





YARN is the prerequisite for Enterprise Hadoop. It provides resource management across Hadoop clusters and extends the power of Hadoop to new technologies so that they can take advantage of cost effective, linear-scale storage and processing. It provides ISVs and developers a consistent framework for writing data access applications that run IN Hadoop.
Customers building a data lake expect to operate on the data without moving it to other systems, leveraging the processing resources of the data lake. Applications that use YARN fulfill that promise, lowering operational costs while improving quality and time-to-insight.
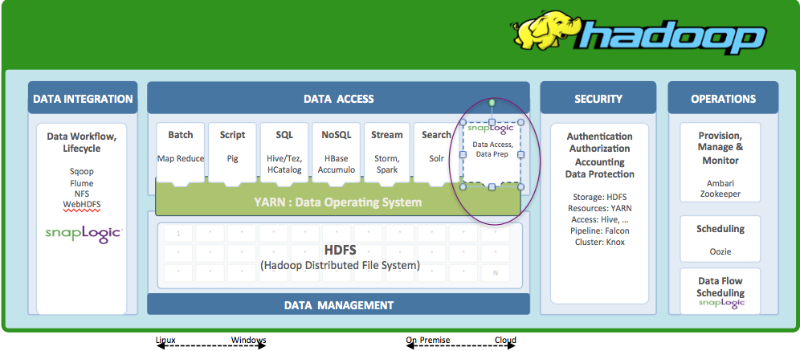
Integration with YARN
To harness the power or YARN, a third party application can either use YARN natively or use a YARN framework (Apache Tez, Apache slider, etc.) and if it does not use YARN it most probably reads directly from HDFS.
There are 3 broad options for integration into YARN.
- Full Control or YARN native: Fine grained control of cluster resources, which allows elastic scaling.
- Interaction through an existing YARN framework like MapReduce: Limited to one of batch or interactive or real time. No support for elastic scaling using YARN.
- Interaction with applications already running on a YARN framework like Hive: Limited to very specific applications or use cases for example using Hive. No support for elastic scaling using YARN.
Obviously any application, which has full control and is yarn native, provides a significant advantage to be able to do very advanced things within Hadoop using the capabilities of YARN.
This difference is necessary as the space become more interesting and confusing at the same time. Hadoop vendors like Hortonworks offer both Yarn Native and Yarn Ready certifications. Yarn ready means that an application can work with and is limited to any of the Yarn enabled applications like Hive, whereas Yarn Native means full control and fine-grained access of cluster resources.
SnapLogic is Yarn Native. This means as data volumes or workloads increase, the SnapLogic Elastic Integration Platform can automatically, elastically scale out leveraging more nodes in the Hadoop cluster on demand, and as these workloads decrease, scale down automatically. This in SnapLogic is called the Hadooplex. This blog post reviews examples of SnapLogic big data integration pipelines.
This post originally appeared on LinkedIn. Ravi Dharnikota is a Sr. Advisor SnapLogic, working closely with customers on their big data and cloud reference architecture.



