






Die multimodale Verarbeitung in der generativen KI stellt einen transformativen Sprung in der Art und Weise dar, wie KI-Systeme Informationen aus mehreren Datentypen – wie Text, Bildern, Audio und Video – gleichzeitig extrahieren und synthetisieren. Im Gegensatz zu herkömmlichen KI-Modellen mit einer einzigen Modalität, die sich auf einen Datentyp konzentrieren, integrieren und verarbeiten multimodale Systeme verschiedene Datenströme parallel und schaffen so ein ganzheitliches Verständnis komplexer Szenarien. Dieser integrierte Ansatz ist entscheidend für Anwendungen, die nicht nur isolierte Erkenntnisse aus einer Modalität erfordern, sondern eine kohärente Synthese aus verschiedenen Datenquellen, was zu kontextuell reichhaltigeren und genaueren Ergebnissen führt.
Generative KI mit multimodaler Verarbeitung definiert die Textextraktion neu und übertrifft herkömmliche OCR, indem sie Text innerhalb seines visuellen und kontextuellen Umfelds interpretiert. Im Gegensatz zu OCR, das nur Bilder in Text umwandelt, analysiert generative KI den umgebenden Bildkontext, das Layout und die Bedeutung und verbessert so die Genauigkeit und Tiefe. In komplexen Dokumenten kann sie beispielsweise zwischen Überschriften, Fließtext und Anmerkungen unterscheiden und Informationen so intelligenter strukturieren. Darüber hinaus zeichnet sie sich bei Texten mit geringer Qualität oder mehrsprachigen Texten aus, was sie in Branchen, die Präzision und nuancierte Interpretation erfordern, unverzichtbar macht.
Bei der Videoanalyse kann eine generative KI, die mit multimodaler Verarbeitung ausgestattet ist, gleichzeitig die visuellen Elemente einer Szene, den Ton (wie Dialoge oder Hintergrundgeräusche) und den zugehörigen Text (wie Untertitel oder Metadaten) interpretieren. Auf diese Weise kann die KI eine Beschreibung oder Zusammenfassung der Szene erstellen, die weitaus nuancierter ist als das, was durch die Analyse des Videos oder des Tons allein erreicht werden könnte. Das Zusammenspiel dieser Modalitäten stellt sicher, dass die generierte Beschreibung nicht nur den visuellen und auditiven Inhalt widerspiegelt, sondern auch den tieferen Kontext und die Bedeutung, die sich aus ihrer Kombination ergibt.
Bei Aufgaben wie der Bildbeschriftung gehen multimodale KI-Systeme über das reine Erkennen von Objekten in einem Foto hinaus. Sie können die semantische Beziehung zwischen dem Bild und dem Begleittext interpretieren und so die Relevanz und Spezifität der generierten Bildunterschriften verbessern. Diese Fähigkeit ist besonders nützlich in Bereichen, in denen der durch eine Modalität bereitgestellte Kontext die Interpretation einer anderen Modalität erheblich beeinflusst, beispielsweise im Journalismus, wo Bilder und schriftliche Berichte sinnvoll aufeinander abgestimmt sein müssen, oder im Bildungswesen, wo visuelle Hilfsmittel in Lehrtexte integriert werden.
Multimodale Verarbeitung ermöglicht es KI, medizinische Bilder (wie Röntgenaufnahmen oder MRT-Aufnahmen) mit der Krankengeschichte, klinischen Notizen und sogar Live-Interaktionen zwischen Arzt und Patient in hochspezialisierten Anwendungen wie der medizinischen Diagnostik zu synthetisieren. Diese umfassende Analyse ermöglicht es der KI, genauere Diagnosen und Behandlungsempfehlungen zu liefern, wobei sie die komplexen Wechselwirkungen zwischen Symptomen, historischen Daten und visueller Diagnostik berücksichtigt. In ähnlicher Weise können multimodale KI-Systeme im Kundenservice die Kommunikationsqualität verbessern, indem sie den Textinhalt der Kundenanfrage sowie den Tonfall und die Stimmung der Stimme analysieren, was zu einfühlsameren und effektiveren Antworten führt.
Über einzelne Anwendungsfälle hinaus spielt die multimodale Verarbeitung eine entscheidende Rolle bei der Verbesserung der Lern- und Generalisierungsfähigkeiten von KI-Modellen. Durch das Training mit einem breiteren Spektrum an Datentypen entwickeln KI-Systeme robustere, flexiblere Modelle, die sich an eine größere Vielfalt von Aufgaben und Szenarien anpassen können. Dies ist besonders wichtig in realen Umgebungen, in denen Daten oft heterogen sind und ein modalitätsübergreifendes Verständnis erfordern, um vollständig interpretiert werden zu können.
Mit der Weiterentwicklung multimodaler Verarbeitungstechnologien versprechen diese neue Möglichkeiten in verschiedenen Bereichen. In der Unterhaltungsbranche könnte multimodale KI interaktive Medienerlebnisse verbessern, indem sie Sprache, Bildmaterial und narrative Elemente nahtlos miteinander verbindet. Im Bildungsbereich könnte sie das personalisierte Lernen revolutionieren, indem sie die Vermittlung von Inhalten an unterschiedliche sensorische Eingaben anpasst. Im Gesundheitswesen könnte die Zusammenführung multimodaler Daten zu Durchbrüchen in der Präzisionsmedizin führen. Letztendlich macht die Fähigkeit, kontextreiche multimodale Inhalte zu verstehen und zu generieren, generative KI zu einer Grundlagentechnologie für die nächste Welle KI-getriebener Innovationen.
Multimodaler Inhaltsgenerator Snap
Der Multimodal Content Generator Snap codiert Datei- oder Dokumenteneingaben in das multimodale Inhaltsformat des Snaps und bereitet sie so für eine nahtlose Integration vor. Die Ausgabe dieses Snaps muss mit dem Prompt Generator Snap verbunden werden, um die Nachrichtennutzlast für die weitere Verarbeitung zu vervollständigen und zu formatieren. Diese optimierte Konfiguration ermöglicht eine effiziente Verarbeitung multimodaler Inhalte innerhalb des Snap-Ökosystems.
Die Snap-Eigenschaften
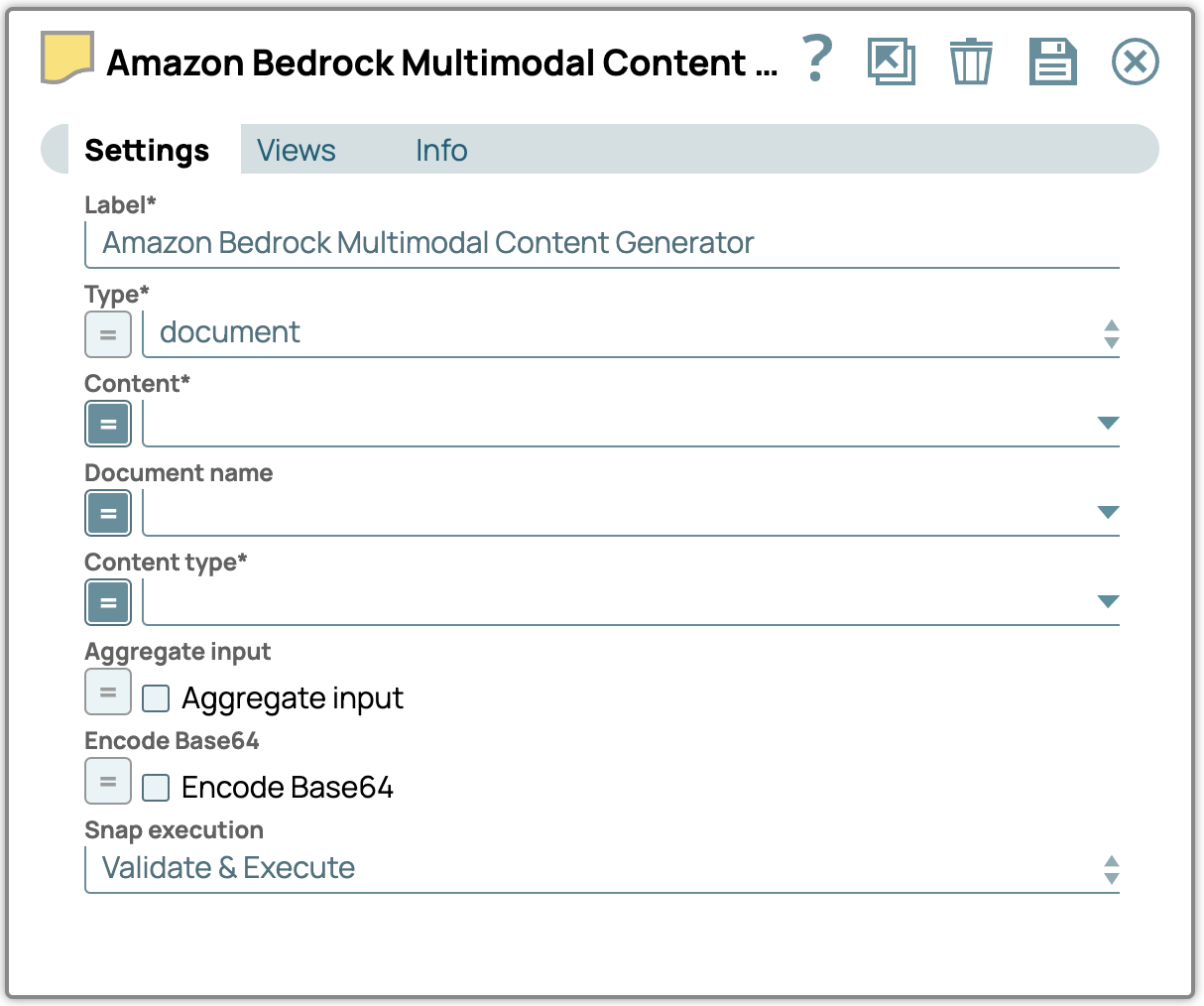
Typ – Wählen Sie den Typ des multimodalen Inhalts aus.
Inhaltstyp – Definieren Sie den spezifischen Inhaltstyp für Daten, die an das LLM übertragen werden.
Inhalt – Geben Sie den Inhaltspfad zu den multimodalen Inhaltsdaten für die Verarbeitung an.
Dokumentname – Benennen Sie das Dokument zu Referenz- und Identifikationszwecken.
Eingaben zusammenfassen – Aktivieren Sie diese Option, um alle Eingaben zu einem einzigen Inhalt zusammenzufassen.
Base64-Kodierung – Aktivieren Sie diese Option, um die Texteingabe in Base64-Kodierung umzuwandeln.
Anmerkung:
- Die Eigenschaft „Inhalt“ wird nur angezeigt, wenn die Eingabansicht vom Typ „Dokument“ ist. Der Wert, der „Inhalt“ zugewiesen wird, muss für Dokumenteingaben im Base64-Format vorliegen, während Snap automatisch Binärdaten als Inhalt für binäre Eingabetypen verwendet.
- Der Dokumentname kann speziell für multimodale Dokumenttypen festgelegt werden.
- Die Eigenschaft „Encode Base64“ codiert Texteingaben standardmäßig in Base64. Wenn diese Option deaktiviert ist, wird der Inhalt ohne Codierung weitergeleitet.
Entwurf eines multimodalen Prompt-Workflows
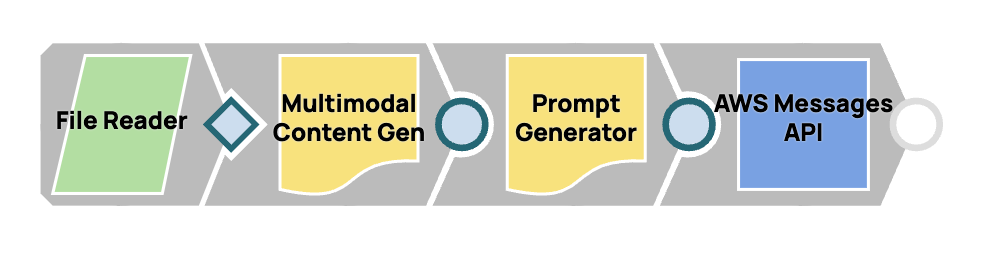
In diesem Prozess integrieren wir mehrere Snaps, um einen nahtlosen Workflow für die multimodale Inhaltserstellung und schnelle Bereitstellung zu schaffen. Durch die Verbindung des Multimodal Content Generator Snap mit dem Prompt Generator Snap konfigurieren wir ihn für die Verarbeitung multimodaler Inhalte. Die fertige Nachrichten-Nutzlast wird dann von Anthropic Claude über AWS Messages an Claude gesendet.
Schritte:
1. Fügen Sie den File Reader Snap hinzu: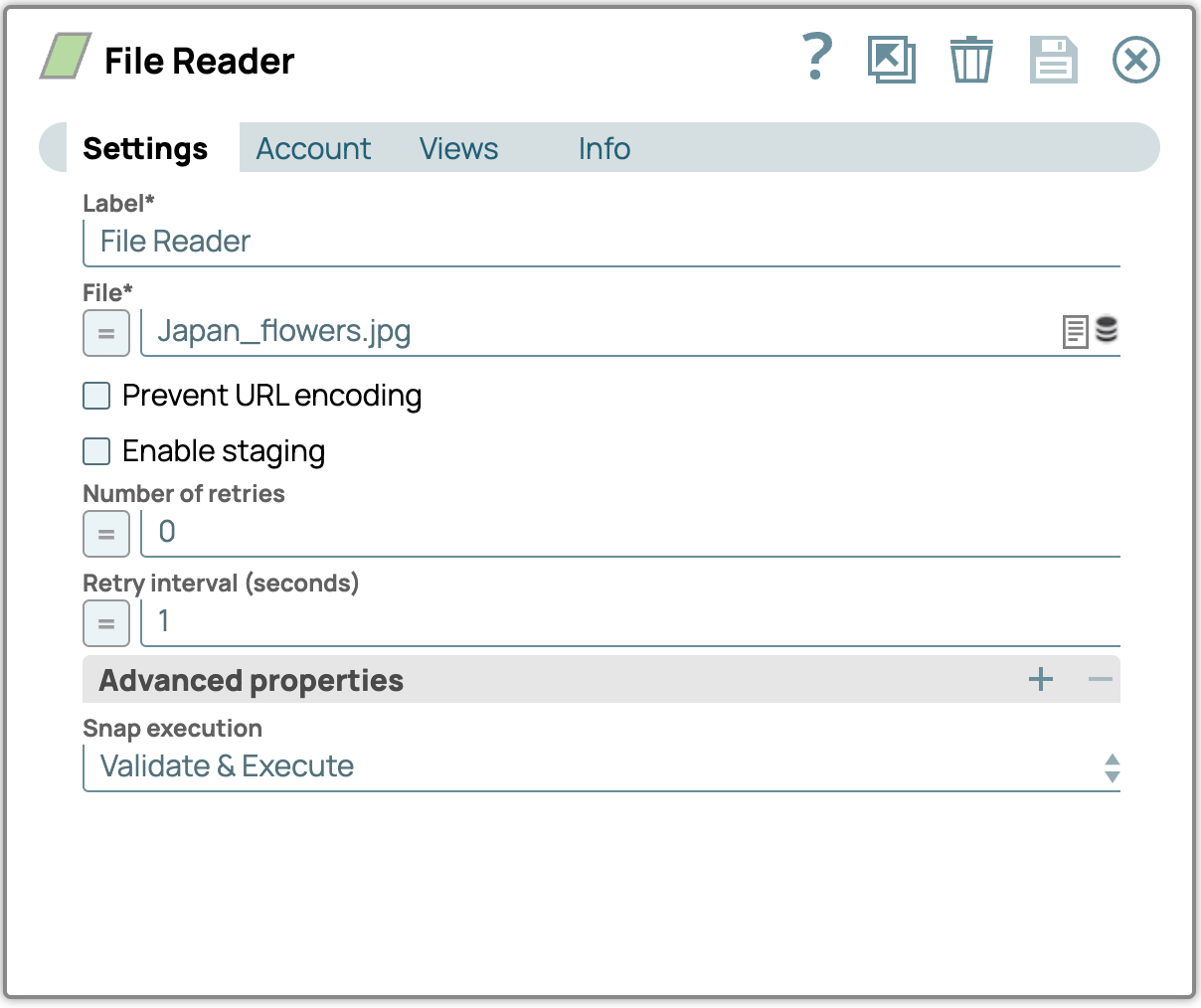
- Ziehen Sie den File Reader Snap per Drag & Drop auf die Designer-Arbeitsfläche.
- Konfigurieren Sie den File Reader Snap, indem Sie das Einstellungsfeld aufrufen und dann eine Datei mit Bildern (z. B. eine PDF-Datei) auswählen. Laden Sie die Beispielbilddateien am Ende dieses Beitrags herunter, falls Sie dies noch nicht getan haben.
Beispielbilddatei (Japan_flowers.jpg)

2. Fügen Sie den Snap „Multimodal Content Generator“ hinzu: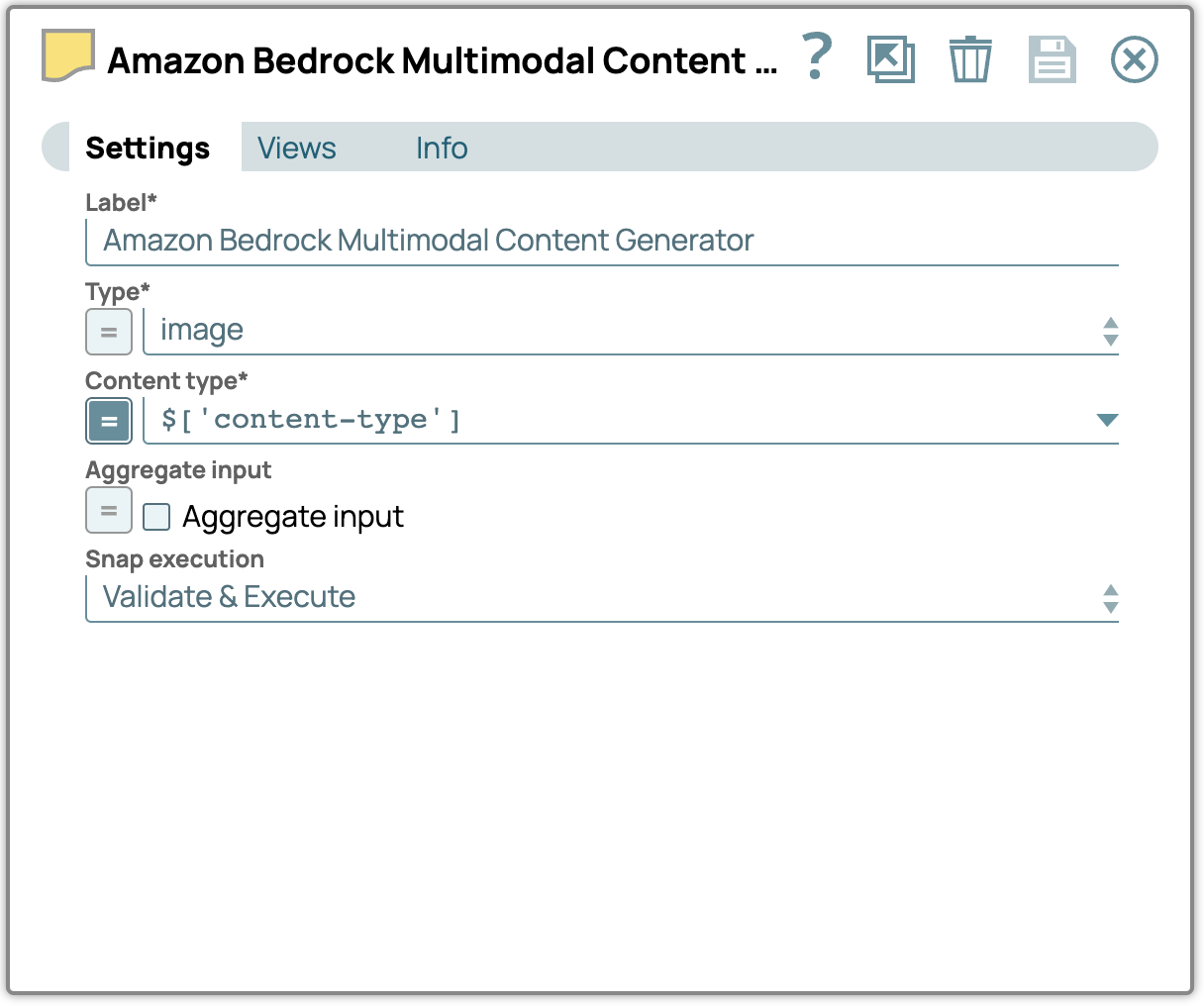
- Ziehen Sie den Snap „Multimodal Content Generator “ per Drag & Drop auf den Designer und verbinden Sie ihn mit dem Snap „File Reader “.
- Öffnen Sie das Einstellungsfenster, wählen Sie den Dateityp aus und geben Sie den entsprechenden Inhaltstyp an.
- Hier ist eine detaillierte Beschreibung der Ausgabeattribute des Multimodal Content Generators:
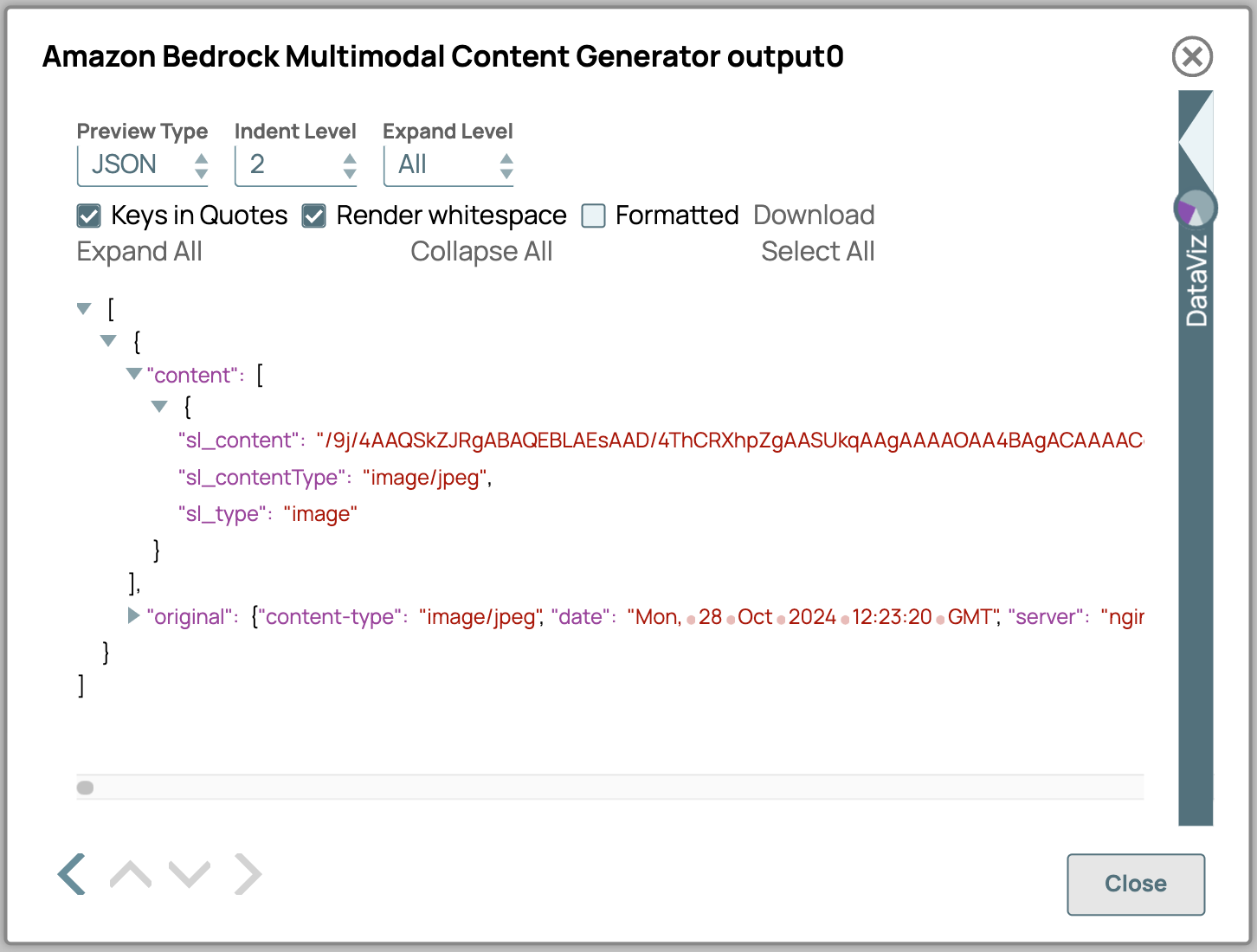
- sl_content: Enthält den eigentlichen Inhalt, der im Base64-Format kodiert ist.
- sl_contentType: Gibt den Inhaltstyp der Daten an. Dieser wird entweder aus der Konfiguration ausgewählt oder, wenn es sich bei der Eingabe um eine Binärdatei handelt, aus dem Binär-Header extrahiert.
- sl_type: Gibt den Inhaltstyp an, wie er in den Snap-Einstellungen definiert ist; in diesem Fall wird „Bild“ angezeigt.
3. Fügen Sie den Snap „Prompt Generator“ hinzu:
- Fügen Sie den Snap „Prompt Generator “ zum Designer hinzu und verknüpfen Sie ihn mit dem Snap „Multimodal Content Generator “.
- Aktivieren Sie im Einstellungsfeld das Kontrollkästchen „Erweiterte Eingabeaufforderung“ und konfigurieren Sie die Eigenschaft „Inhalt“ so, dass die Eingabe aus dem Snap „Multimodaler Inhaltsgenerator“ verwendet wird.
- Klicken Sie auf „Eingabeaufforderung bearbeiten“ und geben Sie Ihre Anweisungen ein.

4. LLM Snap hinzufügen und konfigurieren:
- Fügen Sie den Anthropic Claude auf AWS Message API Snap als LLM hinzu.
- Verbinden Sie diesen Snap mit dem Prompt Generator Snap.
- Wählen Sie in den Einstellungen ein Modell aus, das multimodale Inhalte unterstützt.
- Aktivieren Sie das Kontrollkästchen „Nachrichten-Nutzlast verwenden“ und geben Sie die Nachrichten-Nutzlast in das Feld „Nachrichten-Nutzlast“ ein.
5. Überprüfen Sie das Ergebnis: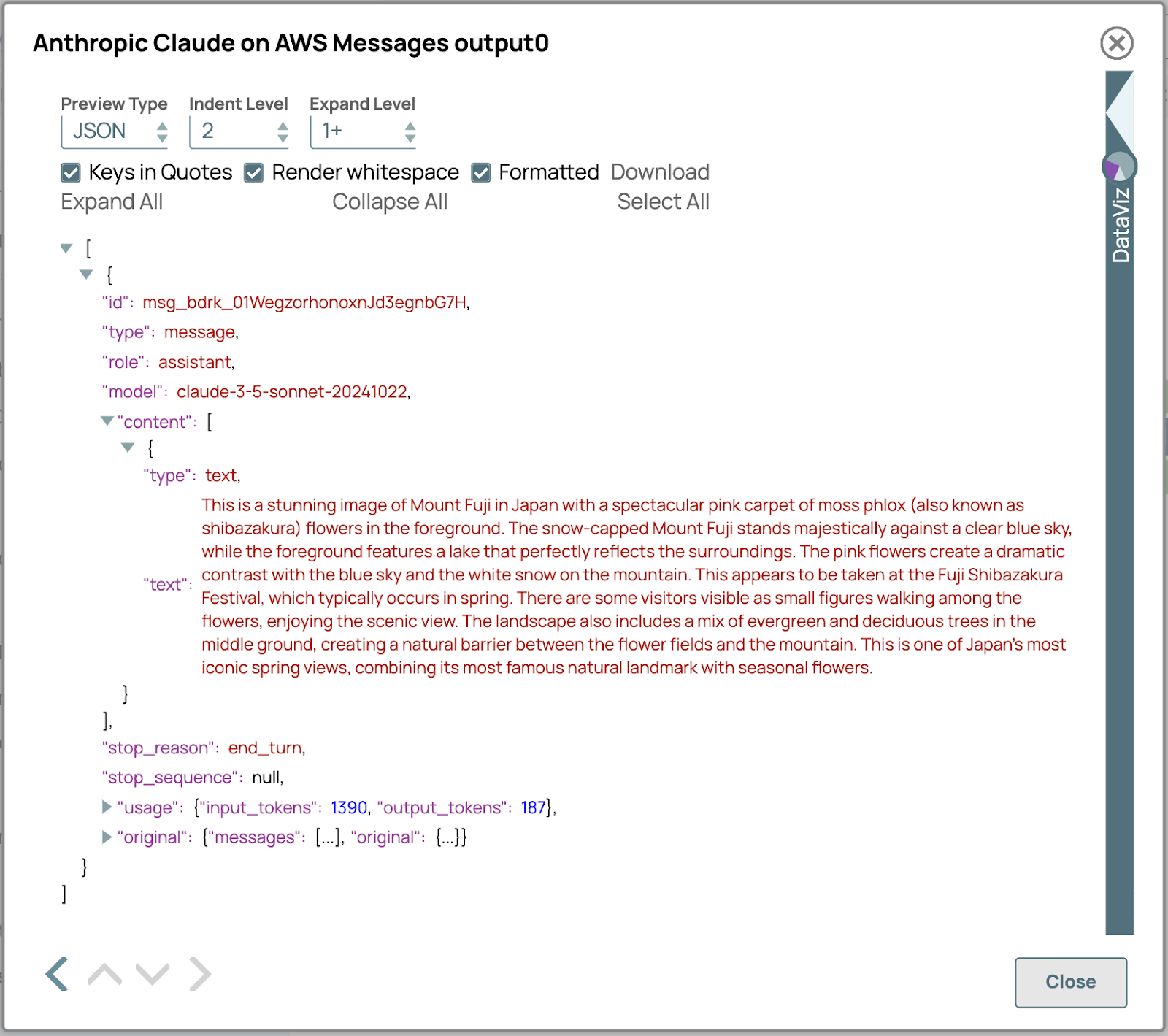
- Überprüfen Sie die Ausgabe von LLM Snap, um sicherzustellen, dass die multimodalen Inhalte korrekt verarbeitet wurden.
- Überprüfen Sie, ob die generierte Antwort den erwarteten Inhalts- und Formatvorgaben entspricht.
- Wenn Anpassungen erforderlich sind, überprüfen Sie die Einstellungen in früheren Snaps, um die Konfiguration zu verfeinern.
Multimodale Modelle für die erweiterte Datenextraktion
Multimodale Modelle definieren die Datenextraktion neu, indem sie über die traditionellen OCR-Fähigkeiten hinausgehen. Im Gegensatz zu OCR, das in erster Linie Bilder in Text umwandelt, analysieren und interpretieren diese Modelle direkt Inhalte in PDF-Dateien und Bildern und erfassen komplexe Kontextinformationen wie Layout, Formatierung und semantische Beziehungen, die mit OCR allein nicht erreicht werden können. Durch das Verständnis sowohl textueller als auch visueller Strukturen kann multimodale KI komplexe Dokumente wie Tabellen, Formulare und eingebettete Grafiken verarbeiten, ohne dass separate OCR-Prozesse erforderlich sind. Dieser Ansatz verbessert nicht nur die Genauigkeit, sondern optimiert auch die Arbeitsabläufe, indem er die Abhängigkeit von herkömmlichen OCR-Tools verringert.
In der heutigen datenreichen Umgebung werden Informationen oft in unterschiedlichen Formaten präsentiert, sodass die Fähigkeit, verschiedene Datenquellen zu analysieren und daraus Erkenntnisse zu gewinnen, unerlässlich ist. Stellen Sie sich vor, Sie verwalten eine Sammlung von Rechnungen, die als PDF-Dateien oder Fotos von Scannern und Smartphones gespeichert sind, und benötigen einen optimierten Ansatz, um deren Inhalt zu interpretieren. Multimodale große Sprachmodelle (LLMs) eignen sich hervorragend für solche Szenarien, da sie eine nahtlose Extraktion von Informationen aus verschiedenen Dateitypen ermöglichen. Diese Modelle unterstützen Aufgaben wie die automatische Identifizierung wichtiger Details, die Erstellung umfassender Zusammenfassungen und die Analyse von Trends in Rechnungen, unabhängig davon, ob es sich um gescannte Dokumente oder Bilder handelt. Hier finden Sie eine Schritt-für-Schritt-Anleitung zur Implementierung dieser Funktionalität in SnapLogic.
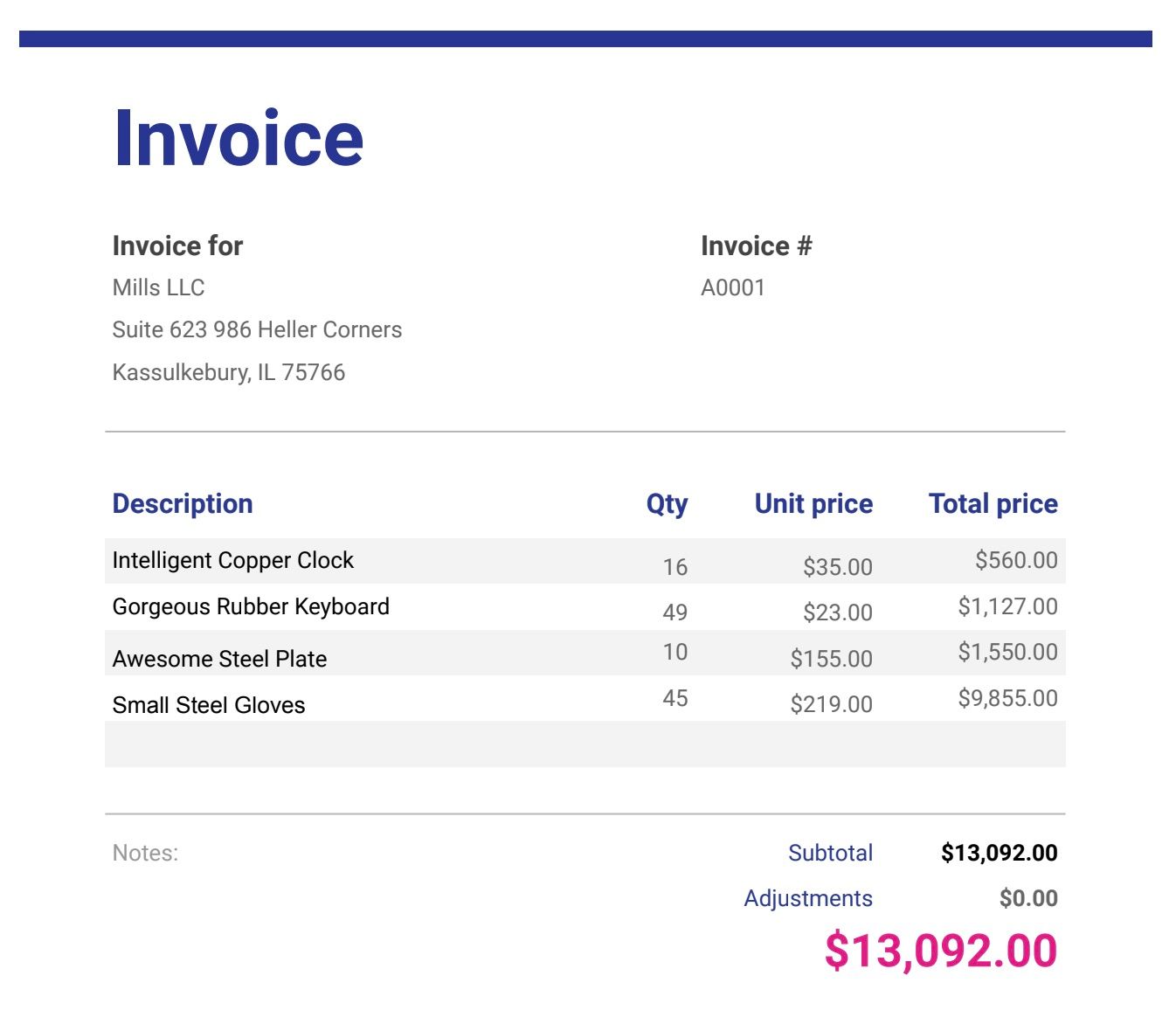
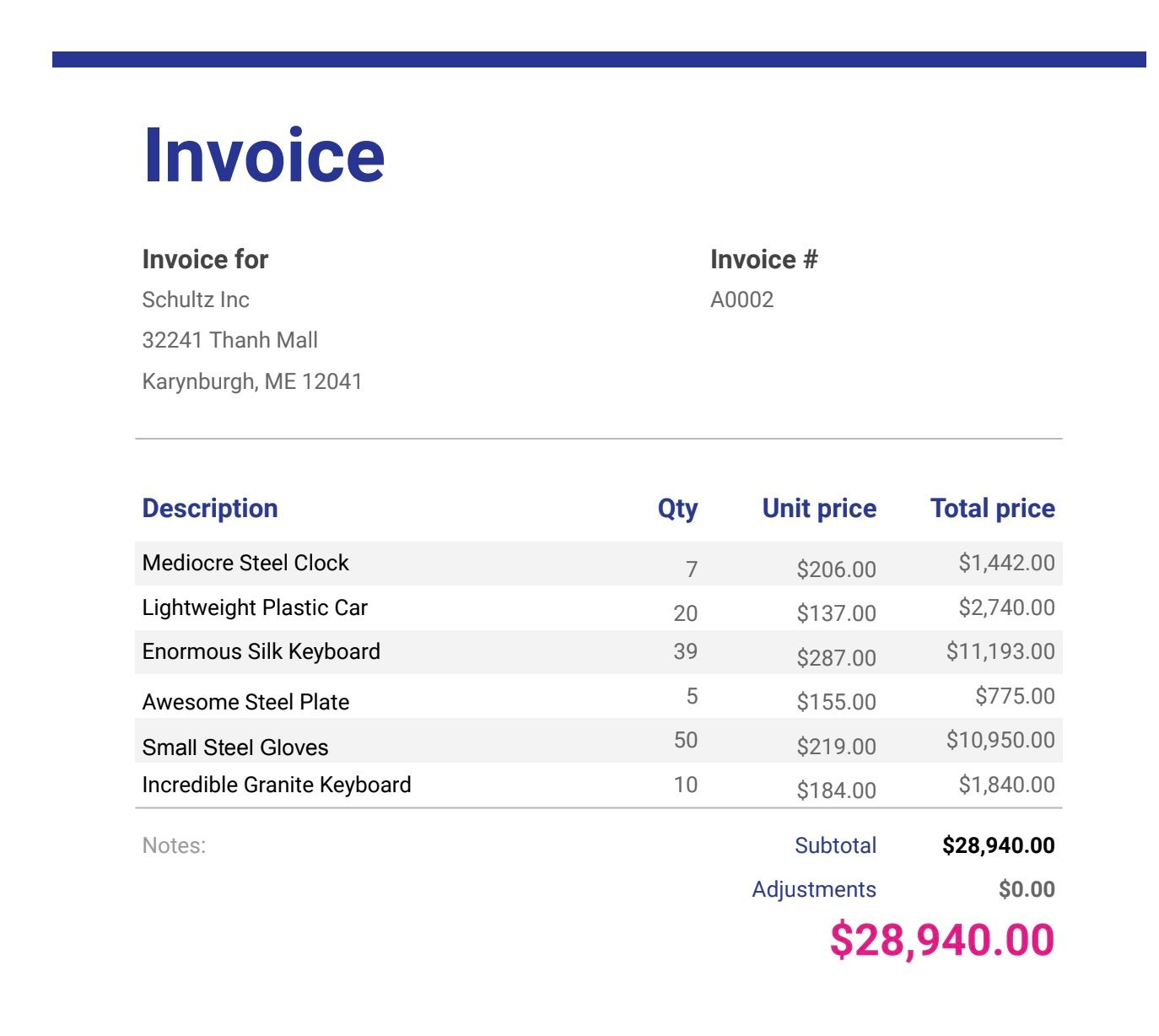
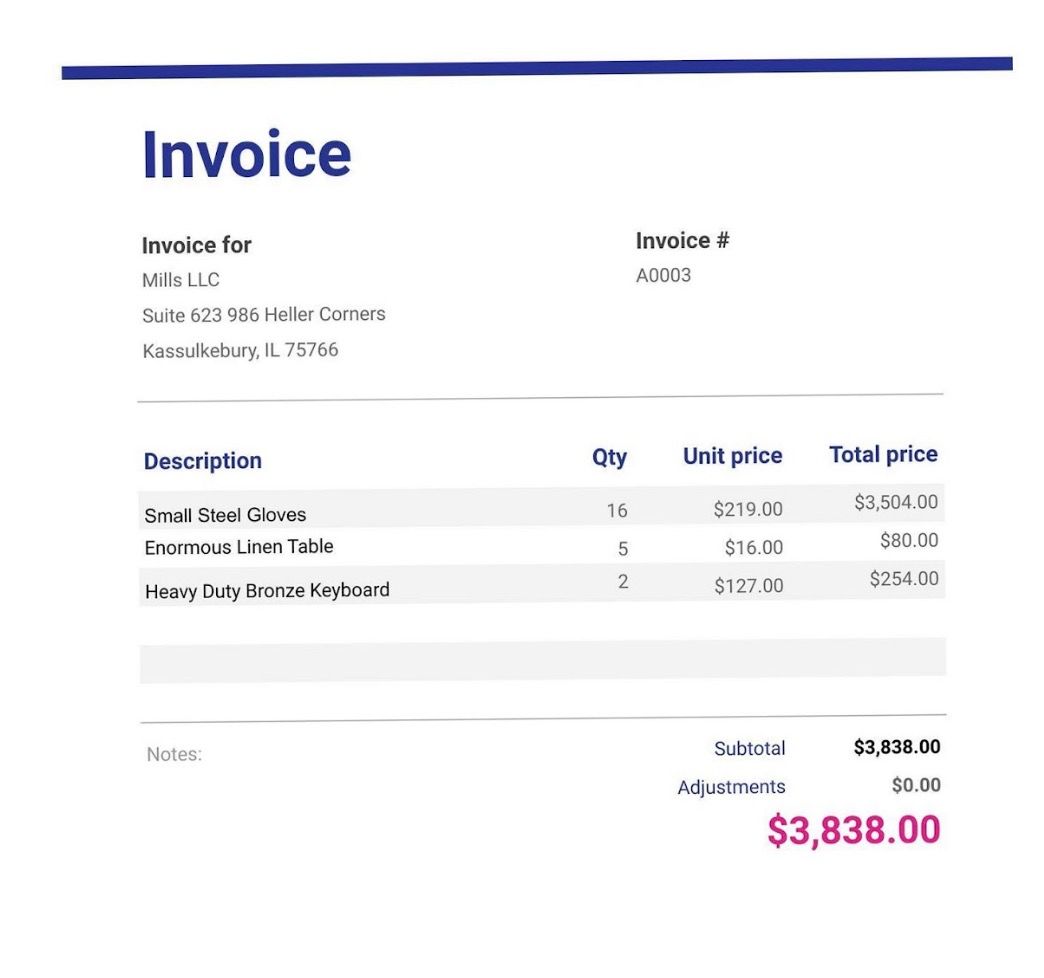
Beispiel-Rechnungsdateien ( laden Sie die Dateien am Ende dieses Beitrags herunter, falls Sie dies noch nicht getan haben)
Laden Sie die Rechnungsdateien hoch.
- Öffnen Manager Seite und gehen Sie zu Ihrem Projekt, das zur Speicherung der Pipelines und zugehörigen Dateien verwendet wird.
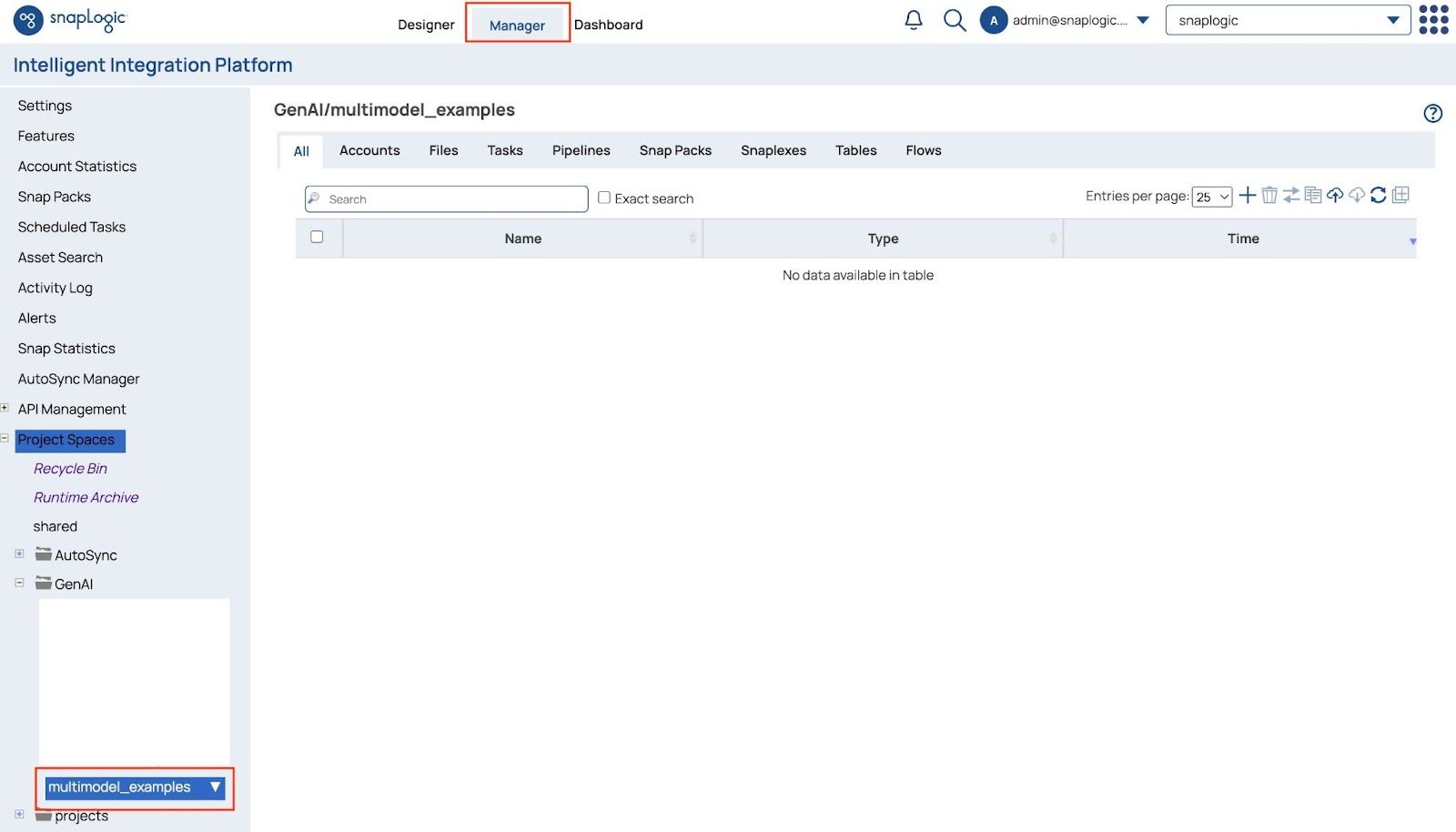
- Klicken Sie auf die + (Plus-)Zeichen und auswählen Datei
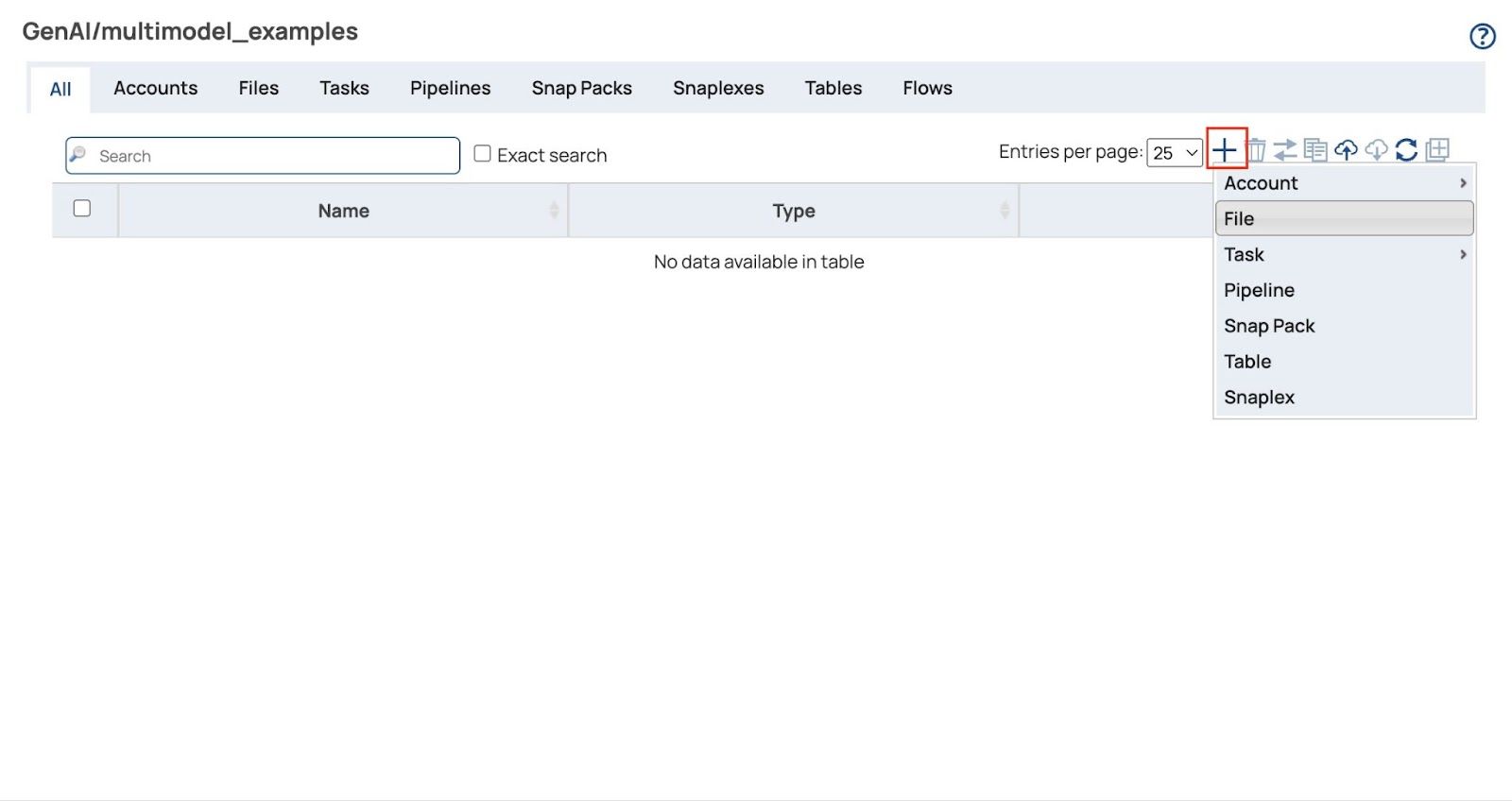
- Die Datei hochladen Ein Dialogfeld wird angezeigt. Klicken Sie auf „Dateien auswählen“, um alle Rechnungsdateien im PDF- und Bildformat auszuwählen (laden Sie die Musterrechnungsdateien am Ende dieses Beitrags herunter, falls Sie dies noch nicht getan haben).
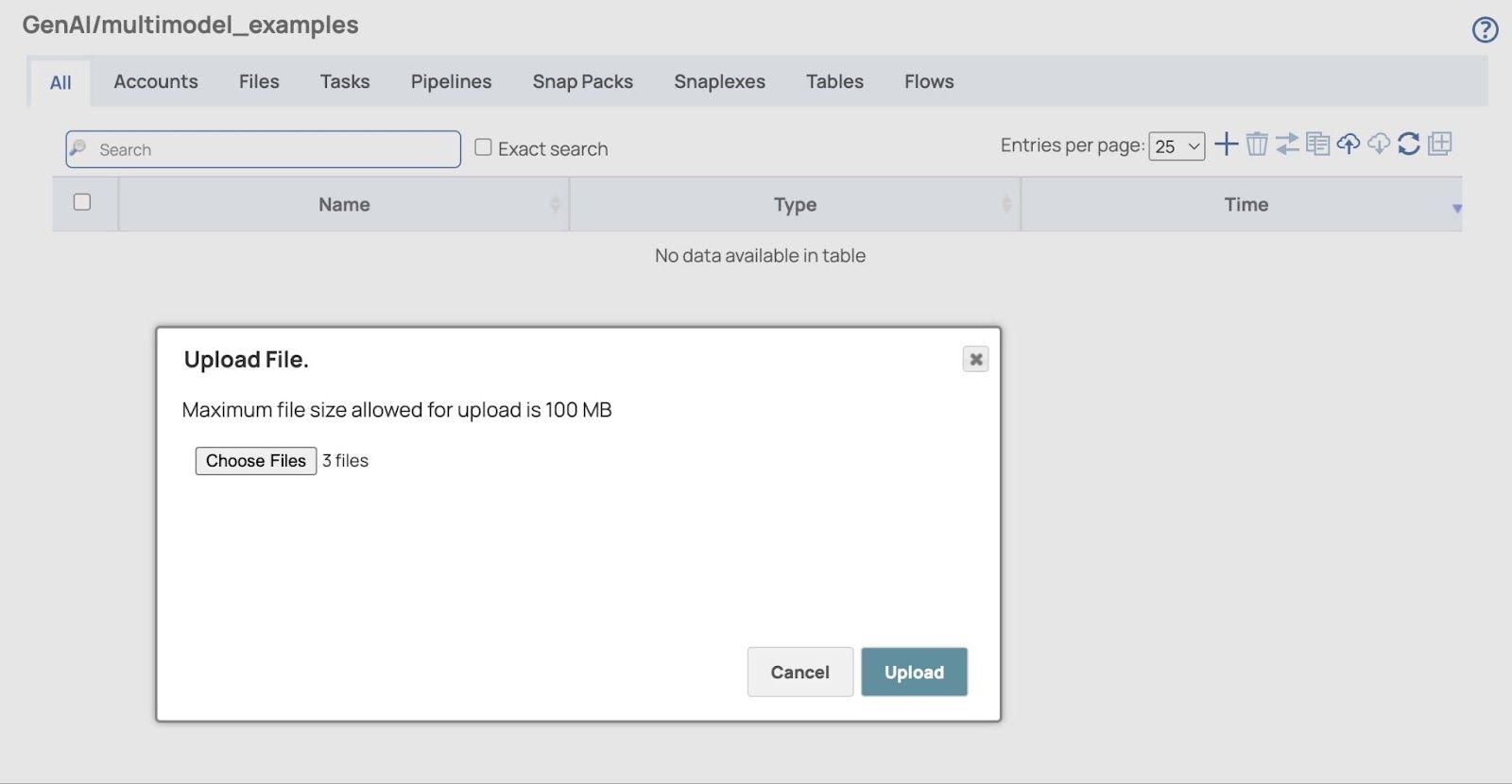
- Klicken Hochladen Schaltfläche und die hochgeladenen Dateien werden angezeigt.
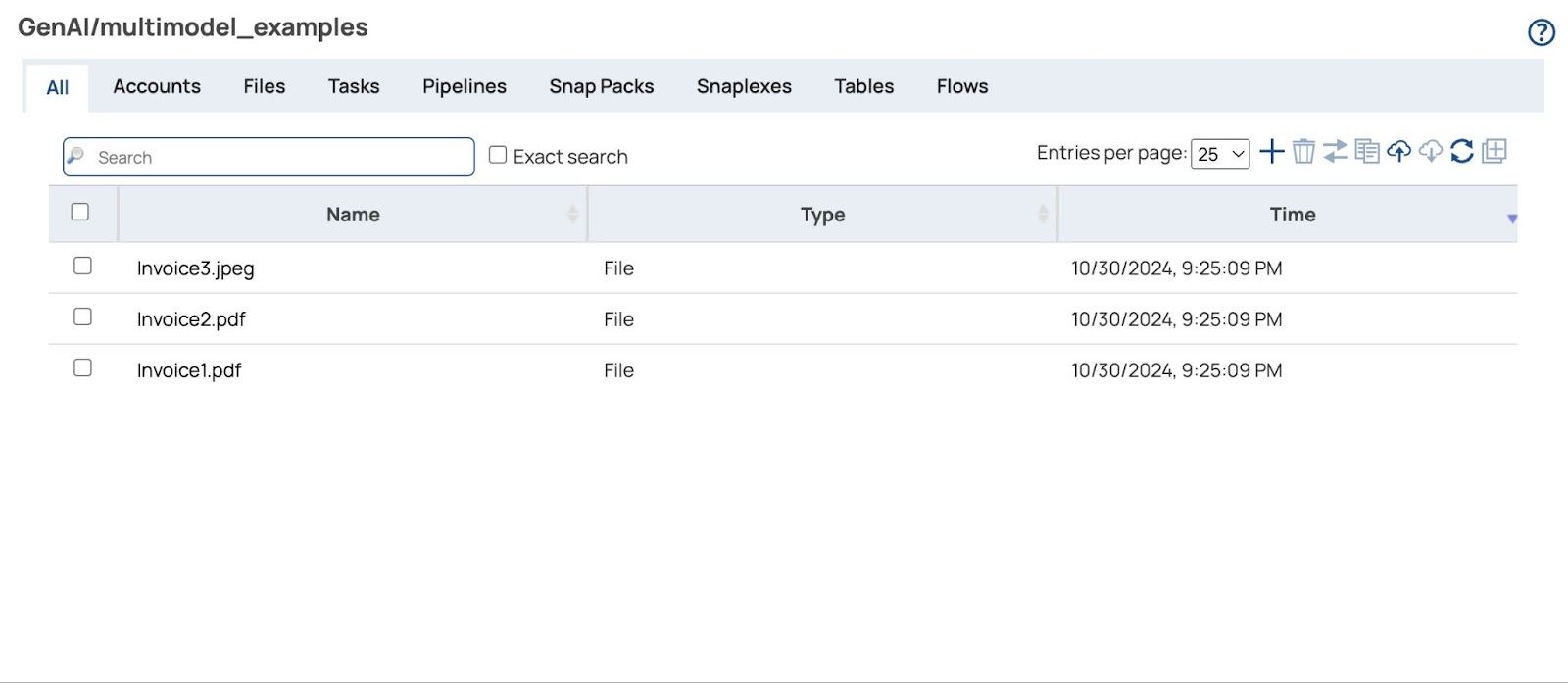
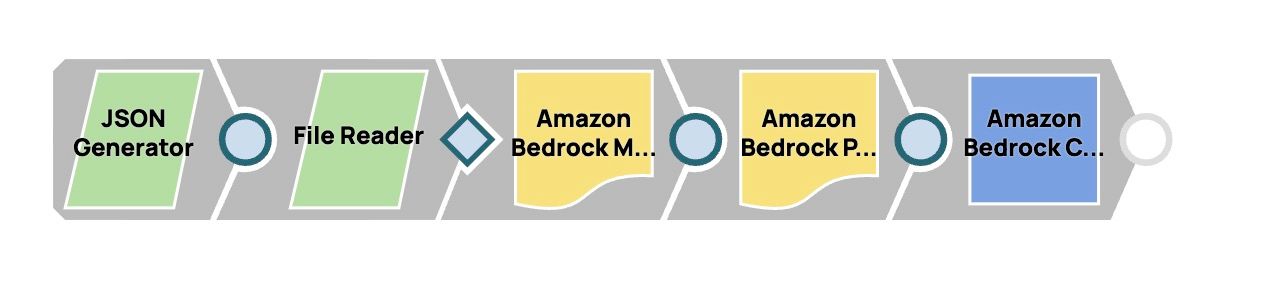
Aufbau der Pipeline
- Fügen Sie den JSON Generator Snap hinzu:
- Ziehen Sie den JSON-Generator per Drag & Drop auf die Designer-Arbeitsfläche.
- Klicken Sie auf das Symbol „Snap“, um die Einstellungen zu öffnen, und klicken Sie dann auf die Schaltfläche „JSON bearbeiten“.
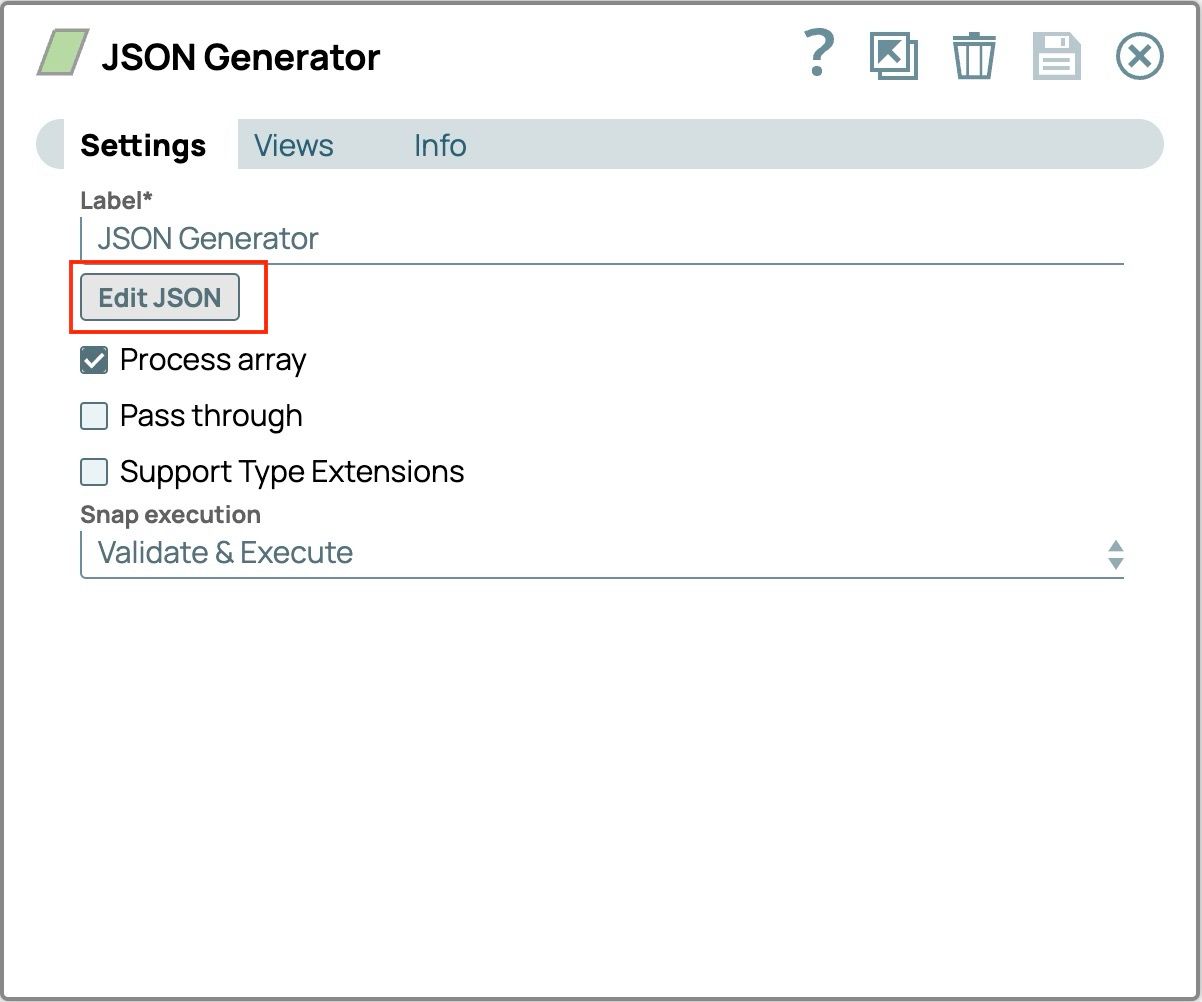
- Markieren Sie den gesamten Text aus der Vorlage und löschen Sie ihn.
- Fügen Sie alle Rechnungsdateinamen im unten angegebenen Format ein. Der Editor sollte wie folgt aussehen.
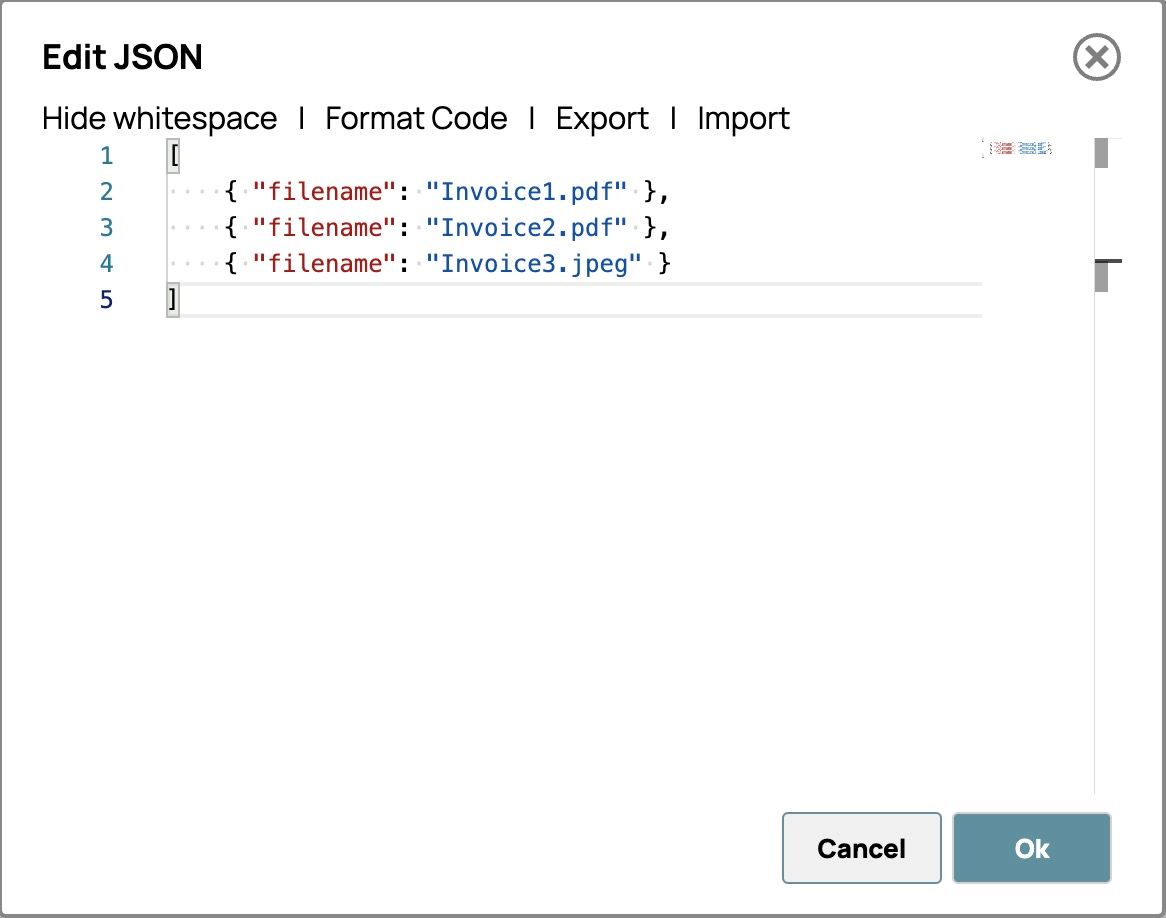
- Klicken Sie unten rechts auf „OK“, um die Eingabeaufforderung zu speichern.
- Speichern Sie die Einstellungen und schließen Sie Snap.
- Fügen Sie den File Reader Snap hinzu:
- Ziehen Sie den File Reader Snap per Drag & Drop auf die Designer-Arbeitsfläche.
- Klicken Sie auf „Snap“, um das Konfigurationsfenster zu öffnen.
- Verbinden Sie den Snap mit dem JSON-Generator Führen Sie die folgenden Schritte aus:
- Registerkarte „Ansichten“ auswählen
- Klicken Sie auf die Plus-Schaltfläche (+) auf der Eingabe Fenster zum Hinzufügen der Eingabeansicht (input0)
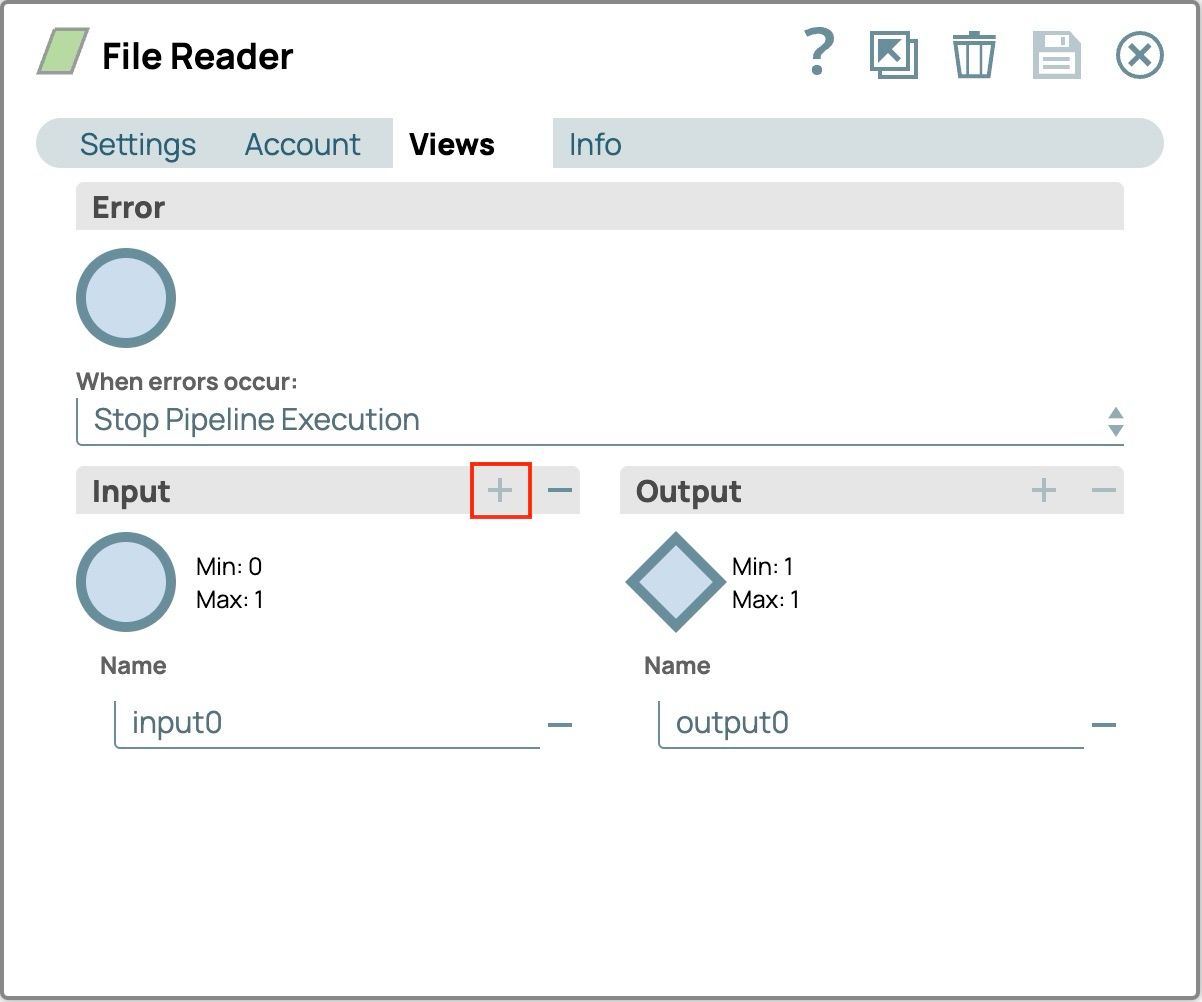
- Konfiguration speichern
- Der Snap auf der Leinwand verfügt über die Eingabeansicht. Verbinden Sie ihn mit dem JSON Generator Snap .
- Wählen Sie im Konfigurationsfenster die Registerkarte „Einstellungen“ aus.
- Setzen Sie die Datei Feld, indem Sie auf das Gleichheitszeichen vor dem Texteingabefeld klicken und es auf $Dateiname alle Dateien zu lesen, die wir in der JSON-Generator Snap
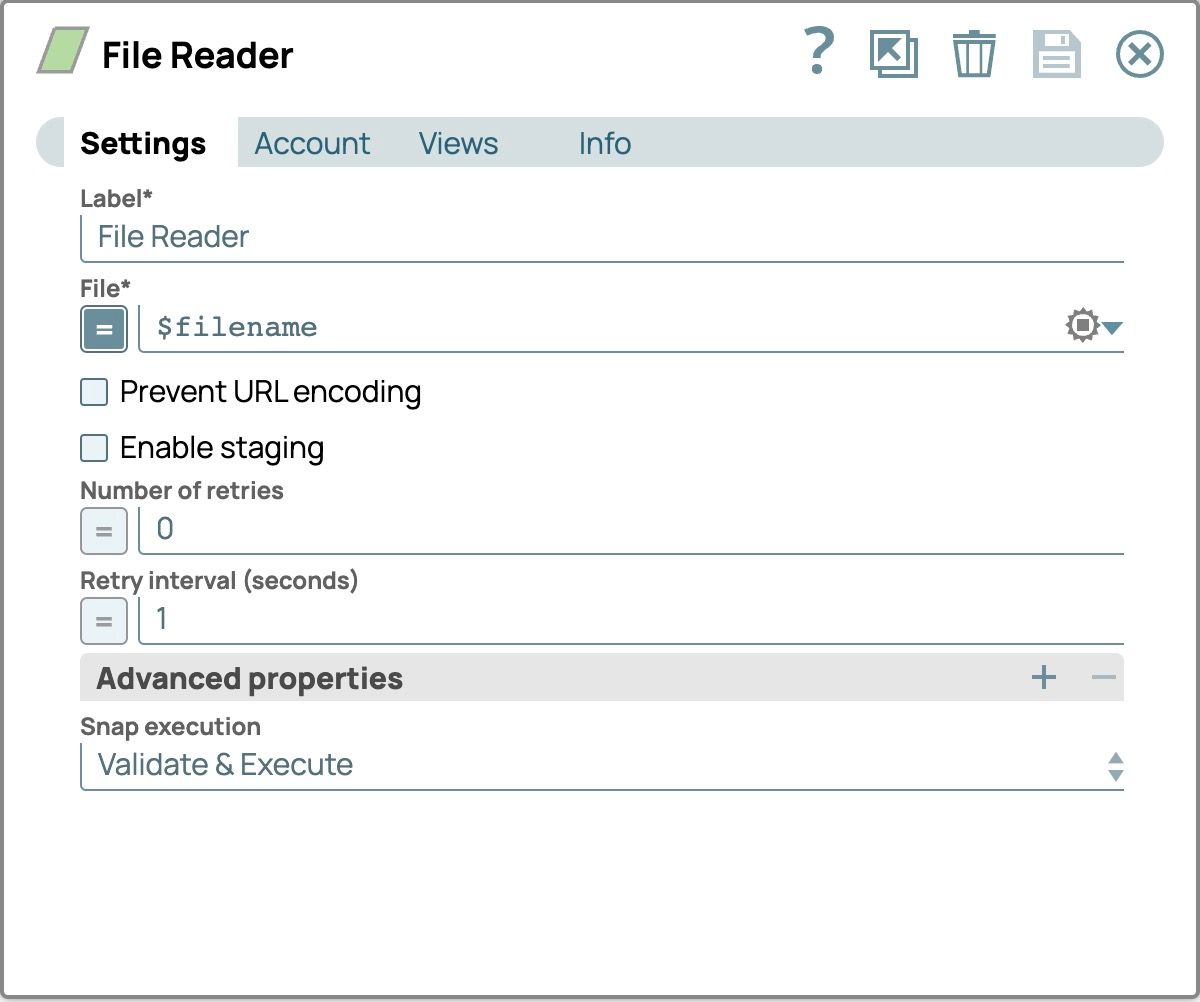
Überprüfen Sie die Pipeline, um die Ausgabe des Dateilesers anzuzeigen.
Felder, die im Multimodal Content Generator Snap verwendet werden
- Der Content-Type gibt den Dateityp an .
- Inhaltsort zeigt den Dateipfad an und wird im Dokumentnamen verwendet
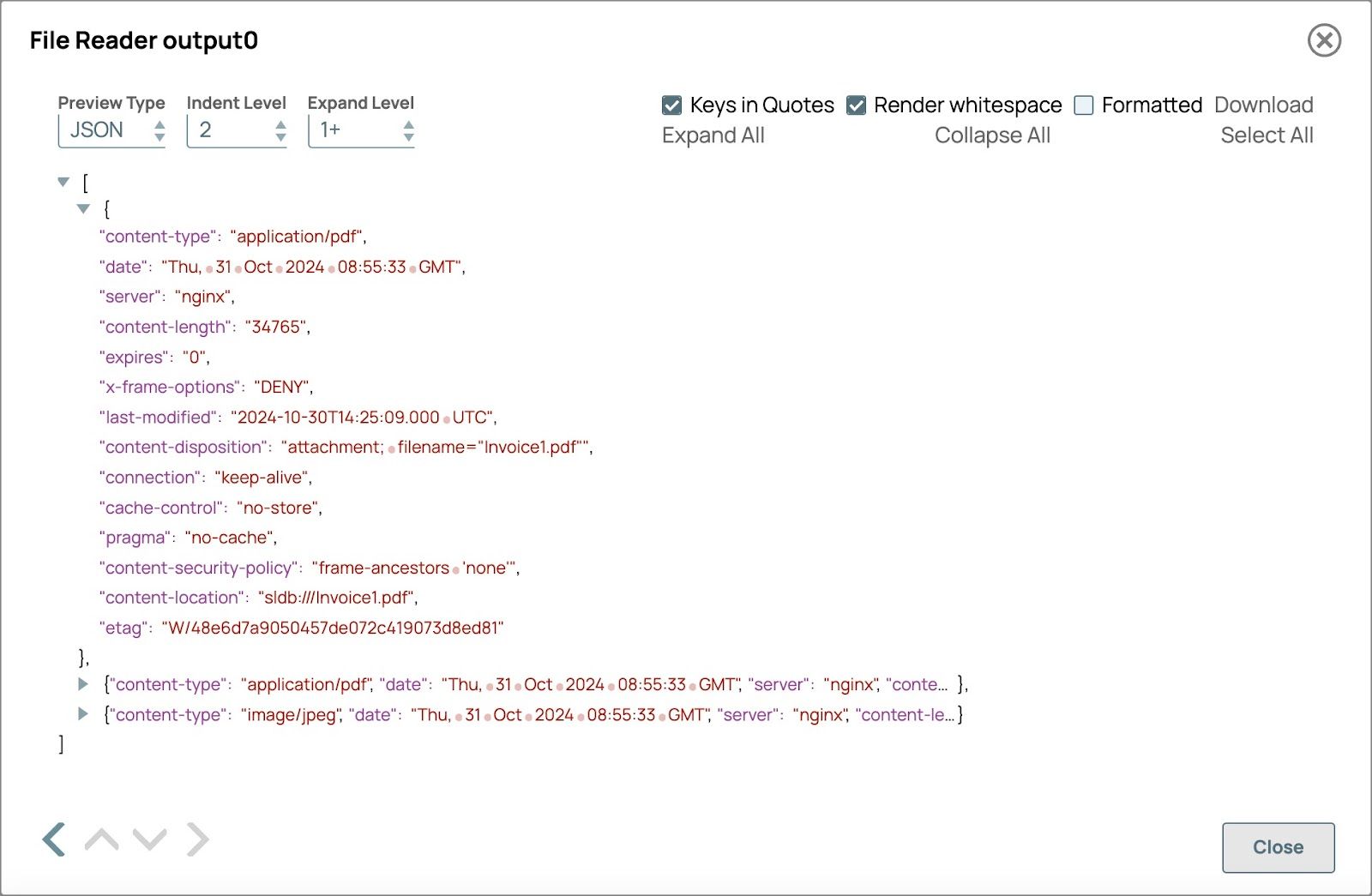
- Fügen Sie den Snap „Multimodal Content Generator“ hinzu:
- Ziehen Sie den Multimodal Content Generator Snap per Drag & Drop auf die Designer-Arbeitsfläche und verbinden Sie ihn mit dem File Reader Snap.
- Klicken Sie auf „Snap“, um das Einstellungsfenster zu öffnen, und konfigurieren Sie die folgenden Felder:
- Typ:
- den Ausdruck aktivieren
- Setze den Wert auf$['content-location'].endsWith('.pdf') ? 'document' : 'image'
- Dokumentname
- den Ausdruck aktivieren
- Setzen Sie den Wert auf
$[‘content-location’].snakeCase() - Verwenden Sie die Snake-Case-Version des Dateipfads als Dokumentnamen, um jede Datei zu identifizieren und sie mit der Amazon Bedrock Converse API kompatibel zu machen. Bei Snake Case werden Wörter in Kleinbuchstaben geschrieben und durch Unterstriche (_) getrennt.
- Gesamtinput
- das Kontrollkästchen aktivieren
- Verwenden Sie diese Option, um alle Eingabedateien zu einem einzigen Dokument zusammenzufassen.
- Die Einstellungen sollten nun wie folgt aussehen
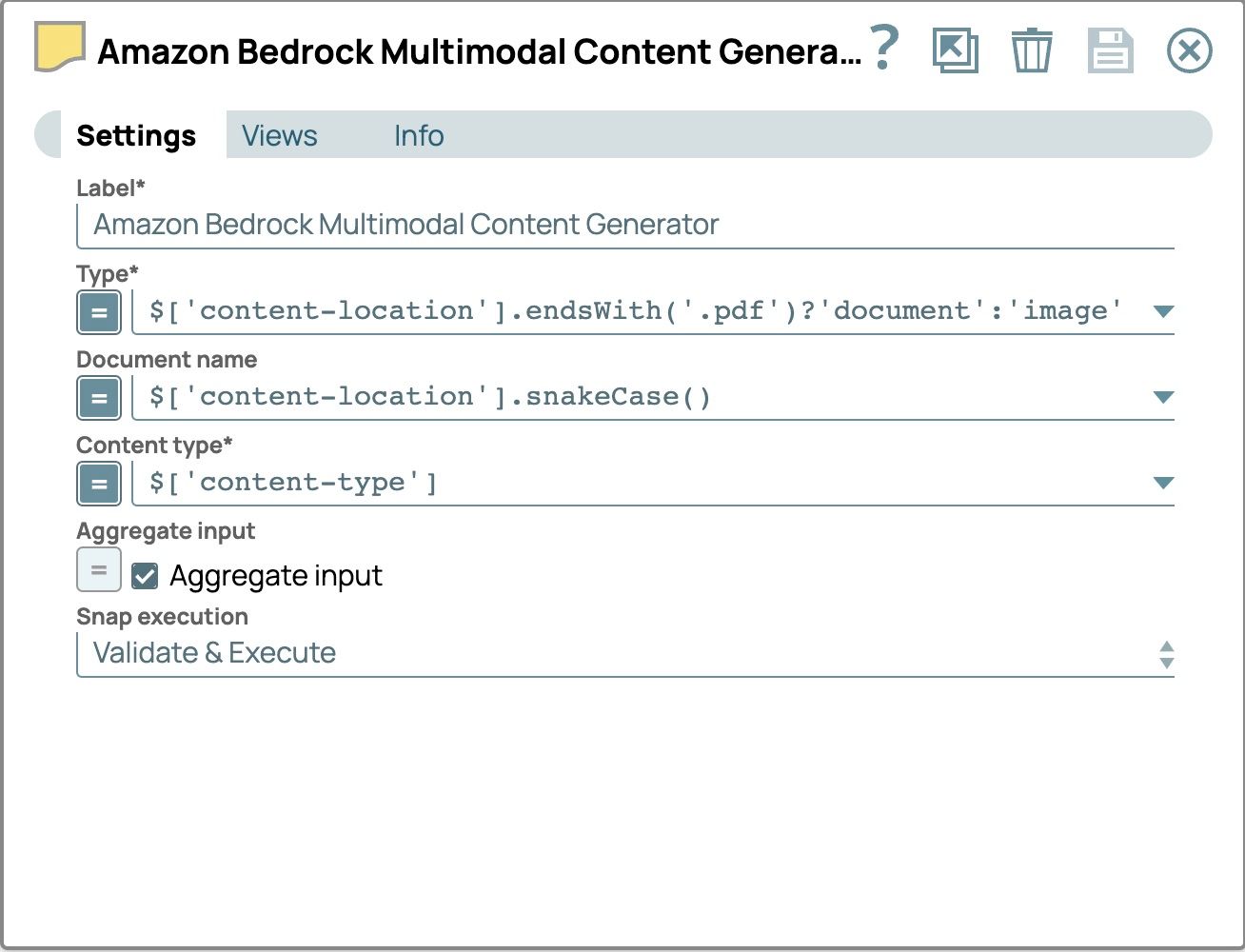
- Typ:
- Überprüfen Sie die Pipeline, um die Multimodaler Inhaltsgenerator Schnappausgabe.
Die Vorschauausgabe sollte wie in der folgenden Abbildung aussehen. Der sl_type lautet Dokument für die PDF-Datei und Bild für die Bilddatei und der Name ist der vereinfachte Dateipfad.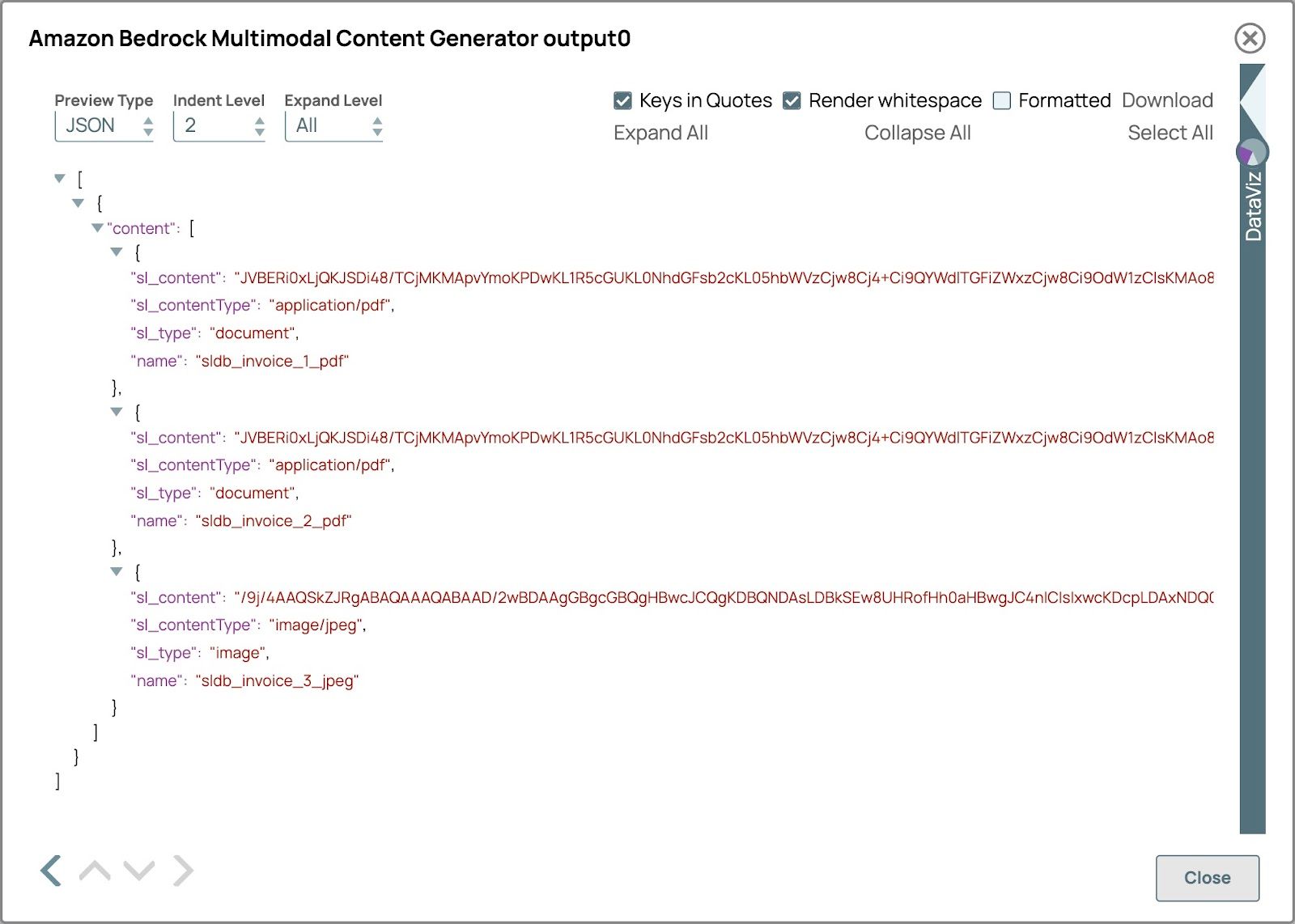
- Fügen Sie den Snap „Prompt Generator“ hinzu:
- Ziehen Sie den Prompt Generator Snap per Drag & Drop auf die Designer-Arbeitsfläche und verbinden Sie ihn mit dem Multimodal Content Generator Snap.
- Klicken Sie auf „Snap“, um das Einstellungsfenster zu öffnen, und konfigurieren Sie die folgenden Felder:
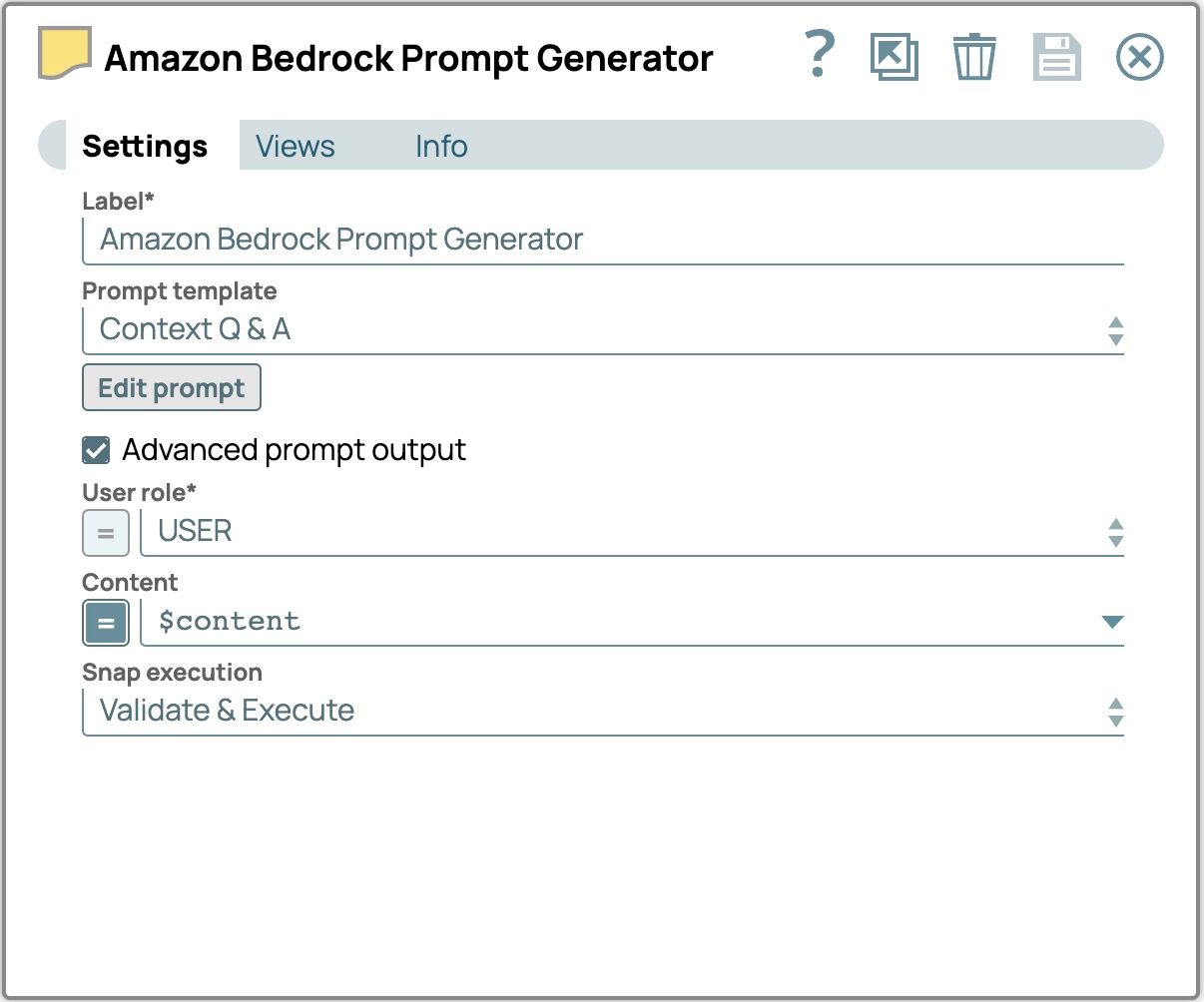
- Aktivieren Sie das Kontrollkästchen „Erweiterte Eingabeaufforderung ausgeben “.
- Setzen Sie den Inhalt auf $content, um den vom Multimodal Content Generator Snap eingegebenen Inhalt zu verwenden.
- Klicken Sie auf „Eingabeaufforderung bearbeiten“ und geben Sie Ihre Anweisungen ein. Zum Beispiel:
Basierend auf der Gesamtmenge aller Rechnungen,
welches Produkt hat die höchsten und niedrigsten Einkaufsmengen,
und in welchen Rechnungen sind diese Angaben zu finden?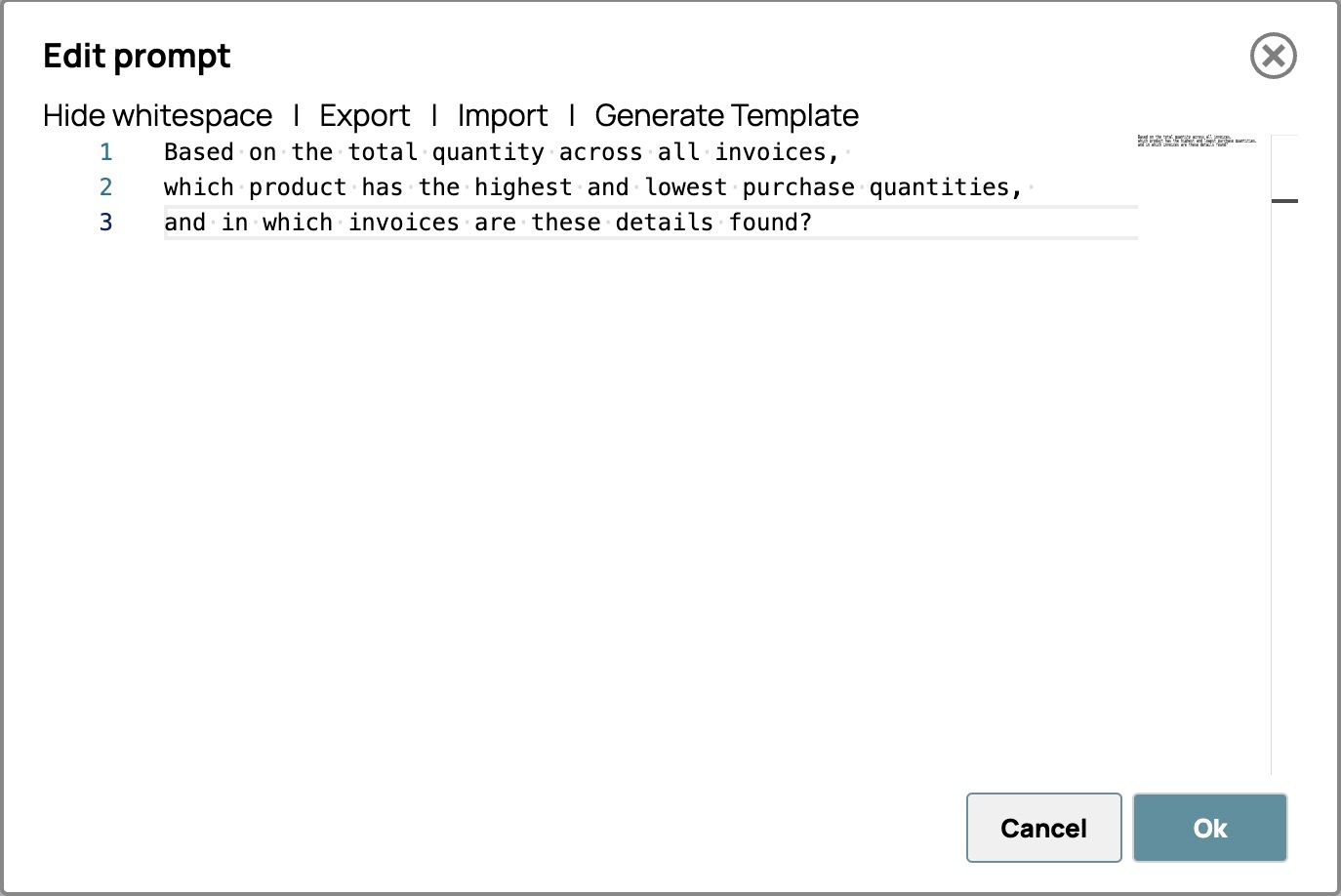
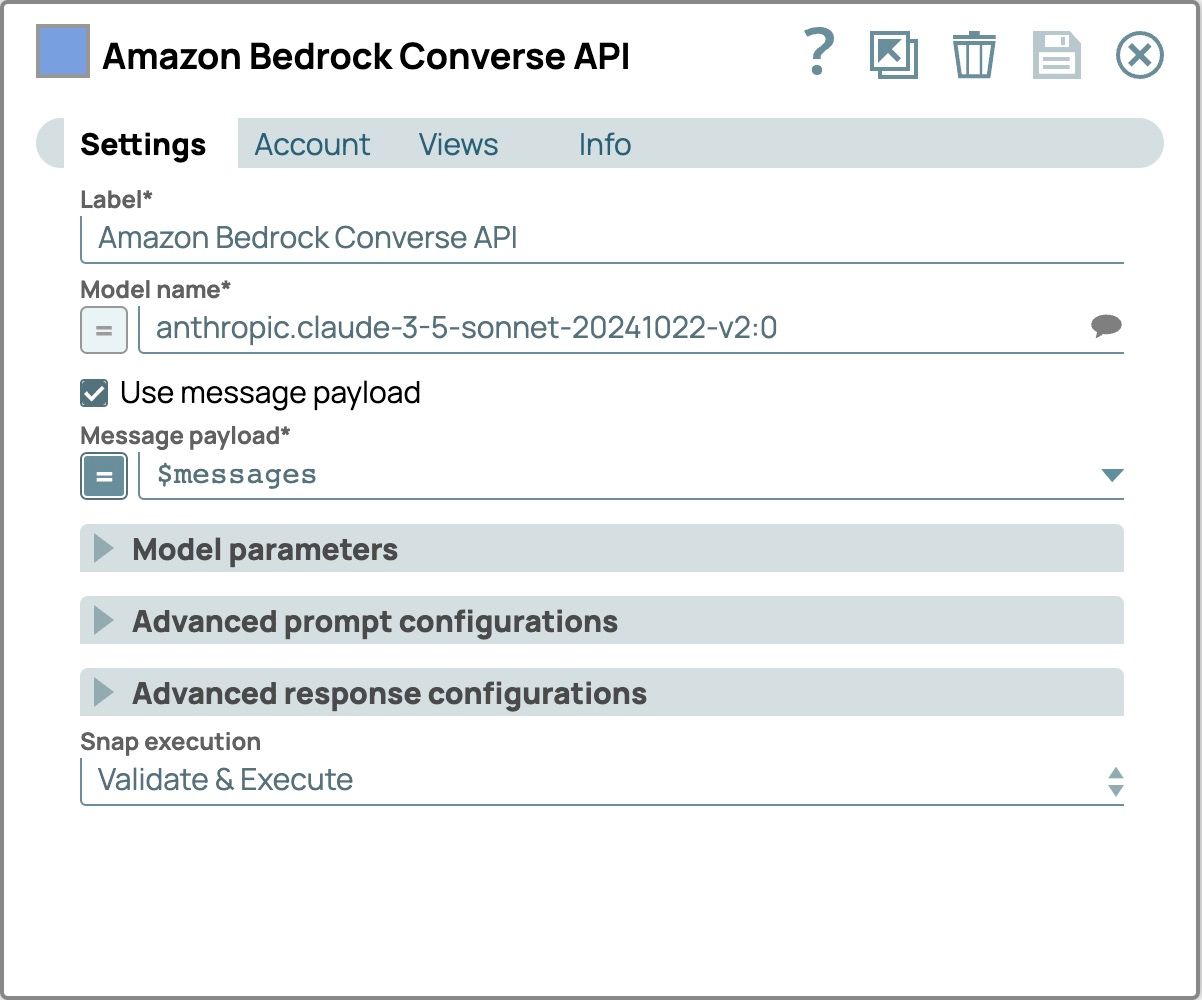
- LLM Snap hinzufügen und konfigurieren:
- Fügen Sie den Amazon Bedrock Converse API Snap als LLM hinzu.
- Verbinden Sie diesen Snap mit dem Prompt Generator Snap.
- Klicken Sie auf „Snap“, um das Konfigurationsfenster zu öffnen.
- Wählen Sie die Registerkarte „Konto“ und wählen Sie Ihr Konto aus.
- Wählen Sie die Einstellungen Registerkarte
- Wählen Sie ein Modell, das multimodale Inhalte unterstützt.
- Aktivieren Sie das Kontrollkästchen „Nachrichten-Nutzlast verwenden “.
- Setzen Sie die Nachrichten-Nutzlast zu $Nachrichten die Nachricht aus dem Prompt-Generator Snap
- Überprüfen Sie das Ergebnis:
Validieren Sie die Pipeline und öffnen Sie die Vorschau der Amazon Bedrock Converse API Klick. Das Ergebnis sollte wie folgt aussehen: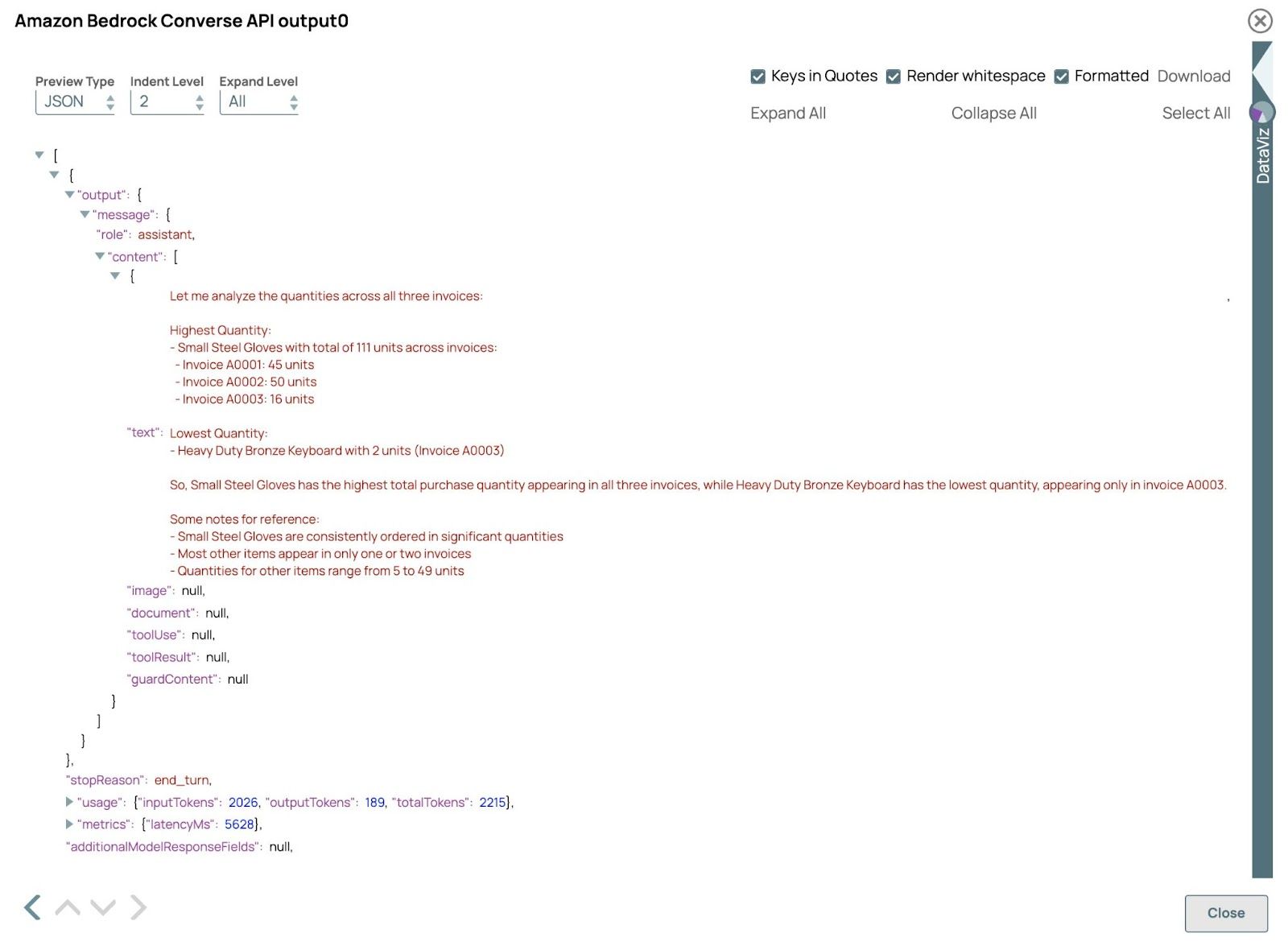
In diesem Beispiel verarbeitet das LLM erfolgreich Rechnungen sowohl im PDF- als auch im Bildformat und demonstriert damit seine Fähigkeit, unterschiedliche Eingaben in einem einzigen Workflow zu verarbeiten. Durch die Extraktion und Analyse von Daten aus diesen Formaten liefert das LLM genaue Antworten und Erkenntnisse und zeigt damit die Effizienz und Flexibilität der multimodalen Verarbeitung. Sie können die Abfragen in der Prompt-Generator Klicken Sie, um verschiedene Ergebnisse zu entdecken.





