






Introduction
De nombreux clients de SnapLogic combinent SnapLogic Intelligent Integration plateforme avec une grande variété d‘outils pour contrôler de bout en bout le cycle de vie des pipelines et autres actifs. Ces processus peuvent inclure la génération automatisée de tickets d‘assistance en cas d‘erreurs, des processus de révision manuels et automatisés via des systèmes de contrôle de version, des pipelines d‘intégration et de déploiement continus, ainsi que des tests unitaires et des contrôles de conformité et de qualité au sein de l‘entreprise.
Comme les entreprises ont des politiques, des exigences, des processus et des chaînes d‘outils différents, il n‘existe pas de recommandation ou de solution unique applicable à tous pour gérer et automatiser le cycle de vie de bout en bout.
Cette série d‘articles de blog a pour but de présenter un ensemble de défis auxquels les entreprises sont confrontées dans le cadre du développement d‘intégrations modernes et de montrer comment vous pouvez facilement relever ces défis grâce à SnapLogic. Plus précisément, cette série décrira également les personas d‘utilisateurs typiques impliqués dans ou autour de vos intégrations et comment la combinaison de SnapLogic et d‘autres outils peut aider à automatiser et à gouverner le cycle de vie de ces intégrations.
Dans la partie 1, vous apprendrez comment SnapLogic plateforme
- capturer automatiquement les erreurs,
- permet de signaler les erreurs en créant automatiquement des tickets contenant des informations détaillées sur l‘erreur et sur l‘état du système.
- aider les intégrateurs et les équipes de test à résoudre les problèmes en mettant l‘accent sur la réutilisation et la facilité d‘utilisation.
Personnages
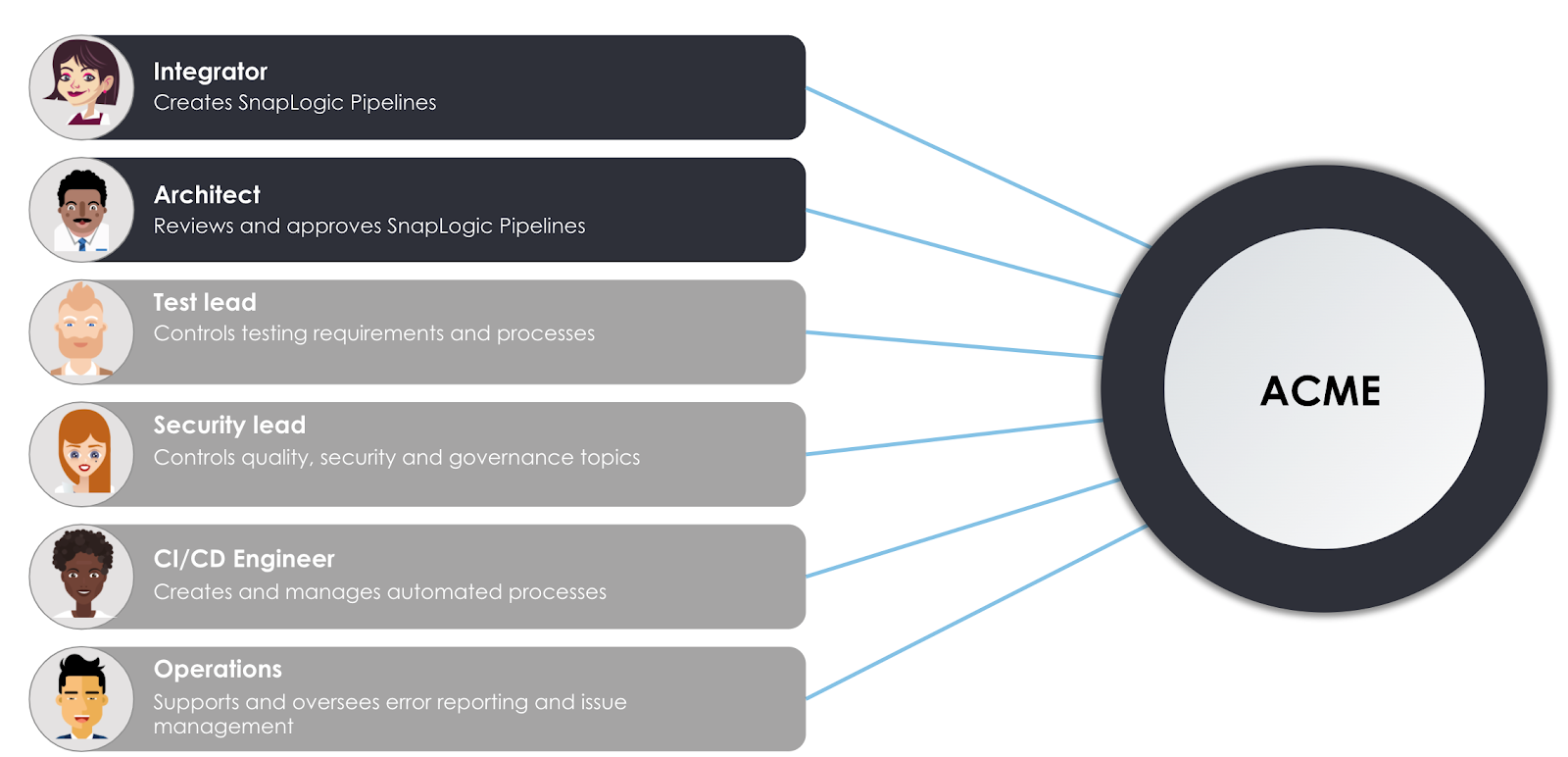
Considérons les personas d‘utilisateurs ci-dessus impliqués dans l‘entreprise fictive ACME.
- L‘intégrateur intégrateur est chargé de travailler avec SnapLogic Intelligent Integration plateforme pour concevoir et créer des pipelines afin de répondre aux besoins de l‘entreprise. Elle est également impliquée dans la révision des pipelines de ses collègues et demande à ses collègues de réviser son travail lorsqu‘il passe de la phase de développement et la production environnements
- Son collègue, l architecteest une personne expérimentée chargée d‘examiner les pipelines et les autres modifications apportées aux actifs au fur et à mesure qu‘ils passent d‘une organisation à l‘autre. Vous constaterez que l Intégrateur et l‘architecte jouent un rôle clé dans la fourniture des intégrations à l‘entreprise. Cependant, plusieurs autres rôles sont là pour s‘assurer que les intégrations sont fluides, automatisées, gouvernées et testées.
- Le Responsable des tests applique les directives et politiques générales de l‘entreprise en matière de tests à l‘outil et aux processus SnapLogic. Plus précisément, il s‘assurera que Les intégrateurs fournissent une couverture de test sous forme de tests unitaires avec les pipelines créés.
- De même, le responsable de la sécurité régit la sécurité des données et les contrôles de qualité de l‘entreprise. Dans notre scénario, il fournit un ensemble de politiques auxquelles les pipelines doivent adhérer.
- Afin d‘automatiser les processus, l‘ingénieur ingénieur CI/CD utilise un ensemble d‘outils et de services pour créer des pipelines automatisés basés sur les étapes du cycle de vie. Plus précisément, il crée des processus qui automatisent les vérifications des tests unitaires, les contrôles de qualité et les promotions du pipeline entre le service de développement et production de développement et de production.
- Enfin, bien que SnapLogic fournisse une introspection et une validation des schémas en temps réel pour aider les intégrateurs à créer des pipelines stables et prévisibles, une erreur dans un pipeline de production doit être détectée et des alertes doivent être générées. Les Opérations répond aux erreurs de production et supervise le cycle de vie des tickets du service d‘assistance, de la création à la résolution.
Note : Les rôles et responsabilités ci-dessus sont fournis à titre indicatif et ne s‘appliquent pas nécessairement à tous les clients SnapLogic. Par exemple, peu des rôles ci-dessus seront assumés par la même personne au sein d‘une organisation.
Automatisation du cycle de vie des pipelines SnapLogic
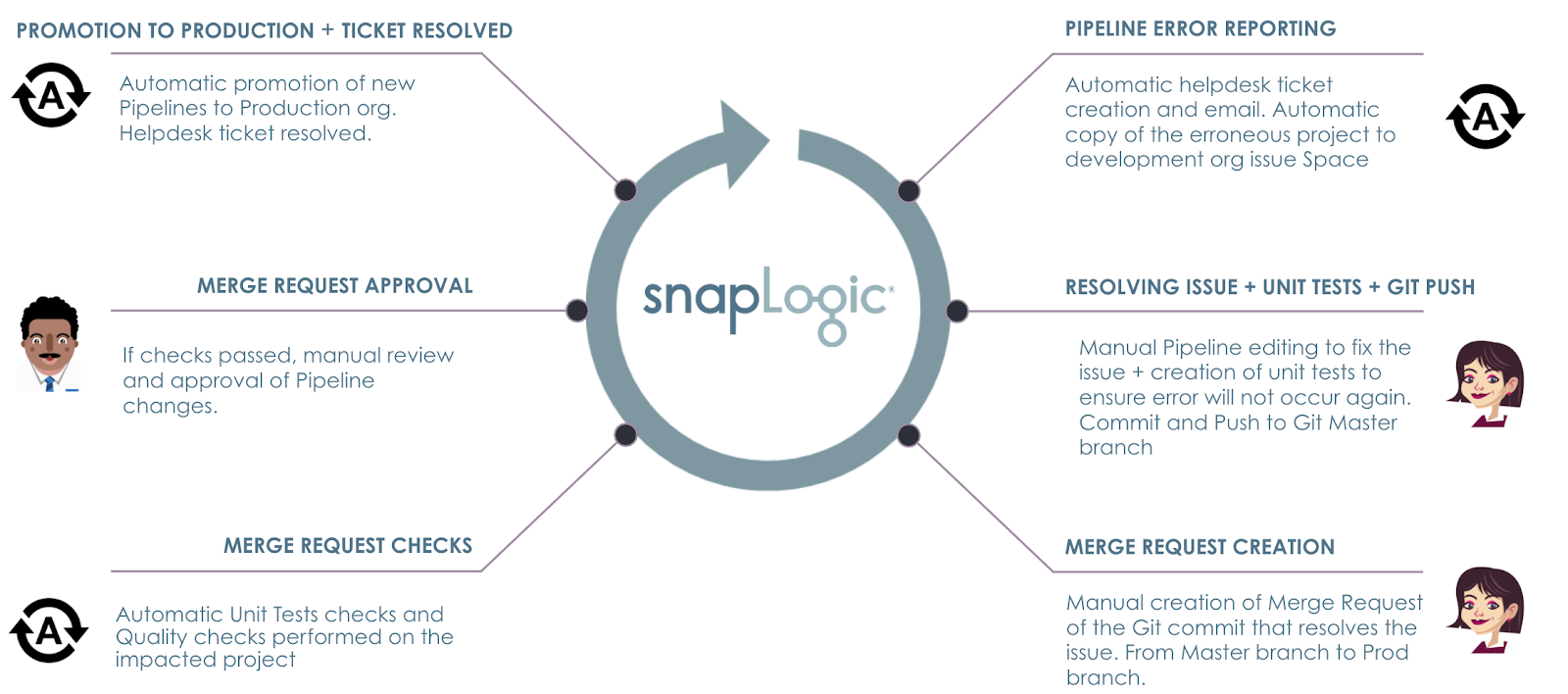
Considérons le scénario suivant : Une erreur se produit dans l‘un des systèmes de production de production. L‘objectif est de mettre en place des processus automatisés pour s‘assurer que
- L‘erreur est détectée et signalée à l‘aide de l‘outil d‘assistance et du système d‘alerte d‘ACME, sous la supervision de Opérations.
- Une copie du projet de pipeline peut immédiatement recevoir l‘attention de l‘Intégrateur. intégrateur pour commencer à corriger le problème dans le processus de développement de l‘entreprise.
- Les tests unitaires et les contrôles de qualité sont effectués avant que l l‘architecte avant que l‘architecte n‘approuve les changements.
- Une fois approuvés, les pipelines sont automatiquement promus au niveau de la production ce qui permet de corriger l‘erreur.
- Le ticket du service d‘assistance est automatiquement fermé lors de la promotion et une mise à jour est envoyée à l‘équipe d‘intervention. Opérations.
Les étapes du scénario ACME sont présentées ci-dessous.
Comme mentionné au début de cet article, les systèmes de helpdesk, les outils d‘alerte et d‘erreur, les systèmes de contrôle de version et les outils d‘intégration continue peuvent varier d‘un client à l‘autre. SnapLogic fonctionne de manière transparente quel que soit l‘outil choisi et nous n‘avons pas de chaîne d‘outils recommandée ou par défaut pour ce processus. Pour ce billet de blog, l‘entreprise fictive ACME a sélectionné les outils ci-dessous.
Rapport d‘erreurs sur les pipelines
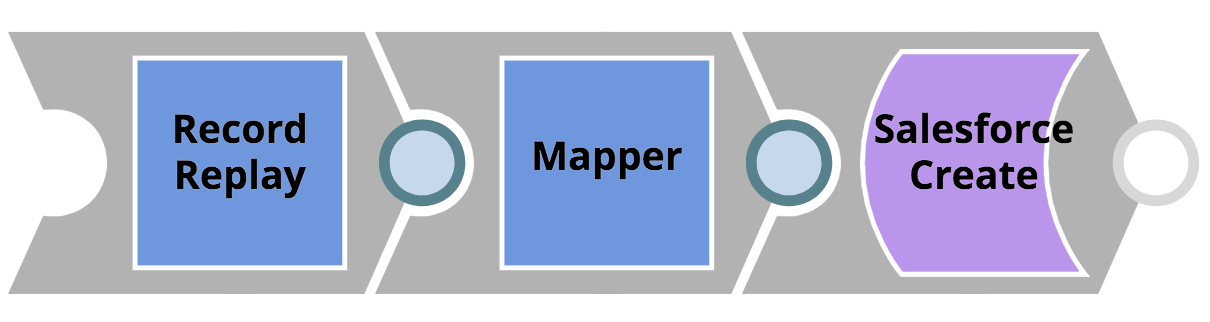
ACME a besoin de migrer son ancien système de gestion de la relation client vers Salesforce. Pour ce faire, CustomerToSalesforce, un pipeline SnapLogic, recevra les enregistrements de clients existants du CRM existant par le biais d‘une Tâche déclenchée qui expose une API REST.
- Les ressources de cette intégration se trouvent dans un projet appelé CRM_MIGRATION dans la section Production de l‘organisation.
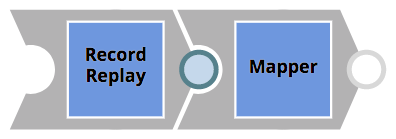
- Les enregistrements des clients transmis dans l‘appel REST seront mappés à un objet Salesforce. Avant l‘instantanéité du Mapper Snap n‘applique le mappage, une Snap de relecture d‘enregistrement est utilisée pour enregistrer l‘objet entrant dans le système de fichiers, ce qui permettra d‘examiner ultérieurement les données client en cas de problème potentiel. Ce pipeline très simple est illustré ci-dessous.
L‘image ci-dessous montre la configuration du Mapper Snap. Elle suppose que l‘appel REST entrant contient les objets suivants dans le corps JSON : prénom, nom, société et revenu. L‘objet Salesforce n‘a pas d‘attribut prénom ni de nommais un mappage est créé pour concaténer le prénom avec nomdernier en un seul Nom propriété.
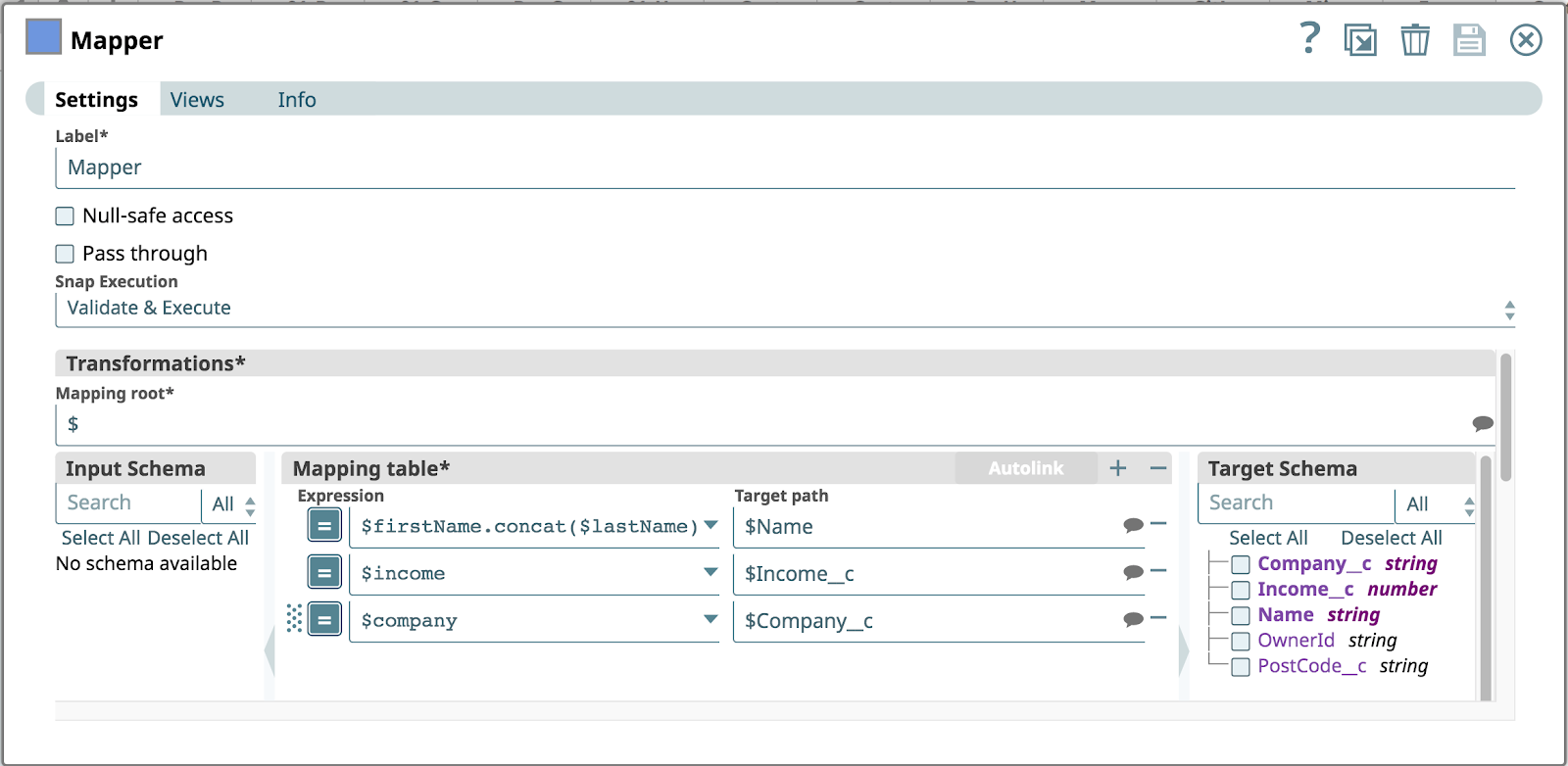
Pouvez-vous d‘ores et déjà repérer les failles potentielles dans la conception et les données de ce pipeline ?
Oui, vous avez compris ! Le pipeline suppose que l‘ancien système de gestion de la relation client fournit toutes les données d‘entrée nécessaires. ACME n‘ayant pas mis en place ses processus et ses contrôles à temps, ce pipeline a été mis en production sans tests unitaires ni contrôles de qualité.
Malheureusement, l‘ancien système de gestion de la relation client qui invoque l‘API REST transmet un objet client auquel il manque l‘élément firstName n‘est pas renseigné. Par conséquent, la première Expression dans la table de correspondance provoquera une erreur car l‘opération de concat échouera.
SnapLogic plateforme fournit pipelines d‘erreurs pour chaque Snap afin de gérer ces cas d‘erreur. Les événements suivants se produisent maintenant.
- L‘erreur est détectée par un pipeline d‘erreurs.
- Le pipeline d‘erreurs crée un ticket JIRA et alerte l‘utilisateur. Opérations en envoyant un courriel
- Le pipeline d‘erreurs copie le projet impacté du projet de production vers un espace d‘émission dans l‘environnement de développement développement
En plus de l‘acheminement de l‘erreur qui s‘est produite en raison de l‘absence de l‘élément firstName manquant, le pipeline transmet quelques propriétés propriétés du pipeline comme paramètres au pipeline d‘erreurs appelé ErrorReporting.
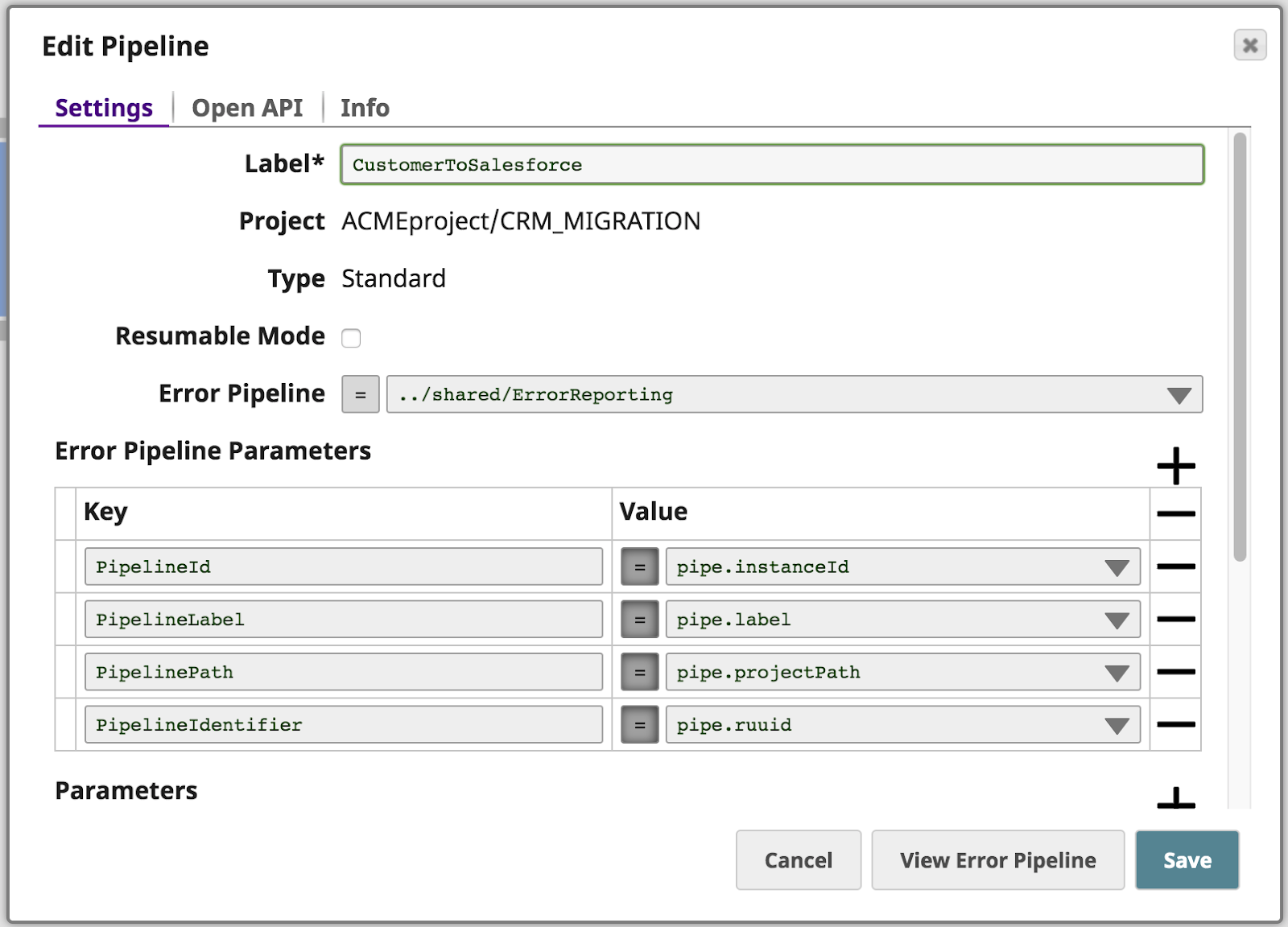
Le pipeline d‘erreurs est présenté ci-dessous. Tout d‘abord, il prend les informations d‘erreur et les paramètres du pipeline et les met en correspondance avec la fonction JIRA Create Snap. Ensuite, il prend la réponse de JIRA (en particulier l‘URL du ticket JIRA qui en résulte) et transmet le document à deux branches à l‘aide de la fonction Copy Snap. La branche supérieure transmet le document à un autre pipeline à l‘aide de l‘action Snap d‘exécution de pipeline. La branche inférieure formate les informations dans un courriel HTML qui est envoyé aux personnes suivantes Opérations à l‘aide de l‘action Snap d‘expéditeur d‘email.
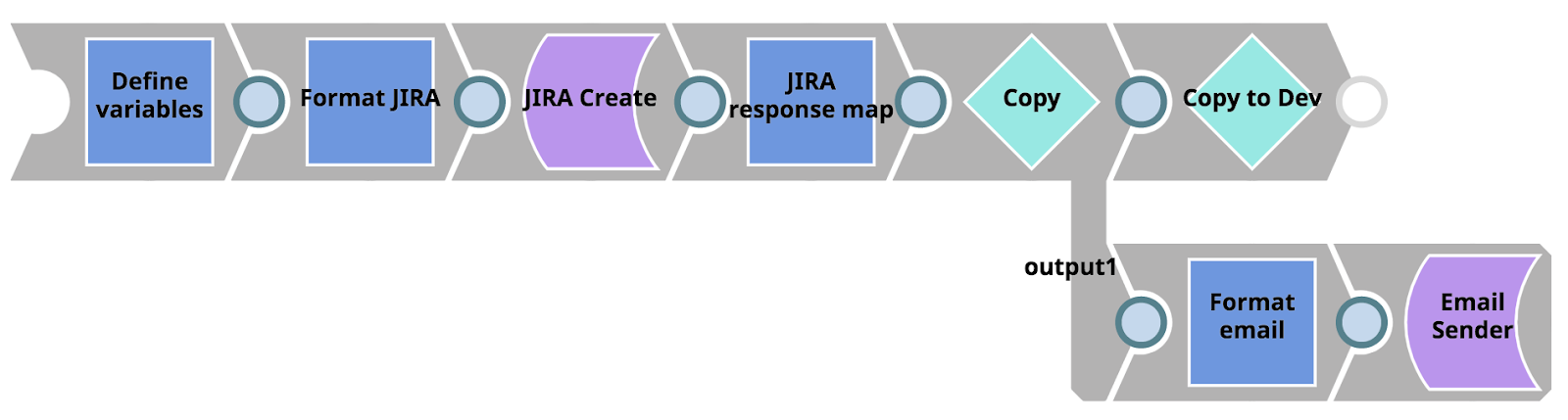
Tout d‘abord, concentrons-nous sur le pipeline enfant invoqué par notre pipeline d‘erreurs à l‘aide de l‘instantané d‘exécution du pipeline (étiqueté comme "Copy to Dev"). Simplement, ce pipeline tire parti de l‘option Metadata Snap Pack afin de lister, récupérer, mapper et mettre à jour les actifs entre le projet dans la zone de production et l‘Issue Space dans l‘environnement de développement dans l‘environnement de développement. Une fois le pipeline terminé, des copies exactes des actifs du projet où l‘erreur s‘est produite seront disponibles pour l intégrateur pourra commencer à travailler dans l‘environnement de développement org.
Il est important de ne pas essayer de résoudre le problème dans l‘interface de production. production en contournant les processus et les contrôles existants.

Ensuite, voyons le résultat des autres actions entreprises par le pipeline d‘erreurs. L‘image ci-dessous montre l‘e-mail qui a été automatiquement envoyé à Opérations. Il mentionne quelques liens pertinents, mais surtout il renvoie au ticket JIRA généré automatiquement.
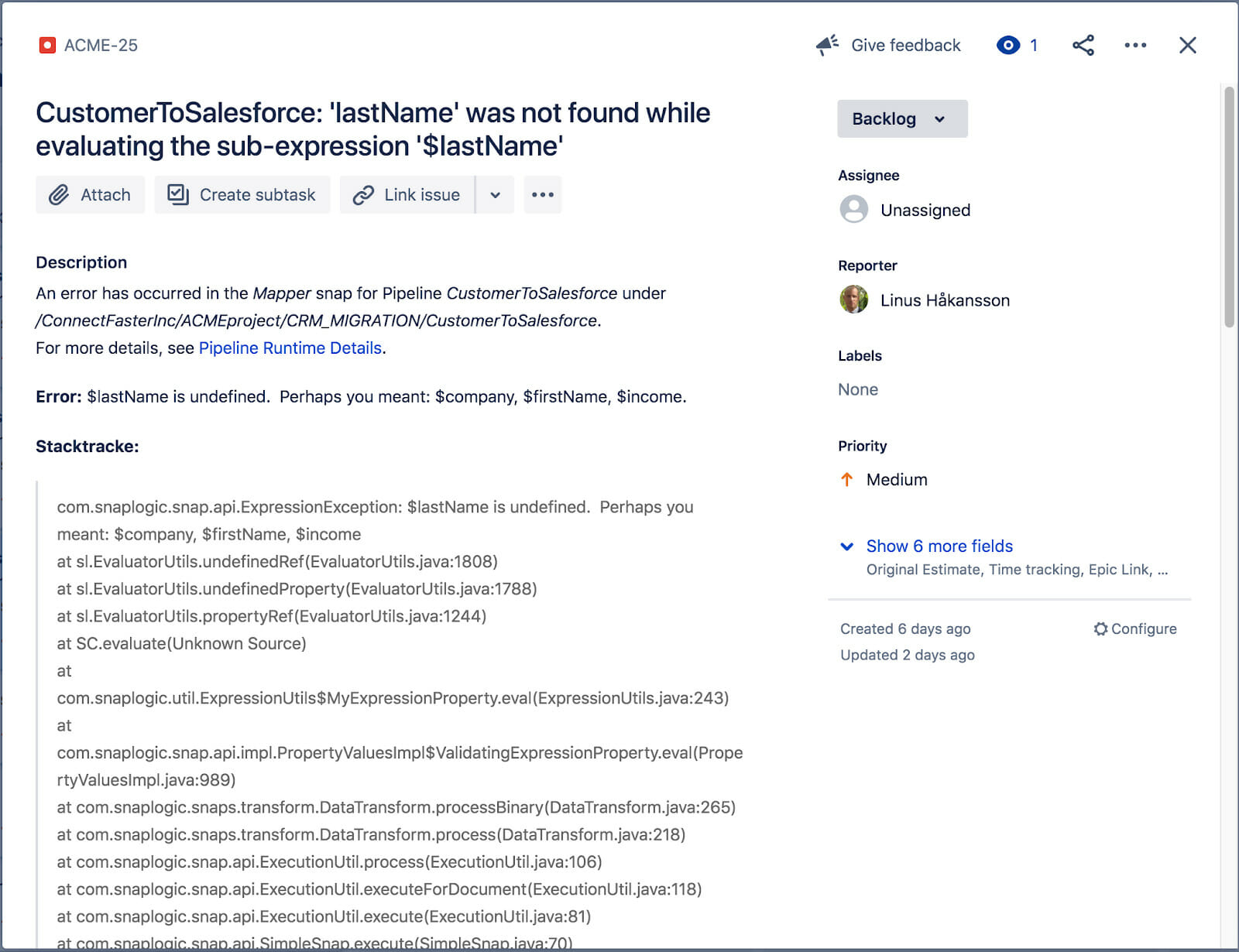
Le ticket JIRA lié peut être vu ci-dessous. Il comprend le titre de l‘erreur, la description, le tracé de la pile, la résolution (pas à l‘écran) ainsi qu‘un lien vers les détails de l‘exécution du pipeline où l‘erreur s‘est produite. Nos Opérations et intégrateur disposent désormais de suffisamment d‘informations pour commencer à résoudre le problème.
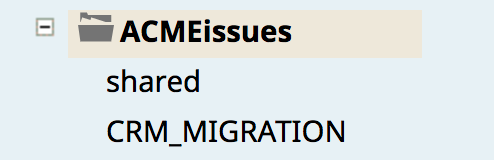
Enfin, l‘image ci-dessous montre la nouvelle copie du fichier CRM_MIGRATION (qui contient le pipeline et la tâche CustomerToSalesforce) qui a été copié depuis le projet de production vers l‘environnement de développement de l‘environnement de développement (ACMEissues).
Résolution des problèmes + Tests unitaires + Git Push
Notre intégratrice est maintenant en mesure de s‘occuper du problème hautement prioritaire et de commencer son travail. Comme elle dispose maintenant d‘exigences et de lignes directrices appropriées en matière de tests de la part de son responsable des testselle va également créer des tests unitaires pour s‘assurer que l‘erreur ne se reproduira pas. Lorsqu‘elle aura terminé, elle utilisera le "Gitlab Push Pipeline" afin de pousser un nouveau commit sur la branche Master Git.
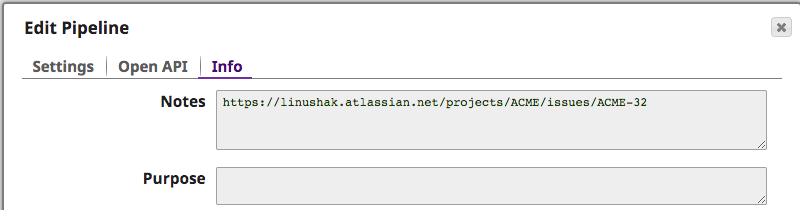
Pour mieux comprendre quelle erreur a causé le problème, l‘intégrateur peut inspecter les notes du pipeline copié qui a causé le problème. Automatiquement, le ticket JIRA a été inséré pour fournir plus d‘informations comme on peut le voir ci-dessous.
Le responsable des tests recommande la logique suivante pour activer les tests unitaires pour les pipelines.
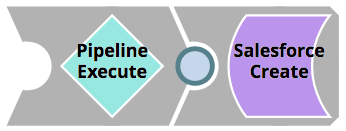
Break out the logic into a separate Pipeline. This will not only make unit testing easier, but also enable reuse of components. This Pipeline should be called <Pipeline_name>_target. The original Pipeline should now instead have a Pipeline Execute Snap that executes the Pipeline housing the logic.
- Create a pipeline as <Pipeline_name>_test qui charge les données de test et exécute le <Pipeline_name>_target Pipeline avec ces données. Il enregistre ensuite le résultat dans un fichier séparé.
- The test data should reside in a file as <Pipeline_name>_input.json
- The result data should be written to a file as <Pipeline_name>_result.json

Note : La manière dont les tests sont exécutés est abordée dans une étape ultérieure de ce billet.
L'intégrateur Intégrateur adapte son pipeline CustomerToSalesforce comme indiqué ci-dessus et crée les pipelines CustomerToSalesforce_target (pour la logique) et CustomerToSalesforce_test (pour la lecture et l'enregistrement des données d'entrée/sortie). Pour s'assurer que les propriétés requises du client CRM existent et corriger efficacement l'erreur, elle adapte le pipeline logique comme suit
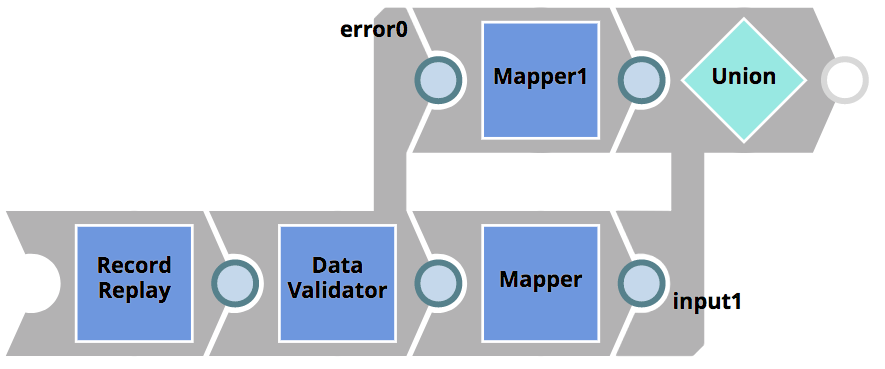
L‘instantanéité du validateur de données Data Validator Snap est utilisé pour vérifier l‘existence des propriétés requises (i.e. prénom et nom). Si les vérifications ne sont pas concluantes, le document est acheminé vers la vue d‘erreur avant d‘être renvoyé au client. Grâce à cette logique, le client CRM existant aura la possibilité d‘agir sur l‘erreur.
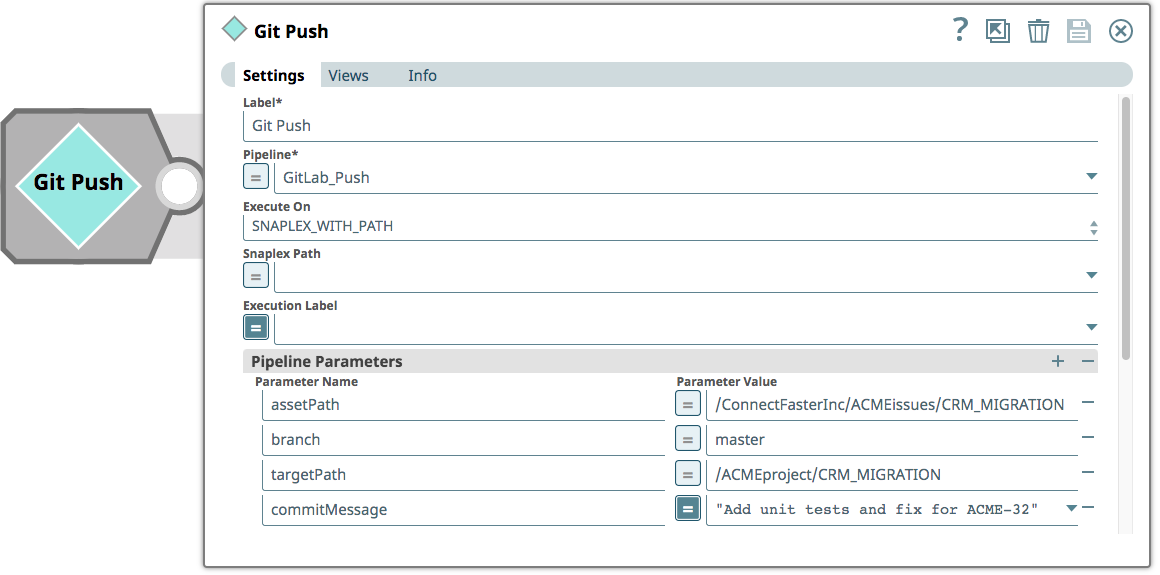
Enfin, l‘intégrateur pousse les pipelines vers la branche Master du dépôt GitLab. Le pipeline utilisé pour invoquer le processus de poussée d‘un commit vers GitLab consiste en un seul Snap ‘Pipeline Execute‘ qui prend des paramètres pour le chemin de l‘actif (le projet dans lequel chercher les changements), la branche (dans le dépôt GitLab), un chemin cible (le projet réel - le dépôt Git ne contient pas de références aux environnements) et un message de commit - dans ce cas faisant référence au numéro de ticket JIRA.
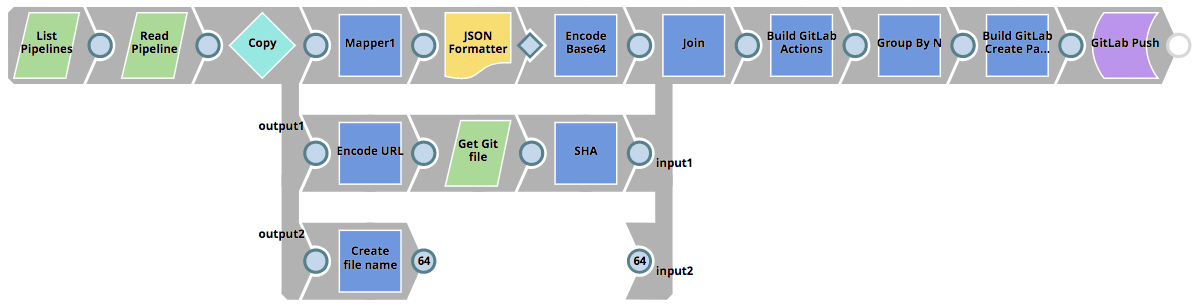
La Pipeline GitLab_Push qui est invoquée peut être vue ci-dessous. Elle lit toutes les Pipelines du projet sélectionné, détermine si les Pipelines doivent être créés dans le dépôt Git ou mis à jour (si une SHA existe déjà) et pousse ensuite un commit vers GitLab.
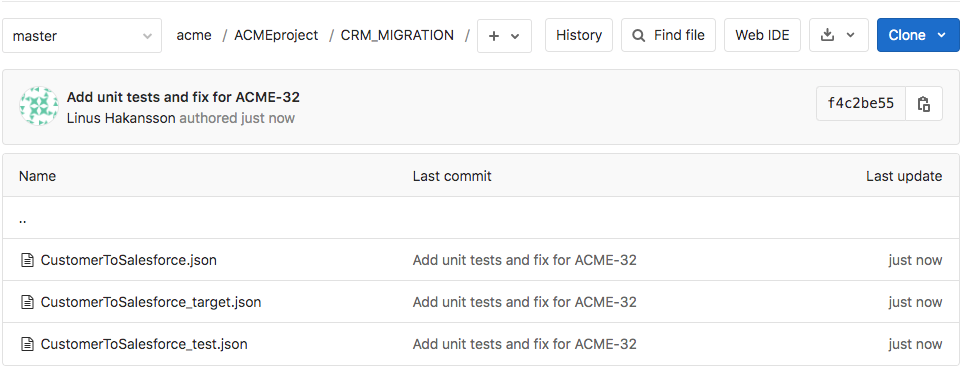
Le résultat de l‘exécution de la Pipeline GitLab_Push est reflété dans le dépôt GitLab comme indiqué dans l‘image ci-dessous. Dans l‘image, la branche Master est actuellement sélectionnée et le navigateur de fichiers affiche les fichiers dans le répertoire ACMEproject/CRM_MIGRATION. Les modifications apportées au pipeline CustomerToSalesforce, ainsi que les deux nouveaux pipelines de tests unitaires ont été ajoutés au référentiel dans le cadre du commit.
Consultez la partie 2 de cette série pour en savoir plus sur les meilleures pratiques concernant la gestion du cycle de vie des demandes de fusion et la promotion des changements dans l‘environnement de production pour vos ressources d‘intégration !







