According to Gartner, poor data quality costs organizations an average of $12.9 million every year. It’s a staggering sum, but not surprising, considering how low-quality data leads to inaccurate analyses and poor decision-making.
ETL data pipelines help improve the quality of your data. They help organizations with a variety of use cases — such as cloud migration, database replication, and data warehousing.
What is an ETL data pipeline?
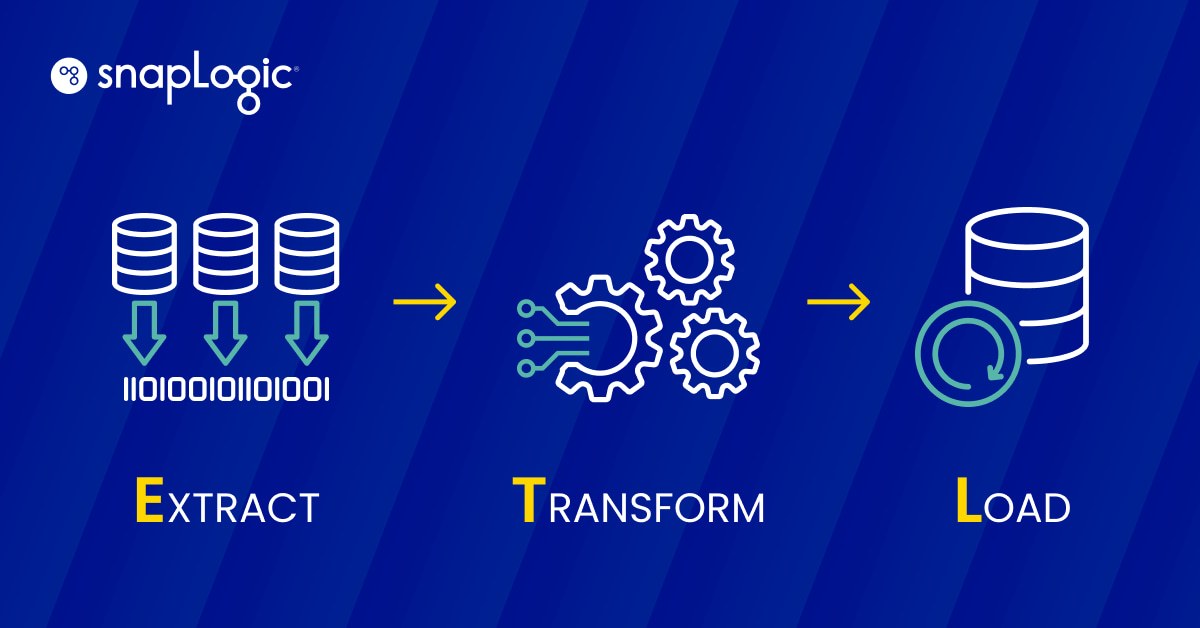
An ETL data pipeline is a three-step process that consists of extracting(E) data, transforming(T) it, and loading(L) it into a data store to be used by a business intelligence tool or machine learning algorithm.
- Extraction: Structured and unstructured data from one or many sources is copied or moved to a staging area.
- Transformation: The data in the staging area is processed for its intended use. This data processing may include cleaning, filtering, deduplication, conversion, encryption, and many other processes, depending on the use case.
- Loading: The transformed data is loaded into a warehouse.
ETL use cases range from simple to highly complex.
For example, a store with multiple locations can set up an ETL data pipeline to collect sales information from all its locations and send it to a central repository every day. That’s a relatively simple example compared to that of Netflix.
Netflix relies on the ETL process to support its real-time data infrastructure. ETL helps Netflix process data that is later used to give highly personalized recommendations to its subscribers. Up until 2015, the company relied on batch processing to manage its data. Data generated from internal processes, as well as user data, flowed through conventional ETL pipelines and ended up in data repositories.
But Netflix was growing at a fast rate, and batch processing simply wasn’t a sustainable solution. The company generated more than 10PB of data every day and expected to generate more, so it switched to stream data integration, which is another type of ETL. Netflix built Keystone, a data platform to handle real-time data streams for analytical use cases, and Mantis, a similar platform to handle operational use cases.
The move from batch processing to stream processing was an iterative one — it took Netflix five years to completely move to a stream processing model. Besides providing personalized recommendations, its ETL pipelines also help the company improve operational efficiency.
ETL vs. other data pipelines: what are the differences?
An ETL data pipeline is a kind of data pipeline, but not every data pipeline is ETL. A data pipeline is any process in which a software program takes data from a source and sends it to a destination. Some of the other types of data pipelines besides ETL include:
ELT
An ELT pipeline is like ETL, but the data is loaded into a data store before the transformation process. ELT pipelines are used to handle large volumes of unstructured data for machine learning use cases.
Change data capture (CDC)
CDC is a kind of data pipeline where a software program tracks all changes made to data in a database and delivers those changes to another system in real time. CDC is used for data synchronization and creating audit logs.
Data replication
Data replication is the process of continuously copying data from one source and saving it to multiple other sources to be used as a backup. Data replication is also used to take production data to operational data warehouses for analysis.
Data virtualization
Data virtualization is the process of integrating all data sources within an organization so that users can access that data through a dashboard. Data virtualization is used to create dashboards and reports for regulatory compliance, supply chain management, and business intelligence.
What are the benefits of an ETL data pipeline?
ETL data pipelines give you complete control over data management in your organization. You can:
- Access clean and accurate data for analysis and get rid of inaccurate, duplicate, and incomplete records at the time of data transformation.
- Easily track data lineage, which makes it easy to implement a data governance framework and monitor the flow of data in different pipelines within the organization.
- Improve data processing efficiency within the organization through automation.
- Visualize data architectures that use ETL data pipelines. By creating such diagrams, you can understand the flow of data and plan adjustments to the pipeline when needed.
ETL data pipelines are easy to set up, especially through data integration tools. These tools are mostly available via low-code and no-code platforms where you can use a graphical user interface (GUI) to build ETL data pipelines and automate the flow of data in your organization.
Types of ETL data pipelines
ETL data pipelines are of three types. This classification is based on how data extraction tools extract data from the source.
Batch processing
In this type of ETL data pipeline, data is extracted in batches. The developer sets period synchronization between the data sources and the staging environment, and the data is extracted on schedule. This means server load only goes up at the time of the sync. Some of the use cases for batch processing include:
- Small and medium organizations: Small and medium-sized organizations work with limited resources and don’t handle large volumes of data. Batch processing allows them to efficiently manage server load at the time of synchronization and work within their resources to manage their data.
- Data scattered across multiple databases in the organization: If there are many databases in the organization, and data is spread on multiple locations on on-premises servers, it is best to create multiple batch ETL data pipelines that sync with the central data repository at different times throughout the day.
- Data is not coming in the form of streams: If you do not generate data in the form of streams, you’re better off using batch ETL data pipelines because they will consume fewer resources.
- Analysts have limited requirements: If your data analysts don’t need fresh data or access to the entire dataset when performing different analyses, batch processing will be a good fit for you.
Stream data integration (SDI)
In SDI, the data extraction tool continuously extracts data from its sources and sends it to a staging environment. This ETL data pipeline is useful when:
- Large datasets need to be processed: Organizations working with large volumes of data that need to be continuously extracted, transformed, and loaded can benefit from stream processing.
- Data is being generated in the form of streams: Any organization where data is continuously being generated in the form of streams can benefit from SDI. For example, YouTube has millions of users watching videos and generating data simultaneously. SDI can help get that data to data stores in real time.
- Access to real-time data is critical: Fraud detection systems stop bad actors and don’t let them make transactions in real time. That’s because they monitor real-time data. SDI comes in handy in such use cases.
How to create a traditional ETL data pipeline with pure Python
When creating a traditional ETL data pipeline with Python, the code snippet would look something like this (pure Python using Pandas; this is not a production-ready example).
| import os from sqlalchemy import create_engine import pandas as pd # Extract data data = pd.read_csv(‘data.csv’) # Transform data data = data.dropna() # remove missing values data = data.rename(columns={‘old_name’: ‘new_name’}) # rename columns data = data.astype({‘column_name’: ‘int64’}) # convert data type # Load data db_url = os.environ.get(‘DB_URL’) engine = create_engine(db_url) data.to_sql(‘table_name’, engine, if_exists=’append’) |
In this example, we:
- Extract data from a CSV file.
- Transform it by removing missing values, renaming columns, and converting data types.
- Load it into an SQL database table.
This is just one, manual code writing, example — the specific steps and libraries that you use will depend on the data source and target, as well as the specific transformations required. Snap
How to simplify data pipelines with SnapLogic
The above snippet is a very basic example of ETL. For more complicated transformations, the manual coding example would be much more involved. In addition, manual coding requires time-consuming maintenance, which robs data engineering and data warehouse shops of valuable productivity.
Rather than manual coding, create data pipelines with SnapLogic’s visual, graphical user interface approach. With SnapLogic, you can create data pipelines that are ETL, ELT, batch or streaming-based. Follow these steps for a SnapLogic no code approach:
- Search for an existing template, among hundreds, in SnapLogic’s Studio Patterns area that meets your data source (database, files, web data), data destination, and functional requirements.
- Copy the pattern into your SnapLogic Designer canvas
- In SnapLogic Designer, modify the SnapLogic pattern to customize to your specific configuration needs.
- Or, start from a blank SnapLogic Designer canvas and select the data source you need from among hundreds of pre-built SnapLogic Snaps and drag the Snap onto your canvas
- Let SnapLogic Iris, an AI-driven integration assistant, guide you through the next steps as you construct your pipeline (if you place a starting point, end point, and midpoint on your canvas, SnapLogic may recommend a complete data pipeline for you based on similar patterns!)
For a more in-depth understanding of modern, AI-driven, ways to create and execute data pipelines in a no-code or low-code manner, read SnapLogic’s approach to ETL.