





Una delle richieste più frequenti che ricevo da colleghi e clienti è: "Come faccio a stimare quanti lavori posso eseguire su un nodo e a che velocità?". La risposta immediata e più accurata è... dipende. Anche se può sembrare una risposta banale, è una risposta sintetica a un problema complesso e multidimensionale. Esaminiamo le variabili.
A partire dalle fonti, fonti diverse "serviranno" i dati a velocità diverse. La lettura di un file da un sito sftp remoto sarà più lenta di quella da un database locale. Anche le applicazioni SaaS variano i tempi di risposta in base al carico. Inoltre, più la sorgente è lontana, maggiore è la possibilità di un instradamento diverso. Una serie di pacchetti può arrivare da Cleveland e un'altra da New York. Il primo gruppo di variabili è costituito dalla sorgente e dalla rete.
Una volta che i dati "arrivano" al nodo, Snap converte la forma di origine in un documento JSON. Ogni riga di dati, messaggio SOAP, documento JSON o qualsiasi altra forma di dati, ha una dimensione che può variare notevolmente. Quando lavoravamo con i database relazionali, la dimensione di una riga di dati non superava il numero totale di colonne per byte nel set di risultati. Oggi, i payload possono variare da un paio di centinaia di byte a megabyte all'interno della stessa richiesta. Questa ampia gamma di dimensioni rende difficile misurare con precisione le prestazioni e i requisiti di memoria. Inoltre, a differenza dei database, dove esiste un limite massimo prestabilito, con le fonti polistrutturate non esiste un limite massimo prestabilito.
La risposta a una richiesta, la latenza della rete e la dimensione dei dati possono variare notevolmente. Tuttavia, la quantità di memoria e la velocità di elaborazione della JVM sono statiche. Un nodo è un server, reale o virtuale, che esegue un sistema operativo Linux o Windows. Nel caso di un Cloudplex, è gestito da SnapLogic ed è coerente perché utilizziamo un'immagine standard per tutti i plex. I Groundplex sono configurati dai clienti e come tali possono avere metriche di performance diverse a causa delle configurazioni di sistema e di rete. Questo può cambiare il comportamento da una sede all'altra.
Essenzialmente, esistono due tipi di snap: in streaming e ad accumulo. Gli snap in streaming ricevono un documento JSON, lo elaborano e lo passano allo snap successivo. Nello snap è presente un solo documento in qualsiasi momento. Gli snap ad accumulo sono l'opposto: i dati in arrivo vengono conservati nello snap finché l'intero flusso di dati non è stato consumato. Non esistono molti snap ad accumulo e sono facili da identificare. Se l'operazione che si desidera eseguire agisce su più di un documento, si tratta di un accumulatore. Lo snap di ordinamento è il più ovvio. La quantità di memoria e di disco richiesta dipende dal numero di documenti e, poiché questi possono variare notevolmente, è difficile essere precisi. Sebbene SnapLogic tenti di fare tutto in memoria come Spark, si riverserà su disco quando necessario. Ciò significa che il nodo deve avere abbastanza spazio su disco per gestire queste condizioni. I requisiti di memoria stimati includono sia la RAM che lo spazio su disco.
Quando viene avviata una pipeline, il piano di controllo invia gli snap a un nodo del plex. Quando viene istanziato, ogni Snap ha un ingombro in memoria. Le dimensioni degli Snap possono variare notevolmente e alcuni, come lo Snap di SAP, hanno dipendenze esterne che devono essere considerate nei requisiti. Inoltre, le dimensioni degli Snap possono cambiare da una release all'altra, man mano che vengono apportati miglioramenti, aggiunte funzionalità o aggiornamenti alle API o modifiche all'infrastruttura. Alcune modifiche ridurranno l'ingombro di memoria, altre lo aumenteranno. L'unica costante è il cambiamento.
Infine, i dati devono essere consegnati all'obiettivo o agli obiettivi. Proprio come le variazioni che abbiamo con l'input, il comportamento della rete e del target può variare notevolmente. Le prestazioni della sorgente e della destinazione possono essere considerate due facce della stessa medaglia. L'unica differenza è che le condizioni che influenzano le prestazioni della sorgente possono essere o meno le stesse della destinazione. Si può avere un'origine che può fornire i dati molto più velocemente di quanto la destinazione possa consumarli. Può accadere anche l'inverso e di solito non è possibile influire su questo aspetto.
È quindi impossibile conoscere con precisione i requisiti di memoria e le caratteristiche di prestazione di un lavoro di integrazione? Sì, ma quando non si può essere precisi, si fa una stima. È possibile definire una gamma di requisiti e comportamenti, sapendo che ci saranno dei "valori anomali" basati su condizioni al di fuori del proprio controllo.
SnapLogic offre la possibilità di monitorare le caratteristiche della pipeline nel dashboard.
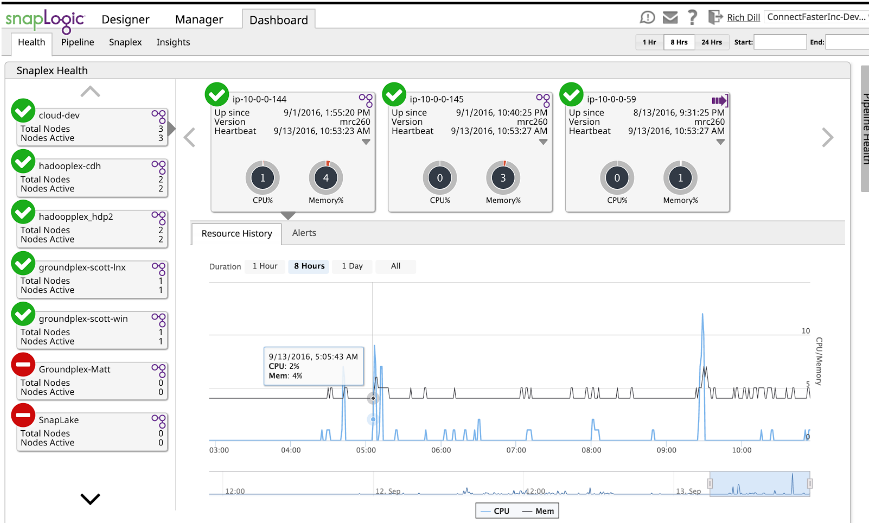
Utilizzando la Dashboard, insieme a una serie di test, è possibile sviluppare un'idea dei requisiti di memoria e di prestazioni. È sufficiente eseguire la pipeline e utilizzare la Dashboard per vedere la memoria utilizzata. Sebbene sia indicata come percentuale, se si conosce la memoria del nodo è un semplice "problema per lo studente" convertirla in memoria effettivamente utilizzata. L'utilizzo dettagliato della memoria e le prestazioni sono contenute nel file di log di ogni esecuzione. Questi registri forniscono informazioni sulla memoria e sulle prestazioni Snap per Snap che possono essere utilizzate non solo per la stima, ma anche per la messa a punto. Ma questo è un altro post del blog.
L'integrazione oggi avviene in un ambiente con molte variabili fuori dal controllo dell'utente. Dobbiamo avere aspettative realistiche sulle prestazioni e sul comportamento. L'architettura loosely coupled di SnapLogic offre resilienza ai cambiamenti, non solo alle sorgenti e alle destinazioni, ma anche alle condizioni di runtime. È possibile sfruttare questa potente capacità se si comprende come utilizzarla a proprio vantaggio.
Rich Dill è un architetto di soluzioni aziendali SnapLogic. Recentemente è stato ospite della nostra serie di podcast SnapTalk per parlare del ciclo di vita dei dati.





