In unserem letzten Beitrag zum Thema „Datenagent-Kontext“ haben wir dargelegt, warum der Kontext das grundlegende Problem für KI-Agenten in Unternehmen darstellt. Über dem Modell, der Rechenleistung und der Pipeline steht eine noch grundlegendere Anforderung: der Kontext. Ein Agent, der nicht weiß, mit welchen Systemen er verbunden ist, was diese Systeme enthalten oder wie man sie korrekt abfragt, wird Antworten generieren, die zwar plausibel erscheinen, aber nicht die Realität widerspiegeln.
Dieser Artikel bietet einen Überblick über die Context Library, eine Kernfunktion von Jean-Paul, dem Enterprise-KI-Agenten von SnapLogic, die dafür sorgt, dass KI-Agenten in Produktionsumgebungen von Unternehmen zuverlässig funktionieren. Er behandelt, wie Kontext ermittelt, gespeichert und durchgesetzt wird und warum gerade die Durchsetzung den Unterschied zwischen einer zuverlässigen Bereitstellung und einer gut gemeinten Demo ausmacht.
Warum KI-Agenten in Unternehmen beim Kontextverstehen versagen
Wenn ein KI-Agent eine Abfrage an Salesforce sendet, muss er bestimmte Details zu Ihrer Umgebung kennen: mit welcher Organisation er kommuniziert, welche Objekte vorhanden sind, welche Felder diese enthalten, welche Feldnamen die API tatsächlich erwartet und welche Objekte noch aktiv sind und welche hingegen veraltete Überbleibsel aus einem Integrationsprojekt von vor drei Jahren sind.
Diese Informationen müssen irgendwoher stammen. Sie sind weder in den Gewichten des Modells noch in der Konfiguration der Konnektoren enthalten. Ohne strukturierten Kontext greifen die Agenten auf Inferenz zurück. Beispielsweise:
- Abfrage nach „Account.Name“, obwohl das eigentliche Feld „Account.Customer_Name__c“ lautet
- SOQL-Abfrage für Objekte ohne Datensätze erstellen
- Falsch interpretierte Feldtypen, falsch interpretierte Null-Möglichkeiten und Rückgabewerte, die korrekt erscheinen, bis sie überprüft werden.
Der Kontext ist kein bloßes „Nice-to-have“. Er macht den Unterschied zwischen einem Agenten, der präzise abfragt, und einem, der falsche Schlussfolgerungen zieht.
Die Context Library ist SnapLogics Antwort darauf. Es handelt sich um eine strukturierte, durchsuchbare und sich selbst aktualisierende Wissensdatenbank, die Jean-Paul vor jeder Aktion konsultiert. Es ist sogar so festgelegt, dass sie vor jeder Aktion konsultiert werden muss. Und so funktioniert es.
Tool-Entdeckung: Wie der Kontext ins Spiel kommt
Die Context Library ist in der Jean-Paul-Admin-Oberfläche integriert und verfügt über zwei Hauptregisterkarten: „Tool Discovery “ und „Contexts“. Der Prozess beginnt unter „Tool Discovery“.
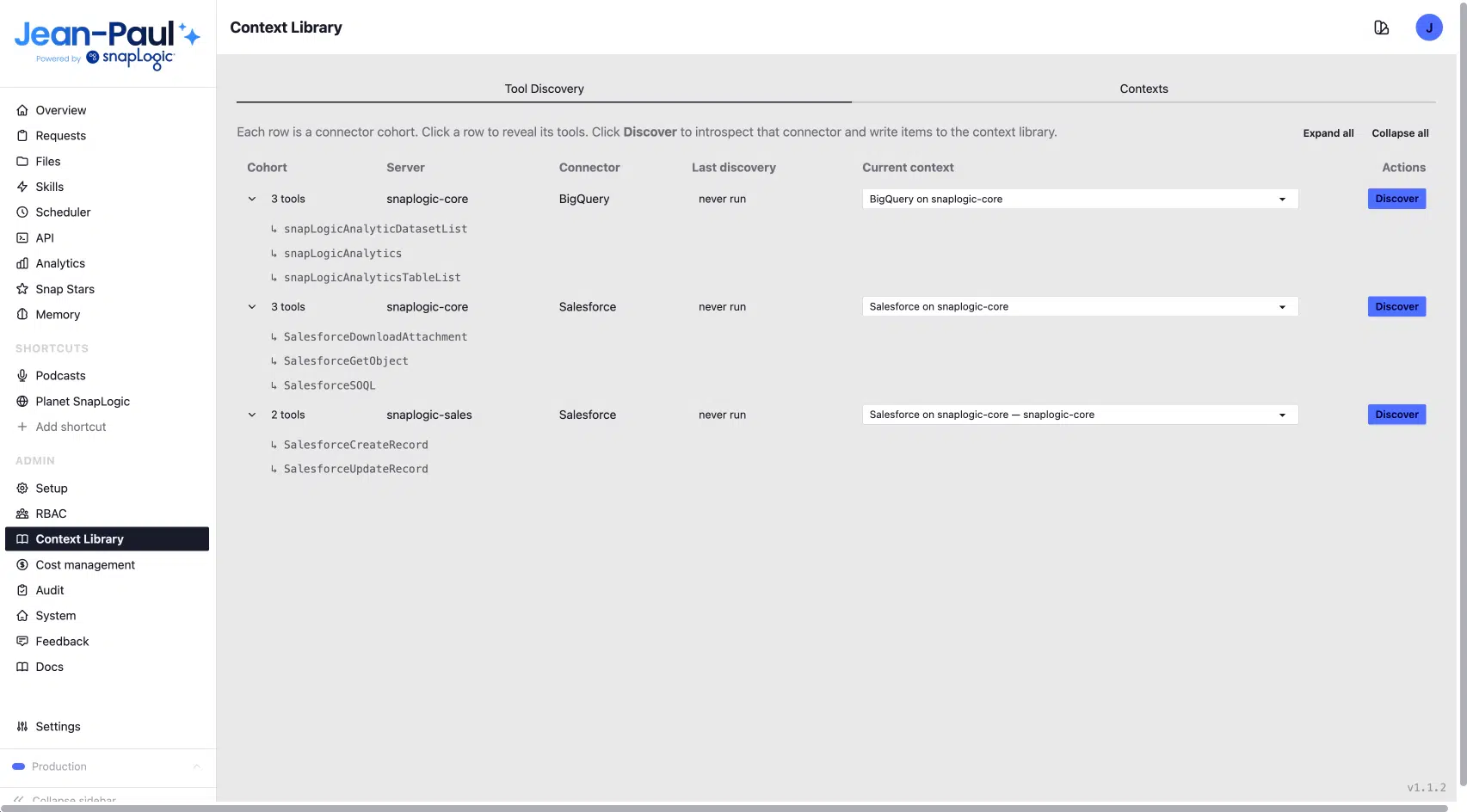
Auf der Registerkarte „Tool Discovery“ werden alle für Jean-Paul verfügbaren Konnektoren-Gruppen aufgelistet, darunter:
- BigQuery auf SnapLogic Core
- Salesforce auf SnapLogic Core
- Salesforce bei SnapLogic Sales
Jeder Eintrag zeigt das Datum an, an dem er zuletzt entdeckt wurde, und verfügt über eine einzige Schaltfläche „Entdecken“.
Durch Klicken auf „Discover“ wird der Live-Konnektor direkt analysiert. Jean-Paul kommuniziert mit dem verbundenen System, erfasst die vorhandenen Daten und speichert die Ergebnisse in der Bibliothek: Objektschemata, Feldbeschreibungen, Datentypen, Nullwert-Flags, Datensatzanzahlen, Zeitstempel der letzten Aktivität sowie eine zusammengefasste Zweckbeschreibung für jedes Objekt. Der Agent sieht, was tatsächlich vorhanden ist: aktuell, in Echtzeit und präzise.
Ein einziger Erkennungslauf in Salesforce liefert 59 Objekte, jedes mit vollständigen Metadaten auf Feldebene: API-Namen, Bezeichnungen, Feldanzahl und strukturierte Notizen, die der Agent zum Zeitpunkt der Abfrage lesen und auswerten kann. Jede Erkennungsfunktion ist speziell auf das System zugeschnitten, das sie analysiert.
Die Salesforce-Analyse ermittelt Objekte, die für die agentische Nutzung relevant sind, filtert diejenigen heraus, die keine Datensätze enthalten, und schließt Objekte aus, die keine Anpassungen oder aussagekräftigen Konfigurationen aufweisen. Auf diese Weise gelangt sie zu 59 sorgfältig ausgewählten, aussagekräftigen Objekten, anstatt eine ungefilterte Liste von mehreren hundert Objekten zu liefern.
Das gleiche Prinzip gilt für Datenplattformen (BigQuery, Snowflake, Databricks, Oracle, PostgreSQL), die eine Introspektion auf Katalogebene erfordern, da die Schemata auf Feldebene nicht selbstdokumentierend sind. Eine Kontextermittlung ist für jedes System of Record (Salesforce, ServiceNow, HCM-Plattformen) oder jedes Data Warehouse erforderlich, das angepasst oder erweitert werden kann. Jean-Paul verfügt über Erkennungsfunktionen für alle diese Systeme.
Der entscheidende architektonische Wandel: Dokumentation als Nebeneffekt der Selbstreflexion. Sie wird automatisch von der Plattform erstellt und spiegelt stets den aktuellen Zustand des Systems wider.
Die Registerkarte „Kontexte“: umfangreiches, strukturiertes Wissen
Sobald ein Objekt erkannt wurde, wird es zu einem umfangreichen Kontexteintrag auf der Registerkarte „Kontexte“. Dies ist es, was der Agent zum Zeitpunkt der Inferenz liest: ein strukturiertes Wissensdokument, das alle Informationen enthält, die für eine präzise Abfrage erforderlich sind.
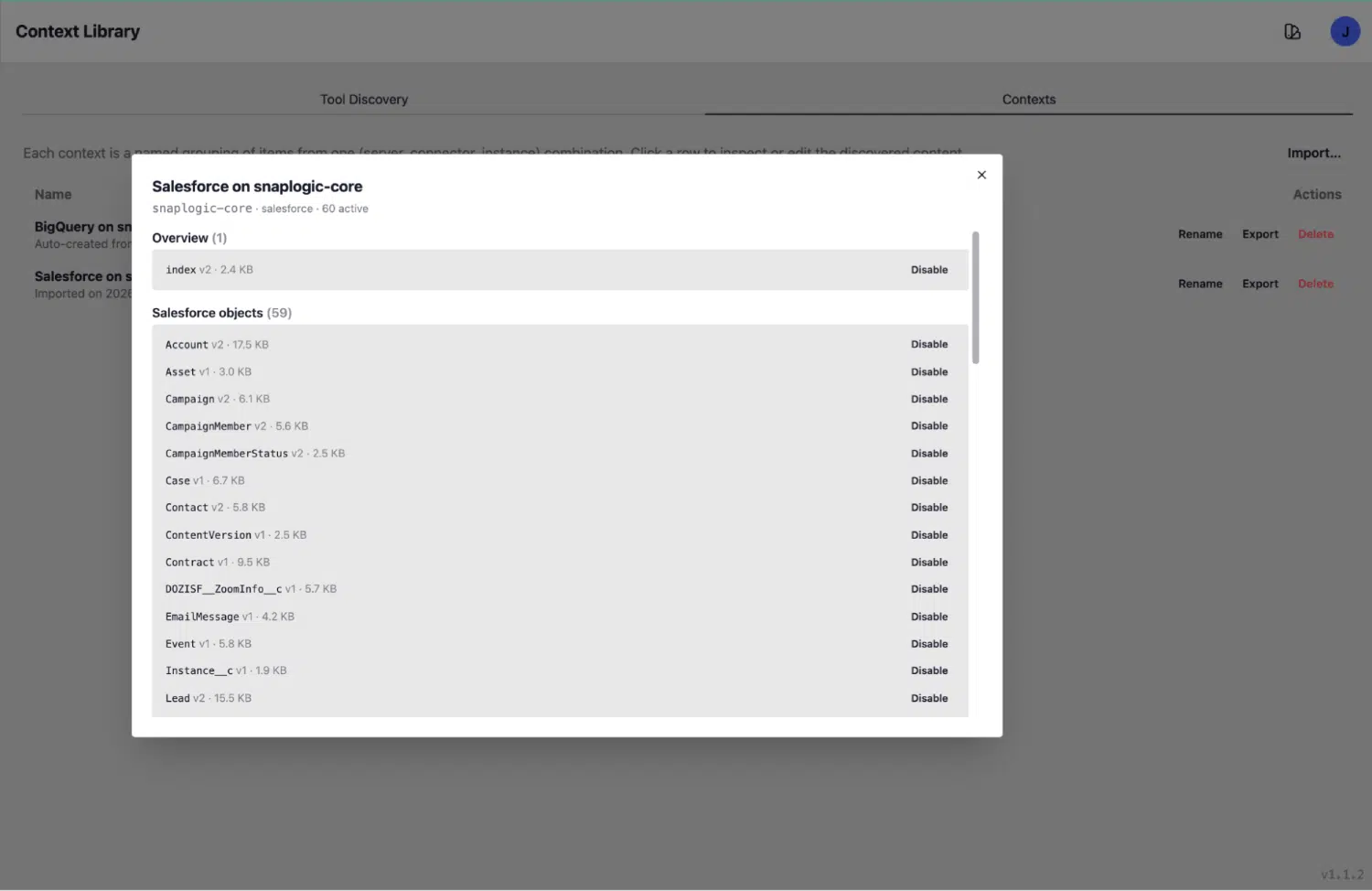
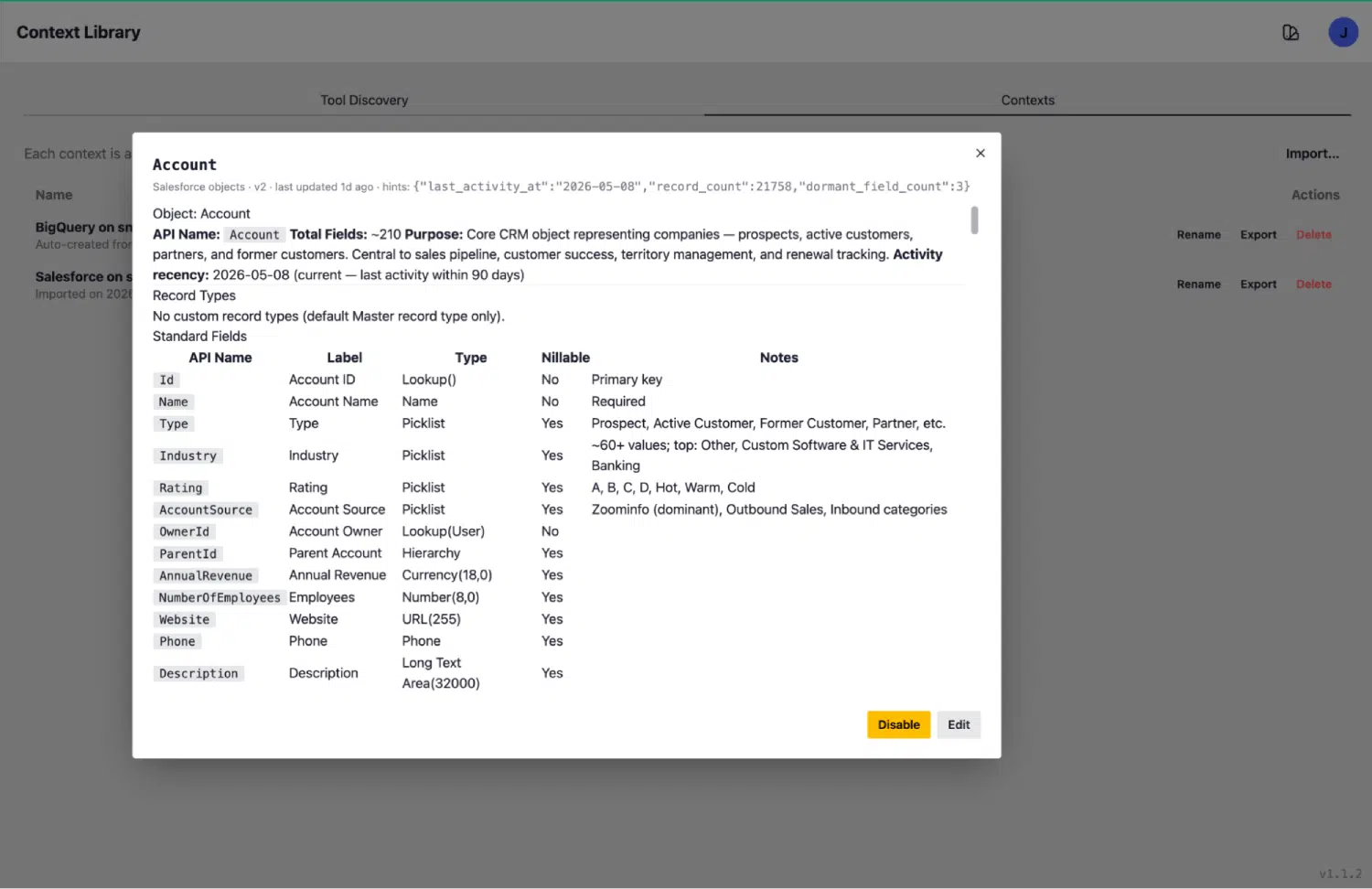
Nehmen wir das „Account“-Objekt als konkretes Beispiel. Sein Kontexteintrag enthält:
- API-Name und -Typ: Account, sf_object
- Zusammenfassung des Zwecks: „Zentrales CRM-Objekt, das Unternehmen, Interessenten, aktive Kunden, ehemalige Kunden, Partner usw. repräsentiert.“
- Anzahl der Datensätze: 21.168
- Aktualität der Aktivität: letzte Aktivität am 22.05.2026, innerhalb der letzten 90 Tage (dieses Objekt ist aktiv und wird genutzt)
- Gesamtzahl der Felder: 210 Felder, aufgelistet mit Bezeichnungen, API-Namen, Datentypen, Null-Flags und für Menschen lesbaren Anmerkungen
- Ruhezustandssignale: werden gegebenenfalls angezeigt, damit der Bearbeiter weiß, welche Objekte belegt sind und welche praktisch aufgegeben wurden
Der BigQuery-Kontext funktioniert auf dieselbe Weise. Die Introspektion des BigQuery-Konnektors liefert Kontexteinträge auf Datensatz- und Tabellenebene: Schemadefinitionen, Spaltenbeschreibungen, Partitionsschlüssel, Zeilenanzahlen und Signale zur Datenaktualität. Ein Agent, der fragt: „Was enthält die Tabelle ‚pipeline_events‘?“, erhält von der Bibliothek eine strukturierte Antwort, die auf dem aktuellen Schemawissen basiert.
Die Genauigkeit auf Feldebene entscheidet darüber, ob eine Abfrage erfolgreich ist oder stillschweigend falsche Ergebnisse liefert. In einer Produktionsumgebung ist dieser Unterschied entscheidend.
Richtlinien für Tools: Kontextnutzung verpflichtend machen
Ein genauer Kontext ist eine Voraussetzung. Eine weitere ist, sicherzustellen, dass der Agent diesen vor jedem Tool-Aufruf liest. Die Registerkarte „Tool-Richtlinien“ in Jean-Paul bildet die Durchsetzungsebene, die beide Aspekte miteinander verbindet.
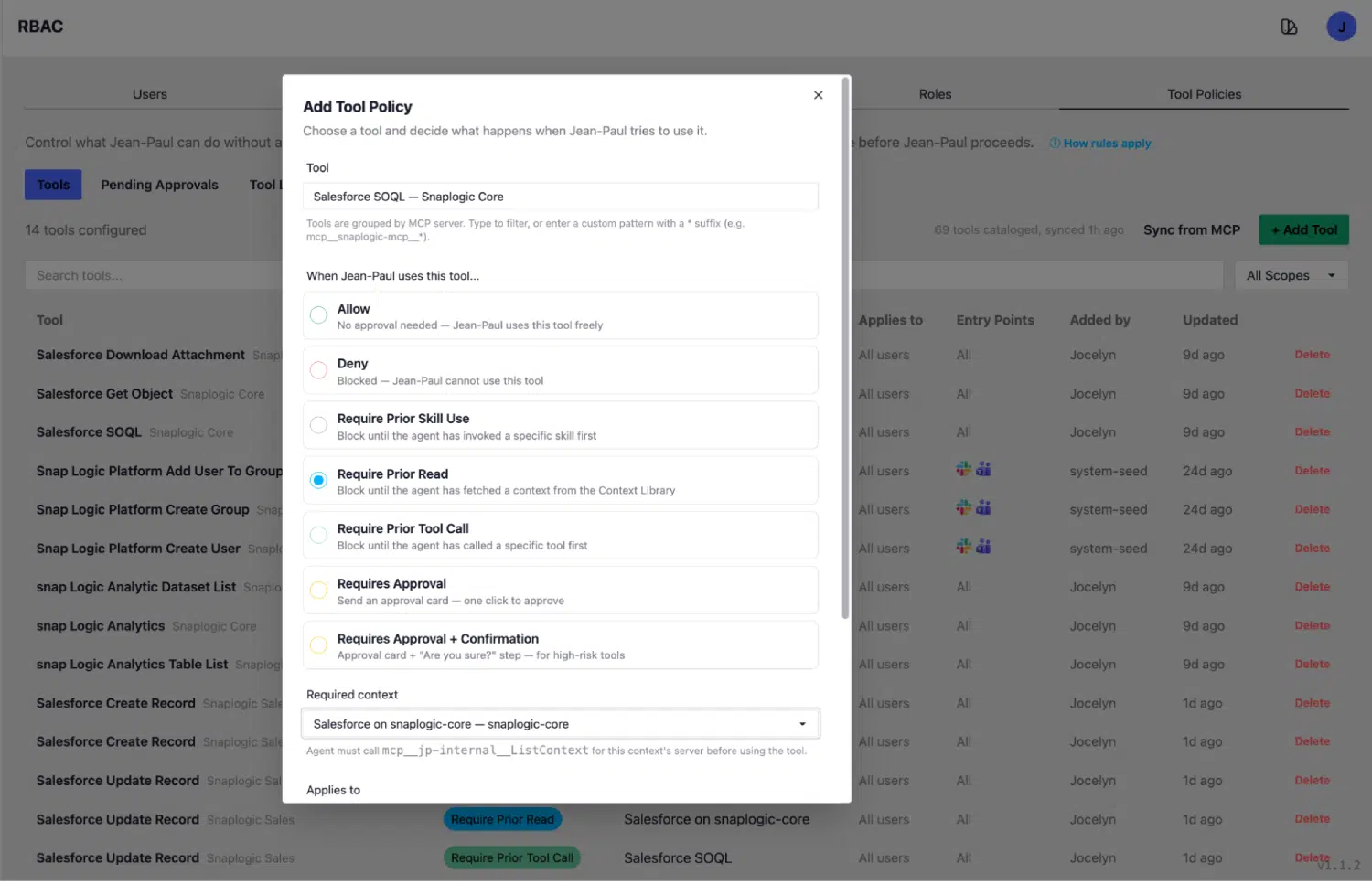
Jedes auf der SnapLogic-Plattform registrierte Tool verfügt über eine Richtlinie. Die wichtigsten Richtlinientypen erfordern:
- Bestätigung: Ein Mensch muss die Aktion bestätigen, bevor das Tool sie ausführt. Wird für Schreibvorgänge, irreversible Aktionen und alle Vorgänge mit realen Konsequenzen verwendet.
- Vorheriges Lesen: Der Agent muss einen Kontexteintrag aus der Kontextbibliothek abrufen, bevor dieses Tool ausgeführt werden kann. Die Ausführung hängt von diesem Lesevorgang ab. Diese Richtlinie sorgt dafür, dass Abfragen schemageführt erfolgen.
- Vorheriger Tool-Aufruf: Der Agent muss ein bestimmtes vorausgesetztes Tool aufrufen, bevor dieses Tool ausgeführt werden kann. Die Ausführung hängt von diesem vorherigen Aufruf ab.
Das klassische Beispiel: SalesforceSOQL verfügt über eine Richtlinie namens „Require Prior Read“, die vorschreibt, dass zunächst ein Aufruf von `GetContext(sf_object)` erfolgen muss. Der Agent kann keine SOQL-Abfrage ausführen, ohne zuvor den entsprechenden Objektkontext aus der Bibliothek gelesen zu haben. Die Richtlinie fungiert als Sperre.
Das gleiche Muster gilt für BigQuery-Abfragen, die Suche nach Personalrichtlinien, das Nachschlagen von Besprechungsprotokollen und alle Tools, die genaue Kenntnisse des Schemas erfordern, um ordnungsgemäß zu funktionieren. Derzeit sind sechzehn Richtlinien konfiguriert und werden in allen Konnektorbereichen angewendet.
Sobald die Tool-Richtlinien eingerichtet sind, ruft der Agent jedes Mal „GetContext“ und anschließend „SalesforceSOQL“ auf – immer in dieser Reihenfolge. Schema-Drift, veraltete Objekte, die Komplexität mehrerer Organisationen: All dies lässt sich bewältigen, wenn der Agent strukturell dazu verpflichtet ist, vor dem Handeln die aktuellen Informationen abzurufen. Wenn man die richtige Durchsetzungsschicht aufbaut, ergeben sich die entsprechenden Aufforderungen von selbst.
Die Kontextbibliothek auf dem neuesten Stand halten
Unternehmensschemata entwickeln sich ständig weiter. Felder werden umbenannt. Objekte werden veraltet. Neue Tabellen kommen hinzu. Die Anzahl der Datensätze ändert sich. Eine Kontextbibliothek muss den aktuellen Zustand jedes verbundenen Systems widerspiegeln und automatisch aktualisiert werden, sobald sich diese Systeme ändern.
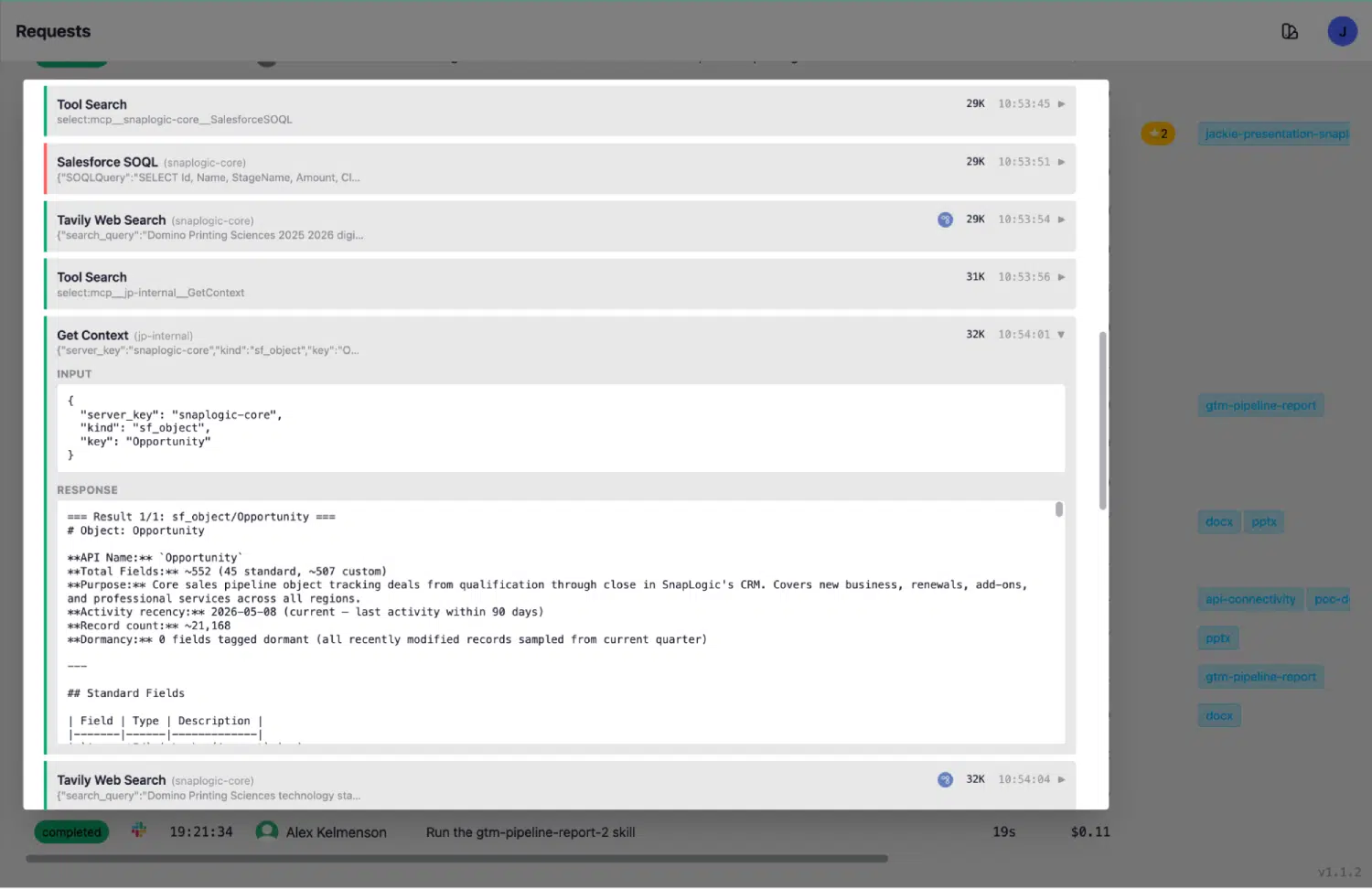
Die Context Library löst dieses Problem durch eine fortlaufende Neu-Introspektion. Jeder Kontexteintrag enthält einen Zeitstempel für die „letzte Erkennung“. Über die Schaltfläche „Discover“ wird die vollständige Introspektion auf Abruf erneut für den Live-Konnektor durchgeführt. Durch die geplante Neu-Erkennung bleibt die Bibliothek ohne manuelles Eingreifen stets auf dem neuesten Stand.
Das Anforderungsprotokoll ist der Prüfpfad für jede Aktion eines Agenten. Wenn ein Agent eine Salesforce-Abfrage ausführt, zeigt das Protokoll den gesamten Ablauf an: „ToolSearch“ zum Auffinden des richtigen Kontextschlüssels, „GetContext“, das eine Live-Antwort mit der aktuellen Datensatzanzahl und dem Datum der letzten Aktivität zurückgibt, und schließlich „SalesforceSOQL“, das auf der Grundlage genauer, aktueller Schema-Informationen ausgeführt wird.
Der Kontext, den der Agent ausliest, spiegelt den aktuellen Zustand des Systems wider. Genau das macht Live-Bereitstellungen in Unternehmen auf der SnapLogic-Plattform so grundlegend anders: Die Informationen des Agenten über die verbundenen Systeme bleiben automatisch auf dem neuesten Stand, ohne dass jedes Mal, wenn ein Salesforce-Administrator ein Feld hinzufügt, ein Mitarbeiter die Dokumentation aktualisieren muss.
Wie das in der Praxis aussieht
Datenumgebungen in Unternehmen können unübersichtlich sein. Systeme ändern sich, die Anzahl der Schnittstellen nimmt zu, und Unternehmen wachsen schneller, als die Dokumentation Schritt halten kann. Die Context Library wurde entwickelt, um diese Unübersichtlichkeit zu bewältigen, ohne dass jedes Mal, wenn sich etwas ändert, menschliches Eingreifen erforderlich ist. So funktioniert sie in den Szenarien, mit denen Daten- und IT-Teams am häufigsten konfrontiert sind:
- Schema-Drift: Wenn Ihr Salesforce-Administrator Felder umbenennt oder neu strukturiert, wird die Bibliothek beim nächsten Erfassungslauf automatisch aktualisiert. Der Agent greift auf die aktuelle Situation zu und nicht auf eine veraltete Momentaufnahme.
- Vermehrung von Konnektoren: Wenn Salesforce in mehreren Konnektorbereichen (Vertrieb, Kern, Partner) vorhanden ist, erhält jeder Bereich seinen eigenen Erkennungskontext. Der Agent weiß, welches Objekt sich wo befindet, ohne raten zu müssen.
- Umgebungen mit mehreren Organisationen: Separate Kontexteinträge pro Organisation enthalten Datensatzzahlen und Aktivitätssignale, sodass der Agent aktive Produktionssysteme von stillgelegten Altsystemen unterscheiden kann.
- Nachvollziehbarkeit: Jeder gelesene Kontext wird protokolliert, sodass Compliance-Teams einen klaren Überblick darüber erhalten, welche Informationen jeweils die Handlungen der Agenten beeinflusst haben.
All dies verbindet ein einfaches architektonisches Prinzip: KI-Agenten arbeiten auf dem Niveau der Informationen, die ihnen zur Verfügung gestellt werden. Wenn man diese Informationen richtig strukturiert und auf dem neuesten Stand hält, verfügt das Modell über alles, was es braucht, um wirklich nützlich zu sein.
Die Context Library ist ab heute in Jean-Paul verfügbar und wird auf der SnapLogic-Plattform in der Produktion eingesetzt – für Salesforce, BigQuery, Zendesk, Sitzungsprotokolle, Personalrichtlinien und eine stetig wachsende Liste verbundener Systeme.
Frühzugang zu Jean-Paul beantragen
Jean-Paul, der Enterprise-KI-Agent von SnapLogic, nimmt ab sofort ausgewählte Kunden für den Early-Access-Zugang auf. Wenn Ihr Unternehmen bereit ist, den Schritt von der Demo zur Live-Bereitstellung zu wagen, würden wir uns gerne mit Ihnen austauschen.