





Les systèmes ETL (extraction, transformation et chargement) sont utilisés depuis plus d‘une décennie. Ils collectent des données provenant de diverses sources, les normalisent et les stockent dans un référentiel central unique. Cependant, des études montrent que neuf décideurs informatiques sur dix affirment que les systèmes existants les empêchent d‘exploiter les technologies numériques dont ils ont besoin pour devenir plus efficaces et développer leurs activités.
Les études montrent que les entreprises modernes peuvent avoir jusqu‘à 400 applications, y compris celles qui génèrent des quantités massives de données comme les médias sociaux ou les plateformes mobiles. La nécessité de gérer en temps réel des volumes de données aussi importants et croissants, dans des formats variés et des charges de travail changeantes, s‘impose aujourd‘hui. On observe donc une évolution vers des processus ETL modernes qui suppriment les intégrations point à point de données disparates et offrent une évolutivité et des performances élevées. Alors que 72 % de l‘intégration des applications se faisait sur site il y a quelques années, ce chiffre n‘est plus que de 42 % aujourd‘hui, selon des études, ce qui indique une adoption croissante du traitement ETL basé sur le site cloud.
Bien que cela soit vrai, de nombreuses organisations sont encore réticentes à l‘idée de s‘éloigner de leur ancienne configuration. Ayant investi beaucoup de temps, d‘efforts et de ressources dans la mise en place de leurs systèmes sur site, le passage à des processus modernes signifie pour ces organisations un changement d‘état d‘esprit et une refonte de l‘ensemble de la chaîne d‘approvisionnement. En outre, selon Gartner, 83 % des projets de migration de données échouent ou dépassent leur budget et leur calendrier. Cela est principalement dû à la complexité de la migration proprement dite :
- Libérer les données de l‘entreprise emprisonnées dans des enregistrements anciens
- Validation des données
- Transfert du code ETL, y compris la restructuration ou l‘optimisation
- S‘adapter à la nouvelle plateforme
- Identifier les bons outils à utiliser
- Mise en place d‘une synchronisation des données entre les systèmes ou les applications
- Veiller à ce que la communication avec d‘autres applications dépendantes de l‘ancien système ne soit pas affectée
Dites bonjour à SNAPAHEAD
Afin d‘aider les entreprises à passer plus facilement et plus rapidement de l‘ETL traditionnel à l‘ETL moderne, Agilisium s‘est associé à SnapLogic pour développer SNAPAHEAD. SNAPAHEAD est un accélérateur de migration pour l‘intégration de données de l‘ancien système vers cloud , principalement utilisé avec AWS plateforme. Avec SnapLogic comme outil d‘intégration de données plateforme, les entreprises peuvent rapidement et facilement connecter l‘ensemble de leur écosystème d‘applications, d‘API, de bases de données, de big data, d‘entrepôts de données, de machines et d‘appareils avec d‘autres services distants afin d‘établir leur base de données cloud et d‘en tirer des informations commerciales.
SNAPAHEAD automatise la conversion du code ETL existant en pipelines compatibles avec SnapLogic, en un seul clic. Agilisium utilise une combinaison de lift-and-shift et de refactoring pour migrer tous les pipelines ETL existants vers SnapLogic. SNAPAHEAD réduit l‘effort de mise en œuvre de 25 % et peut facilement entraîner jusqu‘à 30 % d‘économies.
Comment fonctionne SNAPAHEAD ?
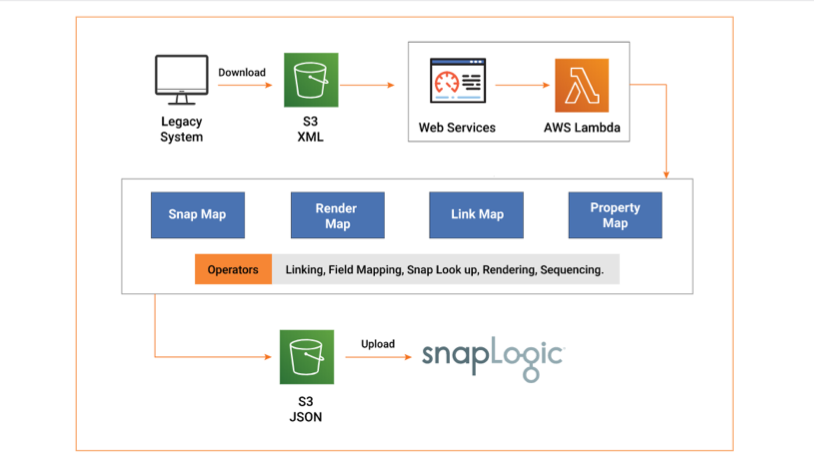
SNAPAHEAD prend comme entrée le fichier XML généré par l‘installation patrimoniale. L‘outil comprend le flux de données de la source à la cible, en décodant chaque transformation de données. SNAPAHEAD mappe ensuite les transformations aux Snaps correspondants dans SnapLogic, qui sont des connecteurs intelligents préconstruits qui réalisent l‘intégration proprement dite. Les Snaps, une fois assemblés, constituent le pipeline de données final.
L‘architecture de SNAPAHEAD peut être classée en quatre grandes catégories :
- Snap Map: Cette section contient une structure de type dictionnaire qui établit une correspondance entre la logique ETL et les Snaps dans SnapLogic. Elle permet de réunir les deux éléments de fonctionnalité qui sont logiquement équivalents.
- Carte de liaison: Les structures rassemblées par la carte instantanée sont reliées entre elles par la carte de liens. C‘est elle qui détermine les étapes suivantes du pipeline, contrôlant ainsi le flux de données.
- Carte des propriétés: Chaque code ETL existant est accompagné de son propre ensemble de configurations et de caractéristiques ou de champs tels que l‘emplacement de la table ou les propriétés de la matrice, pour n‘en citer que quelques-uns. Le Property Mapper identifie ces paramètres et les définit dans les Snaps équivalents.
- Carte de rendu: Les Snaps qui sont livrés à SnapLogic peuvent être considérés comme une chaîne de fonctions, formant le pipeline. L‘interface utilisateur comprend une disposition bien définie pour définir la manière dont ce pipeline doit être placé sur l‘écran. La carte de rendu automatise cet aspect pour les pipelines rendus à l‘aide d‘outils.
SNAPAHEAD utilise des buckets de stockage Amazon S3 pour stocker des fichiers avec du code hérité en entrée et des pipelines SnapLogic en sortie. AWS Lambda, une solution informatique événementielle et sans serveur plateforme, constitue l‘épine dorsale de l‘accélérateur. AWS Lambda s‘occupe des processus de calcul, de l‘exécution du code en réponse aux événements et de la gestion automatique des ressources en fonction des besoins.
Démarrer avec SNAPAHEAD
Du point de vue de l‘utilisateur, le déploiement de SNAPAHEAD est simple. L‘utilisateur interagit avec SNAPAHEAD via une interface utilisateur (UI) intuitive, et un pipeline compatible avec SnapLogic est généré par l‘outil.
Regardez la courte vidéo de démonstration ci-dessous pour savoir comment démarrer avec SNAPAHEAD :
Comme vous pouvez le voir dans la vidéo, le mappage d‘héritage vers Snaps peut être réalisé en quelques étapes simples :
Étape 1 : Accéder au bucket S3 à partir de l‘interface utilisateur SnapLogic
Étape 2 : Télécharger le fichier XML avec les mappages des codes ETL hérités dans le seau S3
Étape 3 : Une fois le fichier téléchargé, cliquez sur SNAPAHEAD.
Étape 4 : Lorsque l‘utilisateur clique sur SNAPAHEAD, le déclencheur événementiel dans AWS Lambda est notifié. AWS Lambda déclenche alors automatiquement l‘accélérateur SNAPAHEAD
Étape 5 : L‘accélérateur lit le fichier et effectue les conversions de pipeline.
Étape 6 : Les Snaps de sortie sont rendus dans un fichier JSON
Étape 7 : SNAPAHEAD renvoie le fichier JSON vers le seau S3.
Étape 8 : Télécharger le fichier JSON
Étape 9 : Charger le fichier JSON dans SnapLogic. Le pipeline de données SnapLogic est prêt pour d‘autres actions.
Selon Gartner, au moins 65 % des grandes organisations auront mis en œuvre une intégration hybride plateforme pour alimenter leur transformation numérique d‘ici 2022. SnapLogic est votre première étape !
Obtenir. Set. SNAPAHEAD !



