La scorsa settimana, parte del team di SnapLogic era a New York City per la conferenza Strata/Hadoop World. Si tratta di uno dei più grandi eventi sui big data negli Stati Uniti e negli ultimi anni è cresciuto costantemente. Anche l'agenda è cambiata un po', passando da discussioni perlopiù accademiche e presentazioni di tipo "how-to" da parte di committer open source a casi di studio reali da parte di aziende non ISV.
A questo proposito, vorrei condividere la storia di uno dei nostri clienti aziendali. Si tratta di un istituto finanziario di oltre 100 anni. Forse non è un'azienda che si potrebbe associare all'avanguardia delle tecnologie di gestione dei dati... Per la natura del loro settore, non posso condividere il loro nome.
Come molte aziende affermate, i sistemi di elaborazione e archiviazione dei dati di questa banca sono stati acquisiti o aggiunti nel corso degli anni in base alle esigenze più pressanti e ai requisiti di conformità del momento. Alla fine si sono trovati a dover gestire un mix ingombrante di oltre 240 interfacce e applicazioni.
Come si può immaginare, i dati erano disponibili in un'ampia varietà di formati, come file Excel, file di testo delimitati (csv), copybook a lunghezza fissa e variabile e file zippati. Inoltre, le fonti di dati erano molteplici, come ftb/sftp, QlikView business intelligence e database SQL Server, Oracle e Sybase. La gestione di questo ambiente non era solo difficile, ma anche dispendiosa in termini di tempo, con un onere significativo per le risorse del personale IT e una pressione sui bilanci.
La conservazione dei dati per un determinato periodo di tempo è un requisito normativo del settore bancario, quindi trovare una soluzione di archiviazione efficiente ed economica era il caso d'uso più urgente, ma l'azienda voleva anche utilizzare in modo più efficace i dati dei clienti.
Per modernizzare l'approccio alla gestione e all'archiviazione dei dati e, in ultima analisi, supportare un servizio clienti più snello e migliorato, l'azienda ha deciso di eliminare una serie di database legacy e applicazioni mainframe, modernizzare l'approccio alla conservazione dei dati e accelerare le analisi aziendali con Hadoop e un data lake.
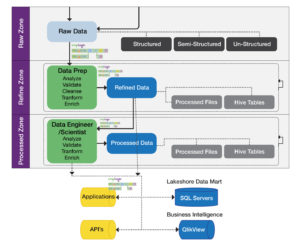
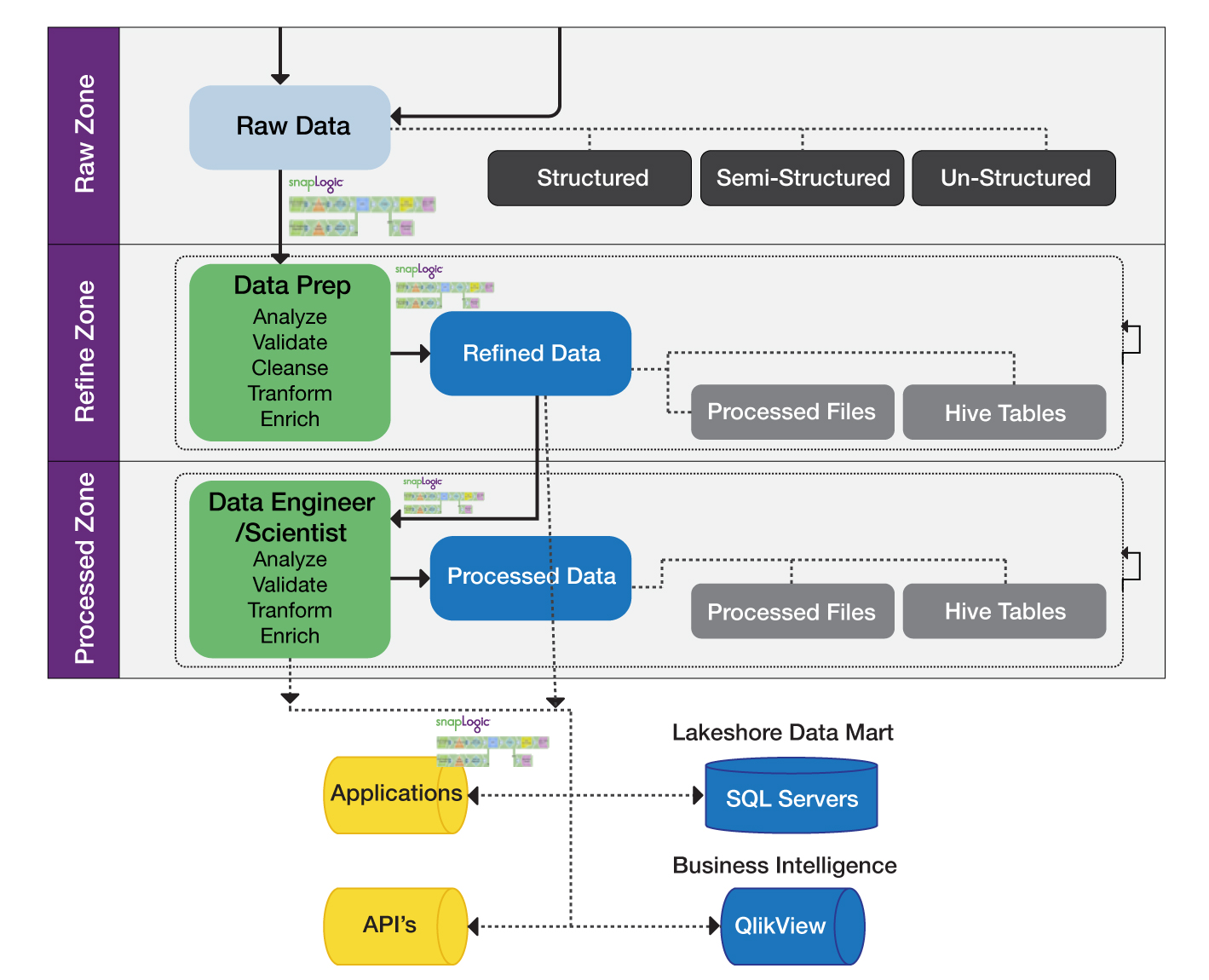
Dopo aver valutato le modalità di realizzazione interna e aver esplorato le opzioni presenti sul mercato, compresi gli strumenti open source, hanno deciso di utilizzare SnapLogic Elastic Integration Platform in combinazione con un ambiente Hadoop basato su Cloudera. SnapLogic ha permesso di eseguire l'ingestione, la preparazione e la distribuzione dei dati in un unico Data Hub, supportando così il pensionamento dei vecchi database e delle applicazioni mainframe e consolidando i dati provenienti da più fonti in un data lake. Nella fase successiva del progetto, SnapLogic consentirà anche di realizzare un "data lake self-service" per le future esigenze di reporting.
Dopo aver utilizzato SnapLogic per consolidare le fonti di dati interne e mandare in pensione molti dei database esistenti e delle applicazioni mainframe che supportavano i dati aziendali interni, hanno aggiunto al Data Hub dati esterni provenienti da fornitori di dati finanziari di terze parti. Quando la loro visione sarà completata, disporranno di un set completo di dati integrati in un Cloudera Data Hub per una conservazione dei dati efficiente ed economica. Questo fornirà anche le basi per il loro prossimo progetto, che sfrutterà il Data Hub per una visione a 360 gradi del cliente e, di conseguenza, per una migliore assistenza ai clienti.
Invece di considerare i dati solo come un problema di conservazione per la conformità alle normative del settore, il Data Hub o data lake di questa banca è visto come un asset strategico. Più che un semplice "storage distribuito a basso costo", il data lake basato su Hadoop è una risorsa centralizzata per l'analisi e l'approfondimento dei dati. Grazie a questi dati aziendali consolidati, l'azienda sarà in grado di visualizzare tutti i dati per cliente e relazione, fornendo così informazioni preziose su come migliorare il servizio clienti complessivo. Noi di SnapLogic siamo orgogliosi di essere un elemento fondamentale per la visione del data lake.
Come ci ha detto il nostro cliente campione: "La sfida iniziale consisteva nel gestire la conformità e i requisiti normativi del settore finanziario. Quando abbiamo pensato a modi innovativi per gestire meglio la situazione, ci è venuto in mente un modo per prendere due piccioni con una fava, per così dire. Che ne dite di un sistema di archiviazione e conservazione dei dati che funga anche da hub di dati per fornire approfondimenti?
La soluzione era chiara, ma il compito era scoraggiante e irto di problemi di competenze. Così siamo partiti coraggiosamente con poco, un DBA junior per aiutarci e la guida di Cloudera e SnapLogic che ci hanno aiutato a progettare e implementare la nostra visione".