





Par Pavan Venkatesh
Flux de données avec Confluent et migration vers Hadoop : Dans mon précédent article de blog, j‘ai expliqué comment tendances futures en matière de mouvements de données à venir. Dans ce billet, je vais approfondir certaines des choses passionnantes que nous avons annoncées dans le cadre de la version d‘hiver 2017 (4.8) de Snaps. Cela permettra également d‘aborder les futures tendances en matière de mouvement de données pour les clients qui souhaitent déplacer des données vers le site cloud à partir de différents systèmes ou migrer vers Hadoop.
Les principales nouveautés de la version d‘hiver 2017 (4.8) sont les suivantes :
- Support de Confluent Kafka - Un système de messagerie distribué pour le streaming de données
- Teradata to Hadoop - Un moyen simple et rapide de migrer les données
- Améliorations du Teradata Snap Pack : En ce qui concerne TPT, les clients peuvent rapidement charger/mettre à jour/supprimer des données dans Teradata
- Le Snap RedShift Multi-Execute - permet d‘exécuter plusieurs instructions de manière séquentielle, afin que les clients puissent conserver la logique de l‘entreprise.
- Améliorations du pack Snap MongoDB (Delete et Update) et du pack Snap DynamoDB (Delete et Delete-item)
- Amélioration de la sortie Workday Read - Les systèmes en aval peuvent désormais l‘utiliser plus facilement.
- Améliorations de Netsuite Snap Pack - Les utilisateurs peuvent désormais soumettre des opérations asynchrones
- Amélioration des fonctionnalités de sécurité - y compris SSL pour MongoDB Snap Pack et l‘invalidation des pools de connexion aux bases de données lorsque les propriétés du compte sont modifiées.
- Amélioration majeure des performances lors de l‘écriture vers un bucket S3 à l‘aide de S3 File Writer - Les utilisateurs peuvent désormais configurer une taille de tampon dans le Snap afin que les blocs plus importants soient envoyés rapidement vers S3.
Kafka est un système de messagerie distribué basé sur un modèle de publication/abonnement avec un débit élevé et une grande évolutivité. Il est principalement utilisé pour l‘ingestion à partir de sources multiples, puis envoyé à plusieurs systèmes en aval. Les cas d‘utilisation comprennent le suivi de l‘activité des sites web, l‘analyse des fraudes, l‘agrégation des journaux, l‘analyse des ventes, etc. Confluent est la société qui fournit la capacité et l‘offre d‘entreprise pour l‘open source Kafka.
Ici, chez SnapLogic, nous avons construit des snapshots producteurs et consommateurs de Kafka dans le cadre du Confluent Snap Pack. Une plongée profonde dans l‘architecture de Kafka et son fonctionnement sera une bonne transition avant d‘entrer dans les détails du Snap Pack ou du pipeline.
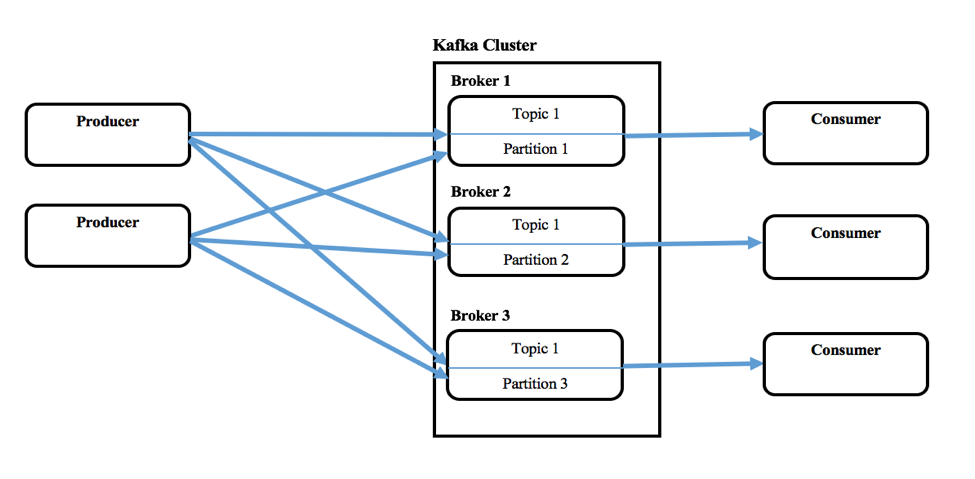
Kafka se compose d‘un ou de plusieurs producteurs qui peuvent produire des messages à partir d‘un ou de plusieurs systèmes en amont, et d‘un ou de plusieurs consommateurs qui consomment des messages dans le cadre de systèmes en aval. Un cluster Kafka est constitué d‘un ou plusieurs serveurs appelés Brokers. Les messages (clé et valeur ou juste la valeur) seront introduits dans des abstractions de plus haut niveau appelées Topics. Chaque sujet peut contenir plusieurs messages provenant de différents producteurs. L‘utilisateur peut également définir des thèmes différents pour une nouvelle catégorie de messages. Ces producteurs écrivent des messages dans les thèmes et les consommateurs les consomment à partir d‘un ou de plusieurs thèmes. Les thèmes sont également partitionnés, répliqués et conservés par les courtiers. Les messages dans les Topics sont ordonnés au sein d‘une partition et chacun d‘entre eux aura un numéro d‘identification séquentiel appelé offset. Zookeeper maintient habituellement ces décalages, mais Confluent l‘appelle le noyau de coordination.
Kafka permet également de configurer un groupe de consommateurs dont plusieurs consommateurs font partie, lorsqu‘ils consomment à partir d‘un thème.
Avec plus de 400 Snaps supportant divers produits on-prem (bases de données relationnelles, fichiers, bases de données nosql, et autres) et cloud (Netsuite, SalesForce, Workday, RedShift, Anaplan, et autres), le Snaplogic Elastic Integration Cloud en combinaison avec le Confluent Kafka Snap Pack sera une combinaison puissante pour déplacer des données vers différents systèmes d‘une manière rapide et en flux continu. Les clients peuvent en tirer des avantages et générer des résultats commerciaux rapidement.
En ce qui concerne le Confluent Kafka Snap Pack, nous supportons Confluent Version 3.0.1 (Kafka v0.9). Ces snaps font abstraction des complexités et les utilisateurs n‘ont qu‘à fournir les détails de configuration pour construire un pipeline qui déplace facilement les données. Une chose à noter est que lorsque plusieurs Consumer Snaps sont utilisés dans un pipeline et ont été configurés avec le même groupe de consommateurs, chaque Consumer Snap se verra attribuer un sous-ensemble différent de partitions dans le Topic.
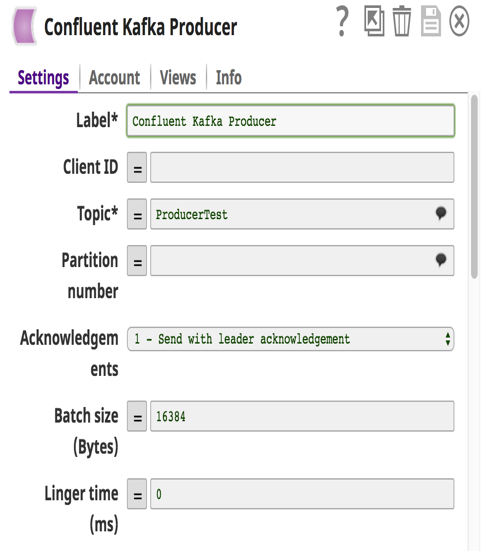
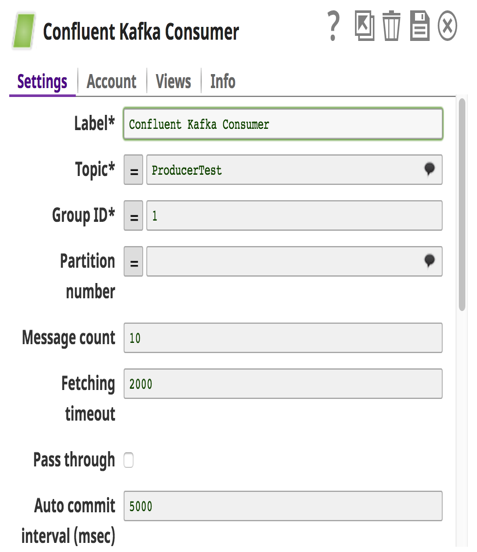
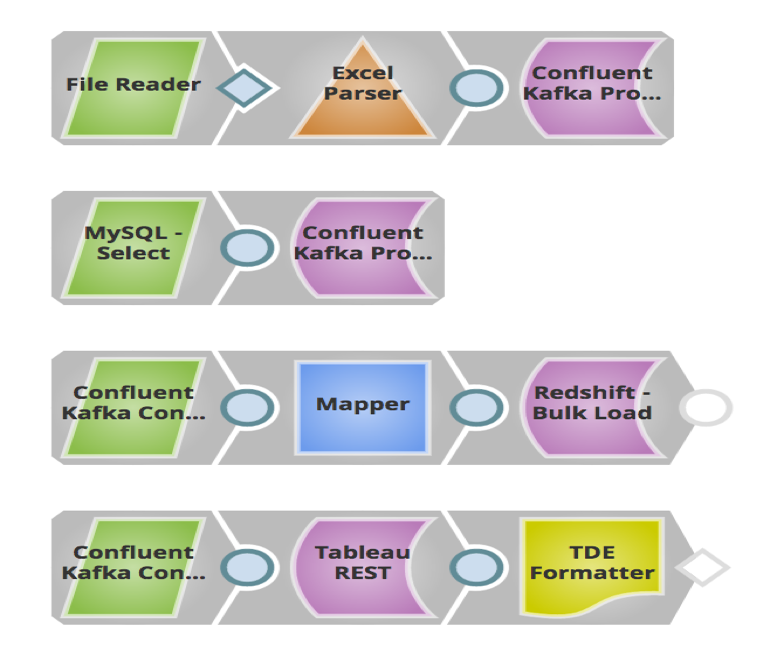
Dans l‘exemple ci-dessus, j‘ai construit un pipeline dans lequel les pistes de vente (messages) stockées dans des fichiers locaux et MySQL sont envoyées à un Topic dans Confluent Kafka via Confluent Kafka Producer Snaps. Le système en aval, Redshift, consommera ces messages à partir de ce thème via le Snap consommateur de Confluent Kafka et les chargera en masse dans RedShift pour des besoins d‘historique ou d‘audit. Ces messages sont également envoyés à Tableau en tant qu‘autre consommateur pour exécuter des analyses sur le nombre de prospects générés cette année, afin que le client puisse les comparer à ceux de l‘année dernière.
Migration aisée de Teradata vers Hadoop
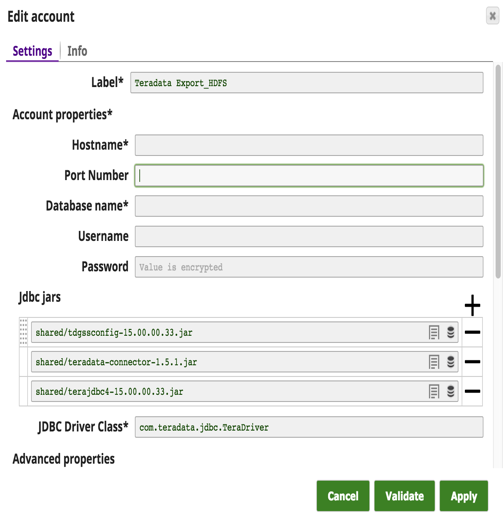
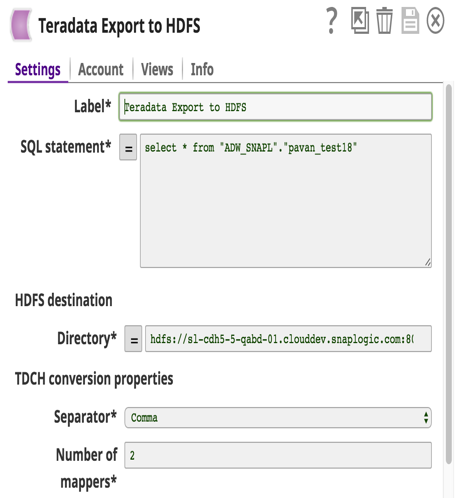
Un changement majeur s‘est opéré : les clients abandonnent les solutions Teradata coûteuses au profit d‘Hadoop ou d‘autres entrepôts de données. Jusqu‘à présent, il n‘existait pas de solution simple pour transférer de grandes quantités de données de Teradata vers Hadoop. Avec cette version, nous avons développé un Teradata Export to HDFS Snap avec deux objectifs à l‘esprit : 1) la facilité d‘utilisation et 2) la haute performance. Ce Snap utilise le Teradata Connector for Hadoop (TDCH v1.5.1). Les clients n‘ont qu‘à télécharger ce connecteur à partir du site web de Teradata Teradata en plus des jarres jdbc habituelles. Aucune installation n‘est nécessaire sur les nœuds Teradata ou Hadoop.
TDCH utilise MapReduce (MR) comme moteur d‘exécution où les requêtes sont soumises à ce cadre, et les processus distribués lancés par le cadre MapReduce établissent des connexions JDBC avec la base de données Teradata. Les données extraites seront directement chargées dans l‘emplacement HDFS défini. Le degré de parallélisme de ces travaux TDCH est défini par le nombre de mappers (une configuration Snap) utilisés par le travail MapReduce. Le nombre de mappers définit également le nombre de fichiers créés dans l‘emplacement HDFS.
Les détails du compte Snap avec un exemple de requête pour extraire des données de Teradata et les charger sur HDFS sont présentés ci-dessous.
La canalisation à cet effet est la suivante :
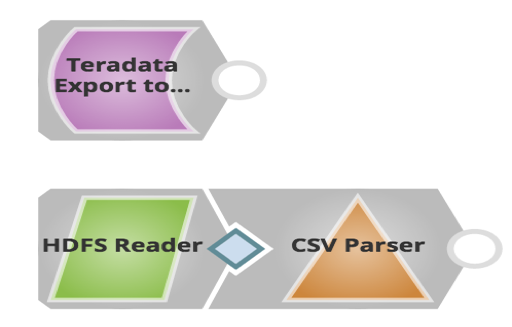
Comme vous pouvez le voir ci-dessus, vous n‘utilisez qu‘un seul Snap pour exporter des données de Teradata et les charger dans HDFS. Les clients peuvent ensuite utiliser le Snap HDFS Reader pour lire les fichiers exportés.
La version Winter 2017 a apporté de nombreux avantages aux clients, qu‘il s‘agisse de flux de données, de migrations faciles, d‘amélioration des fonctionnalités de sécurité ou d‘avantages en termes de performances. Pour plus d‘informations sur la version SnapLogic Winter 2017 (4.8), consultez les notes de version.
Pavan Venkatesh est chef de produit senior chez SnapLogic. Suivez-le sur Twitter @pavankv.




