





Publié précédemment sur Medium
J‘ai la chance de travailler avec un groupe solide d‘ingénieurs, d‘architectes et d‘analystes au sein d‘une entreprise appelée CBG. Chez CBG, notre vision est de construire et de soutenir une myriade d‘entités de soins de santé grâce à notre expertise et à nos solutions cliniques, opérationnelles et numériques reconnues, le tout dans le but d‘accélérer des résultats éprouvés. Notre personnel, notre mentalité et notre culture rendent tout cela possible. L‘une des entités de soins de santé que nous avons construites s‘appelle RealRx, et d‘autres sont à l‘horizon.
Nos équipes ont fait preuve d‘une grande résilience sociale et professionnelle au cours de l‘année écoulée. Comme la plupart des équipes technologiques, elles résolvent chaque jour des problèmes difficiles, s‘adaptent rapidement aux nouveaux pivots de notre entreprise et s‘efforcent d‘accomplir notre mission technologique. L‘un des éléments de cette mission consiste à éliminer le gaspillage et les états d‘attente afin de maximiser le rendement de l‘équipe. Nous avons découvert qu‘une façon d‘éliminer le gaspillage et les états d‘attente est de tout automatiser et d‘adopter le CI/CD pour TOUT ce que nous construisons, touchons et supportons, y compris les plateformes low-code/no-code sur lesquelles nous développons.
Je souhaite partager une approche que nous adoptons avec la plate-forme d‘intégration intelligente SnapLogic (IIP) low-code/no-code plateforme pour intégrer l‘automatisation CI/CD dans nos pratiques SDLC quotidiennes qui s‘avèrent faciliter l‘obtention de résultats commerciaux plus rapides pour nos partenaires stratégiques, nos clients et nos membres.
Qu‘est-ce que la CI/CD ?
Les équipes d‘ingénieurs modernes adoptent généralement quelque chose de similaire à ces quatre piliers : intégration continue, déploiement continu, infrastructure en tant que code, et adoption d‘un état d‘esprit sécuritaire qui déplace la sécurité loin sur la gauche du SDLC d‘une organisation. Le problème que j‘ai rencontré est que de nombreuses équipes ne comprennent toujours pas ce que ces mots à la mode signifient, pourquoi ils sont importants pour une équipe et quand ils n‘ont pas d‘importance (ils n‘apportent que peu de valeur).
Je voudrais me concentrer sur le premier pilier ci-dessus. Dans le passé, les développeurs d‘une équipe pouvaient travailler de manière isolée pendant une période prolongée et ne fusionner leurs modifications avec la branche principale/le tronc principal qu‘une fois leur travail terminé. Cette pratique du "mode batch" rendait la fusion des modifications de code difficile et fastidieuse, et entraînait l‘accumulation de bogues pendant une longue période sans qu‘ils soient corrigés. Il était donc plus difficile de fournir des mises à jour aux clients rapidement et sans risque.
C‘est pour remédier à ces problèmes qu‘est née l‘intégration continue. L‘intégration continue est une pratique de développement logiciel dans laquelle les développeurs fusionnent régulièrement et fréquemment leurs modifications de code dans un référentiel central, après quoi des constructions et des tests automatisés sont exécutés. L‘intégration continue (ci-après "IC") fait le plus souvent référence à l‘étape de construction ou d‘intégration du processus de publication d‘un logiciel, qui comprend à la fois une composante d‘automatisation (par exemple, un service d‘IC ou de construction) et une composante culturelle (par exemple, l‘apprentissage d‘une intégration fréquente).
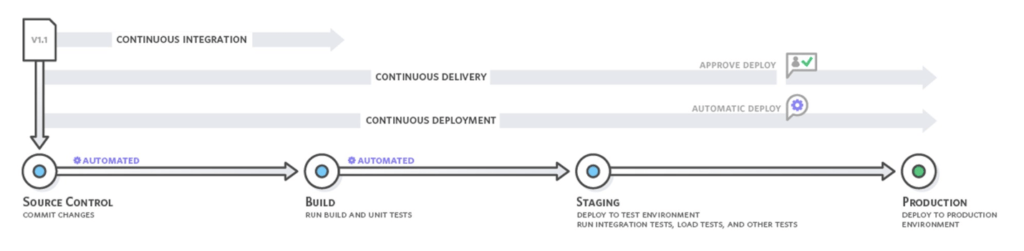
En plus de l‘IC, deux autres pratiques ont été introduites dans les équipes logicielles : la livraison continue et le déploiement continu. Il est intéressant de noter que de nombreuses équipes d‘ingénieurs assimilent l‘une ou l‘autre de ces pratiques à l‘IC, mais la plupart du temps, c‘est le déploiement continu qui est le plus important.
Avec la livraison continue, les modifications du code sont automatiquement construites, testées et préparées pour une mise en production, mais ne sont pas réellement mises en production. La livraison continue s‘appuie sur l‘intégration continue en déployant toutes les modifications du code dans un environnement de test après l‘étape de construction. Le déploiement continu marque le coup, nous amène à done^2 et va jusqu‘au bout en automatisant le déploiement de toutes les modifications accumulées grâce aux pratiques d‘intégration continue. C‘est très simple.
Comment aborder la CI/CD ?
D‘un point de vue conceptuel, c‘est ce que l‘on appelle CI/CD, et il s‘agit d‘une théorie pure. Il peut être difficile d‘assimiler la théorie et de la convertir en un véritable carburant qui pousse une équipe à adapter de nouvelles habitudes et pratiques dans un environnement d‘entreprise ou de startup au rythme rapide.
Dans le monde réel de CBG, voici comment les pratiques CI/CD peuvent être observées dans les pratiques quotidiennes de notre équipe à un niveau élevé :
- Les développeurs s‘engagent fréquemment dans un dépôt partagé en utilisant Git comme système de contrôle de version, parfois plusieurs fois par jour en utilisant une méthodologie proche de GitFlow
- Avant chaque livraison, les développeurs effectuent des tests unitaires locaux sur leur code avant de l‘intégrer.
- Ils exécutent également des analyses de sécurité et des vérifications orthographiques par le biais de scripts de construction.
- Chaque révision validée déclenche également un processus de construction et de test automatisé qui permet de détecter immédiatement toute erreur ou tout problème.
- Les événements sont transmis à MS Teams et AWS CloudWatch pour être visibles par les membres de l‘équipe, qu‘ils soient bons ou mauvais, de sorte qu‘ils sont "grands et bruyants"
- Les connecteurs webhook entrants permettent à des services externes de notifier nos canaux CI/CD par des moyens personnalisés.
- GitHub Actions jobs and steps drive the automation of these activities, and push custom metadata with job/step statuses.
- Toutes les activités CI/CD liées aux pull requests, aux pushes et aux issues sont diffusées à ChatOps (MS Teams) et à l‘enregistrement central (AWS CloudWatch).
- Chaque fusion/poussée vers nos branches principales déclenche une nouvelle version et un nouveau déploiement en production, de manière automatique, qui a été entièrement testé à de nombreuses reprises, minimisant ainsi le risque de temps d‘arrêt et maximisant le nombre de fonctionnalités que nos équipes peuvent fournir à chaque itération.
L‘IC aide nos équipes à être plus productives en libérant les développeurs des tâches manuelles et en encourageant les comportements qui contribuent à réduire le nombre d‘erreurs et de bogues transmis aux clients. Grâce à des tests plus fréquents, les équipes peuvent découvrir et traiter les bogues plus tôt, avant qu‘ils ne se transforment en problèmes plus importants par la suite. Enfin, l‘IC aide les équipes à fournir des mises à jour à leurs clients plus rapidement et plus fréquemment.
Où SnapLogic entre-t-il en jeu ?
Une autre mission technologique de CBG est d ‘adopter l‘automatisation pragmatique, la RPA, les bots, les intégrations d‘API et les solutions " low-code/no-code " pour construire des solutions numériques résistantes et faciles à utiliser. L‘une de ces solutions " low-code/no-code " plateforme que nous utilisons pour nos ETL/ELT, nos intégrations de données et d‘API et notre automatisation s‘appelle SnapLogic Intelligent Integration Platform (plate-forme d‘intégration intelligente).
SnapLogic gère très bien différents types d‘intégrations de données et d‘API pour toutes sortes d‘organisations. Parallèlement, des entreprises tournées vers l‘avenir comme CBG exploitent également les méthodologies DevOps/NoOps pour leurs propres initiatives d‘intégration de données et d‘applications les workflows . Un problème que j‘ai déjà rencontré est que les services comme SnapLogic (aka low-code/no-code) ne s‘intègrent pas toujours bien avec les pratiques DevOps comme CI/CD et infrastructure-as-code. SnapLogic est une agréable exception à cette règle, et je vais vous montrer pourquoi et comment.
SnapLogic propose aux entreprises plusieurs méthodes pour appliquer les pratiques CI/CD dans leur SDLC, y compris quelques méthodes de migration natives, mais aucune ne s‘est avérée plus puissante et plus flexible pour mes équipes que le Snap SnapLogic Metadata. L‘approche CI/CD de CBG pour SnapLogic exploite le Snap Snap SnapLogic Metadata dans les pipelines dédiés aux activités CI/CD, ce qui permet aux développeurs de construire et de personnaliser les pipelines pour extraire un, plusieurs ou tous les types de catégories de métadonnées pour leurs besoins CI/CD.
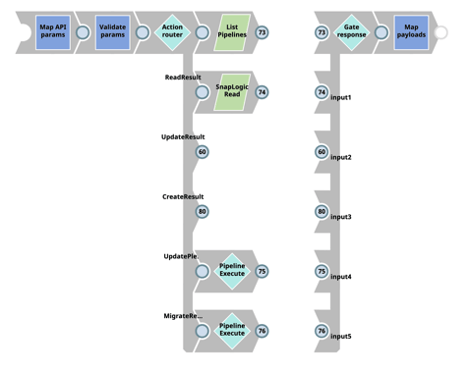
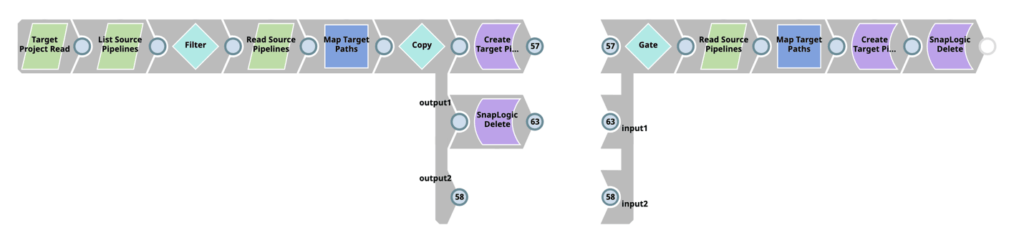
En utilisant les pipelines SnapLogic, nos équipes peuvent utiliser n‘importe quel composant du pipeline pour modifier et transformer les métadonnées afin de répondre aux exigences de l‘entreprise. Le principal avantage de cette approche, et la raison pour laquelle nos équipes chez CBG la considèrent comme la meilleure méthode, est qu‘elle nous permet de contrôler entièrement comment et ce qui est fait pour notre processus CI/CD spécifique, y compris la façon dont ces artefacts de pipeline sont déployés vers différents nœuds et projets.
Nos équipes d‘ingénieurs bénéficient en outre des systèmes de contrôle de source existants (comme GitHub) et des systèmes d‘automatisation de construction/déploiement existants (comme GitHub Actions) pour travailler avec les composants SnapLogic. Nos équipes ont constaté que nos systèmes de contrôle de source et nos systèmes d‘automatisation de construction/déploiement fonctionnent très bien ensemble et de manière presque transparente pour exécuter les pipelines distants SnapLogic à partir de GitHub à travers l‘API SnapLogic fournie et liée à nos tâches déclenchées. Nous avons réussi à connecter les actions GitHub les workflows et les API SnapLogic pour automatiser notre processus de déploiement low-code/no-code tout au long des phases de développement, de test et de production.
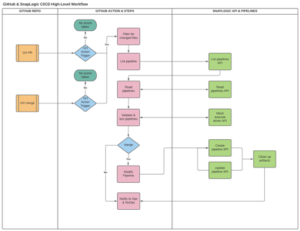
Cette approche de haut niveau permet à nos équipes d‘empaqueter le contenu dans GitHub, puis d‘utiliser des scripts d‘automatisation de construction/déploiement pour envoyer des versions spécifiques et modifiées basées sur une demande d‘extraction ou de fusion à SnapLogic pour le dépaquetage et la mise à jour d‘un environnement en aval à partir du développement.
L‘époque où nous devions effectuer des déploiements manuels via l‘interface utilisateur de SnapLogic est révolue. Toutes les modifications sont déployées vers le nœud et le projet spécifiés automatiquement en fonction des événements de contrôle de source, des actions GitHub et des types de flux que ces actions déclenchent.

Faire du CI/CD de cette manière permet à nos équipes d‘assumer un flux de développement plus naturel similaire aux autres codes et microservices sur lesquels ils travaillent, en parallèle, au cours de la même itération ou des itérations futures. Elles n‘ont plus besoin de se souvenir d‘un flux CI/CD différent en fonction du projet auquel elles s‘attaquent ou du fait qu‘il s‘agisse ou non d‘un low-code/no-code. Le système est également très propre et automatisé pour les auditeurs et nous sommes en mesure de limiter les autorisations à un niveau granulaire dans les nœuds, les environnements et les projets SnapLogic.
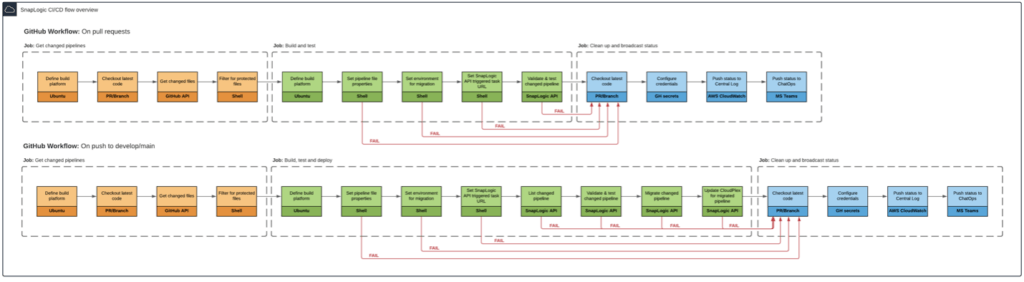
Actuellement, nos flux CI/CD couvrent deux scénarios : l‘un pour les pull requests dans GitHub qui est destiné à valider et tester les pipelines SnapLogic avant qu‘ils ne soient intégrés dans les branches develop ou main, et l‘autre pour lorsqu‘il y a un événement push/merge dans GitHub vers les branches develop ou main. Ce dernier flux est destiné non seulement à valider et tester les pipelines, mais aussi à déployer et mettre à jour automatiquement les métadonnées des pipelines nouvellement modifiés qui sont packagés pour le déploiement continu.
TL;DR
En résumé, il est inspirant de voir que nos équipes technologiques ne se sentent jamais satisfaites tant qu‘elles ne peuvent pas automatiser un processus manuel, y compris les services à code faible ou sans code comme SnapLogic. C‘est encore plus rafraîchissant lorsque des plateformes comme SnapLogic offrent de multiples options pour atteindre l‘adhérence CI/CD. Nos équipes apprécient le flux actuel, nos auditeurs apprécient l‘automatisation et l‘absence d‘erreur humaine, et nos partenaires commerciaux apprécient le risque minimal de déploiement de nouvelles fonctionnalités en production.





