Pipeline, bei der ein Softwareprogramm alle an den Daten in einer Datenbank vorgenommenen Änderungen verfolgt und diese Änderungen in Echtzeit an ein anderes System übermittelt. CDC wird für die Datensynchronisierung und die Erstellung von Prüfprotokollen verwendet.
Datenreplikation
Bei der Datenreplikation werden kontinuierlich Daten aus einer Quelle kopiert und in mehreren anderen Quellen gespeichert, um sie als Backup zu verwenden. Die Datenreplikation wird auch verwendet, um Produktionsdaten zu Analysezwecken in operative Data Warehouses zu übertragen.
Virtualisierung von Daten
Unter Datenvirtualisierung versteht man den Prozess der Integration aller Datenquellen innerhalb eines Unternehmens, so dass die Benutzer über ein Dashboard auf diese Daten zugreifen können. Die Datenvirtualisierung wird zur Erstellung von Dashboards und Berichten für die Einhaltung von Vorschriften, die Verwaltung von Supply Chain und Business Intelligence verwendet.
Was sind die Vorteile einer ETL-Datenpipeline?
ETL-Datenpipelines geben Ihnen die vollständige Kontrolle über das Datenmanagement in Ihrem Unternehmen. Sie können:
- Greifen Sie zu Analysezwecken auf saubere und genaue Daten zu und beseitigen Sie ungenaue, doppelte und unvollständige Datensätze zum Zeitpunkt der Datentransformation.
- Einfache Verfolgung der Datenabfolge, was die Implementierung eines Data-Governance-Rahmens und die Überwachung des Datenflusses in verschiedenen Pipelines innerhalb des Unternehmens erleichtert.
- Verbesserung der Effizienz der Datenverarbeitung innerhalb des Unternehmens durch Automatisierung.
- Visualisieren Sie Datenarchitekturen, die ETL-Datenpipelines verwenden. Durch die Erstellung solcher Diagramme können Sie den Datenfluss verstehen und bei Bedarf Anpassungen an der Pipeline planen.
ETL-Datenpipelines sind einfach einzurichten, vor allem mit Datenintegrationstools. Diese Tools sind meist über Low-Code- und No-Code-Plattformen verfügbar, bei denen Sie eine grafische Benutzeroberfläche (GUI) verwenden können, um ETL-Datenpipelines zu erstellen und den Datenfluss in Ihrem Unternehmen zu automatisieren.
Arten von ETL-Datenpipelines
ETL-Datenpipelines lassen sich in drei Typen unterteilen. Diese Klassifizierung basiert darauf, wie Datenextraktionswerkzeuge Daten aus der Quelle extrahieren.
Stapelverarbeitung
Bei dieser Art von ETL-Datenpipeline werden die Daten in Stapeln extrahiert. Der Entwickler legt eine periodische Synchronisierung zwischen den Datenquellen und der Staging-Umgebung fest, und die Daten werden nach Plan extrahiert. Dies bedeutet, dass die Serverlast nur zum Zeitpunkt der Synchronisierung ansteigt. Einige der Anwendungsfälle für die Stapelverarbeitung sind:
- Kleine und mittlere Unternehmen: Kleine und mittlere Unternehmen arbeiten mit begrenzten Ressourcen und haben keine großen Datenmengen zu bewältigen. Die Stapelverarbeitung ermöglicht es ihnen, die Serverlast zum Zeitpunkt der Synchronisierung effizient zu verwalten und im Rahmen ihrer Ressourcen zu arbeiten, um ihre Daten zu verwalten.
- Daten, die über mehrere Datenbanken im Unternehmen verstreut sind: Wenn es im Unternehmen viele Datenbanken gibt und die Daten über mehrere Standorte auf lokalen Servern verteilt sind, ist es am besten, mehrere ETL-Batch-Datenpipelines zu erstellen, die zu verschiedenen Zeiten des Tages mit dem zentralen Datenspeicher synchronisiert werden.
- Die Daten kommen nicht in Form von Datenströmen: Wenn Sie Daten nicht in Form von Streams generieren, sollten Sie besser Batch-ETL-Datenpipelines verwenden, da diese weniger Ressourcen verbrauchen.
- Analysten haben begrenzte Anforderungen: Wenn Ihre Datenanalysten bei der Durchführung verschiedener Analysen keine neuen Daten oder keinen Zugriff auf den gesamten Datensatz benötigen, ist die Stapelverarbeitung die richtige Wahl für Sie.
Integration von Datenströmen (SDI)
In SDI extrahiert das Datenextraktionstool kontinuierlich Daten aus ihren Quellen und sendet sie an eine Staging-Umgebung. Diese ETL-Datenpipeline ist nützlich, wenn:
- Große Datenmengen müssen verarbeitet werden: Unternehmen, die mit großen Datenmengen arbeiten, die kontinuierlich extrahiert, umgewandelt und geladen werden müssen, können von Stream Processing profitieren.
- Daten werden in Form von Strömen erzeugt: Jedes Unternehmen, in dem kontinuierlich Daten in Form von Datenströmen erzeugt werden, kann von SDI profitieren. Bei YouTube zum Beispiel schauen sich Millionen von Nutzern Videos an und erzeugen gleichzeitig Daten. SDI kann dabei helfen, diese Daten in Echtzeit in Datenspeicher zu übertragen.
- Der Zugang zu Echtzeitdaten ist entscheidend: Betrugserkennungssysteme stoppen bösartige Akteure und lassen sie nicht in Echtzeit Transaktionen durchführen. Das liegt daran, dass sie Echtzeitdaten überwachen. SDI ist in solchen Anwendungsfällen sehr nützlich.
Wie man eine traditionelle ETL-Datenpipeline mit Python erstellt
Bei der Erstellung einer herkömmlichen ETL-Datenpipeline mit Python würde der Codeschnipsel etwa so aussehen (reines Python mit Pandas; dies ist kein produktionsreifes Beispiel).
| import os from sqlalchemy import create_engine import pandas as pd # Extract data data = pd.read_csv(‘data.csv’) # Transform data data = data.dropna() # remove missing values data = data.rename(columns={‘old_name’: ‘new_name’}) # rename columns data = data.astype({‘column_name’: ‘int64’}) # convert data type # Load data db_url = os.environ.get(‘DB_URL’) engine = create_engine(db_url) data.to_sql(‘table_name’, engine, if_exists=’append’) |
In diesem Beispiel werden wir:
- Extrahieren von Daten aus einer CSV-Datei.
- Transformieren Sie sie, indem Sie fehlende Werte entfernen, Spalten umbenennen und Datentypen konvertieren.
- Laden Sie sie in eine SQL-Datenbanktabelle.
Dies ist nur ein Beispiel für das Schreiben von manuellem Code - die spezifischen Schritte und Bibliotheken, die Sie verwenden, hängen von der Datenquelle und dem Ziel sowie von den erforderlichen spezifischen Transformationen ab. Snap
Vereinfachung von Datenpipelines mit SnapLogic
Der obige Ausschnitt ist ein sehr einfaches Beispiel für ETL. Für kompliziertere Transformationen wäre das Beispiel der manuellen Kodierung viel aufwändiger. Darüber hinaus erfordert die manuelle Kodierung eine zeitaufwändige Wartung, die den Data-Engineering- und Data-Warehouse-Abteilungen wertvolle Produktivität raubt.
Anstatt manuell zu kodieren, erstellen Sie Datenpipelines mit der visuellen, grafischen Benutzeroberfläche von SnapLogic. Mit SnapLogic können Sie Datenpipelines erstellen, die auf ETL, ELT, Batch oder Streaming basieren. Befolgen Sie diese Schritte für einen SnapLogic-Ansatz ohne Code:
- Suchen Sie im Studio Patterns-Bereich von SnapLogic nach einer von Hunderten vorhandenen Vorlagen, die Ihre Datenquelle (Datenbank, Dateien, Webdaten), Ihr Datenziel und Ihre funktionalen Anforderungen erfüllen.
- Kopieren Sie das Muster in Ihren SnapLogic Designer Canvas
- Ändern Sie in SnapLogic Designer das SnapLogic-Muster, um es an Ihre spezifischen Konfigurationsanforderungen anzupassen.
- Oder Sie beginnen mit einer leeren SnapLogic Designer-Arbeitsfläche und wählen die gewünschte Datenquelle aus Hunderten von vorgefertigten SnapLogic-Snaps aus und ziehen den Snap auf Ihre Arbeitsfläche
- Lassen Sie sich von SnapLogic Iris, einem KI-gesteuerten Integrationsassistenten, durch die nächsten Schritte beim Aufbau Ihrer Pipeline führen (wenn Sie einen Start-, End- und Mittelpunkt auf Ihrem Canvas festlegen, kann SnapLogic Ihnen auf der Grundlage ähnlicher Muster eine vollständige Datenpipeline empfehlen).
Für ein tieferes Verständnis der modernen, KI-gesteuerten Möglichkeiten zur Erstellung und Ausführung von Datenpipelines ohne oder mit nur wenig Code lesen Sie bitte den ETL-Ansatz von SnapLogic.