





Last week, part of the SnapLogic team was in New York City for the Strata/Hadoop World conference. It’s one of the largest big data events in the U.S. and has grown steadily larger over recent years. The agenda has shifted a bit as well – from largely academic discussions and how-to presentations by open source committers to real-world case studies by non-ISV enterprises.
With that in mind, I’d like to share a story from one of our enterprise customers. In fact, this customer is a 100+ year old financial institution. Perhaps not a company that you would associate with the cutting edge of data management technologies… Due the nature of their industry, I can’t share their name.
Like many established companies, this bank’s data processing and storage systems have been acquired or added over the years based on the most pressing needs and compliance requirements at the time. They ultimately found themselves trying to manage an unwieldy mix of 240+ interfaces and applications.
As you can imagine, data came in a wide variety of formats, such as Excel files, delimited text files (csv), fixed and variable length copybook and zipped files. They also had a variety of data sources, such as ftb/sftp, QlikView business intelligence, and SQL Server, Oracle and Sybase databases. Managing this environment was not only difficult, but also time-consuming, putting a significant burden on IT staff resources and a strain on budgets.
Data retention for a specified period of time is a regulatory requirement in the banking industry, so finding a cost-effective and efficient storage solution was the most pressing use case, but they also wanted to more effectively utilize their customer data.
Looking to modernize their approach to data management and storage, and ultimately, support more streamlined and improved customer service, they decided to eliminate a number of their legacy databases and mainframe applications, modernize their data retention approach, and accelerate business analytics with Hadoop and a data lake.
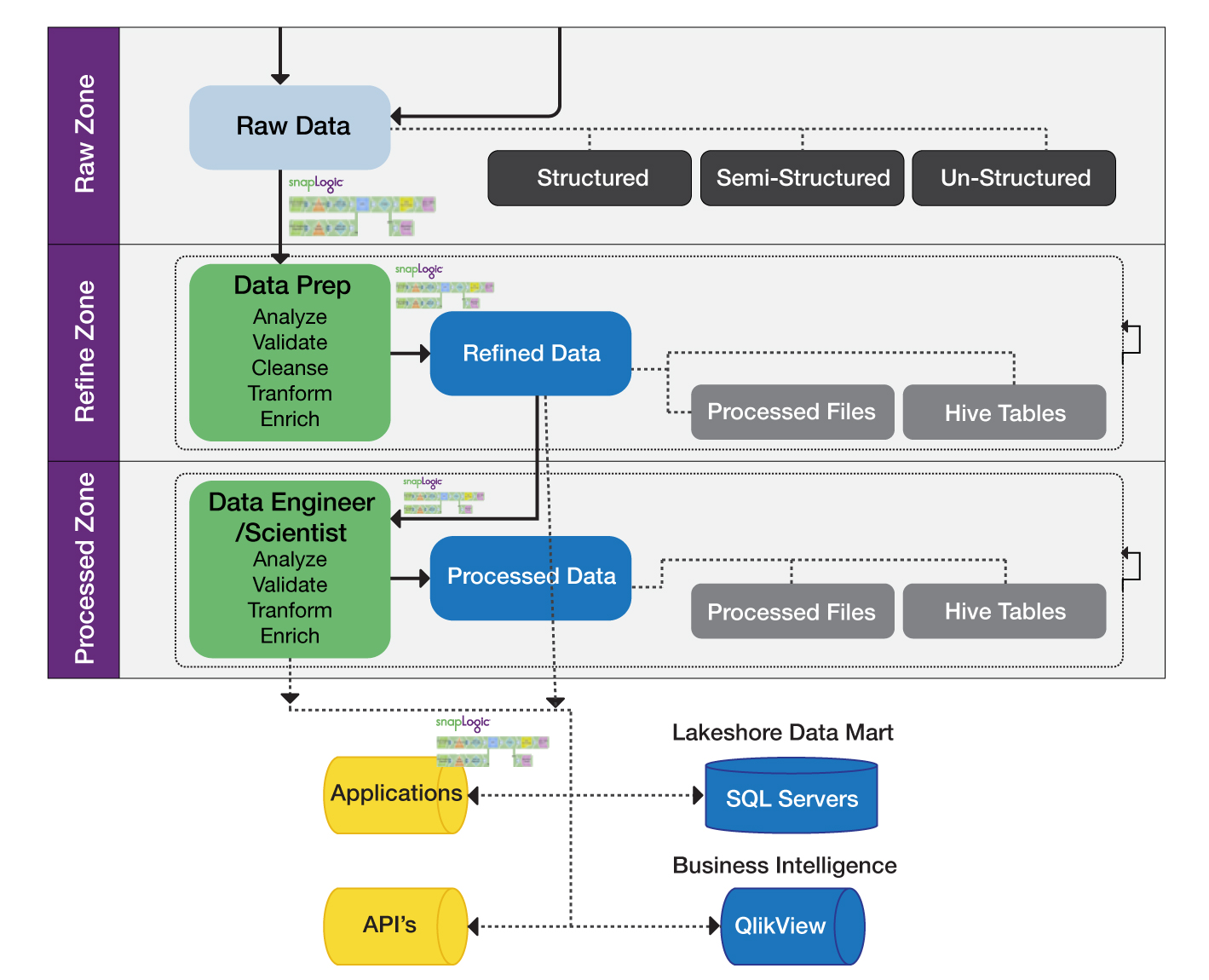
After considering how they might do this internally and also exploring options in the market including open source tools, they decided to use the SnapLogic Elastic Integration Platform in conjunction with a Cloudera-based Hadoop environment. SnapLogic enabled them to perform ingestion, preparation and delivery of data into a single Data Hub, thereby supporting the retirement of older databases and mainframe applications and consolidating data from multiple sources within a data lake. In the next phase of the project, SnapLogic will also enable their vision of a “self-service data lake” for future reporting needs.
After using SnapLogic to consolidate internal data sources and retire many of their existing databases and mainframe applications supporting internal business data, they added to the Data Hub external data from 3rd party financial data providers. When their vision is complete, they will have a comprehensive set of integrated data in a Cloudera Data Hub for efficient, cost-effective data retention. This will also provide the foundation for their next project, which will leverage the Data Hub for a 360-degree view of the customer and, consequently, improved customer care.
Instead of viewing data as just a retention issue for industry regulatory compliance, this bank’s Data Hub or data lake is viewed as a strategic asset. More than just “cheap distributed storage,” the Hadoop-based data lake is a centralized resource for data analytics and insights. With this consolidated business data they will be able to view all data by customer and relationship, so will provide invaluable information on how to improve overall customer service. At SnapLogic we’re proud to be a critical enabler of their data lake vision.
As our customer champion told us: “The initial challenge was to deal with compliance and regulatory requirements in the financial industry. When we thought of innovative ways of getting a better handle on it we came up with a way to kill two birds with one stone, so to speak. What about a data archival and retention system doubling as a data hub to provide insights?
The solution was clear but the task was daunting and fraught with skillset challenges. So we bravely took off with not much, a junior DBA to help and guidance from Cloudera and SnapLogic who helped us design and implement our vision.”



