





Legacy ETL (extract, transform, and load) systems have been in use for over a decade now, gathering data from a range of sources, standardizing it, and storing it in a single central repository. However, studies note that nine out of ten IT decision-makers claim legacy systems are preventing them from harnessing the digital technologies they need to become more efficient and grow their business.
Research shows that modern enterprises can have as many as 400 applications, including ones generating massive amounts of data like social media or mobile platforms. The need of the hour is to manage such large and growing volumes of data, in varied formats and changing workloads, in real-time. Thus, there is a shift toward modern ETL processes that do away with point-to-point integrations of disparate data and offer high scalability and performance. In contrast to 72 percent of application integration being done on-prem several years ago, the number stands at just 42 percent today, according to studies, indicating increasing adoption of cloud-based ETL processing.
Although this may be true, many organizations are still reluctant to move away from their legacy setup. Having invested considerable time, effort, and resources in setting up their on-premises systems, a shift to modern processes for these organizations means a change in mindset and re-working the complete supply chain. Further, according to Gartner, 83% of data migration projects either fail or exceed their budgets and schedules. This is primarily due to the complexities involved in performing the actual migration, which include:
- Relieving trapped company data from legacy records
- Data validation
- Transfer of ETL code, including restructuring or optimization
- Adapting to the new platform
- Identifying the right tools to use
- Establishing data synchronization between systems or applications
- Ensuring that communication with other legacy-dependent applications is not affected
Say Hello to SNAPAHEAD
In order to help organizations make the transition from legacy to modern ETL easier and faster, Agilisium joined forces with SnapLogic to develop SNAPAHEAD. SNAPAHEAD is a migration accelerator for legacy to cloud data integration, predominantly used with the AWS platform. With SnapLogic as the data integration platform, organizations can quickly and easily connect their entire ecosystem of applications, APIs, databases, big data, data warehouses, machines, and devices with other remote services to establish their cloud data foundation and derive business insights.
SNAPAHEAD automates the conversion of legacy ETL code to SnapLogic compliant pipelines, with a single click. Agilisium uses a combination of lift-and-shift and refactoring to migrate all legacy ETL pipelines to SnapLogic. SNAPAHEAD reduces implementation effort by 25% and can easily result in up to 30% cost savings.
How does SNAPAHEAD work
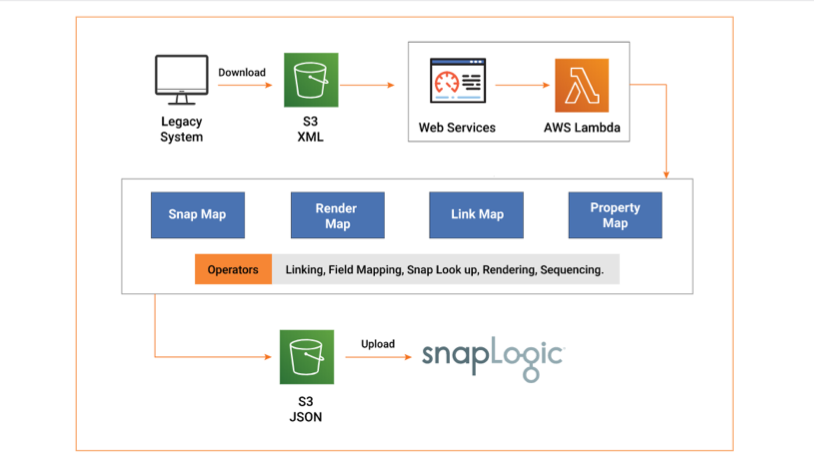
SNAPAHEAD takes the XML file generated by the legacy setup as its input. The tool understands the data flow from source to target, decoding every data transformation. SNAPAHEAD then maps the transformations to the corresponding Snaps in SnapLogic, which are pre-built intelligent connectors that perform the actual integration. The Snaps, when put together, make the final data pipeline.
The architecture behind SNAPAHEAD can be categorized into four broad sections:
- Snap Map: This section contains a dictionary-like structure that maps ETL logic to Snaps in SnapLogic. It performs the task of bringing together the two pieces of functionality that are logically equivalent.
- Link Map: The structures brought together by the Snap Map are linked together by the Link Map. This is what decides the consequent stages of the pipeline, thereby controlling the data flow.
- Property Map: Every legacy ETL code comes with its own set of configurations and features or fields like table location or matrix properties, to name a few. The Property Mapper identifies such parameters and defines them in the equivalent Snaps.
- Render Map: The Snaps that are delivered to SnapLogic can be viewed as a chain of functions, forming the pipeline. The UI includes a well-defined arrangement for defining how this pipeline is to be placed on the screen. The Render Map automates this look for tool-rendered pipelines.
SNAPAHEAD uses Amazon S3 storage buckets to store files with input legacy code and output SnapLogic pipelines. AWS Lambda, an event-driven and serverless computing platform, forms the backbone of the accelerator. AWS Lambda takes care of computing processes, running code in response to events, and automatically managing resources according to requirements.
Getting started with SNAPAHEAD
From a user perspective, deploying SNAPAHEAD is straightforward. The user interacts with SNAPAHEAD via an intuitive User Interface (UI), and a SnapLogic-compliant pipeline is generated by the tool.
Watch the short demo video below to learn how to get started with SNAPAHEAD:
As you can see from the video, the legacy to Snaps mapping can be performed in few simple steps:
Step 1: Access the S3 bucket from the SnapLogic UI
Step 2: Upload the XML file with legacy ETL code mappings into the S3 bucket
Step 3: Once the file is uploaded, click on SNAPAHEAD
Step 4: When the user clicks on SNAPAHEAD, the event-based trigger in AWS Lambda is notified. AWS Lambda then automatically triggers the SNAPAHEAD accelerator
Step 5: The accelerator reads the file and performs pipeline conversions
Step 6: The output Snaps are rendered in a JSON file
Step 7: SNAPAHEAD sends the JSON file back to the S3 bucket
Step 8: Download the JSON file
Step 9: Upload the JSON file into SnapLogic. The SnapLogic data pipeline is ready for further action
According to Gartner, at least 65% of large organizations will have implemented a hybrid integration platform to power their digital transformation by 2022. SnapLogic is your first step!
Get. Set. SNAPAHEAD!



