





Pubblicato in precedenza su Medium
Ho la fortuna di lavorare con un forte gruppo di ingegneri, architetti e analisti in un'azienda chiamata CBG. In CBG, la nostra visione è quella di costruire e supportare una miriade di enti sanitari attraverso le nostre acclamate competenze e soluzioni cliniche, operative e digitali, il tutto con l'obiettivo di accelerare risultati comprovati. Le nostre persone, la nostra mentalità e la nostra cultura rendono tutto questo possibile. Una di queste entità sanitarie che abbiamo costruito si chiama RealRx e altre sono all'orizzonte.
Nell'ultimo anno i nostri team hanno dimostrato una grande capacità di recupero sociale e professionale. Come la maggior parte dei team tecnologici, risolvono ogni giorno problemi difficili, si adattano rapidamente a nuovi cambiamenti all'interno della nostra azienda e si sforzano di portare a termine la nostra missione tecnologica. Una parte di questa missione consiste nell'eliminare gli sprechi e gli stati di attesa per massimizzare il rendimento del team. Abbiamo scoperto che un modo per eliminare gli sprechi e gli stati di attesa è automatizzare tutto e adottare il CI/CD per TUTTO ciò che costruiamo, tocchiamo e supportiamo, comprese le piattaforme low-code/no-code su cui sviluppiamo.
Voglio condividere un approccio che stiamo adottando con la piattaforma low-code/no-code SnapLogic Intelligent Integration Platform (IIP) per incorporare l'automazione CI/CD nelle nostre pratiche SDLC quotidiane che stanno dimostrando di facilitare risultati di business più rapidi per i nostri partner strategici, clienti e membri.
Che cos'è il CI/CD?
I team di ingegneri moderni generalmente abbracciano qualcosa di simile a questi quattro pilastri: integrazione continua, distribuzione continua, infrastruttura come codice e adozione di una mentalità di sicurezza che sposta la sicurezza molto a sinistra nell'SDLC di un'organizzazione. Il problema in cui mi sono imbattuto è che molti team non capiscono ancora cosa significhino queste parole d'ordine, perché siano importanti per un team e quando non siano effettivamente importanti (forniscano poco valore).
Vorrei concentrarmi sul primo pilastro. In passato, gli sviluppatori di un team potevano lavorare in isolamento per un lungo periodo e unire le loro modifiche al ramo master/principale/trunk solo una volta completato il loro lavoro. Questa pratica "batch mode" rendeva l'unione delle modifiche al codice difficile e dispendiosa in termini di tempo, con il risultato che i bug si accumulavano per lungo tempo senza essere corretti. Questi fattori rendevano più difficile fornire aggiornamenti ai clienti in modo rapido e senza rischi.
Per risolvere questi fattori è nata l'integrazione continua. L'integrazione continua è una pratica di sviluppo software in cui gli sviluppatori uniscono regolarmente e frequentemente le loro modifiche al codice in un repository centrale, dopo di che vengono eseguiti build e test automatizzati. L'integrazione continua (CI da qui in poi) si riferisce più spesso alla fase di compilazione o integrazione del processo di rilascio del software, che comporta sia una componente di automazione (ad esempio, un CI o un servizio di compilazione) sia una componente culturale (ad esempio, imparare a integrare frequentemente).
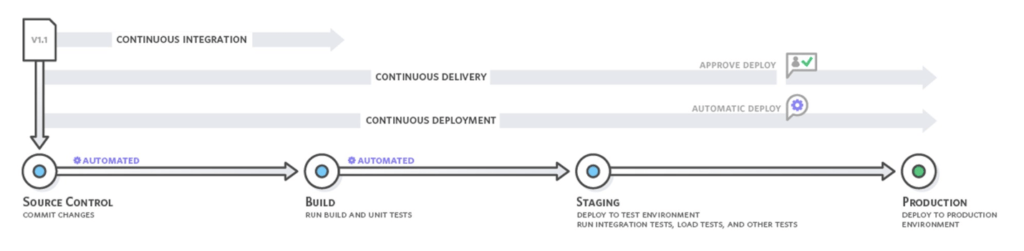
Oltre alla CI, sono state introdotte altre due pratiche per i team software, chiamate continuous delivery e continuous deployment. È interessante notare che molti team di ingegneri equiparano l'una o l'altra con la CD, ma il più delle volte quella che conta davvero è la distribuzione continua.
Con la consegna continua, le modifiche al codice vengono automaticamente costruite, testate e preparate per il rilascio in produzione, ma non arrivano effettivamente in produzione. La consegna continua amplia l'integrazione continua distribuendo tutte le modifiche al codice in un ambiente di test dopo la fase di compilazione. E la distribuzione continua segna il touchdown, ci porta a done^2, e porta al massimo l'automazione della distribuzione di tutte le modifiche accumulate attraverso le pratiche di CI. È piuttosto semplice.
Come ci avviciniamo al CI/CD?
Concettualmente, questo è il CI/CD in poche parole ed è puramente teorico. Può essere impegnativo digerire la teoria e convertirla in carburante reale che spinga un team ad adattare nuove abitudini e pratiche in un ambiente aziendale o di startup dal ritmo serrato.
Nel mondo reale di CBG, ecco come le pratiche CI/CD possono essere osservate nelle pratiche quotidiane del nostro team ad alto livello:
- Gli sviluppatori eseguono frequentemente il commit su repository condivisi utilizzando Git come sistema di controllo della versione, a volte più volte al giorno, utilizzando una metodologia simile a GitFlow.
- Prima di ogni commit, gli sviluppatori eseguono test unitari locali sul loro codice prima di integrarlo.
- Inoltre, eseguono linting, scansioni di sicurezza e controlli ortografici tramite script di compilazione.
- Ogni revisione impegnata innesca anche un'esecuzione automatica di build e test per far emergere immediatamente eventuali errori o problemi in modo automatico.
- Gli eventi vengono inviati a MS Teams e AWS CloudWatch per essere visibili ai membri del team, siano essi positivi o negativi, in modo da essere "grandi e forti".
- I connettori webhook in entrata consentono ai servizi esterni di notificare i nostri canali CI/CD attraverso mezzi personalizzati.
- I lavori e le fasi di GitHub Actions guidano l'automazione di queste attività e inviano metadati personalizzati con gli stati dei lavori e delle fasi.
- Tutte le attività CI/CD relative a richieste di pull, push e problemi sono trasmesse a ChatOps (MS Teams) e al logging centrale (AWS CloudWatch).
- Ogni merge/push ai nostri rami principali attiva una nuova release e un nuovo deploy in produzione, in modo automatico, che è stato completamente testato molte volte, riducendo al minimo il rischio di downtime e massimizzando il numero di funzionalità che i nostri team possono fornire a ogni iterazione.
La CI aiuta i nostri team a essere più produttivi, liberando gli sviluppatori dalle attività manuali e incoraggiando comportamenti che contribuiscono a ridurre il numero di errori e di bug rilasciati ai clienti. Con test più frequenti, i team possono scoprire e risolvere i bug in anticipo, prima che si trasformino in problemi più gravi. Infine, aiuta i team a fornire aggiornamenti ai clienti più rapidamente e più frequentemente.
Dove entra in gioco SnapLogic?
Un'altra missione tecnologica di CBG è quella di abbracciare l'automazione pragmatica, l'RPA, i bot, le integrazioni API e le soluzioni low-code/no-code per costruire soluzioni digitali resilienti e facili da usare. Una di queste piattaforme low-code/no-code che utilizziamo per le nostre integrazioni ETL/ELT, dati e API e per l'automazione si chiama SnapLogic Intelligent Integration Platform.
SnapLogic fa un ottimo lavoro nel gestire diversi tipi di integrazioni di dati e API per tutti i tipi di organizzazioni. Parallelamente, aziende lungimiranti come CBG stanno sfruttando le metodologie DevOps/NoOps per le proprie iniziative e flussi di lavoro di integrazione di dati e applicazioni. Un problema che ho riscontrato in precedenza è che servizi come SnapLogic (aka low-code/no-code) non sempre si integrano bene con le pratiche DevOps come CI/CD e infrastructure-as-code. SnapLogic è una piacevole eccezione a questa affermazione e voglio mostrarvi perché e come.
SnapLogic offre alle aziende diversi metodi per applicare le pratiche CI/CD nel loro SDLC, compresi alcuni metodi di migrazione nativa, ma nessuno si è dimostrato più potente e flessibile per i miei team di SnapLogic Metadata Snap. L'approccio CI/CD di CBG per SnapLogic sfrutta SnapLogic Metadata Snap in pipeline dedicate alle attività CI/CD, che consentono agli sviluppatori di costruire e personalizzare pipeline per estrarre uno, alcuni o tutti i tipi di categoria di metadati per le loro esigenze CI/CD.
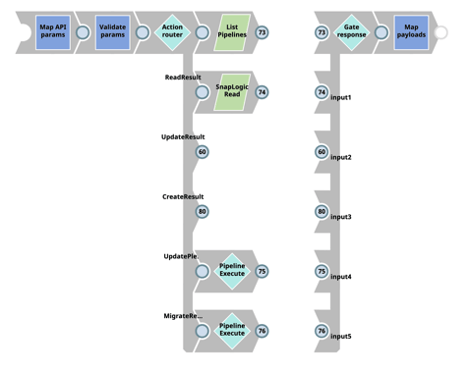
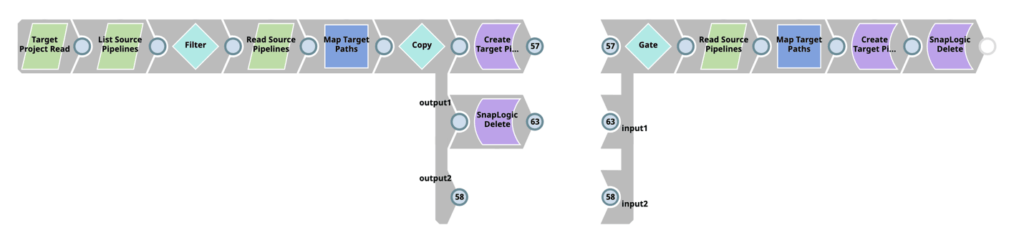
Utilizzando le pipeline SnapLogic, i nostri team possono sfruttare qualsiasi componente della pipeline per modificare e trasformare i metadati al fine di soddisfare i requisiti aziendali. Il vantaggio principale di questo approccio, e il motivo per cui i nostri team di CBG lo ritengono un metodo superiore, è che ci permette di avere il pieno controllo di come e cosa viene fatto per il nostro specifico processo CI/CD, compreso il modo in cui gli artefatti della pipeline vengono distribuiti ai diversi nodi e progetti.
I nostri team di ingegneri traggono ulteriore vantaggio dai sistemi di controllo sorgente esistenti (come GitHub) e dai sistemi di automazione di build/deploy esistenti (come GitHub Actions) per lavorare con i componenti SnapLogic. I nostri team hanno scoperto che i nostri sistemi di controllo dei sorgenti e i sistemi di automazione di build/deploy funzionano molto bene insieme e quasi senza problemi nell'esecuzione delle pipeline remote di SnapLogic da GitHub attraverso l'API SnapLogic fornita e legata ai nostri task attivati. Abbiamo collegato con successo i flussi di lavoro delle azioni di GitHub e le API di SnapLogic per automatizzare il nostro processo di distribuzione low-code/no-code attraverso le fasi di sviluppo, test e produzione.
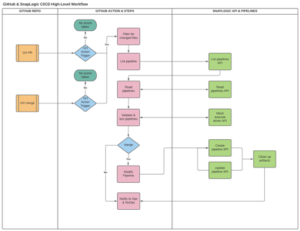
Questo approccio di alto livello offre ai nostri team la possibilità di impacchettare i contenuti in GitHub e quindi di utilizzare script di automazione di build/deploy per inviare versioni specifiche e modificate in base a una richiesta di pull o di merge a SnapLogic per lo spacchettamento e l'aggiornamento di un ambiente downstream dallo sviluppo.
Sono finiti i giorni in cui si dovevano fare i deploy manuali attraverso l'interfaccia utente di SnapLogic. Tutte le modifiche vengono distribuite al nodo e al progetto specificato in modo automatico, in base agli eventi del controllo sorgente, alle azioni di GitHub e ai tipi di flussi attivati da tali azioni.

Un CI/CD di questo tipo consente ai nostri team di assumere un flusso di sviluppo più naturale, simile a quello di altri codici e microservizi su cui lavorano, in parallelo, durante la stessa iterazione o quelle future. Non hanno più bisogno di ricordare un flusso CI/CD diverso in base al progetto che stanno affrontando o al fatto che sia low-code/no-code o meno. Anche per i revisori appare molto pulito e automatizzato e siamo in grado di limitare le autorizzazioni a livello granulare nei nodi, negli ambienti e nei progetti SnapLogic.
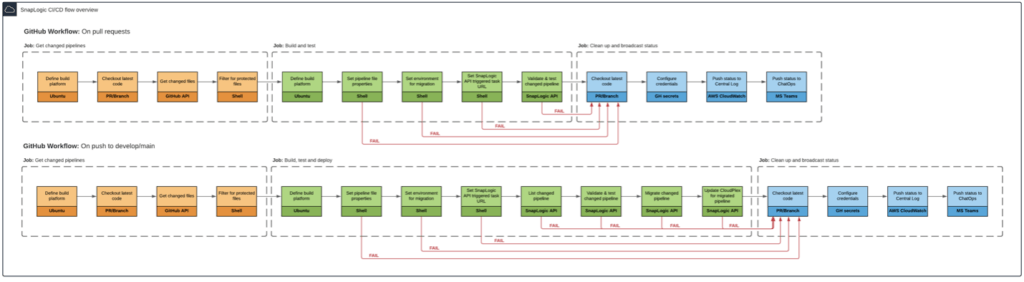
Attualmente, i nostri flussi CI/CD coprono due scenari: uno per le richieste di pull in GitHub, destinato a convalidare e testare le pipeline SnapLogic prima che vengano integrate nei rami di sviluppo o principali, e un altro per quando c'è un evento di push/merge in GitHub verso i rami di sviluppo o principali. Quest'ultimo flusso ha lo scopo non solo di convalidare e testare le pipeline, ma anche di distribuire e aggiornare automaticamente i metadati per le pipeline appena modificate e confezionate per la distribuzione continua.
TL;DR
In sintesi, è stimolante vedere come i nostri team tecnologici non si sentano mai soddisfatti finché non riescono ad automatizzare un processo manuale, compresi i servizi low-code/no-code come SnapLogic. È ancora più piacevole quando piattaforme come SnapLogic offrono diverse opzioni per raggiungere l'aderenza CI/CD. I nostri team amano il flusso attuale, i nostri revisori amano l'automazione e la mancanza di errori umani, e i nostri partner commerciali amano il rischio minimo di distribuire nuove funzionalità in produzione.




