





Dans mon précédent article, j'ai décrit les différentes approches et modèles à prendre en compte lors de l'ingestion de données à partir d'une source de données relationnelles dans un lac de données en ruche basé sur Hadoop. Dans ce billet, je décrirai une approche pratique sur la façon d'utiliser ces modèles avec la plateforme d'intégration élastique SnapLogic sans avoir besoin d'écrire du code. Les modèles de couche d'ingestion de big data décrits ici prennent en compte toutes les considérations de conception et les meilleures pratiques pour une ingestion efficace des données dans le lac de données en ruche Hadoop. Ces modèles sont utilisés aujourd'hui par de nombreuses organisations d'entreprise pour déplacer de grandes quantités de données, en particulier à mesure qu'elles accélèrent leurs initiatives de transformation numérique et s'efforcent de comprendre ce dont les clients ont besoin.
Considérons un scénario dans lequel vous voulez ingérer des données d‘une base de données relationnelle (comme Oracle, mySQl, SQl Server, etc.) dans Hive. Disons que nous voulons utiliser AVRO comme format de données pour les tables Hive. Voyons maintenant comment ce modèle vous permet de générer automatiquement tous les schémas AVRO requis et les tables Hive.
Les étapes clés associées à ce modèle sont les suivantes :
- Fournir la possibilité de sélectionner un type de base de données comme Oracle, mySQl, SQlServer, etc. Configurer ensuite les informations de connexion à la base de données appropriées (nom d‘utilisateur, mot de passe, hôte, port, nom de la base de données, etc.)
- Fournir la possibilité de sélectionner une table, un ensemble de tables ou toutes les tables de la base de données source. Par exemple, nous voulons déplacer toutes les tables dont le nom commence par "commandes" ou contient "commandes".
- Pour chaque table sélectionnée dans la base de données relationnelle source :
- Interroger les métadonnées de la base de données relationnelle source pour obtenir des informations sur les colonnes des tables, les types de données des colonnes, l‘ordre des colonnes et les clés primaires/étrangères.
- Générer le schéma AVRO pour une table. Traiter automatiquement tous les mappages et transformations nécessaires pour la colonne (noms de colonnes, clés primaires et types de données) et générer le schéma AVRO.
- Générer le DDL requis pour la table Hive. Traite automatiquement tous les mappages et transformations requis pour les colonnes et génère le DDL pour la table Hive équivalente.
- Sauvegarder les schémas AVRO et les DDL Hive dans HDFS et d‘autres référentiels cibles.
- Créer la table Hive à l‘aide de la DDL
Le modèle SnapLogic pour générer automatiquement le schéma et le DDL Hive est ci-dessous. Il peut être utilisé dans le cadre de votre flux de données Ingest pour déplacer les données d‘une source de données relationnelles vers Hive.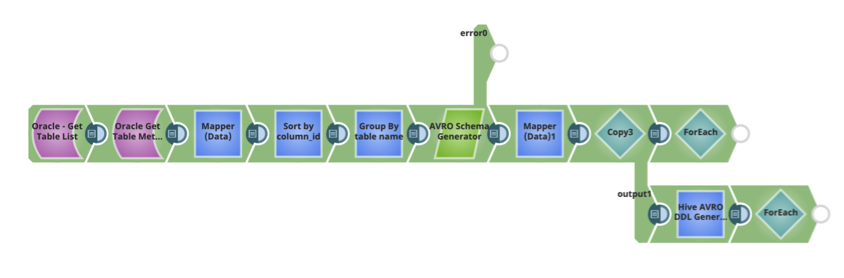
Pour chaque table, les schémas Avro et les DDL des tables Hive sont également stockés dans HDFS. 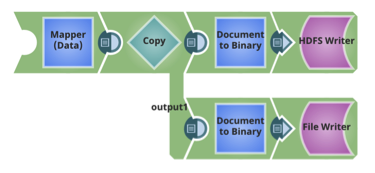
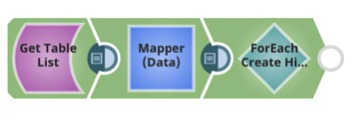
Pour chaque table, créez la table Hive, en utilisant le DDL Hive et le schéma AVRO.
 Les Modèles d‘intégration SnapLogic catalog fournit des pipelines de flux de données d‘intégration préconstruits et réutilisables qui permettent de réutiliser les données et d‘améliorer la productivité.
Les Modèles d‘intégration SnapLogic catalog fournit des pipelines de flux de données d‘intégration préconstruits et réutilisables qui permettent de réutiliser les données et d‘améliorer la productivité.
Dans mon prochain article, je parlerai d‘un autre modèle pratique d‘intégration de données pour l‘ingestion de big data avec SnapLogic sans avoir besoin de coder.
Prochaines étapes :
- Télécharger le livre blanc : Comment construire un lac de données d'entreprise : Considérations importantes avant de se lancer. Vous pouvez également regarder le webinar enregistré et consulter les diapositives sur le blog de SnapLogic.
- Télécharger le livre blanc : Le lac de données va-t-il noyer l‘entrepôt de données ?
- Regardez cette démonstration de SnapReduce et de SnapLogic Hadooplex pour découvrir notre approche "Hadoop for Humans" de l‘intégration des big data.




