





Les volumes de données augmentent de façon exponentielle et de nombreuses organisations commencent à prendre conscience de la complexité de leurs mouvements de données croissants et de leurs solutions de gestion des données.. Les données existent dans différents systèmes, et en tirer une valeur significative est devenu un défi majeur pour de nombreuses entreprises. En outre, la plupart des données sont généralement stockées dans des systèmes relationnels tels que MySQL, PostgreSQL et Oracle, qui sont les bases de données courantes principalement utilisées à des fins d'OLTP. Les systèmes NoSQL tels que Cassandra, MongoDB et DynamoDB sont également apparus avec un modèle de cohérence ajustable afin de stocker certaines de ces données critiques. Les clients déplacent ensuite généralement ces données vers des systèmes beaucoup plus importants tels que Teradata et Hadoop (OLAP), qui peuvent stocker de grandes quantités de données, afin de pouvoir exécuter des analyses, des rapports ou des requêtes complexes. Il existe également une tendance récente qui consiste à déplacer certaines de ces données vers cloud, en particulier vers Amazon RedShift ou Snowflake, ainsi que vers HDInsights ou Azure Data Warehouse.
Si nous parlons des tendances passées et actuelles en matière de flux de données dans les différents systèmes, voici ce qu'il en est :
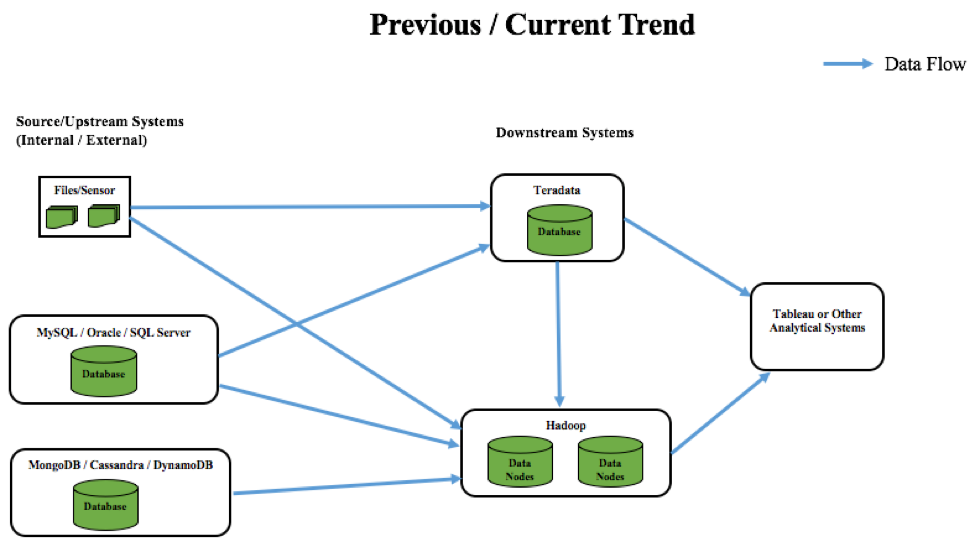 A titre d'exemple : Prenons l'exemple d'une grande industrie alimentaire ou d'un secteur de la vente au détail. La manière traditionnelle d'analyser les modèles/tendances d'achat consistait à stocker les données dans des fichiers plats ou des bases de données opérationnelles, puis à les transférer vers un système d'entrepôt de données basé sur cloud , tel que Teradata (tendance précédente). Ce processus était davantage axé sur le traitement par lots et ne permettait pas d'obtenir des informations en temps réel. Par exemple, les clients qui reçoivent des coupons lorsqu'ils font des achats dans ces secteurs d'activité se basent uniquement sur des recherches et des recommandations historiques. Certains de ces coupons peuvent être pertinents pour de nombreux acheteurs, mais la plupart du temps, ils ne le sont pas.
A titre d'exemple : Prenons l'exemple d'une grande industrie alimentaire ou d'un secteur de la vente au détail. La manière traditionnelle d'analyser les modèles/tendances d'achat consistait à stocker les données dans des fichiers plats ou des bases de données opérationnelles, puis à les transférer vers un système d'entrepôt de données basé sur cloud , tel que Teradata (tendance précédente). Ce processus était davantage axé sur le traitement par lots et ne permettait pas d'obtenir des informations en temps réel. Par exemple, les clients qui reçoivent des coupons lorsqu'ils font des achats dans ces secteurs d'activité se basent uniquement sur des recherches et des recommandations historiques. Certains de ces coupons peuvent être pertinents pour de nombreux acheteurs, mais la plupart du temps, ils ne le sont pas.
Aujourd'hui, les données explosent à l'échelle mondiale. Par conséquent, le nombre de systèmes (capteurs, etc.) pour les capturer augmente également, de sorte que des systèmes NoSQL évolutifs sont apparus pour stocker ces ensembles de données variés. Ces types d'ensembles de données en constante augmentation doivent être transférés vers des systèmes peu coûteux et évolutifs à des fins d'analyse. C'est là que le big data a évolué et que les utilisateurs ont commencé à transférer leurs données vers Hadoop au lieu de Teradata, principalement pour des raisons de coût. Tous ces systèmes sont ensuite généralement intégrés à des outils de BI tels que Tableau pour la visualisation des données. Grâce à cette configuration, le secteur de l'alimentation et de la vente au détail est en mesure d'envoyer rapidement des données à différents systèmes et de les analyser à la volée avec une boucle de rétroaction rapide. Cela permet d'adopter une approche efficace centrée sur le client et d'imprimer des coupons sur la base d'une combinaison de ce qu'il a acheté récemment ou précédemment.
Si nous parlons des tendances futures en matière de flux de données entre les différents systèmes, voici comment on peut les prévoir :
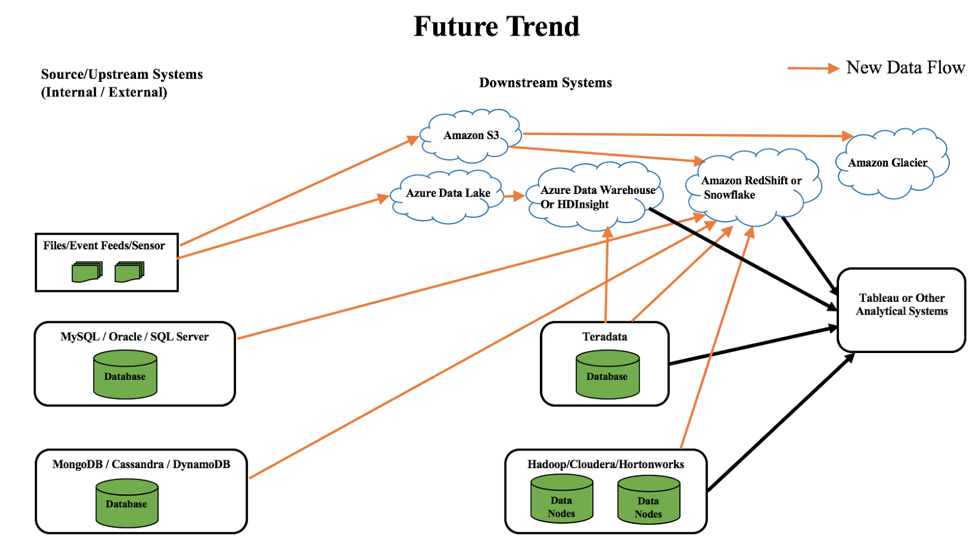
Comme le montre le diagramme ci-dessus, cloud est là pour rester et devient plus important que jamais. Les clients transfèrent peu à peu leurs données vers le site cloud, afin de réduire la maintenance de l'infrastructure, les coûts et d'autres complexités en interne. Voici quelques-unes des tendances futures en matière de données :
- Déplacer des données de systèmes opérationnels et NoSQL vers Redshift ou Snowflake
- Déplacement des données de Teradata vers Hadoop sur cloud comme HDInsights ou Azure Data Warehouse
- Déplacer les données des capteurs/des flux d'événements vers Azure Data Lake ou Amazon S3. Par la suite, Amazon Glacier pourrait être utilisé pour stocker les données froides ou rarement utilisées.
Dans l'ensemble, lemouvement des données est devenu essentiel dans ces systèmes pour en tirer une valeur commerciale essentielle. Cela nécessite un effort de développement ETL supplémentaire s'il est effectué manuellement. Mais Snaplogic permet aux utilisateurs de déplacer très facilement les données vers différents systèmes - à la fois pour les applications et les bases de données/entrepôts de données (sur site ou cloud) en construisant des pipelines via des connecteurs préconstruits appelés Snaps - sans aucun effort de codage. Avec un simple mécanisme de glisser-déposer fourni par Snaplogic scalable plateforme, les clients peuvent facilement construire des pipelines avec des Snaps pertinents, et déplacer des données à partir de différents systèmes afin d'en tirer rapidement une valeur commerciale. Ces Snaps effectuent également la transformation, le nettoyage ou la manipulation des données afin que les systèmes en aval puissent obtenir les données souhaitées qui peuvent aider les résultats de l'entreprise.
Quelques pipelines SnapLogic pour les tendances actuelles et futures sont présentés ci-dessous :

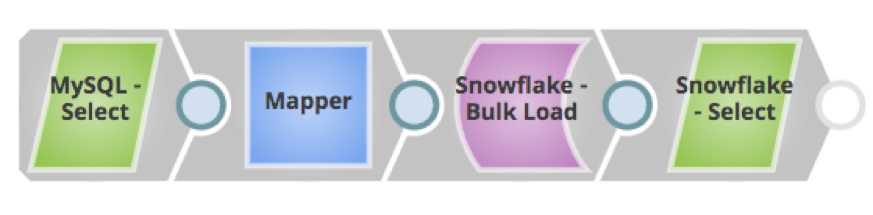 En résumé, cloud va se généraliser au fur et à mesure que de plus en plus d'entreprises y transfèrent leurs données, en raison des divers avantages et de la flexibilité mentionnés ici. Le site cloud plateforme de SnapLogic est en première ligne pour y contribuer.
En résumé, cloud va se généraliser au fur et à mesure que de plus en plus d'entreprises y transfèrent leurs données, en raison des divers avantages et de la flexibilité mentionnés ici. Le site cloud plateforme de SnapLogic est en première ligne pour y contribuer.
