






Snowpark è un insieme di librerie e runtime della piattaforma dati Snowflake cloud che consentono agli sviluppatori di elaborare in modo sicuro codice Python, Java o Scala non SQL, senza spostamento di dati nel motore di elaborazione elastico di Snowflake.
Ciò consente di interrogare ed elaborare i dati, su scala, in Snowflake. Le operazioni di Snowpark possono essere eseguite passivamente sul server, alleggerendo i costi di gestione e garantendo prestazioni affidabili.
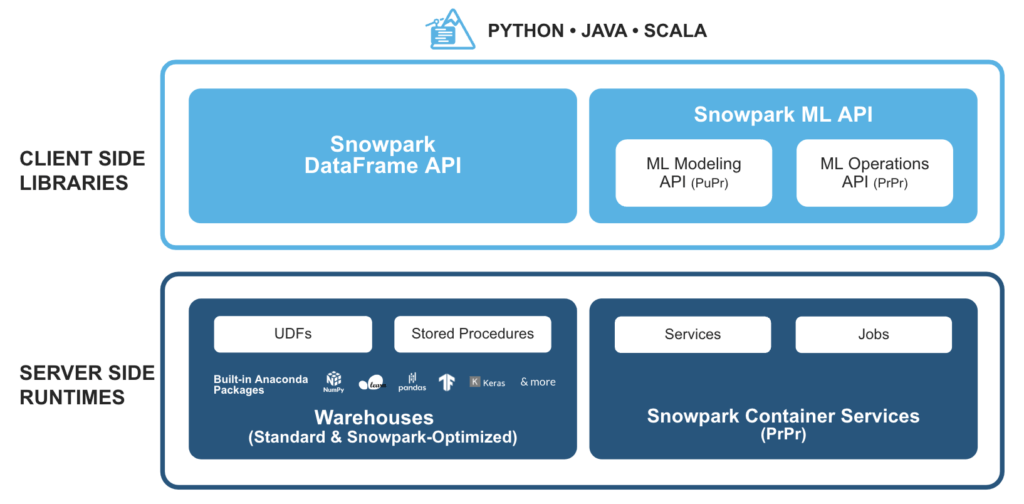
Come funziona Snowpark con SnapLogic?
La piattaforma di integrazione intelligente (IIP) di SnapLogic offre un modo semplice per sfruttare le funzioni definite dall'utente (UDF) personalizzate e costruite dagli sviluppatori per Snowpark. Inoltre, lo Snowflake Snap Pack viene utilizzato per implementare casi d'uso avanzati di machine learning e data engineering con Snowflake.
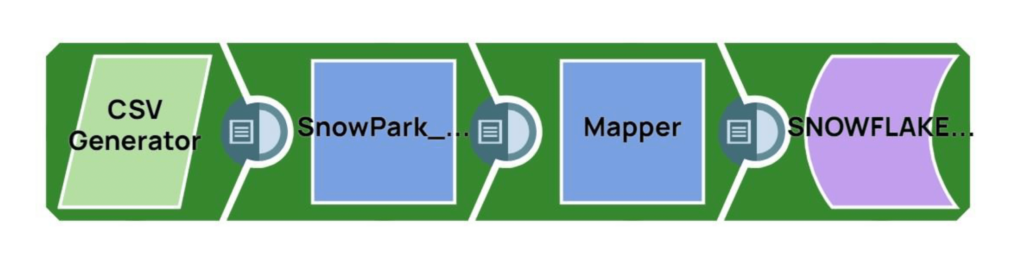
Esempio di integrazione tra Snowpark e SnapLogic
Esaminiamo i passaggi per invocare le librerie di Snowpark usando lo Snap Remote Python Script in SnapLogic:
Passo 1: leggere le righe di esempio da un'origine (un generatore CSV in questo caso)
Passo 2: utilizzare lo snap script Python remoto per:
- Invocare le librerie Snowpark Python
- Eseguire ulteriori operazioni sulle righe di dati di origine
Passo 3: caricare i dati elaborati in una tabella Snowflake di destinazione
Configurazioni SnapLogic IIP
Sul lato SnapLogic, è necessario installare il Remote Python Executor (RPE) utilizzando i seguenti passaggi:
Passi 1 e 2: i primi due passi per l'installazione di RPE sono spiegati in dettaglio nella documentazione di SnapLogic IIP. La porta di accesso predefinita di RPE è la 5301, quindi la "comunicazione in entrata" deve essere abilitata su questa porta.
- Se l'istanza Snaplex è un Groundplex, l'RPE può essere installato nello stesso nodo Snaplex.
- Se l'istanza Snaplex è un Cloudplex, l'RPE può essere installato come qualsiasi altro nodo remoto accessibile da Snaplex.
Fase 3: Il passo successivo richiede l'installazione del pacchetto RPE personalizzato seguendo i passi della sezione "immagine personalizzata" della documentazione. Per installare le librerie Snowpark sul nodo, aggiornare il file requirements.txt come indicato di seguito:
requisiti.txtsnaplogicnumpy==1.22.1snowflake-snowpark-pythonsnowflake-snowpark-python[pandas]
Nel nostro esempio, l'istanza Snaplex è un Cloudplex e il nodo remoto è una macchina virtuale Ubuntu di Azure. Il pacchetto RPE personalizzato è installato sulla macchina virtuale Azure.
Configurazioni a fiocco di neve
Sul lato Snowflake, dobbiamo impostare le configurazioni e creare una tabella di destinazione.
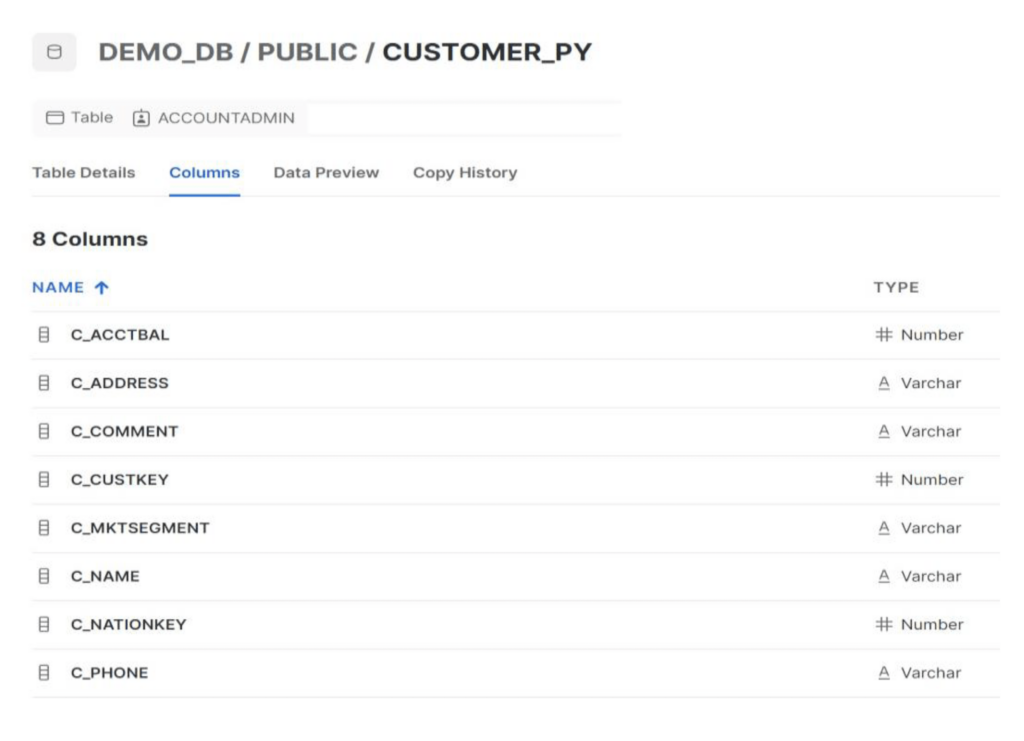
Passo 1: aggiornare le "politiche di rete" di Snowflake per consentire i nodi SnapLogic e RPE. Per questo esempio, utilizzeremo la tabella CUSTOMER_PY nello schema Public.
Passo 2: creare l'account Snowflake in SnapLogic con i parametri richiesti. L'account utilizzato nel nostro esempio è un account Snowflake S3 Database.
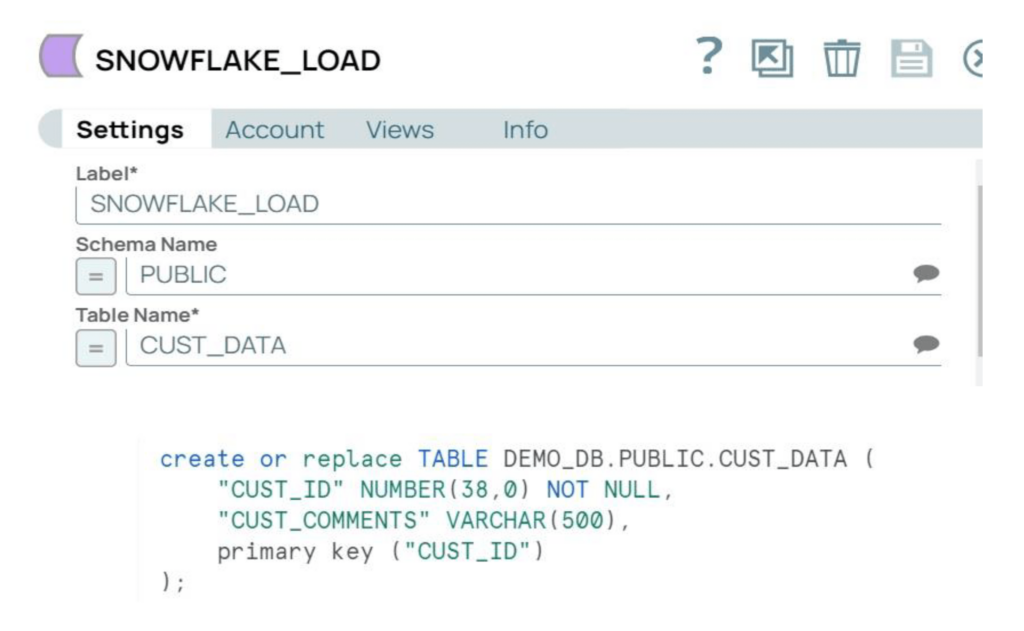
Flusso della pipeline SnapLogic (Remote_Python_Snowpark_Sample)
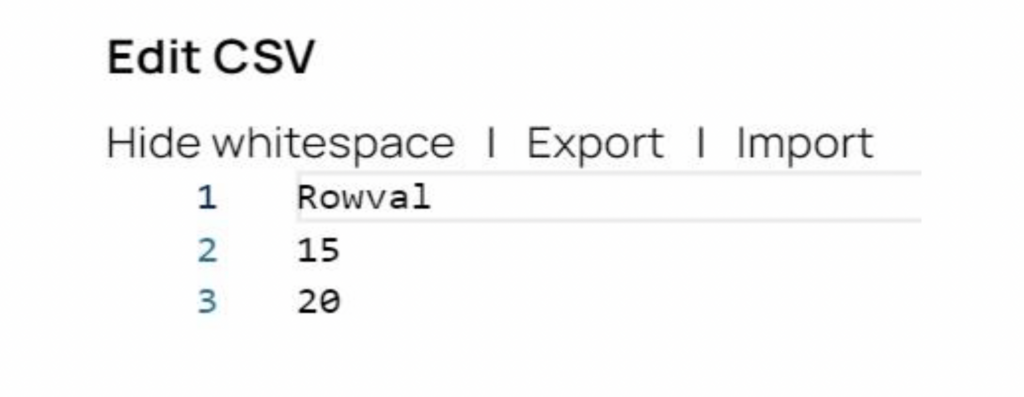
Fase 1: il generatore CSV Snap genera i dati di origine. Per il nostro esempio, ci sono due record di origine, con i valori 15 e 20.
Fase 2: lo snap script Python remotoesegue il codice Python per chiamare le librerie Python di Snowpark ed eseguire ulteriori operazioni sulle righe di dati di origine. Si veda lo snippet del codice Python qui sotto:

Il codice Python esegue le seguenti operazioni:
- Costruire Snowpark DataFrames per recuperare i dati dalle tabelle Snowflake. Filtrare i record per recuperare i dati per la C_NATIONKEY e i dati della colonna C_COMMENT associata per ogni riga di input dall'Upstream Snap (dal CSV Generator).
- Creare ed eseguire una UDF per aggiungere il timestamp corrente ai record correlati nella colonna C_COMMENT. Il nome dell'UDF di esempio è append_data.
- Restituisce i valori di C_NATIONKEY e i record C_COMMENT aggiornati al Mapper Snap a valle.
Passo 3: Convalidare la pipeline SnapLogic e risolvere eventuali errori di convalida.
Passo 4: Eseguire la pipeline e verificare i dati nel database di destinazione su Snowflake.
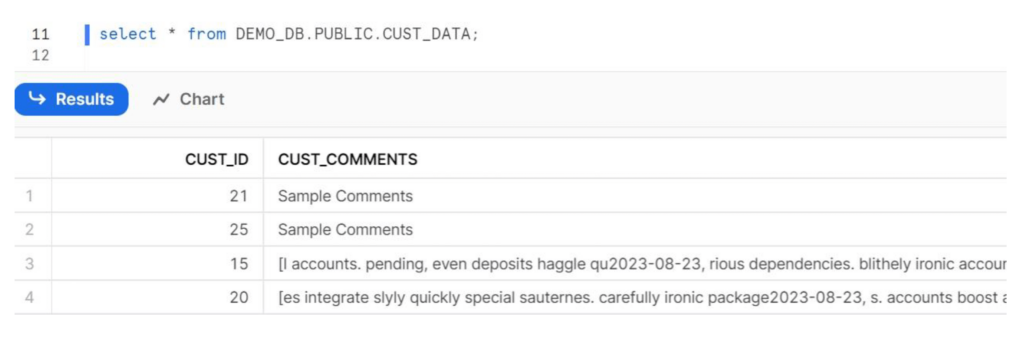
Fase 5: Congratulazioni, l'integrazione tra Snowpark e SnapLogic è avvenuta con successo!
Riferimenti aggiuntivi
Documentazione API di Snowpark
Guida allo sviluppo di Snowpark per Python
SnapLogic Remote Python Script Documentazione di Snap
Esportazione della pipeline SnapLogic
Codice Python per lo script Python remoto Snap







