





L‘une des demandes les plus fréquentes que j‘entends de la part de mes collègues et de mes clients est la suivante : "Comment puis-je estimer le nombre de tâches que je peux exécuter sur un nœud et leur vitesse d‘exécution ?" La réponse immédiate et la plus précise est... cela dépend. Bien que cette réponse puisse sembler désinvolte, elle constitue une réponse succincte à un problème complexe et multidimensionnel. Examinons les variables.
En ce qui concerne les sources, les différentes sources fourniront les données à des rythmes différents. La lecture d‘un fichier à partir d‘un site sftp distant sera plus lente que la lecture d‘une base de données locale. Le temps de réponse des applications SaaS varie également en fonction de la charge. En outre, plus la source est éloignée, plus le risque d‘un routage différent est grand. Un ensemble de paquets peut arriver par Cleveland et un autre par New York. La première série de variables est la source et le réseau.
Une fois que les données "arrivent" au nœud, le Snap convertit la forme de la source en un document JSON. Chaque ligne de données, message SOAP, document JSON ou autre forme de données, a une taille qui peut varier considérablement. Lorsque nous travaillions avec des bases de données relationnelles, la taille d‘une ligne de données ne dépassait pas le nombre total de colonnes multiplié par le nombre d‘octets dans l‘ensemble de résultats. Aujourd‘hui, les charges utiles peuvent varier de quelques centaines d‘octets à des mégaoctets au sein d‘une même requête. Ce large éventail de tailles rend difficile la mesure précise des performances et des besoins en mémoire. Et contrairement aux bases de données pour lesquelles il existe une limite supérieure, il n‘existe pas de limite supérieure pour les sources poly-structurées.
La réponse à une requête, la latence du réseau et la taille des données peuvent varier considérablement. Cependant, la quantité de mémoire et la vitesse de traitement de la JVM sont statiques. Un nœud est un serveur, réel ou virtuel, exécutant un système d‘exploitation Linux ou Windows. Dans le cas d‘un Cloudplex, il est géré par SnapLogic et est cohérent car nous utilisons une image standard pour tous les plexes. Les Groundplexes sont configurés par les clients et, en tant que tels, peuvent présenter des mesures de performance différentes en raison de la configuration du système et du réseau. Cela peut modifier le comportement d‘un site à l‘autre.
Il existe essentiellement deux types de snaps: les snaps de flux et les snaps d‘accumulation. Les snaps en continu reçoivent un document JSON, le traitent et le transmettent au snap suivant. Il n‘y a qu‘un seul document dans le Snap à tout moment. Les Snaps d‘accumulation sont l‘inverse, les données entrantes sont stockées dans le Snap jusqu‘à ce que l‘ensemble du flux de données ait été consommé. Il n‘y a pas beaucoup d‘instantanés d‘accumulation et ils sont faciles à identifier. Si l‘opération que vous souhaitez effectuer agit sur plus d‘un document, il s‘agit d‘un accumulateur. Le cliché de tri est le plus évident. La quantité de mémoire et de disque nécessaire dépend du nombre de documents et, comme ils peuvent varier considérablement, il est difficile d‘être précis. Bien que SnapLogic tente de tout faire en mémoire comme Spark, il débordera sur le disque si nécessaire. Cela signifie que le nœud doit avoir suffisamment d‘espace disque pour gérer ces conditions. Les besoins estimés en mémoire comprennent à la fois la RAM et l‘espace disque.
Lorsqu‘un pipeline est démarré, le plan de contrôle envoie les Snaps à un nœud sur le plex. Lorsqu‘il est instancié, chaque Snap a une empreinte mémoire. La taille des snap peut varier considérablement et certains, comme le snap SAP, ont des dépendances externes qui doivent être prises en compte dans les exigences. En outre, la taille des snap peut changer d‘une version à l‘autre, au fur et à mesure que nous apportons des améliorations, que nous ajoutons des fonctionnalités, que nous mettons à jour les API ou que nous modifions l‘infrastructure. Certains changements réduiront l‘empreinte mémoire, d‘autres l‘augmenteront. La seule constante est le changement.
Enfin, les données doivent être transmises à la cible ou aux cibles. Tout comme les variations que nous avons avec les données d‘entrée, le comportement du réseau et de la cible peut varier considérablement. Les performances de la source et de la cible peuvent être considérées comme les deux faces d‘une même pièce. La seule différence réside dans le fait que les conditions qui influencent les performances de la source peuvent ou non être les mêmes que celles de la cible. Vous pouvez avoir une source qui peut fournir les données beaucoup plus rapidement que la cible ne peut les consommer. L‘inverse peut se produire, et ce n‘est généralement pas quelque chose que vous pouvez influencer.
Est-il donc impossible de connaître avec précision les besoins en mémoire et les caractéristiques de performance d‘un travail d‘intégration ? Oui, mais lorsque vous ne pouvez pas être exact, vous faites des estimations. Vous pouvez définir une gamme d‘exigences et de comportements en sachant qu‘il y aura des "valeurs aberrantes" basées sur des conditions indépendantes de votre volonté.
SnapLogic permet de surveiller les caractéristiques du pipeline dans le tableau de bord.
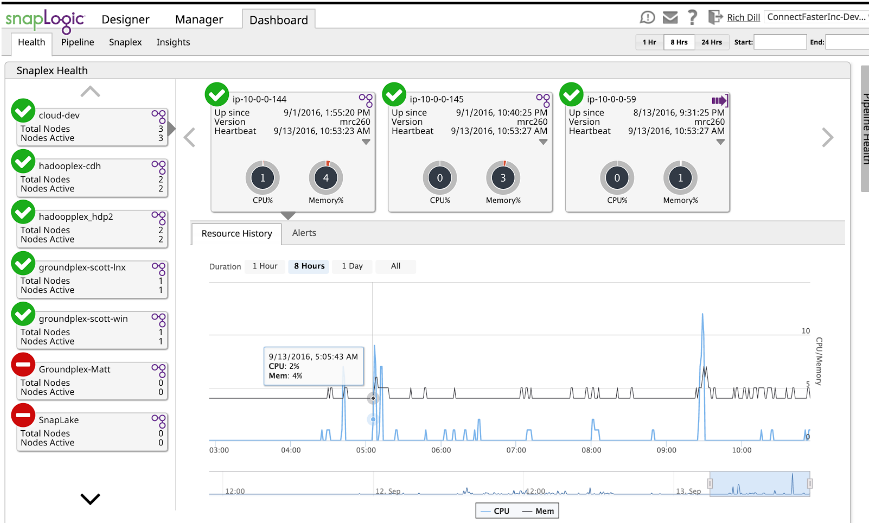
Le tableau de bord, combiné à une série de tests, vous permet de vous faire une idée des besoins en mémoire et en performances. Il suffit d‘exécuter le pipeline et d‘utiliser le tableau de bord pour voir la mémoire utilisée. Bien qu‘elle soit exprimée en pourcentage, si vous connaissez la mémoire du nœud, il suffit d‘un simple "problème pour l‘étudiant" pour la convertir en mémoire réellement utilisée. Le détail de l‘utilisation de la mémoire et des performances se trouve dans le fichier journal de chaque exécution. Ces journaux fournissent des informations sur la mémoire et les performances Snap by Snap qui peuvent être utilisées non seulement pour l‘estimation, mais aussi pour le réglage. Mais il s‘agit là d‘un autre article de blog.
Aujourd‘hui, l‘intégration se fait dans un environnement où de nombreuses variables échappent au contrôle de l‘utilisateur. Nous devons avoir des attentes réalistes en matière de performance et de comportement. L‘architecture faiblement couplée de SnapLogic permet de résister aux changements, non seulement au niveau des sources et des cibles, mais aussi au niveau des conditions d‘exécution. Vous pouvez tirer parti de cette puissante capacité si vous savez comment l‘utiliser à votre avantage.
Rich Dill est architecte de solutions d‘entreprise SnapLogic. Il a récemment participé à notre série de podcasts SnapTalk sur le cycle de vie des données.





