





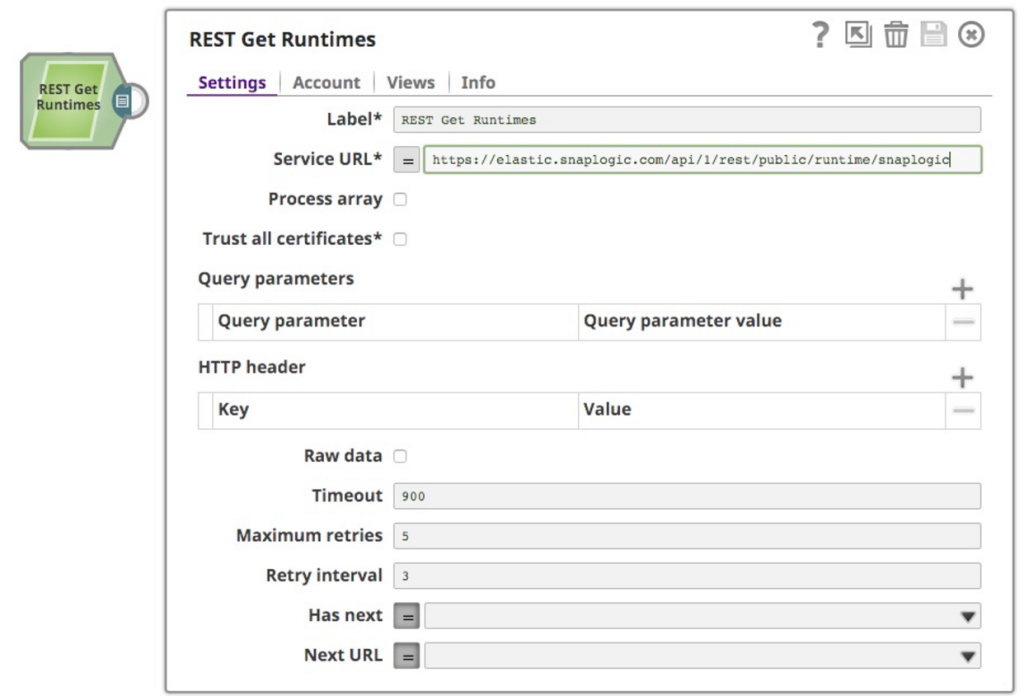
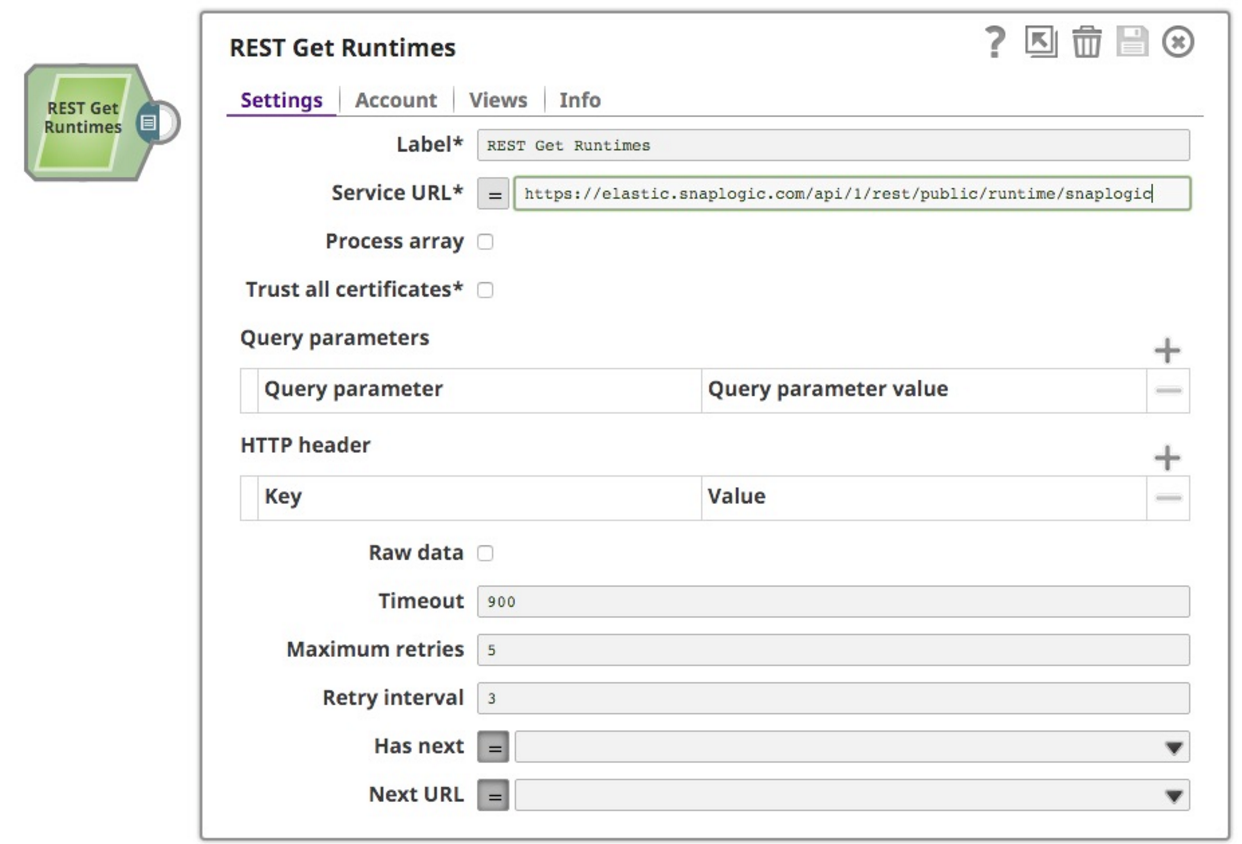
Dans le cadre d'un projet d'analyse plus large sur lequel je travaille, analysant les informations d'exécution de SnapLogic plateforme, j'ai choisi d'utiliser la fonctionnalité exposée à tous les clients, l'API publique pour l'API de surveillance des pipelines et l'API REST. Ces deux éléments sont combinés dans ce billet. J'ai commencé par lire la documentation (bien sûr), qui indique le format de la requête et de la réponse. J'ai donc créé un nouveau pipeline et déposé un REST GET Snap sur le canevas :
Je voulais obtenir les données d'exécution de l'org snaplogic sur SnapLogic plateforme . Dans l'URL, j'ai donc spécifié snaplogic comme org. L'autre chose à retenir est que l'API nécessite une authentification, j'ai donc créé un compte d'authentification de base avec mes informations d'identification. Cela fonctionne bien et me permet de récupérer les informations que je voulais, comme suit :
[
{
"headers": {
"x-frame-options": "DENY",
"connection": "keep-alive",
"x-sl-userid": "[email protected]",
"access-control-max-age": "17600",
"content-type": "application/json",
"date": "Sun, 31 Jan 2016 01: 29: 59 GMT",
"access-control-allow-credentials": "true",
"access-control-allow-methods": "GET, POST, OPTIONS, PUT, DELETE",
"x-sl-statuscode": "200",
"content-length": "5175",
"content-security-policy": "frame-ancestors 'none'",
"access-control-allow-origin": "*",
"server": "nginx/1.6.2",
"access-control-allow-headers": "authorization, x-date, content-type, if-none-match"
},
"statusLine": {
"reasonPhrase": "OK",
"statusCode": 200,
"protoVersion": "HTTP/1.1"
},
"entity": {
"response_map": {
"entries": [
{
"pipe_id": "1b10f684-24c0-4002-abd3-09b2e87e975f",
"ccid": "56ab61ed63766e7406c491ba",
"runtime_path_id": "snaplogic/rt/cloud/dev",
"subpipes": { },
"state_timestamp": "2016-01-31T01: 29: 43.758000+00: 00",
"parent_ruuid": null,
"create_time": "2016-01-31T01: 29: 43.484000+00: 00",
"id": "0aa7943d-d6c3-408c-9490-1d2b6b281227",
"runtime_label": "cloud-dev",
"cc_label": "prodxl-jcc1",
"documents": 9,
"user_id": "[email protected]",
"label": "REPORT - NGM FSM Ultra Task Failure Audit",
"state": "Completed",
"invoker": "scheduled"
},
...another 9 of these...
],
"total": 154,
"limit": 10,
"offset": 0
},
"http_status_code": 200
}
}
]Notez la petite section à la fin, avec le total, la limite et le décalage, indiquant que je n'ai récupéré que les 10 premiers temps d'exécution disponibles. La récupération d'un plus grand nombre de temps d'exécution fait appel à la fonctionnalité de "pagination" qui a été ajoutée à l'instantané REST GET l'année dernière (la documentation détaille des exemples d'utilisation de la pagination avec Eloqua, Marketo et HubSpot). Les deux champs de l'infobox pour le Snap sont "Has Next", un booléen qui indique s'il y a une itération supplémentaire à faire, et "Next URL", qui sont tous deux des expressions, de sorte que la condition peut être dynamique.
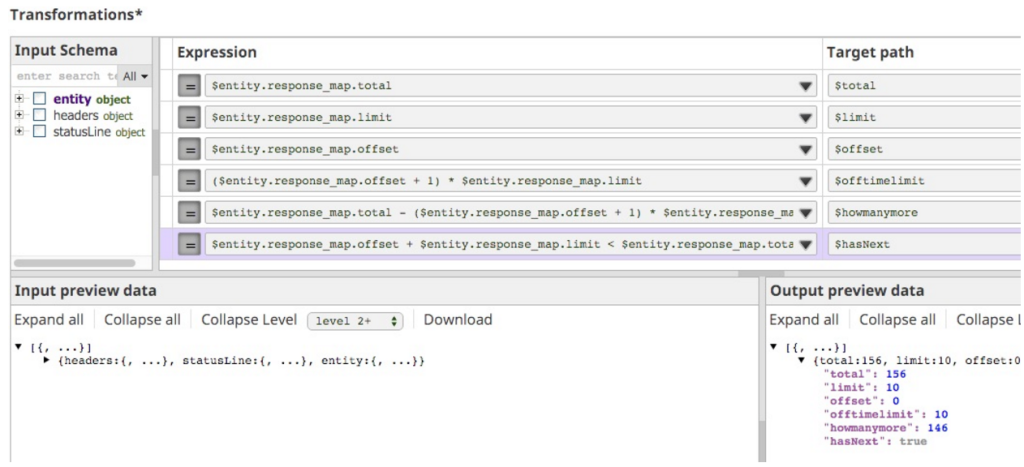
Dans le cas de mon API d'exécution SnapLogic, je devais déterminer, à partir de ces trois champs (total, limite, décalage), comment indiquer si l'URL suivante allait être, et laquelle. Pour mettre au point ma logique, j'ai donc placé un Mapper Snap next dans le pipeline afin de pouvoir itérer jusqu'à ce que j'obtienne les bonnes expressions.
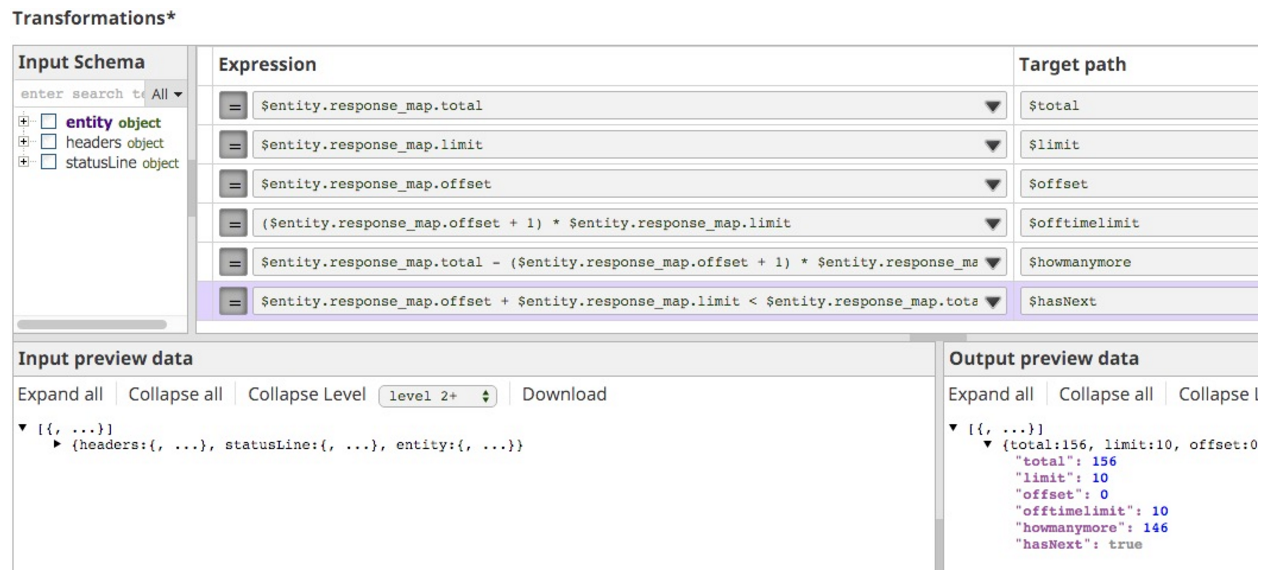
Pour vous donner une idée de la façon dont j'ai procédé, voici l'état de mon Mapper :
L'élément important ici est l'expression que j'ai utilisée pour indiquer s'il y a d'autres données à récupérer, hasNext:
$entity.response_map.offset + $entity.response_map.limit < $entity.response_map.total
Je peux maintenant l'appliquer à l'action REST GET, mais je dois d'abord trouver comment créer l'URL suivante. L'URL suivante sera la même que l'URL de service, mais en ajoutant simplement "?offset=n", où n est le nombre que j'ai déjà récupéré, moins un, car nous commençons toujours à compter dans le vrai style CS, avec 0 ! Mon URL est donc l'expression suivante :
'https://elastic.snaplogic.com/api/1/rest/public/runtime/snaplogic?offset=' + ($entity.response_map.offset+$entity.response_map.limit)
Vous devez vous assurer que les deux champs sont en mode expression.
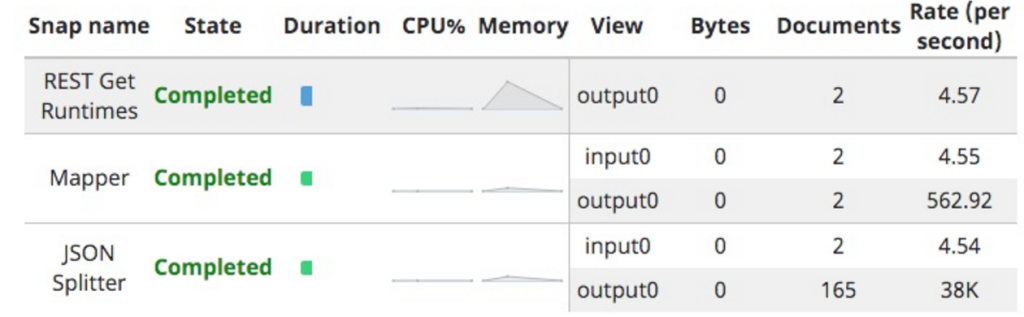
Nous pouvons tester cela pour nous assurer que l'ensemble des données est récupéré. Lorsque j'enregistre ce temps, l'aperçu du REST GET est le suivant :
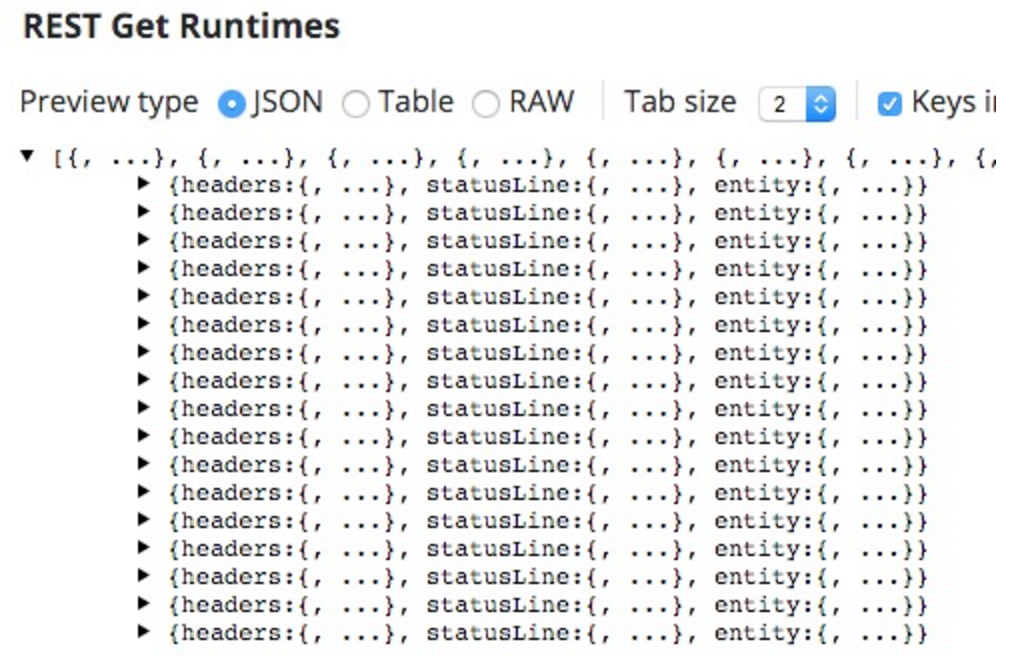
La fois où j'ai exécuté ce programme, le nombre de durées d'exécution était le suivant :

D'où les dix-sept itérations.

C'est là que réside un autre problème ; il se présente sous la forme de dix-sept documents, un pour chaque ensemble d'itérations, mais avec jusqu'à 10 (la taille limite par défaut) durées d'exécution par itération.
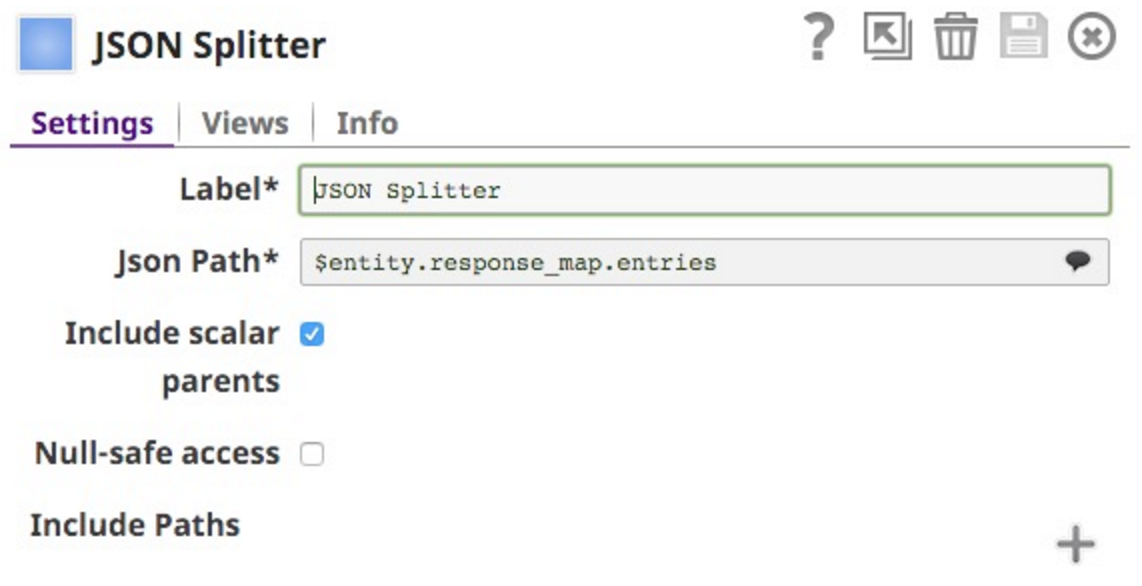
Cela m'oblige à placer un JSON Splitter Snap pour l'étendre :
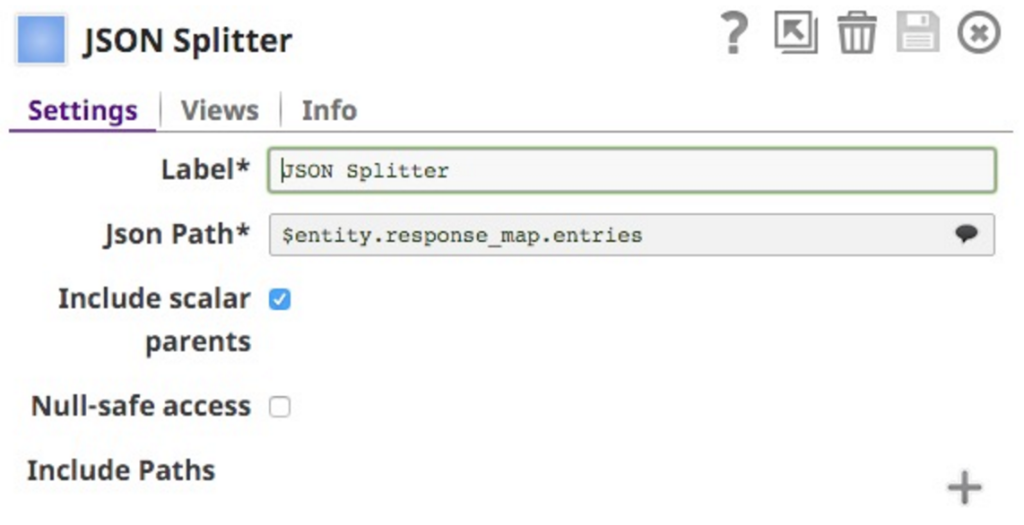
Notez que j'ai sélectionné $entity.response_mpa.entries comme chemin JSONPath à fractionner. Ceci est sélectionnable à partir de cette liste déroulante (notez que j'ai coupé le bas de la liste, elle continue pour toutes les clés dans le document :
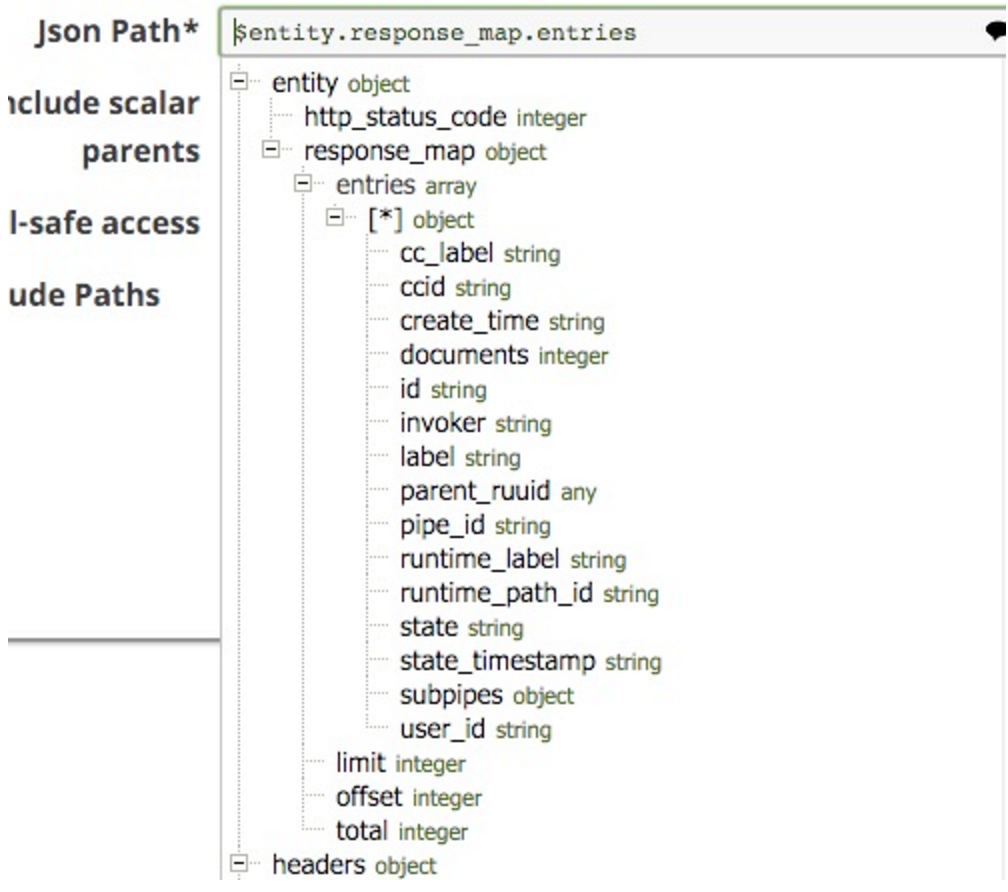
J'ai également inclus le parent scalaire, de sorte que chaque document inclut les parents directs :
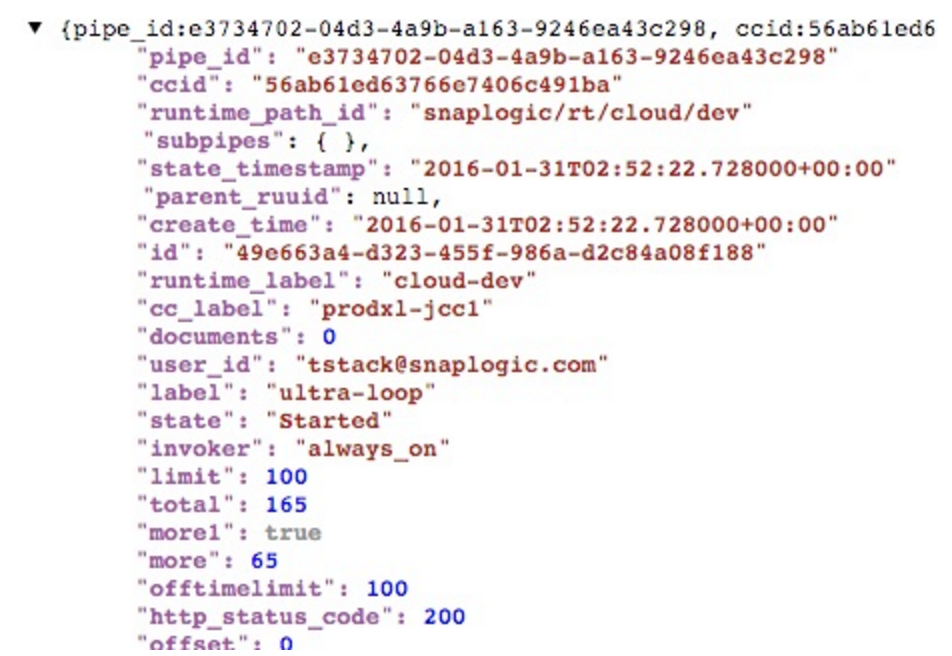
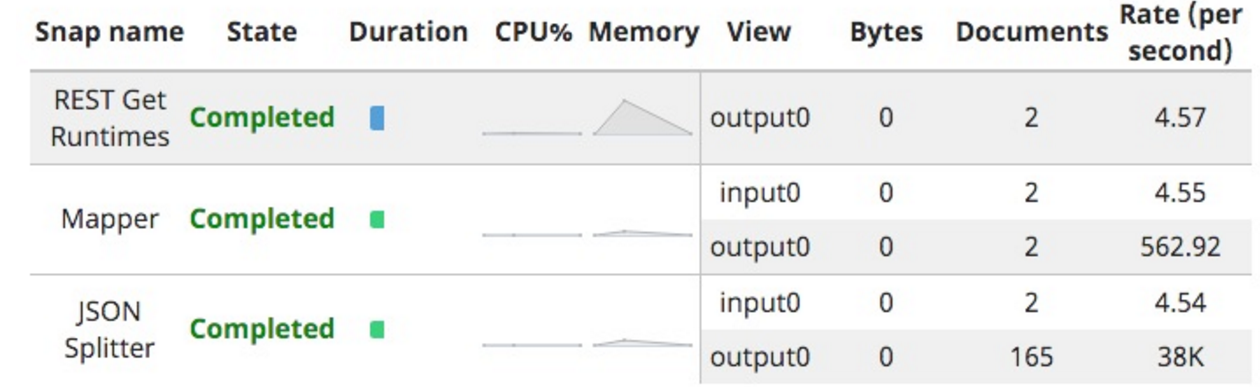
Désormais, lorsque j'exécute le programme, j'obtiendrai le nombre complet de durées d'exécution des pipelines, sous la forme de documents distincts :
Remarque : vous remarquerez peut-être que le nombre de durées d'exécution dans la demande varie au fil de cet article, ce qui s'explique par le fait que les données disponibles ont été différentes pendant la période de rédaction. Vous pouvez être spécifique avec les options de l'API pour être spécifique sur la période de la demande.
Prochaines étapes :
- Consultez les articles similaires de mon collègue Robin Howlett
- Consultez les articles de Greg Benson sur l'architecture de la plate-forme d'intégration élastique SnapLogic.
- Consultez nos vidéos pour voir SnapLogic en action ou demandez une démonstration personnalisée.






{kind=link}