





Previously published on Medium
I’m fortunate to work with a strong group of engineers, architects, and analysts at a company called CBG. At CBG, our vision is to build and support myriad healthcare entities through our acclaimed clinical, operational, and digital expertise and solutions, all with a goal to accelerate proven outcomes. Our people, mindsets, and culture very much make this possible. One such healthcare entity we’ve built is called RealRx, and there are more on the horizon.
Our teams have shown so much resilience socially and professionally over the past year. Like most technology teams, they solve difficult problems every day, adapt quickly to new pivots within our company, and strive to accomplish our technology mission. One piece of that mission is to eliminate waste and wait states to maximize team throughput. We’ve found that one way to eliminate waste and wait states is to automate everything and embrace CI/CD with EVERYTHING we build, touch and support, including low-code/no-code platforms we develop on.
I want to share an approach we’re taking with the SnapLogic Intelligent Integration Platform (IIP) low-code/no-code platform to embed CI/CD automation in our daily SDLC practices that are proving to facilitate speedier business outcomes for our strategic partners, customers, and members.
What is CI/CD?
Modern engineering teams generally will embrace something similar to these four pillars: continuous integration, continuous deployment, infrastructure as code, and adopting a security mindset that shifts security far to the left of an organizations’ SDLC. The issue I’ve stumbled across is that many teams still don’t actually understand what those buzzwords mean, why they’re important to a team, and when they don’t actually matter (provide little value.)
I want to focus on the first pillar above. In the past, developers on a team might work in isolation for an extended period and only merge their changes to the master/main branch/trunk once their work was completed. This “batch mode” practice made merging code changes difficult and time-consuming, and resulted in bugs accumulating for a long time without correction. These factors made it harder to deliver updates to customers quickly and without risk.
To fix those factors, continuous integration was born. Continuous integration is a software development practice where developers regularly and frequently merge their code changes into a central repository, after which automated builds and tests are run. Continuous integration (CI from here on) most often refers to the build or integration stage of the software release process, which entails both an automation component (e.g., a CI or build service) and a cultural component (e.g., learning to integrate frequently.)
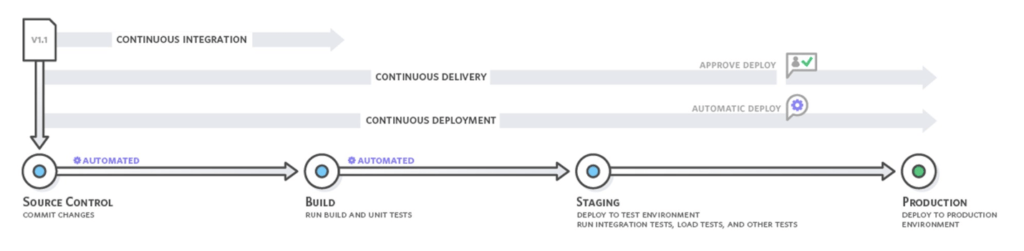
In addition to CI, two other practices were introduced to software teams called continuous delivery and continuous deployment. Interestingly, many engineering teams equate one or the other with being CD, but most often the one that really matters is continuous deployment.
With continuous delivery, code changes are automatically built, tested, and prepared for a release to production, but don’t actually make it to production. Continuous delivery expands upon continuous integration by deploying all code changes to a testing environment after the build stage. And continuous deployment scores the touchdown, gets us to done^2, and takes it to the max in automating the deployment of all accumulated changes collected through CI practices. Pretty simple.
How do we approach CI/CD?
Conceptually, that is CI/CD in a nutshell and it is purely theory. It can be challenging to digest theory and convert it to real fuel that drives a team to adapt new habits and practices in a fast-paced enterprise or startup environment alike.
In the real world at CBG, here’s how CI/CD practices can be observed in our team’s day-to-day practices at a high-level:
- Developers frequently commit to shared repository using Git as our version control system, sometimes several times per day using a methodology akin to GitFlow
- Prior to each commit, developers run local unit tests on their code before integrating
- Also, they run linting, security scans and spellchecks via build scripts
- Every revision committed also triggers an automated build and test run to immediately surface any errors or issues automagically
- Events are pushed to MS Teams and AWS CloudWatch for visibility to team members, whether good or bad, so they’re “big and loud”
- Incoming webhook connectors enable external services to notify our CI/CD channels through custom mediums
- GitHub Actions jobs and steps drive the automation of these activities, and push custom metadata with job/step statuses
- All CI/CD activity related to pull requests, pushes, and issues are broadcast to ChatOps (MS Teams) and central logging (AWS CloudWatch)
- Every merge/push to our main branches triggers a new release and new deploy to production, automagically, that has been fully tested many times, minimizing risk of downtime and maximizing the number of features our teams can deliver each iteration
CI helps our teams be more productive by freeing developers from manual tasks and encouraging behaviors that help reduce the number of errors and bugs released to customers. With more frequent testing, teams can discover and address bugs earlier before they grow into larger problems later. And lastly, it helps teams deliver updates to their customers faster and more frequently.
Where does SnapLogic come in to play?
Another technology mission we live by at CBG is to embrace pragmatic automation, RPA, bots, API integrations, and low-code/no-code solutions to build resilient, easy-to-use digital solutions. One such low-code/no-code platform we use for our ETL/ELT, data & API integrations, and automation is called SnapLogic Intelligent Integration Platform.
SnapLogic does a great job of handling different types of data & API integrations for all kinds of organizations. In parallel, forward-looking companies like CBG are also leveraging DevOps/NoOps methodologies for their own data and application integration workflows and initiatives. One issue I’ve run in to previously is that services like SnapLogic (aka low-code/no-code) don’t always integrate well with DevOps practices like CI/CD and infrastructure-as-code. SnapLogic is a pleasant exception to that statement, and I want to show you why and how.
SnapLogic has several methods for companies to apply CI/CD practices in their SDLC, including some native migration methods, but none have proven more powerful and flexible for my teams than the SnapLogic Metadata Snap. CBG’s CI/CD approach for SnapLogic leverages the SnapLogic Metadata Snap in pipelines dedicated to CI/CD activities, which allows developers to build and customize pipelines to pull one, some, or all of any metadata category type for their CI/CD needs.
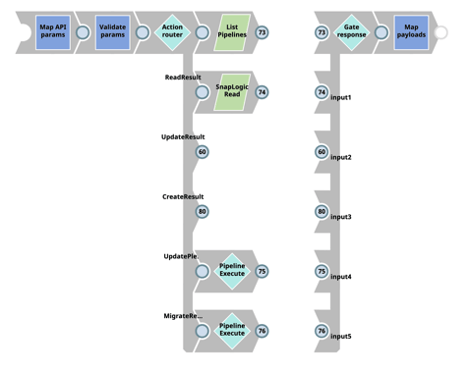
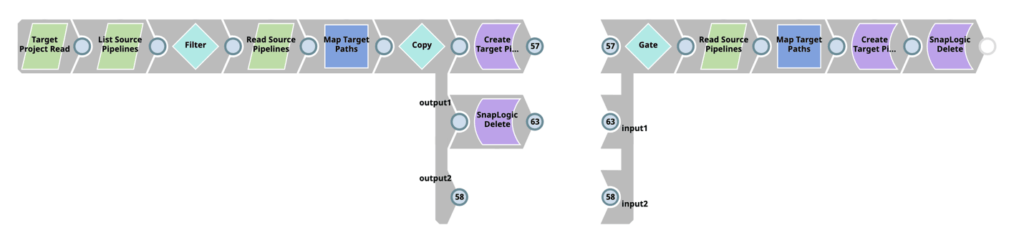
Using SnapLogic pipelines, our teams can leverage any pipeline component to change and transform the metadata in order to meet business requirements. The key benefit of this approach, and why our teams at CBG believe it to be the superior method, is that it allows us to have full control of how and what is done for our specific CI/CD process, including how those pipeline artifacts are deployed to different nodes and projects.
Our engineering teams further benefit from existing source control systems (like GitHub) and existing build/deploy automation systems (like GitHub Actions) to work with the SnapLogic components. What our teams have found is that our source control systems and build/deploy automation systems play very nicely together, and work near seamlessly in executing SnapLogic remote pipelines from GitHub through the provided SnapLogic API tied to our triggered tasks. We’ve successfully connected GitHub Actions workflows and SnapLogic APIs to automate our low-code/no-code deploy process all the way through dev, test and production.
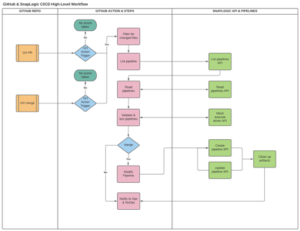
This high-level approach gives our teams the ability to package the contents into GitHub and then use build/deploy automation scripts to send specific, modified versions based on a pull request or merge request back to SnapLogic for unpacking and updating of a downstream environment from development.
Gone are the days where we had to do manual deploys through the SnapLogic UI. All changes are deployed to the specified node and project automagically based on source control events, GitHub actions and the kinds of flows those event actions trigger.

Doing CI/CD like this enables our teams to assume a more natural development flow similar to other code and microservices they work on, in parallel, during the same or future iterations. They no longer need to remember a different CI/CD flow based on the project they’re tackling or whether it’s low-code/no-code or not. It also looks really clean and automated for auditors and we’re able to limit permissions at a granular level in the SnapLogic nodes, environments, and projects.
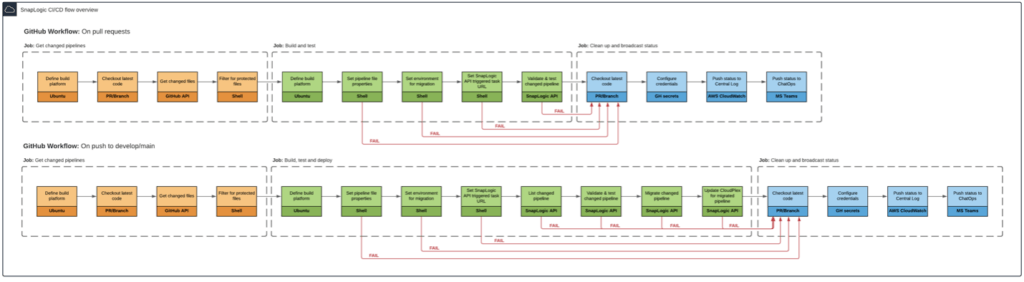
Currently, our CI/CD flows cover two scenarios: one for pull requests in GitHub that is intended to validate and test SnapLogic pipelines before they’re integrated into develop or main branches, and another for when there is a push/merge event in GitHub to develop or main branches. This latter flow is intended to not only validate and test pipelines, but also to automagically deploy and update metadata for newly modified pipelines that are packaged for continuous deployment.
TL;DR
In summary, it’s inspiring to see how our technology teams never feel satisfied until they can automate a manual process, including low-code/no-code services like SnapLogic. It’s even more refreshing when platforms like SnapLogic provide multiple options to achieve CI/CD adherence. Our teams love the current flow, our auditors love the automation and lack of human error, and our business partners love the minimal risk of deploying new features to production.





