





Eine der häufigsten Anfragen, die ich von Kollegen und Kunden höre, lautet: "Wie kann ich abschätzen, wie viele Aufträge ich auf einem Knoten ausführen kann und wie schnell sie laufen werden?" Die unmittelbare und genaueste Antwort lautet: Es kommt darauf an. Auch wenn diese Antwort leichtfertig erscheinen mag, ist sie doch eine prägnante Antwort auf ein komplexes, mehrdimensionales Problem. Lassen Sie uns die Variablen untersuchen.
Angefangen bei den Quellen, werden verschiedene Quellen die Daten mit unterschiedlicher Geschwindigkeit "liefern". Das Lesen einer Datei von einer entfernten sftp-Site wird langsamer sein als das Lesen aus einer lokalen Datenbank. Auch bei SaaS-Anwendungen variiert die Antwortzeit aufgrund der Auslastung. Je weiter die Quelle entfernt ist, desto größer ist die Wahrscheinlichkeit einer unterschiedlichen Weiterleitung. Eine Gruppe von Paketen kann über Cleveland ankommen, eine andere Gruppe über New York City. Die erste Gruppe von Variablen sind die Quelle und das Netzwerk.
Sobald die Daten am Knotenpunkt "ankommen", wandelt der Snap das Quellformat in ein JSON-Dokument um. Jede Datenzeile, ob SOAP-Nachricht, JSON-Dokument oder in welcher Form die Daten auch immer vorliegen, hat eine Größe, die stark variieren kann. Als wir noch mit relationalen Datenbanken arbeiteten, war die Größe einer Datenzeile nicht größer als die Gesamtzahl der Spalten mal Bytes in der Ergebnismenge. Heute können die Nutzdaten innerhalb ein und derselben Anfrage von einigen hundert Bytes bis zu Megabytes reichen. Diese große Bandbreite macht es schwierig, Leistung und Speicherbedarf genau zu messen. Und anders als bei Datenbanken, wo es eine feste Obergrenze gibt, gibt es bei polystrukturierten Quellen keine feste Obergrenze.
Die Antwort auf eine Anfrage, die Netzwerklatenz und die Datengröße können stark variieren. Die Größe des Arbeitsspeichers und die Verarbeitungsgeschwindigkeit der JVM sind jedoch statisch. Ein Knoten ist ein realer oder virtueller Server, auf dem ein Linux- oder Windows-Betriebssystem läuft. Im Falle eines Cloudplex wird er von SnapLogic verwaltet und ist einheitlich, da wir ein Standard-Image für alle Plexe verwenden. Groundplexes werden von den Kunden eingerichtet und können daher aufgrund von System- und Netzwerkkonfigurationen unterschiedliche Leistungskennzahlen aufweisen. Dadurch kann sich das Verhalten von einem Standort zum anderen ändern.
Es gibt im Wesentlichen zwei Arten von Snaps: Streaming und Akkumulation. Streaming-Snaps empfangen ein JSON-Dokument, verarbeiten es und geben es an den nächsten Snap weiter. Es befindet sich immer nur ein Dokument in einem Snap. Bei akkumulierenden Snaps ist es umgekehrt: Die eingehenden Daten werden im Snap gespeichert, bis der gesamte Datenstrom verbraucht ist. Es gibt nicht viele akkumulierende Snaps und sie sind leicht zu erkennen. Wenn die gewünschte Operation auf mehr als ein Dokument wirkt, handelt es sich um einen Akkumulator. Der Sortier-Snap ist der offensichtlichste. Der benötigte Speicher- und Plattenplatz hängt von der Anzahl der Dokumente ab, und da diese sehr unterschiedlich sein können, ist es schwierig, eine genaue Angabe zu machen. SnapLogic versucht zwar, wie Spark alles im Arbeitsspeicher zu erledigen, wird aber bei Bedarf auf die Festplatte ausweichen. Das bedeutet, dass der Knoten über genügend Festplattenspeicher verfügen muss, um diese Bedingungen zu bewältigen. Die geschätzten Speicheranforderungen umfassen sowohl RAM als auch Festplattenplatz.
Wenn eine Pipeline gestartet wird, sendet die Steuerebene die Snaps an einen Knoten im Plex. Wenn er instanziiert wird, hat jeder Snap einen Speicherfußabdruck. Die Größe eines Snap kann stark variieren, und einige, wie der SAP-Snap, haben externe Abhängigkeiten, die bei den Anforderungen berücksichtigt werden müssen. Außerdem können sich die Snap-Größen von Release zu Release ändern, wenn wir Verbesserungen vornehmen, neue Funktionen hinzufügen, APIs aktualisieren oder die Infrastruktur ändern. Einige Änderungen werden den Speicherbedarf verringern, andere werden ihn vergrößern. Die einzige Konstante ist die Veränderung.
Schließlich müssen die Daten an das Ziel oder die Ziele übermittelt werden. Genau wie die Variationen, die wir bei der Eingabe haben, kann auch das Verhalten des Netzes und des Ziels stark variieren. Die Leistung von Quelle und Ziel kann als zwei Seiten derselben Medaille betrachtet werden. Der einzige Unterschied besteht darin, dass die Bedingungen, die die Leistung der Quelle beeinflussen, mit denen des Ziels übereinstimmen können oder auch nicht. Eine Quelle kann die Daten viel schneller bereitstellen als das Ziel sie verbrauchen kann. Der umgekehrte Fall kann eintreten, und das ist in der Regel nichts, was Sie beeinflussen können.
Ist es also unmöglich, den Speicherbedarf und die Leistungsmerkmale einer Integrationsaufgabe genau zu kennen? Ja, aber wenn man es nicht genau sagen kann, muss man schätzen. Sie können einen Bereich von Anforderungen und Verhalten definieren, wobei Sie wissen, dass es "Ausreißer" aufgrund von Bedingungen gibt, die sich Ihrer Kontrolle entziehen.
SnapLogic bietet die Möglichkeit, Pipeline-Eigenschaften im Dashboard zu überwachen.
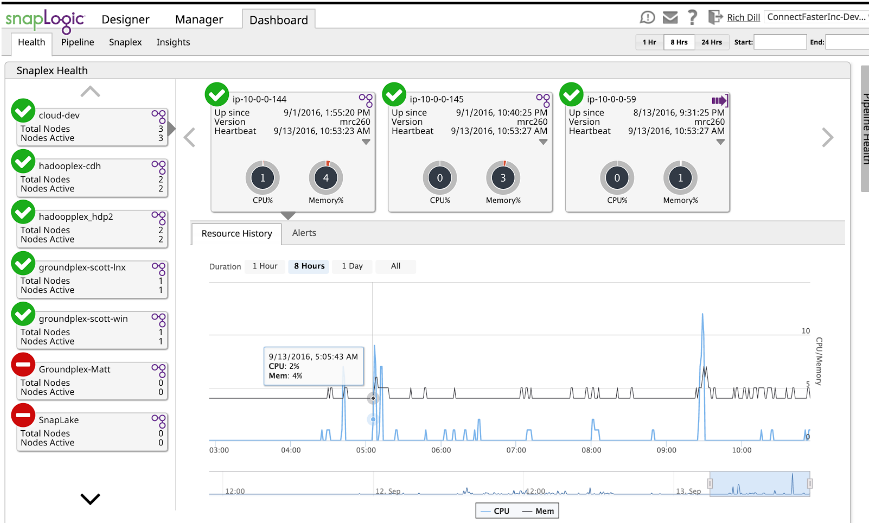
Mithilfe des Dashboards können Sie in Verbindung mit einer Reihe von Testläufen ein Gefühl für die Speicher- und Leistungsanforderungen entwickeln. Führen Sie einfach die Pipeline aus und verwenden Sie das Dashboard, um den verwendeten Speicher zu sehen. Dieser wird zwar in Prozent angegeben, aber wenn Sie den Speicher des Knotens kennen, ist es ein einfaches "Problem für den Schüler", ihn in den tatsächlich verwendeten Speicher umzurechnen. Detaillierte Angaben zur Speichernutzung und Leistung finden Sie in der Protokolldatei jedes Laufs. Diese Protokolle liefern Snap-by-Snap-Speicher- und Leistungsinformationen, die nicht nur für Schätzungen, sondern auch für die Optimierung verwendet werden können. Aber das ist ein anderer Blog-Beitrag.
Die Integration erfolgt heute in einer Umgebung mit vielen Variablen, die sich der Kontrolle des Benutzers entziehen. Wir müssen realistische Erwartungen an die Leistung und das Verhalten haben. Die lose gekoppelte Architektur von SnapLogic bietet Widerstandsfähigkeit gegenüber Änderungen, nicht nur bei Quellen und Zielen, sondern auch bei Laufzeitbedingungen. Sie können diese leistungsstarke Fähigkeit nutzen, wenn Sie wissen, wie Sie sie zu Ihrem Vorteil einsetzen können.
Rich Dill ist ein SnapLogic Enterprise Solutions Architect. Er wurde kürzlich in unserer Podcast-Serie SnapTalk vorgestellt, in der er über den Lebenszyklus von Daten spricht.


