





Von Pavan Venkatesh
Datenströme mit Confluent und Migration zu Hadoop: In meinem letzten Blogbeitrag habe ich erklärt, wie Trends der zukünftigen Datenbewegung aussehen werden. In diesem Beitrag gehe ich auf einige der spannenden Dinge ein, die wir als Teil der Snaps-Version Winter 2017 (4.8) angekündigt haben. Dabei geht es auch um künftige Datenbewegungstrends für Kunden, die Daten aus verschiedenen Systemen in die Cloud verschieben oder zu Hadoop migrieren möchten.
Zu den wichtigsten Highlights der Winterversion 2017 (4.8) gehören:
- Unterstützung von Confluent Kafka - ein verteiltes Nachrichtensystem für Datenströme
- Teradata zu Hadoop - Ein schneller und einfacher Weg, Daten zu migrieren
- Erweiterungen des Teradata Snap Packs: An der TPT-Front können Kunden Daten in Teradata schnell laden/aktualisieren/löschen
- Der RedShift Multi-Execute Snap - Ermöglicht die sequentielle Ausführung mehrerer Anweisungen, so dass Kunden die Geschäftslogik beibehalten können
- Verbesserungen des MongoDB-Snap-Pakets (Löschen und Aktualisieren) und des DynamoDB-Snap-Pakets (Löschen und Löschen-Element)
- Verbesserungen der Workday-Leseausgabe - Jetzt ist es für die nachgelagerten Systeme einfacher, sie zu nutzen
- Netsuite Snap Pack Verbesserungen - Benutzer können jetzt asynchrone Operationen übermitteln
- Verbesserungen der Sicherheitsfunktionen - Einschließlich SSL für MongoDB Snap Pack und Ungültigmachen von Datenbankverbindungspools, wenn Kontoeigenschaften geändert werden
- Wesentliche Leistungsverbesserung beim Schreiben in einen S3-Bucket mit S3 File Writer - Benutzer können jetzt eine Puffergröße im Snap konfigurieren, damit größere Blöcke schnell an S3 gesendet werden
Kafka ist ein verteiltes Nachrichtensystem auf der Grundlage des Publish/Subscribe-Modells mit hohem Durchsatz und hoher Skalierbarkeit. Es wird hauptsächlich für die Aufnahme von Daten aus mehreren Quellen verwendet, die dann an mehrere nachgeschaltete Systeme gesendet werden. Zu den Anwendungsfällen gehören die Verfolgung von Website-Aktivitäten, Betrugsanalyse, Protokollaggregation, Verkaufsanalyse und andere. Confluent ist das Unternehmen, das die Unternehmensfähigkeit und das Angebot für Open Source Kafka bereitstellt.
Hier bei SnapLogic haben wir Kafka Producer und Consumer Snaps als Teil des Confluent Snap Packs entwickelt. Ein tiefer Einblick in die Kafka-Architektur und ihre Funktionsweise ist eine gute Überleitung, bevor wir auf die Details des Snap Packs oder der Pipeline eingehen.
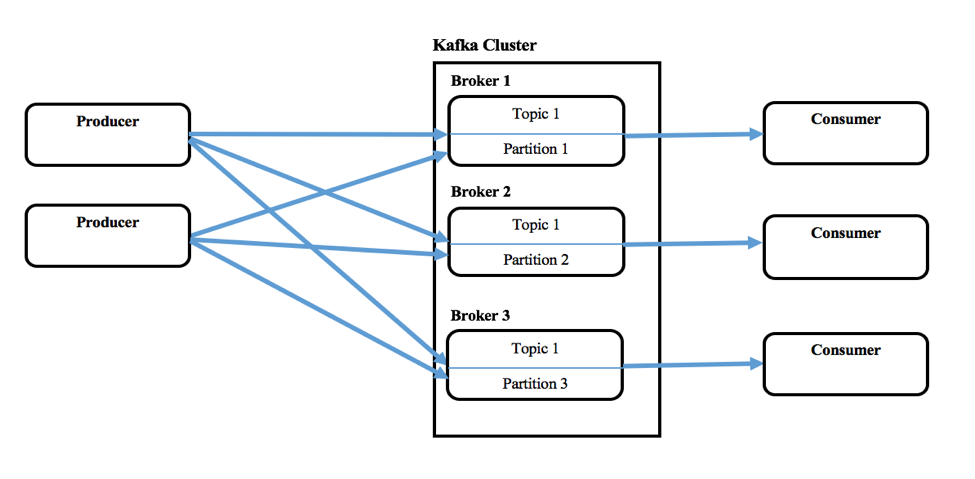
Kafka besteht aus einem oder mehreren Producern, die Nachrichten von einem oder mehreren Upstream-Systemen produzieren können, und aus einem oder mehreren Consumern, die Nachrichten als Teil von Downstream-Systemen konsumieren. Ein Kafka-Cluster besteht aus einem oder mehreren Servern, den Brokern. Nachrichten (Schlüssel und Wert oder nur der Wert) werden in eine höhere Abstraktionsebene namens Topics eingespeist. Jedes Topic kann mehrere Nachrichten von verschiedenen Producern enthalten. Der Benutzer kann auch verschiedene Themen für neue Nachrichtenkategorien definieren. Diese Produzenten schreiben Nachrichten in Topics und Konsumenten konsumieren von einem oder mehreren Topics. Außerdem werden Topics partitioniert, repliziert und über Brokers hinweg persistiert. Die Nachrichten in den Topics werden innerhalb einer Partition geordnet und jede dieser Partitionen hat eine fortlaufende ID-Nummer, die Offset genannt wird. Normalerweise verwaltet Zookeeper diese Offsets, aber Confluent nennt es Koordinationskernel.
Kafka ermöglicht auch die Konfiguration einer Consumer-Gruppe, zu der mehrere Consumer gehören, wenn sie von einem Topic konsumieren.
Mit über 400 Snaps, die verschiedene On-Prem- (relationale Datenbanken, Dateien, Nosql-Datenbanken und andere) und Cloud-Produkte (Netsuite, SalesForce, Workday, RedShift, Anaplan und andere) unterstützen, wird die Snaplogic Elastic Integration Cloud in Kombination mit dem Confluent Kafka Snap Pack eine leistungsstarke Kombination für die schnelle und streaming-basierte Übertragung von Daten an verschiedene Systeme sein. Kunden können so Vorteile realisieren und schnell Geschäftsergebnisse erzielen.
Was das Confluent Kafka Snap Pack betrifft, so unterstützen wir Confluent Version 3.0.1 (Kafka v0.9). Diese Snaps abstrahieren die Komplexität und die Benutzer müssen nur Konfigurationsdetails angeben, um eine Pipeline zu erstellen, die Daten einfach bewegt. Zu beachten ist, dass, wenn mehrere Consumer-Snaps in einer Pipeline verwendet werden und mit derselben Consumer-Gruppe konfiguriert wurden, jedem Consumer-Snap eine andere Teilmenge von Partitionen im Topic zugewiesen wird.
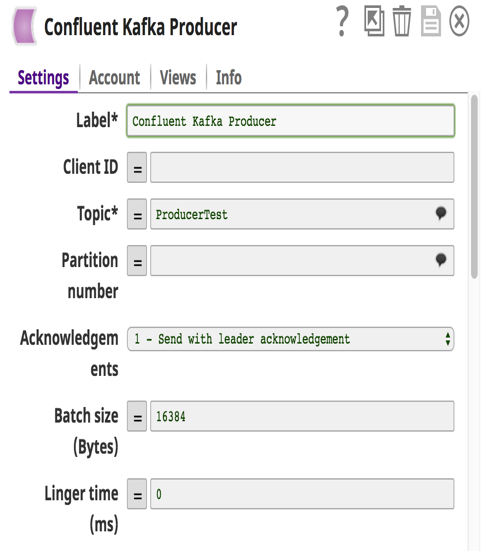
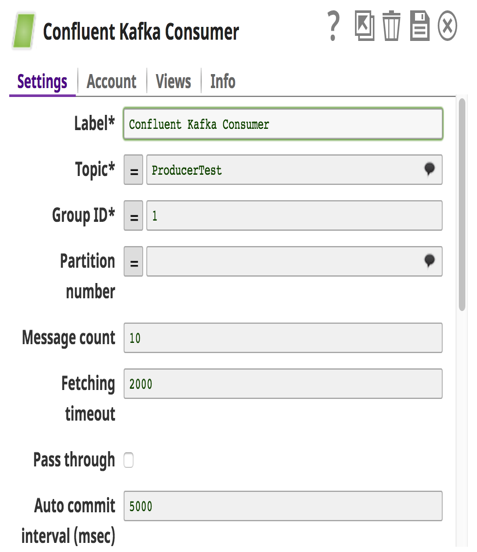
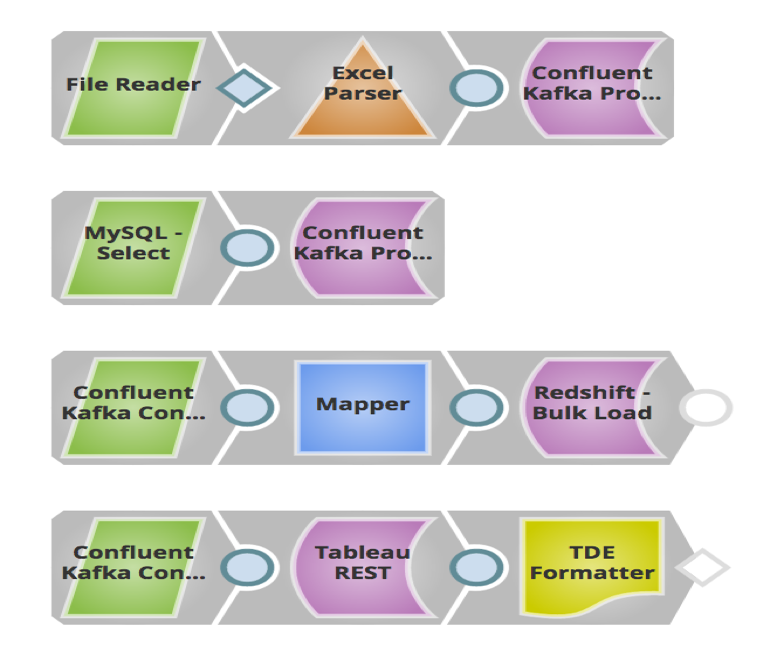
Im obigen Beispiel habe ich eine Pipeline aufgebaut, in der Vertriebsleads (Nachrichten), die in lokalen Dateien und MySQL gespeichert sind, über Confluent Kafka Producer Snaps an ein Topic in Confluent Kafka gesendet werden. Das nachgelagerte System Redshift konsumiert diese Nachrichten aus diesem Topic über den Confluent Kafka Consumer Snap und lädt sie in großen Mengen in RedShift für historische oder Audit-Bedürfnisse. Diese Nachrichten werden auch an Tableau als weiterer Consumer gesendet, um Analysen darüber durchzuführen, wie viele Leads in diesem Jahr generiert wurden, so dass der Kunde dies mit dem letzten Jahr vergleichen kann.
Einfache Migrationen von Teradata zu Hadoop
Es hat eine große Verschiebung stattgefunden, bei der die Kunden von teuren Teradata-Lösungen zu Hadoop oder anderen Data Warehouses wechseln. Bis jetzt gab es keine einfache Lösung für die Übertragung großer Datenmengen von Teradata zu Big Data Hadoop. Mit dieser Version haben wir einen Teradata Export to HDFS Snap entwickelt, der zwei Ziele im Auge hat: 1) Benutzerfreundlichkeit und 2) hohe Leistung. Dieser Snap verwendet den Teradata Connector für Hadoop (TDCH v1.5.1). Kunden müssen diesen Connector nur von der Teradata Website herunterladen. zusätzlich zu den regulären jdbc jars herunterladen. Eine Installation ist weder auf Teradata- noch auf Hadoop-Knoten erforderlich.
TDCH verwendet MapReduce (MR) als Ausführungsmaschine, wobei die Abfragen an dieses Framework übermittelt werden und die vom MapReduce-Framework gestarteten verteilten Prozesse JDBC-Verbindungen mit der Teradata-Datenbank herstellen. Die abgerufenen Daten werden direkt in den definierten HDFS-Speicher geladen. Der Grad der Parallelität für diese TDCH-Aufträge wird durch die Anzahl der Mapper (eine Snap-Konfiguration) definiert, die vom MapReduce-Auftrag verwendet werden. Die Anzahl der Mapper bestimmt auch die Anzahl der Dateien, die am HDFS-Speicherort erstellt werden.
Die Snap-Kontodetails mit einer Beispielabfrage zum Extrahieren von Daten aus Teradata und zum Laden in HDFS sind unten dargestellt.
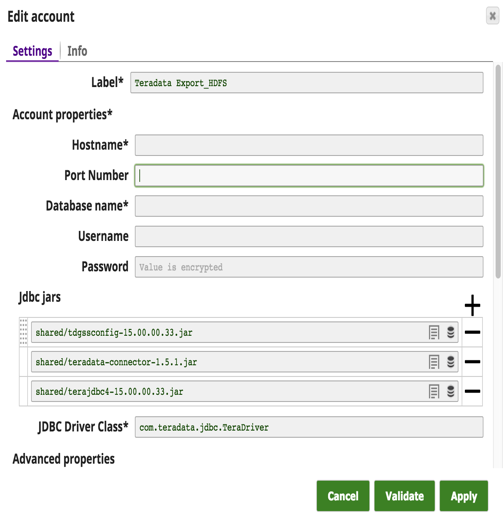
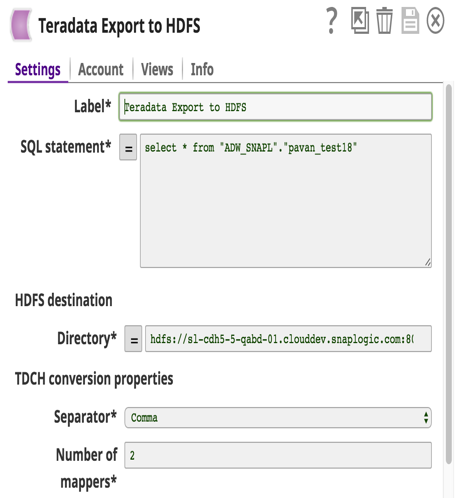
Die diesbezügliche Pipeline sieht wie folgt aus:
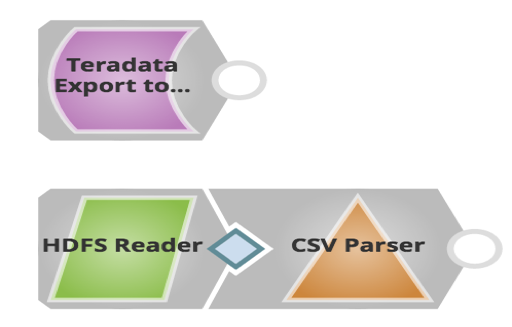
Wie Sie oben sehen können, verwenden Sie nur einen Snap, um Daten aus Teradata zu exportieren und sie in HDFS zu laden. Kunden können später den HDFS Reader Snap verwenden, um die exportierten Dateien zu lesen.
Das Winter 2017 Release bietet Kunden viele Vorteile, von Datenströmen über einfache Migrationen bis hin zu verbesserten Sicherheitsfunktionen und Leistungsvorteilen. Weitere Informationen über das SnapLogic Winter 2017 (4.8) Release finden Sie in den Versionshinweise.
Pavan Venkatesh ist Senior Produktmanager bei SnapLogic. Folgen Sie ihm auf Twitter @pavankv.




