





According to McKinsey, enterprise employees will be using data to optimize almost all of their work by 2025. Already, the applications and platforms in your tech stack provide an enormous amount of data that can capture critical business insights. But before you can leverage your data, you need a way to manage its intake and flow throughout your organization.
Enter the backbone of the modern enterprise: the data pipeline.
What Is a Data Pipeline?
A data pipeline is a series of automated workflows for moving data from one system to another.
Broadly, the data pipeline consists of three steps:
- Data ingestion from point A (the source).
- Transformation or processing.
- Loading to point B (the destination lake, warehouse, or analytics system).
Any time processing occurs between point A and point B, you’ve created a data pipeline between the two points. If the processing occurs after point B, you’ve still created a data pipeline; it just has a different configuration.
Data pipelines consolidate the data from isolated sources into a single source of truth the whole organization can use, so they’re essential to analytics and decision-making. Without a pipeline, teams analyze data from each source in a silo — preventing them from seeing how data connects at a big-picture level.
Data Pipeline vs. ETL vs. ELT
“Data pipeline” is an umbrella term, while ETL (extract, transform, load) and ELT (extract, load, transform) are types of data pipelines.
ETL data pipelines extract data from the source, transform it through a set of operations, and load it to the destination warehouse or system. A transformation is any automated action that changes the data before it reaches the warehouse. Common transformations include:
- Cleaning and deduplicating the data.
- Aggregating different data sets.
- Converting data to another format.
- Performing calculations to create new data.
If you’re using an ETL pipeline, your goal is to validate, prune, and standardize your data before it’s loaded to the warehouse.
If you transform the data after it reaches the warehouse, you’re using an ELT data pipeline. Those who use cloud data storage often prefer ELT because it allows them to speed up and simplify delivery from source to warehouse.
Data Pipeline Architecture Examples
A simple ETL pipeline looks like this:
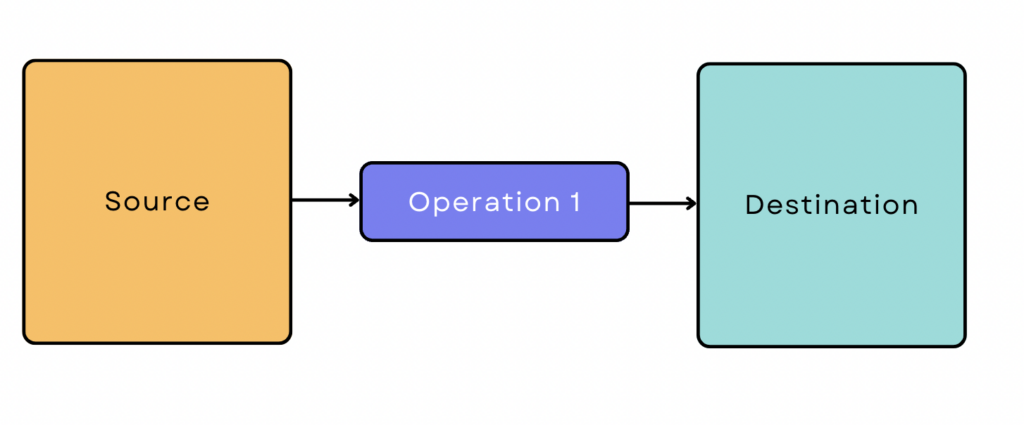
However, most data pipelines aren’t that simple. They usually involve many sources and operations, and the data often interacts with other tools and platforms along the way. Sometimes different operations run in parallel to speed up the process.
At the beginning of the data pipeline, there are two ways to ingest data from the source: batch processing and real-time/streaming processing. Sometimes you need a combination of both. These different ingestion needs are foundational to three common data pipeline configurations.
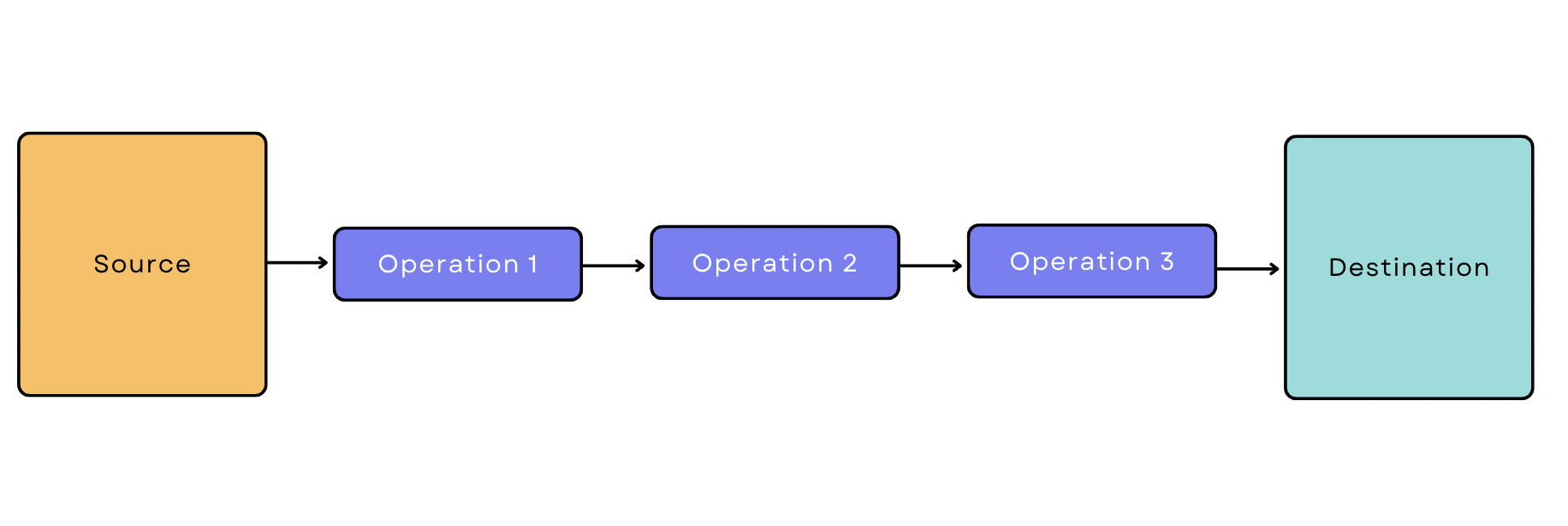
Batch-based Data Pipeline
In batch processing, the ingestion tool extracts data from the source in batches at periodic intervals of time. A batch-based data pipeline is a pipeline that starts with batch ingestion. Let’s say you want to pull transactional data from Google Analytics, apply three transformations, and load it to the warehouse. Your pipeline would look like this:
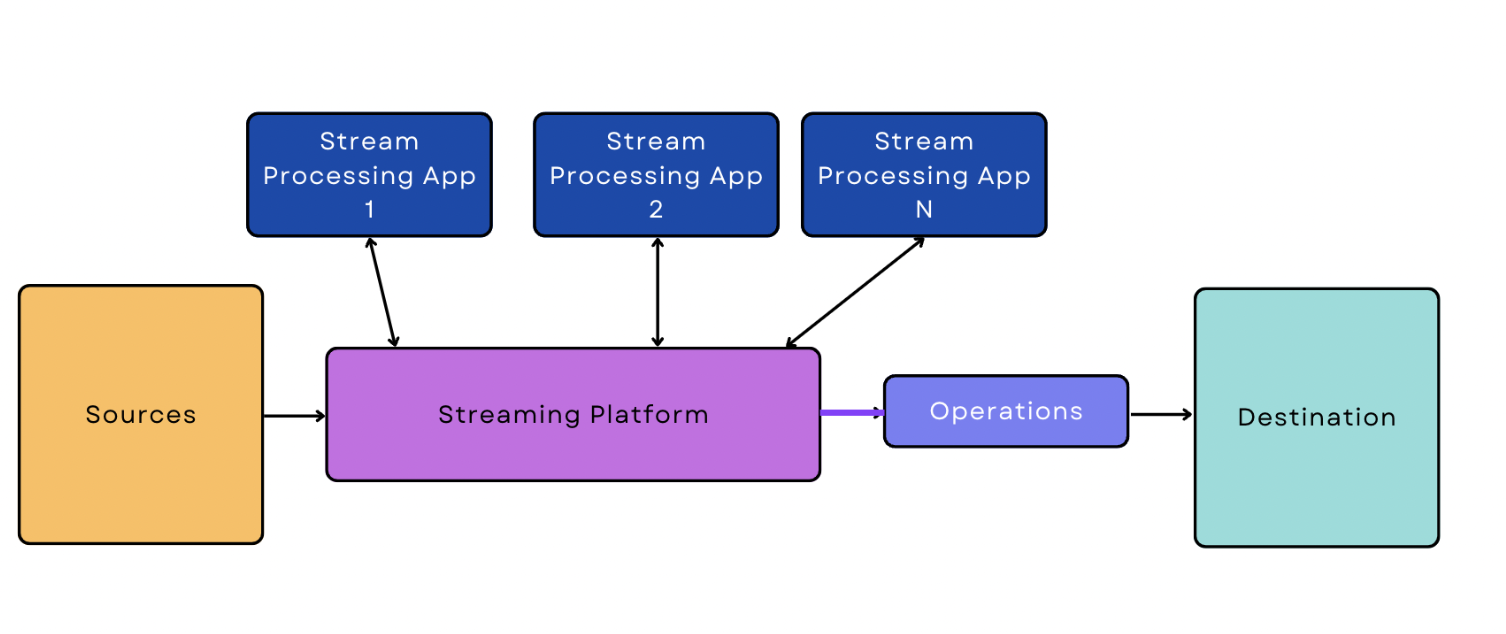
Real-time/Streaming Data Pipeline
In real-time/streaming processing, data is ingested from the source continuously and in real time. A streaming data pipeline is a pipeline that begins with real-time/streaming data ingestion.
Compared to batch ingestion, real-time/streaming ingestion is more difficult for software to handle because it needs to be on and constantly monitoring to stream the data in real time. This extra complexity manifests in the pipeline itself, too; the simplest version of a streaming data pipeline is a bit more complicated than the simplest version of a batch-based pipeline.
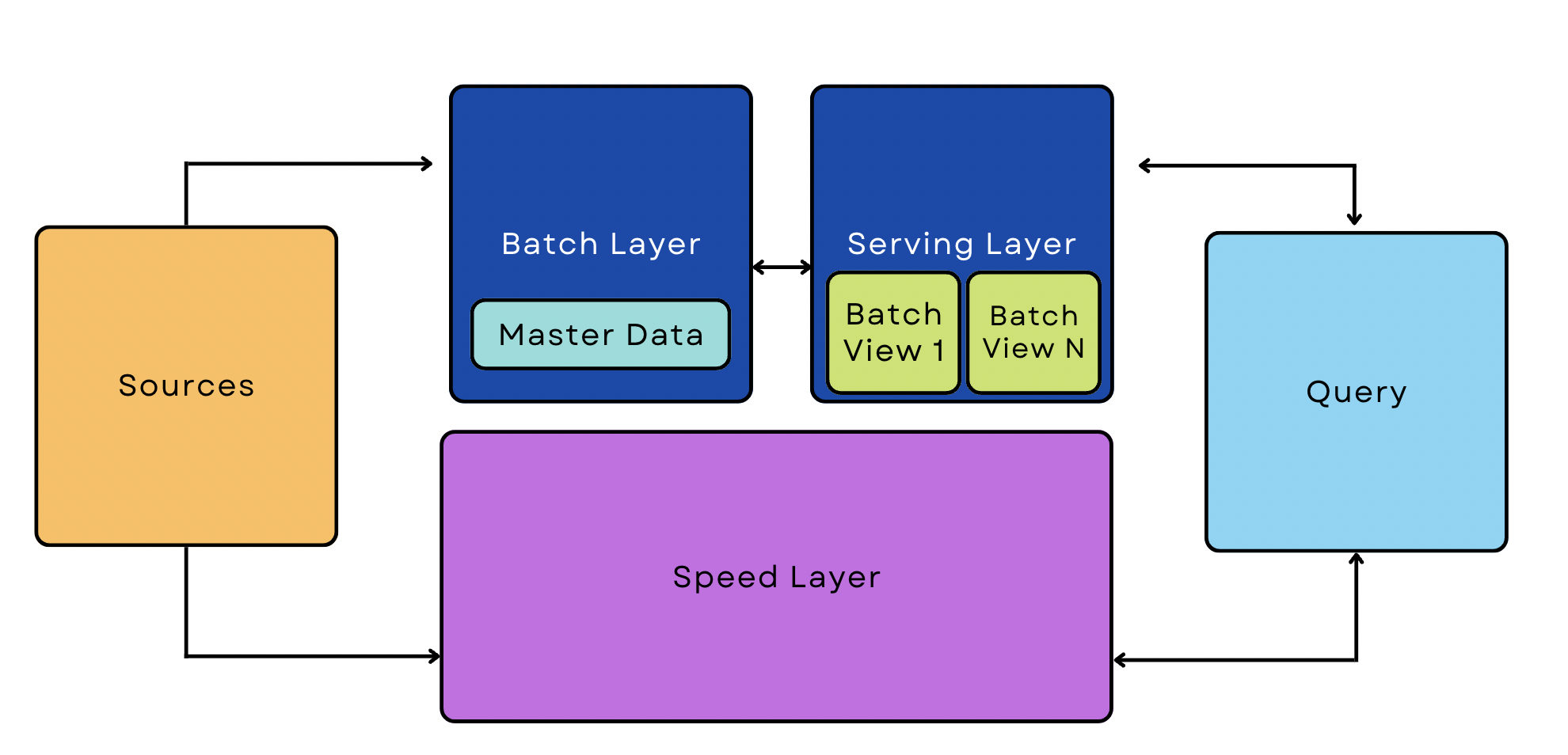
Lambda Architecture Pipeline
A Lambda pipeline combines batch and streaming processes into the same architecture. These pipelines are popular ways to manage big data because they can accommodate both streaming and real-time use cases.
5 Steps To Building an In-house Data Pipeline From Scratch
Compared to using off-the-shelf tools, building a pipeline from scratch is often a time- and resource-intensive process. It generally only makes sense for organizations with exceptionally specialized needs and plenty of engineering resources. If your company fits these criteria, consider following these steps to build your pipeline.
1. Outline Your Goals and Constraints
Start with a precise understanding of what you need the pipeline to do. Do you want to extract information from one database and join it with another? Do you need to push your results into an online store? How many sources will you have?
More specifically, outline the following:
- Sources — What data sources are you using?
- Type of data ingestion — Can the data be processed in batches, or do you need to stream it continuously?
- Destination — Where is the data going?
- Transformation — How does the data need to change so it’s consistent across sources and useful for analytics tools? When do these changes occur?
- Pit Stops — Does the data need to be pushed to other apps or destinations along the way?
2. Map Out a High-level Workflow
Sketch out the main components of your pipeline using modeling software, flowchart software, or even pen and paper. This step helps you visualize the different components in your architecture and how they interact with each other.
Let the following questions guide how you construct your pipeline, aiming for the simplest workflow that can get the job done:
- Are there downstream dependencies on upstream jobs? For example, if you have source data from MySQL databases, do you need the results of an ETL process before moving on to another stage?
- What jobs can run parallel to each other (if any)?
- Do multiple tools need access to the same data? What kind of synchronization is required?
- What is the workflow for failed jobs? Who gets notified?
- If ingested data doesn’t pass validation, where does it go? Do you want to automatically discard it, or would you rather diagnose the errors and reintroduce it to your pipeline?
3. Design the Core Components
If you’re building your data pipeline from scratch, you’ll need to write software to pull and transform the data. This step varies wildly from pipeline to pipeline.
Let’s say you want to consolidate customer data from different systems like your CRM and point of sale system. In this use case, you’d be writing programs that clean and deduplicate the data and then “normalize” it to the same fields (gender, data format, etc.) so it’s assimilated correctly. The consolidated data could then be used to inform personalized notifications, upsells, and segmented email campaigns.
4. Scale the Pipeline
Perform benchmark/load testing to identify possible bottlenecks and scalability issues. This will help you identify your pipeline’s target and peak performance, target and peak load, and acceptable performance limits.
If the load testing turns up bottlenecks or other scalability issues, evaluate ways to address them.
- Load balancing distributes network traffic across a group of servers, balancing out the volume of traffic that each server needs to handle. This solution is helpful when you’re serving millions of users and fielding a large number of simultaneous requests.
- Database sharding is a type of load balancing. In this case, you split a large volume of data (not traffic) across a network of servers. It’s helpful for the same use cases as load balancing — if you have millions of users, you’re working with an enormous amount of user data.
- Horizontal scaling means adding more machines to your pool (scaling out) instead of adding more GPU or RAM to existing servers (scaling up). Scaling out typically allows for more flexibility than scaling up, but it can be more expensive.
- Caching stores copies of a file in a temporary storage location so they can be accessed more quickly. On the front end, caching allows users to access website content and search for information in your database as quickly as possible.
5. Implement a Data Governance Framework
By this point, your data pipeline is complete — but you need a plan for keeping user data secure and regulation compliant throughout your pipeline. Identify all instances of sensitive data you’ll be ingesting and storing — including personal information, credit card data, and anything protected under GDPR or other regulations.
Next, outline the measures you’ll be taking to protect that data. Common security measures include:
- Encrypting data.
- Setting permission-based access controls.
- Maintaining detailed logs and records.
- Monitoring data via third-party tools like Datadog.
- Enabling multi-factor authentication and strong password enforcement on the front end to help safeguard against breaches.
Build or Buy? Alternatives To Building a Pipeline From Scratch
Building a data pipeline from scratch can be costly and difficult compared to using off-the-shelf ingestion tools with pre-built connectors. Upstream changes to the API or new analytics needs can change the scope of a project midstream, creating constant and ongoing work.
Off-the-shelf ingestion tools save time and money by automating critical functions without forcing you to write software to perform every task. Integration platforms like SnapLogic have libraries of pre-built connectors you can use to create custom data pipelines — no coding necessary.
Build Intelligent Data Pipelines With SnapLogic
Don’t waste your engineering resources reinventing the wheel. SnapLogic’s expertly engineered low-code/no-code connectors let you build powerful and flexible data pipelines near-immediately. With 600+ connectors to choose from and automated syncing and data prep options, SnapLogic integrates with your entire tech stack.
Ready to learn how much easier it can be to build enterprise-grade data pipelines? Try a demo today.







