





In meinem letzten Beitrag habe ich die verschiedenen Ansätze und Muster beschrieben, die beim Ingesting von Daten aus relationalen Datenquellen in einen Hadoop-basierten Hive Data Lake zu berücksichtigen sind. In diesem Beitrag beschreibe ich einen praktischen Ansatz, wie diese Muster mit der SnapLogic Elastic Integration Platform genutzt werden können, ohne dass dafür Code geschrieben werden muss. Die hier beschriebenen Big Data Ingestion Layer Patterns berücksichtigen alle Designüberlegungen und Best Practices für eine effektive Aufnahme von Daten in den Hadoop Hive Data Lake. Diese Muster werden heute von vielen Unternehmen verwendet, um große Datenmengen zu bewegen, insbesondere wenn sie ihre Initiativen zur digitalen Transformation beschleunigen und daran arbeiten, die Bedürfnisse ihrer Kunden zu verstehen.
Betrachten wir ein Szenario, in dem Sie Daten aus einer relationalen Datenbank (wie Oracle, mySQl, SQl Server usw.) in Hive einlesen möchten. Nehmen wir an, wir möchten AVRO als Datenformat für die Hive-Tabellen verwenden. Schauen wir uns nun an, wie Sie mit diesem Muster alle erforderlichen AVRO-Schemata und die Hive-Tabellen automatisch generieren können.
Die wichtigsten Schritte, die mit diesem Muster verbunden sind, sind die folgenden:
- Bieten Sie die Möglichkeit, einen Datenbanktyp wie Oracle, mySQl, SQlServer usw. auszuwählen. Konfigurieren Sie dann die entsprechenden Datenbankverbindungsinformationen (wie Benutzername, Passwort, Host, Port, Datenbankname usw.)
- Bieten Sie die Möglichkeit, eine Tabelle, eine Gruppe von Tabellen oder alle Tabellen der Quelldatenbank auszuwählen. Wir wollen zum Beispiel alle Tabellen verschieben, die mit "orders" beginnen oder es im Tabellennamen enthalten.
- Für jede aus der relationalen Quelldatenbank ausgewählte Tabelle:
- Abfrage der Metadaten der relationalen Quelldatenbank nach Informationen über Tabellenspalten, Spaltendatentypen, Spaltenreihenfolge und Primär-/Fremdschlüssel.
- Generieren Sie das AVRO-Schema für eine Tabelle. Alle erforderlichen Zuordnungen und Transformationen für die Spalte (Spaltennamen, Primärschlüssel und Datentypen) werden automatisch verarbeitet und das AVRO-Schema generiert.
- Generieren Sie die für die Hive-Tabelle erforderliche DDL. Verarbeiten Sie automatisch alle erforderlichen Zuordnungen und Transformationen für die Spalten und generieren Sie die DDL für die entsprechende Hive-Tabelle.
- Speichern Sie die AVRO-Schemata und die Hive-DDL in HDFS und anderen Ziel-Repositories.
- Erstellen Sie die Hive-Tabelle mit der DDL
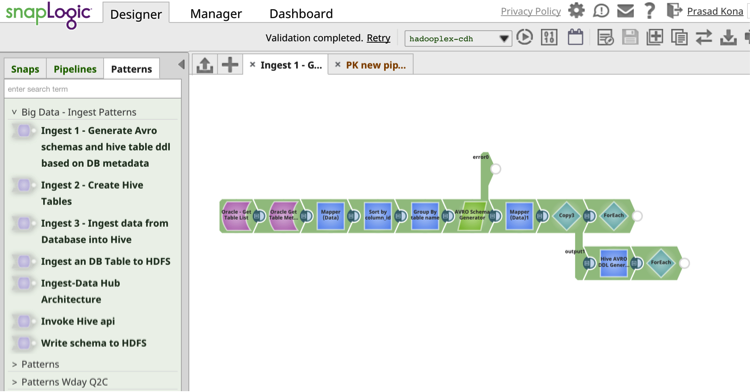
Das SnapLogic-Muster zur automatischen Generierung des Schemas und der Hive-DDL finden Sie unten. Es kann als Teil Ihrer Ingest-Datenflusspipeline verwendet werden, um Daten aus einer Beziehungsdatenquelle in Hive zu übertragen.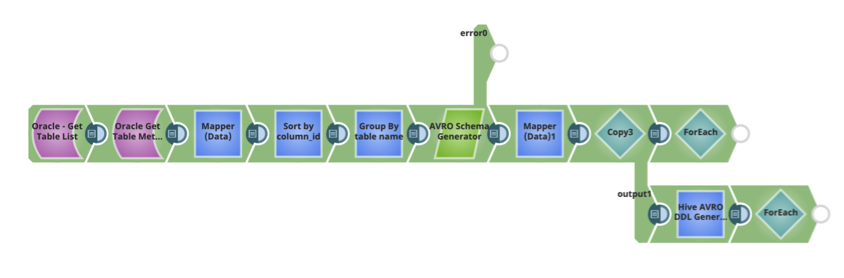
Für jede Tabelle werden Avro-Schemata und Hive-Tabellen-DDLs ebenfalls im HDFS gespeichert. 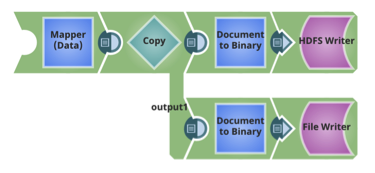
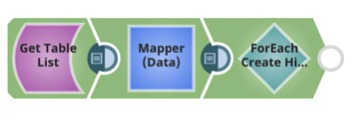
Erstellen Sie für jede Tabelle die Hive-Tabelle unter Verwendung der Hive-DDL und des AVRO-Schemas.
 Die Muster für die SnapLogic-Integration catalog bietet vorgefertigte, wiederverwendbare Integrationsdatenfluss-Pipelines, die eine Wiederverwendbarkeit ermöglichen und die Produktivität steigern.
Die Muster für die SnapLogic-Integration catalog bietet vorgefertigte, wiederverwendbare Integrationsdatenfluss-Pipelines, die eine Wiederverwendbarkeit ermöglichen und die Produktivität steigern.
In meinem nächsten Beitrag werde ich über ein weiteres praktisches Datenintegrationsmuster für Big Data Ingestion mit SnapLogic schreiben, ohne dass Sie dafür programmieren müssen.
Nächste Schritte:
- Laden Sie das Whitepaper herunter: Wie man einen Enterprise Data Lake aufbaut: Wichtige Überlegungen, bevor Sie loslegen. Sie können auch das aufgezeichnete Webinar und die Folien im SnapLogic-Blog ansehen.
- Laden Sie das Whitepaper herunter: Wird der Data Lake das Data Warehouse ertränken?
- Sehen Sie sich diese Demonstration von SnapReduce und SnapLogic Hadooplex an und erfahren Sie mehr über unseren "Hadoop für Menschen"-Ansatz zur Big Data-Integration.






