






Il numero totale di casi confermati di COVID-19, in tutto il mondo, si avvicina a due milioni.
Sul web sono disponibili molte risorse per seguire e comprendere la crescita di questa pandemia, tra cui il gestito dal Centro per la scienza e l'ingegneria dei sistemi della Johns Hopkins University.. Questo cruscotto è supportato da un repository di dati pubblicato su GitHub. I dati di origine sono di alta qualità, ma richiedono una trasformazione strutturale significativa per una visualizzazione efficace. La piattaforma di integrazione intelligente SnapLogic gestisce facilmente le trasformazioni.
In questo blog, illustrerò la costruzione di una pipeline SnapLogic che legge un sottoinsieme di questi dati dal repository GitHub, filtra i dati per alcuni Paesi e li trasforma in modo da poterli visualizzare con un grafico a linee utilizzando la funzione DataViz di SnapLogic. Se volete seguirci, visitate la nostra comunità per scaricare la pipeline illustrata in questo post. In questo blog sono presenti collegamenti alle sezioni pertinenti della documentazione di prodotto di SnapLogic, dove è possibile trovare ulteriori informazioni.
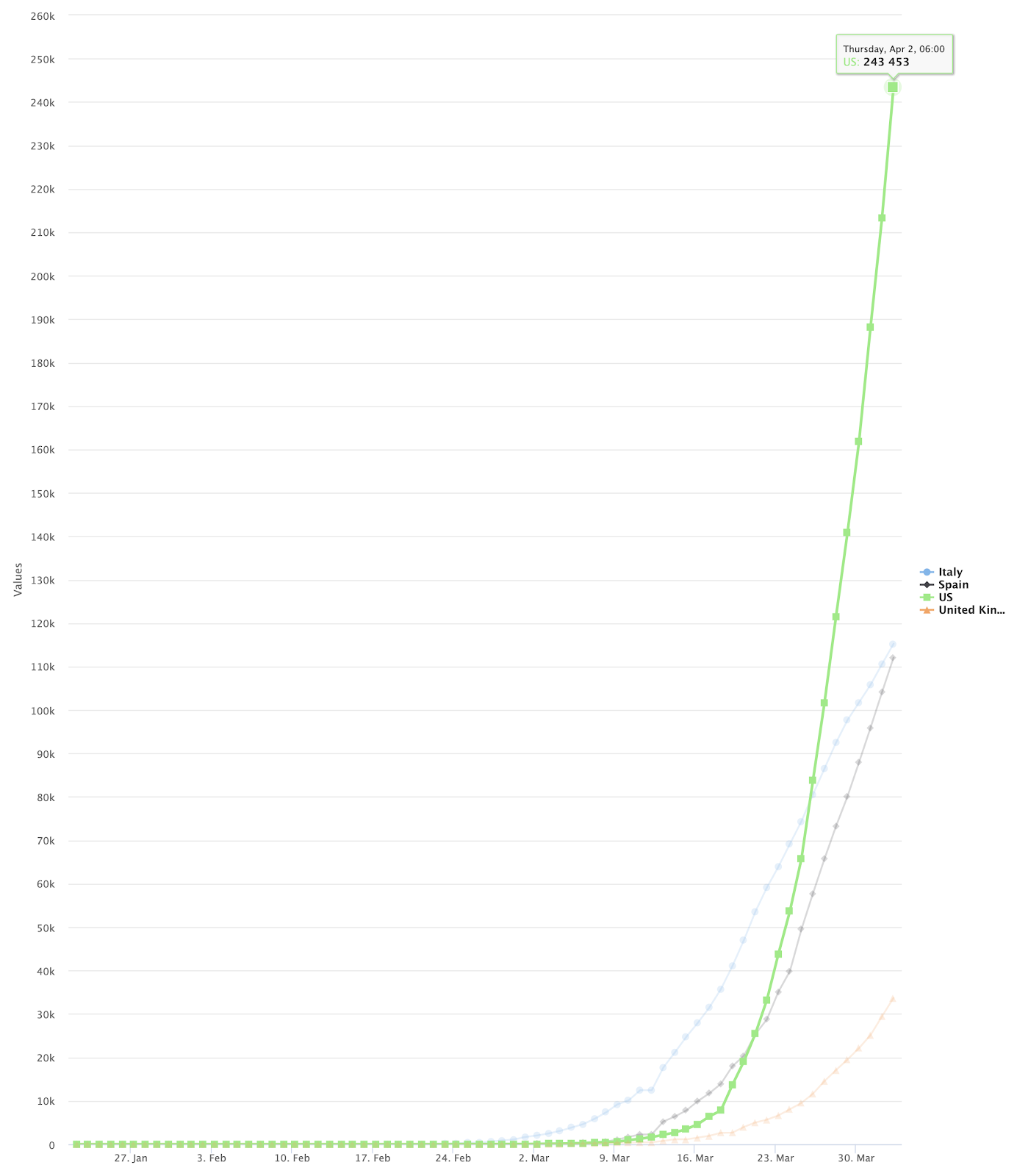
L'output finale sarà simile a questo:
Esaminare i dati di partenza
I nostri dati di partenza sono quelli della JHU time_series_covid19_confirmed_global.csv Questo file contiene i dati delle serie temporali per il totale dei casi confermati di COVID-19, per paese/regione. Questo file contiene le serie temporali dei casi totali di COVID-19 confermati, per paese/regione, e viene aggiornato ogni giorno.
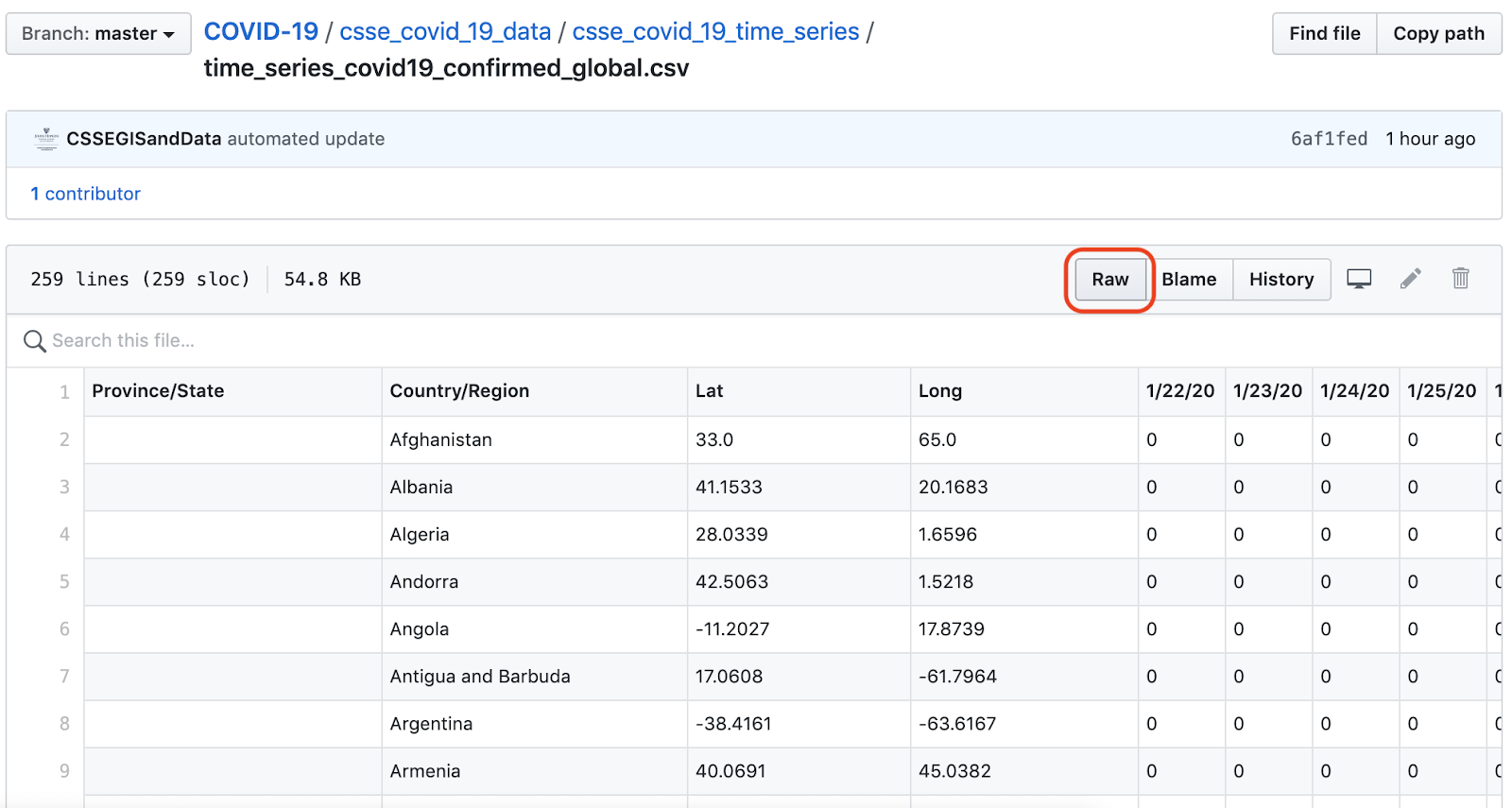
GitHub Raw in questa vista è collegato a all'URL del file CSV grezzo.
Costruire la pipeline
Ecco una panoramica della nostra pipeline SnapLogic per leggere e trasformare questi dati:

Esaminiamo questa pipeline, Snap per Snap.
1. Lettore di file e parser CSV
I primi due snap di questa pipeline mostrano un'accoppiata molto comune:
- A Lettore di file per leggere i dati grezzi, configurato con il file grezzo URL.
- A Parser specifico per il formato dei dati del file, in questo caso CSV.
È importante capire con quanti dati stiamo lavorando. Lo si può fare eseguendo la pipeline e visualizzando le statistiche di esecuzione della pipeline. Statistiche di esecuzione della pipelineche mostra che il parser CSV ha generato 258 documenti di output, uno per ogni riga del file CSV.
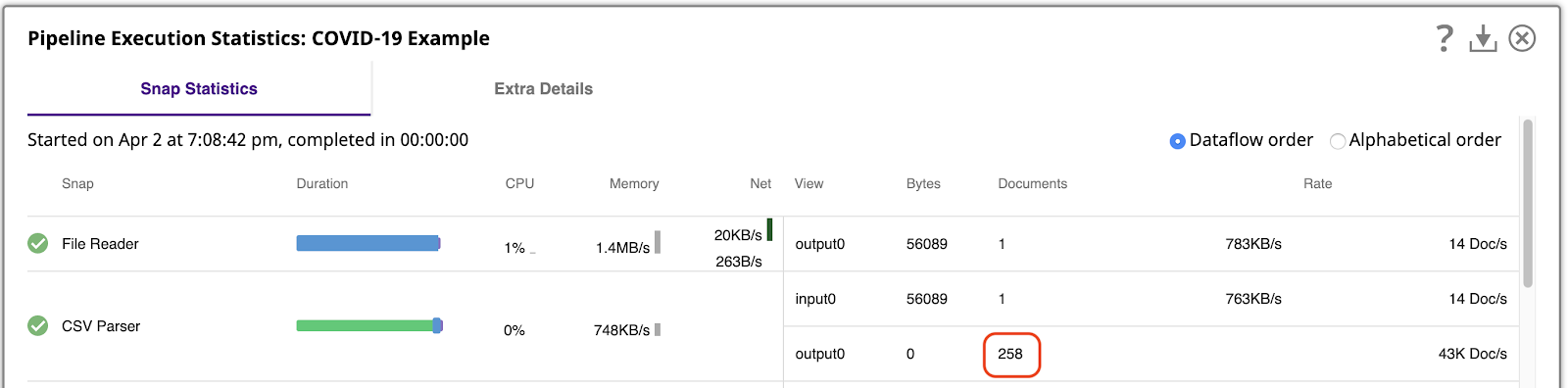
La piattaforma SnapLogic consente di elaborare i dati anche in modalità anteprima, mentre si costruiscono le pipeline. Per lavorare facilmente con questi 258 documenti di output in anteprima, aprite le Impostazioni del Designer e modificare il parametro Numero di documenti in anteprima a 500:
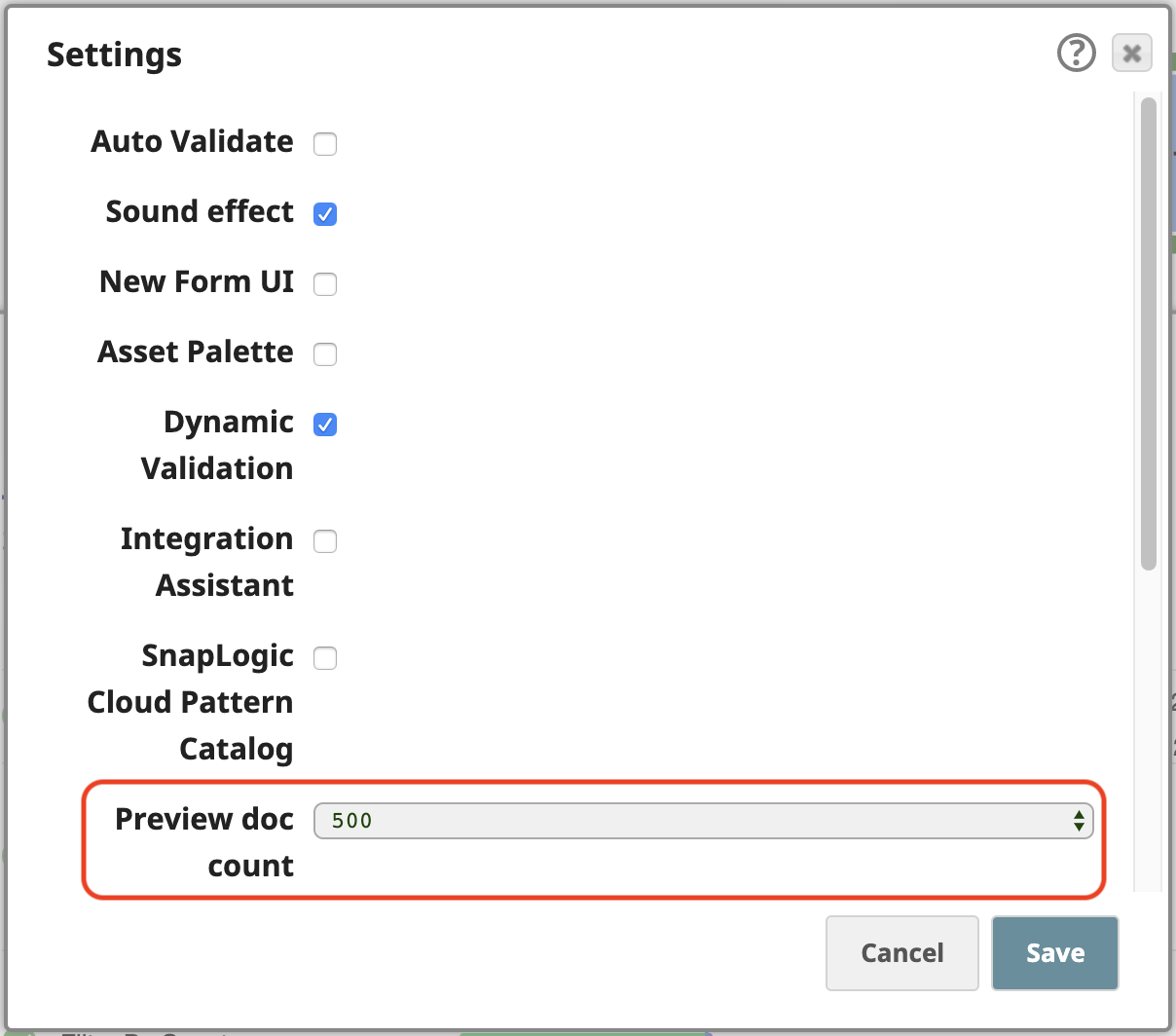
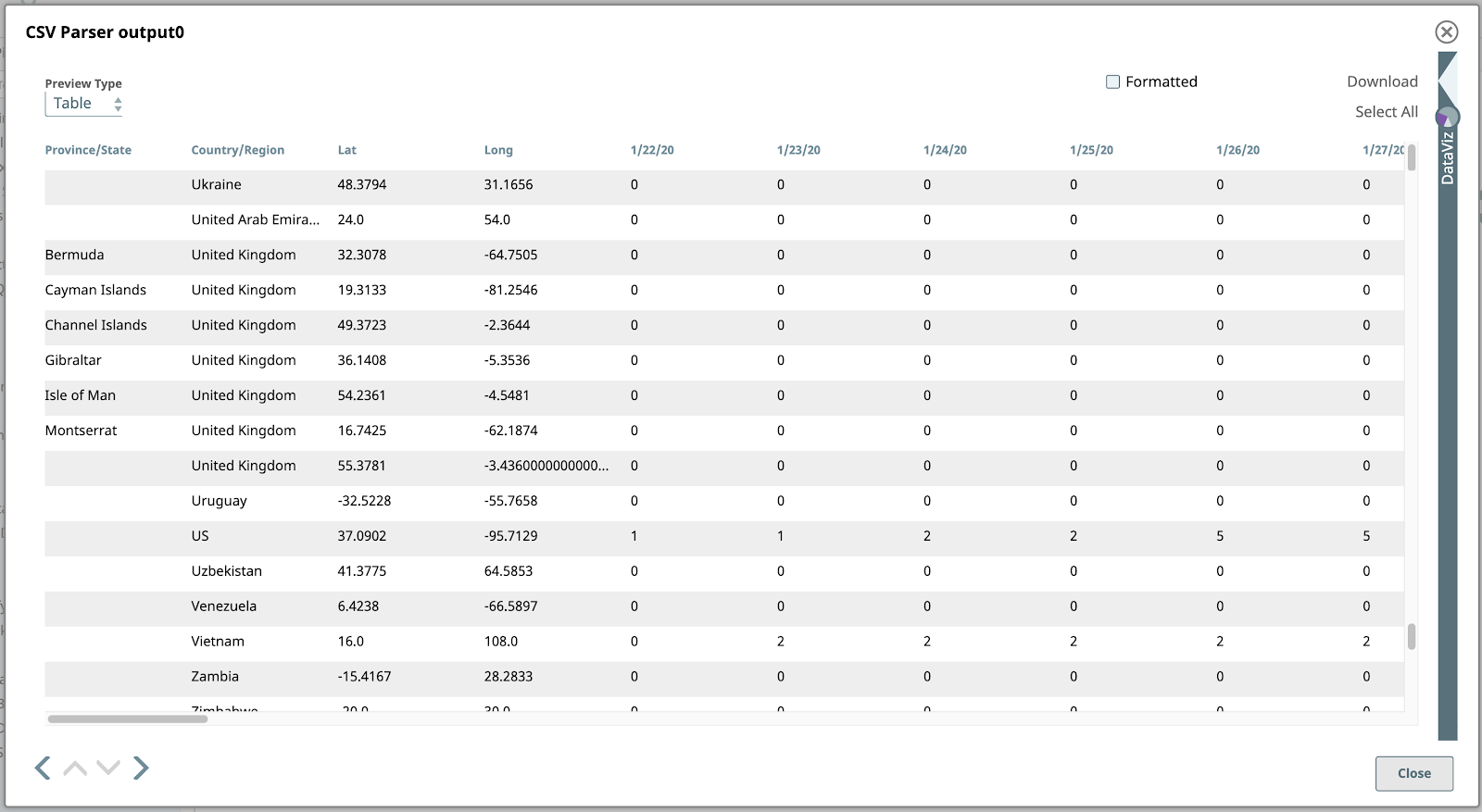
Ora, se si convalida la pipeline, si può vedere l'anteprima di tutti i file Parser CSVdel parser CSV. La tabella predefinita Tabella è il formato migliore per mostrare questi dati, data la loro struttura tabellare.
2. Filtrare per paese
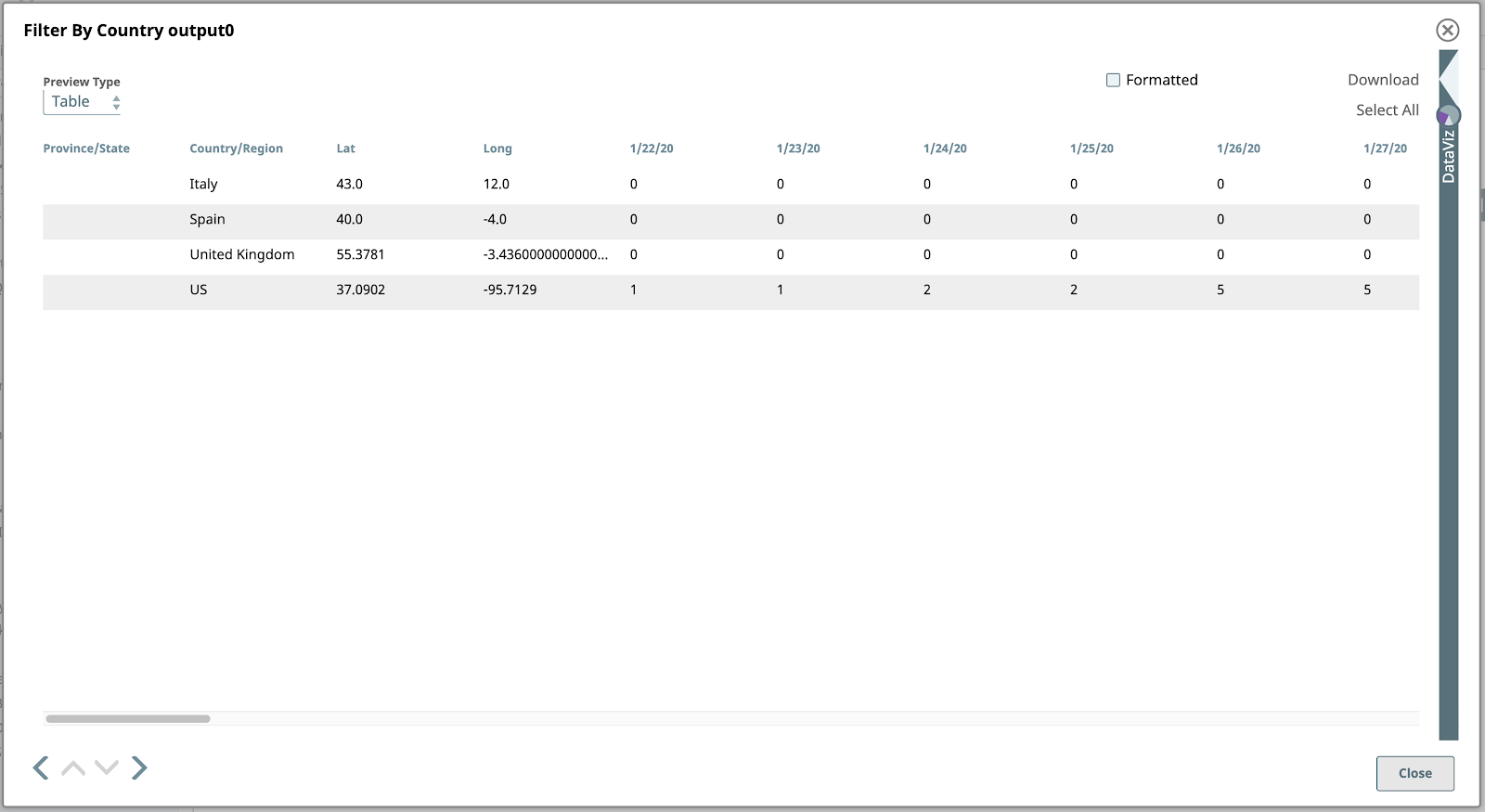
Quindi, filtriamo questi dati per trovare le righe (documenti) corrispondenti solo ai quattro Paesi su cui ci concentriamo in questo esempio. I Paesi sono Stati Uniti, Spagna, Italia e Regno Unito.
Utilizzare un Filtro Snap, configurato con un'espressione utilizzando il linguaggio di espressione di SnapLogicche si basa su JavaScript, ma con caratteristiche aggiuntive per lavorare con i documenti SnapLogic. Questa espressione viene valutata per ogni documento di input come vero o falso. Se l'espressione è valutata come vero per un dato documento di input, questo passerà come documento di output di questo Snap, se invece è falsoil documento verrà saltato.
Per vedere l'espressione completa Espressione del filtrofare clic sulla freccia verso il basso e poi sull'editor espandi editor per aprire il Costruttore di espressioni:
Diamo un'occhiata più da vicino a questa espressione:
["Stati Uniti", "Italia", "Spagna", "Regno Unito"] .indexOf($['Country/Region']) >= 0 && $['Province/State'] == ""
Questa espressione utilizza un array per specificare i paesi di interesse e l'indice indexOf per verificare se il Paese/Regione è un elemento di questo array. Verifica inoltre se il valore Provincia/Stato è vuoto, poiché non siamo non interessati alle righe con un valore per questa colonna.
Se visualizziamo l'anteprima dell'output di questo Snap, vediamo le quattro righe (documenti!) di interesse:
3. Potare i campi
Il prossimo progetto in cantiere è un Mapper di gran lunga il più potente e frequentemente usato in SnapLogic. In questo caso si utilizza l'elemento Mapper per implementare un altro pattern tipico di una pipeline di questo tipo: il filtraggio delle colonne dei dati, che chiameremo campi o chiavi poiché ogni documento è rappresentato come un oggetto JSON. Osserviamo il Mapperè la sua configurazione:
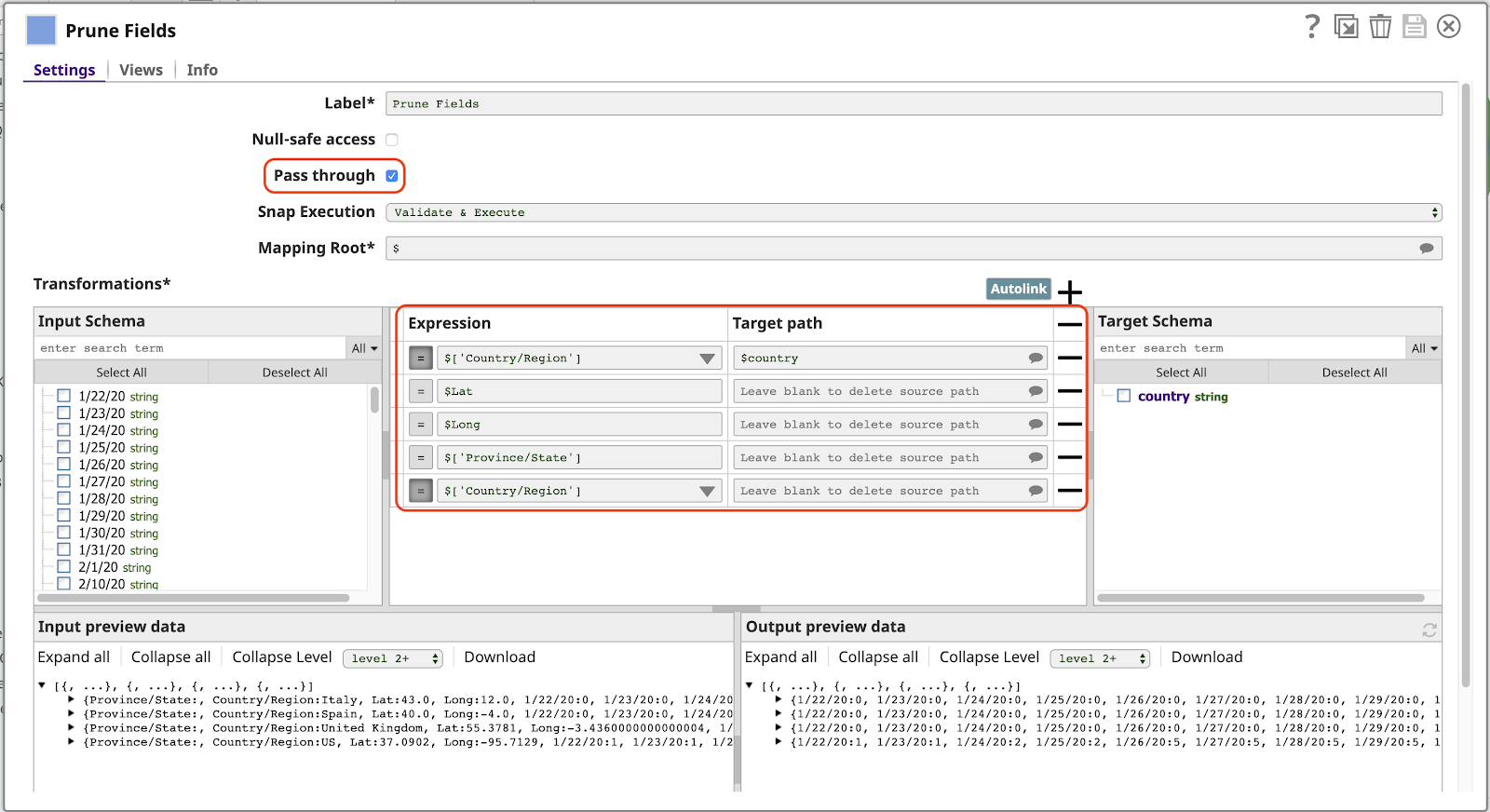
Si noti quanto segue su questa configurazione:
- Il Passaggio attraverso è abilitata. Ciò consente a tutti i campi di passare per impostazione predefinita, senza mapparli esplicitamente, compresi i campi corrispondenti alle date (1/22/20, ecc.). Ciò significa che l'output includerà automaticamente i nuovi dati per le date aggiuntive alla prossima esecuzione della pipeline.
- La prima riga del file Trasformazioni mappa il valore del campo Paese/Regione al nome paese nell'output. La presenza del campo / nel nome originale rende non valido l'uso dell'espressione $Paese/Regione. Dovremmo usare la sintassi alternativa più lunga $['Paese/Regione'], che non è auspicabile. Con questa mappatura, possiamo riferirci a questo valore semplicemente come $paese.
- Qualsiasi riga che abbia un'espressione Espressione ma nessun valore per Percorso di destinazione verrà eliminata dall'output. Questo è necessario solo quando Passa attraverso è abilitato. Si noti che è necessario avere una riga per il Paese/Regione altrimenti il valore di questo campo apparirà due volte nel documento di output, come Paese/Regione (perché Passa attraverso è abilitato) e come Paesecome specificato dalla prima mappatura.
Ecco un'anteprima di questo Snap, con solo i campi della data e del paese all'estrema destra:
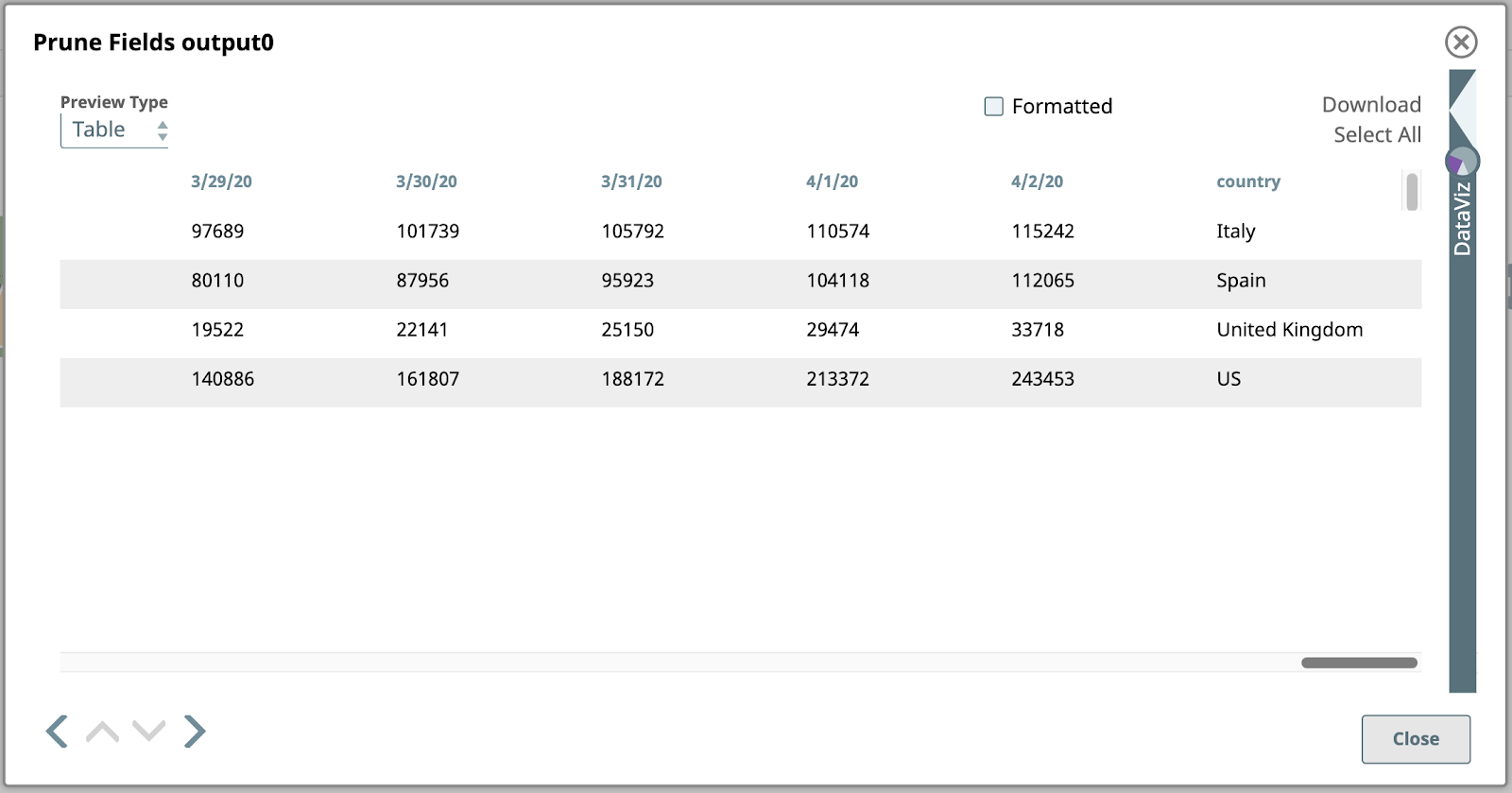
Diamo un'occhiata più da vicino a questo risultato. Ogni valore sotto una colonna di data in questa tabella è il numero totale di casi confermati in quella data nel paese corrispondente nella colonna più a destra. Questi sono i dati che vogliamo rappresentare graficamente, ma prima dobbiamo invertire la struttura in modo che le colonne diventino righe. Ciò richiederà una mappatura e delle espressioni più avanzate.
4. Mappare le colonne in array
Il prossimo progetto in cantiere è un altro Mapper:
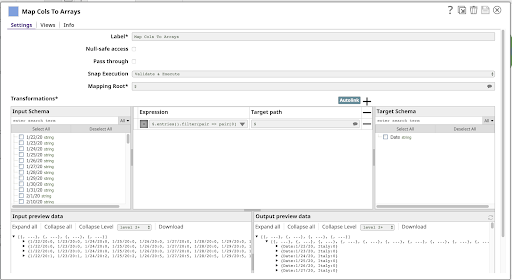
Ha un'unica Espressione:
$.entries().filter(pair => pair[0] != ‘country’) .map(pair => { Date: pair[0], [$country]: pair[1] })
Vediamo di analizzare la situazione.
$.voci()
Questa sottoespressione produrrà un array di coppie chiave/valore nell'oggetto, dove ogni coppia è un subarray con due elementi: la chiave e il valore. È possibile vedere questo risultato utilizzando la sottoespressione sottoespressione del costruttore di Costruttore di espressioni:

.filtro(coppia => coppia[0] != 'paese')
Questa sottoespressione filtrerà l'array di coppie chiave/valore prodotto da vociottenendo un nuovo array di coppie che corrispondono alla funzione di callback fornita come argomento. Nell'immagine qui sopra vediamo le prime coppie del documento contenente i dati degli Stati Uniti: ["1/22/20", "1"], ["1/23/20", "1"], ["1/24/20", "2"], ecc. Se si guarda all'output di Prune Fields, si possono vedere le coppie finali in questa riga: ["4/2/20", "243453"], ["country", "US"]. La nostra funzione di filtro corrisponderà a tutte le coppie tranne l'ultima, dove coppia[0] == "paese".
.map(pair => { Date: pair[0], [$country]: pair[1] })
L'input di questa mappa è un array di coppie chiave/valore che rappresentano ogni data e il numero di casi per quella data: ["1/22/20", "1"], ..., ["4/2/20", "243453"] per la riga degli Stati Uniti.
La mappa restituisce un nuovo array restituisce un nuovo array in cui ogni coppia sarà trasformata dall'espressione a destra dell'attributo =>che è un letterale dell'oggetto ottenendo un oggetto con due proprietà:
- Date: la coppia[0] dà come risultato una proprietà denominata Data contenente la prima metà di ogni coppia (il valore della data).
- [$country]: pair[1] dà come risultato una proprietà il cui nome è il valore dell'espressione $country, e il cui valore è la seconda parte di ciascuna coppia (il numero di occorrenze).
Per l'ultima coppia della riga di dati USA, il metodo mappa produrrà un oggetto come questo:
{“Date”: “4/2/20”, “US”: “243453”}
Questa è la forma più vicina a quella necessaria per iniziare a tracciare i punti su un grafico.
Quando si cambia il Tipo di anteprima a JSON, ecco l'anteprima dell'output del metodo Mappa colonne in array Snap:
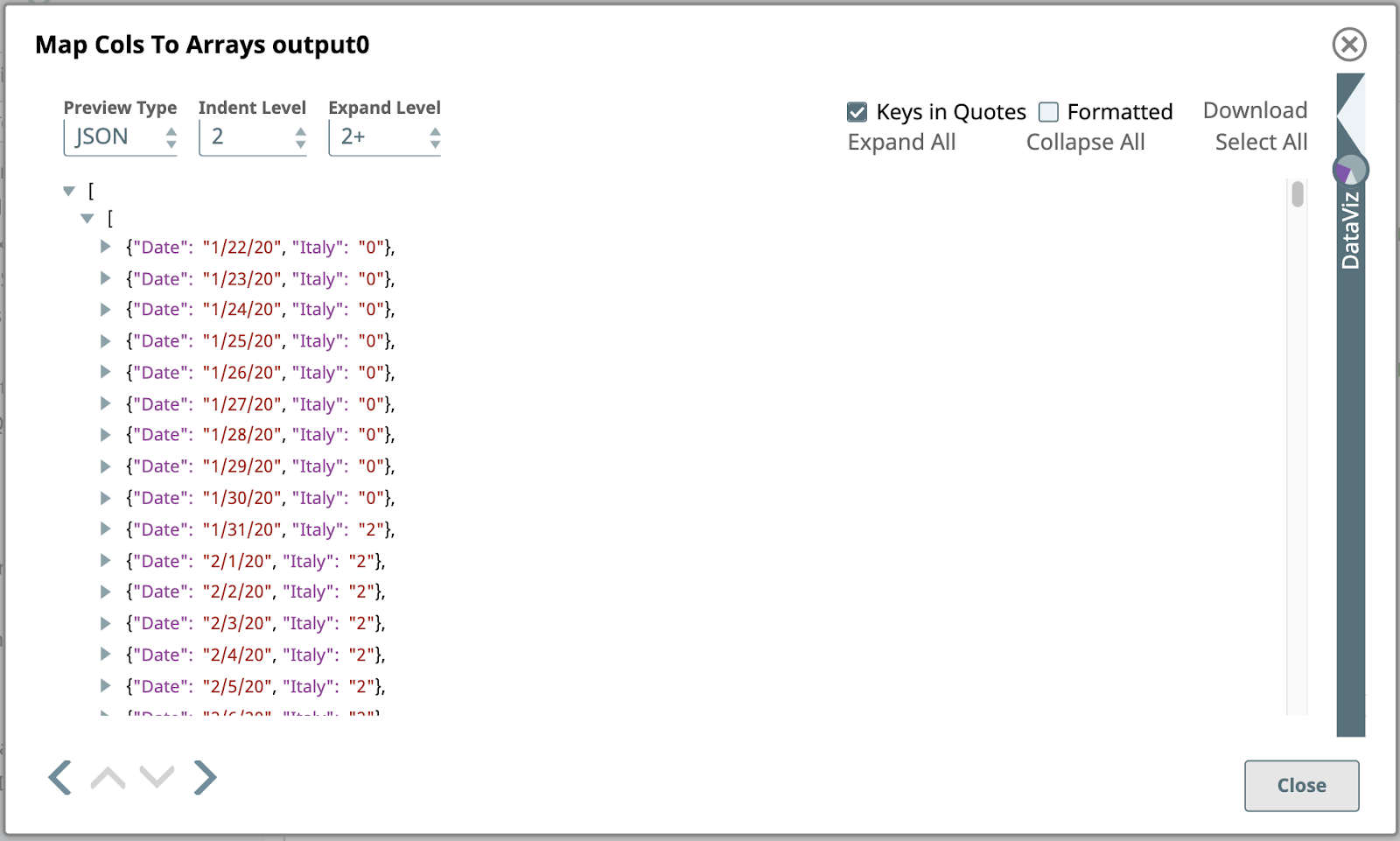
Questa è una vista parziale della primo di questo Snap, creato trasformando il primo documento di input contenente i dati dell'Italia. A differenza del documento di input, che era un semplice oggetto JSON composto da coppie nome/valore, l'oggetto di output è un array di oggetti JSON.
Se si cambia il Tipo di anteprima e si fa clic su alcune celle dell'ultima riga, che rappresentano gli stessi dati, si può osservare la struttura della matrice annidata.
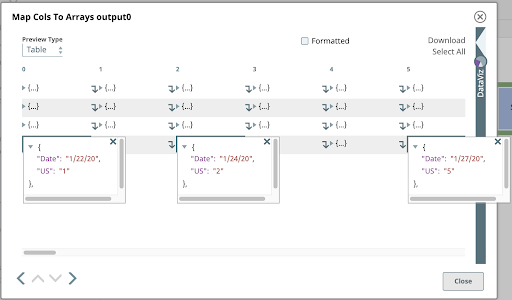
5. Dividere
Come mostrato in precedenza, ogni documento in ingresso allo Snap successivo della nostra pipeline è un array di oggetti. Vogliamo dividere questi array nei loro oggetti componenti. Utilizziamo il JSON Splitter con l'opzione Percorso Json configurato con il percorso che fa riferimento agli elementi dell'array che devono essere mappati come documenti di output. Facendo clic sull'icona di suggerimento all'estremità destra dell'opzione Percorso Json ci aiuta a farlo. Facendo clic sul nodo superiore di questa struttura, il percorso viene impostato su $[*].
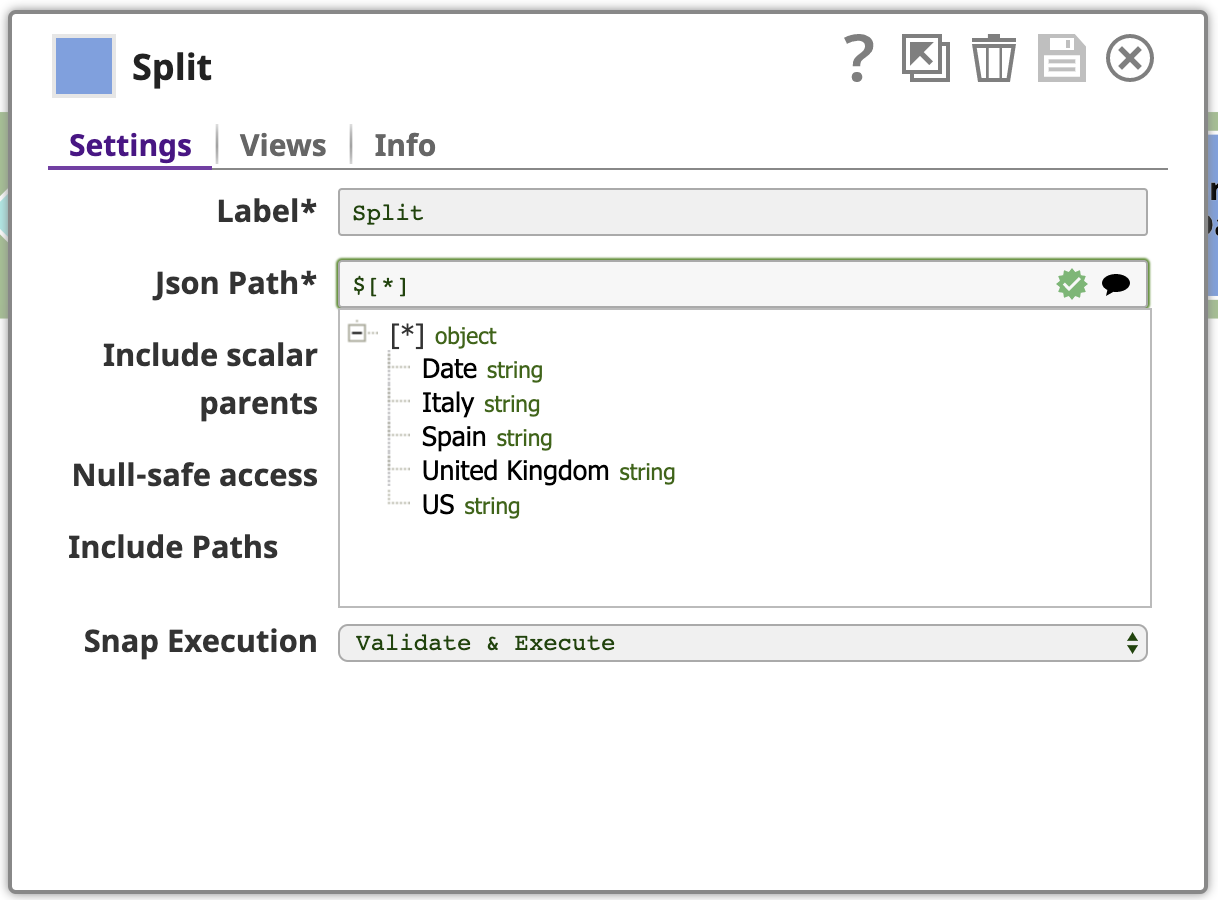
Ecco l'output dello splitter JSON per le righe con valori US:
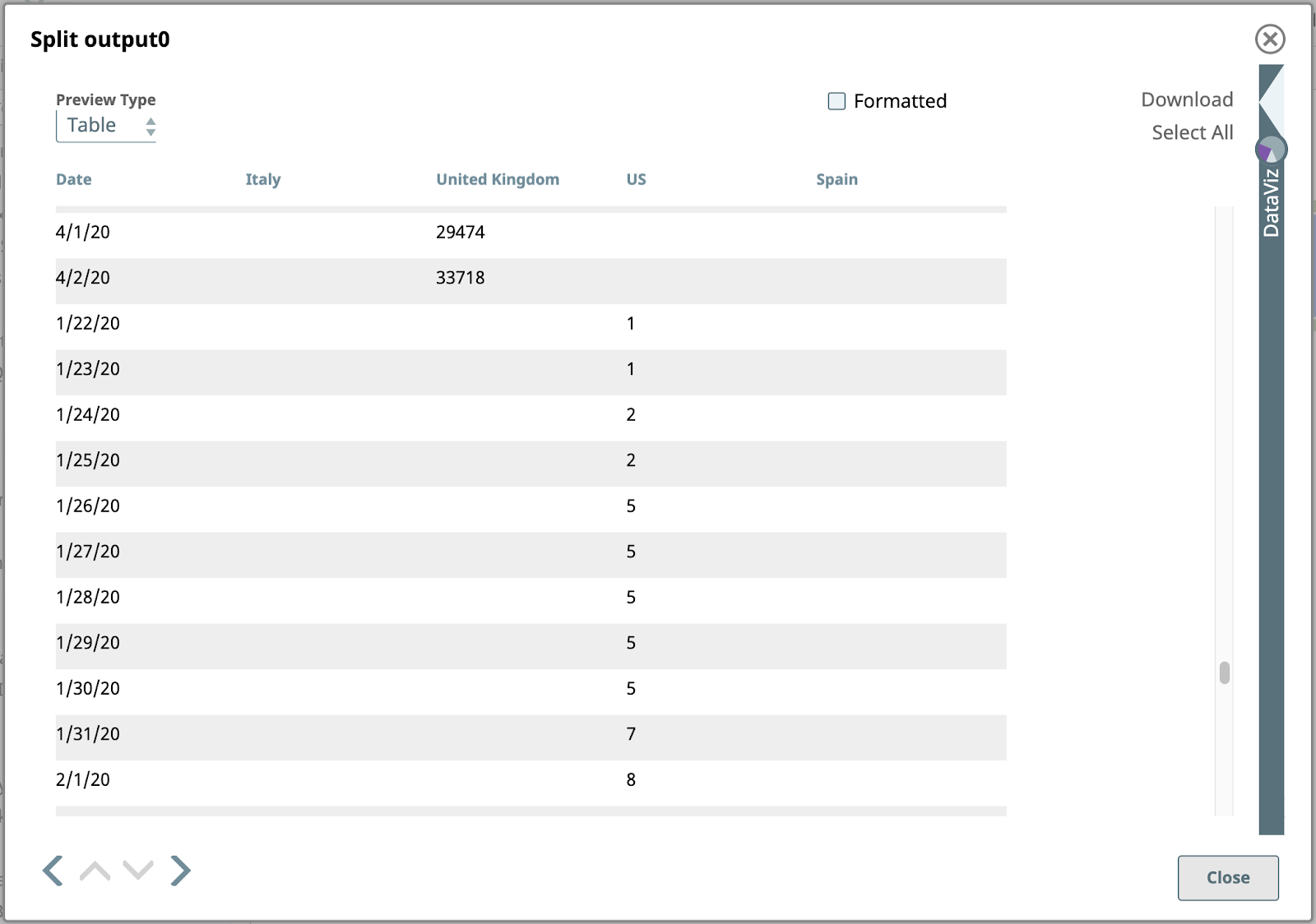
6. Ordina per data
Successivamente, ordinare i dati per Data. È facile con il metodo Ordina configurato come mostrato:
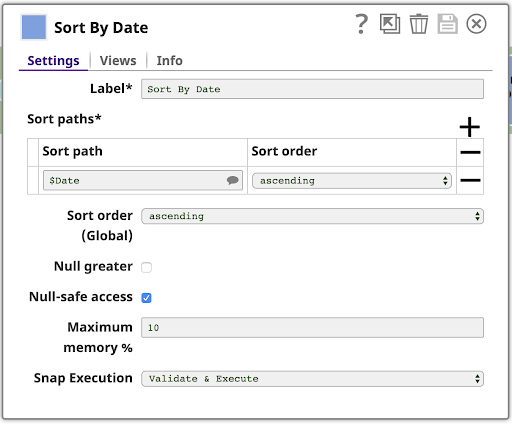
Questo è l'output ordinato:
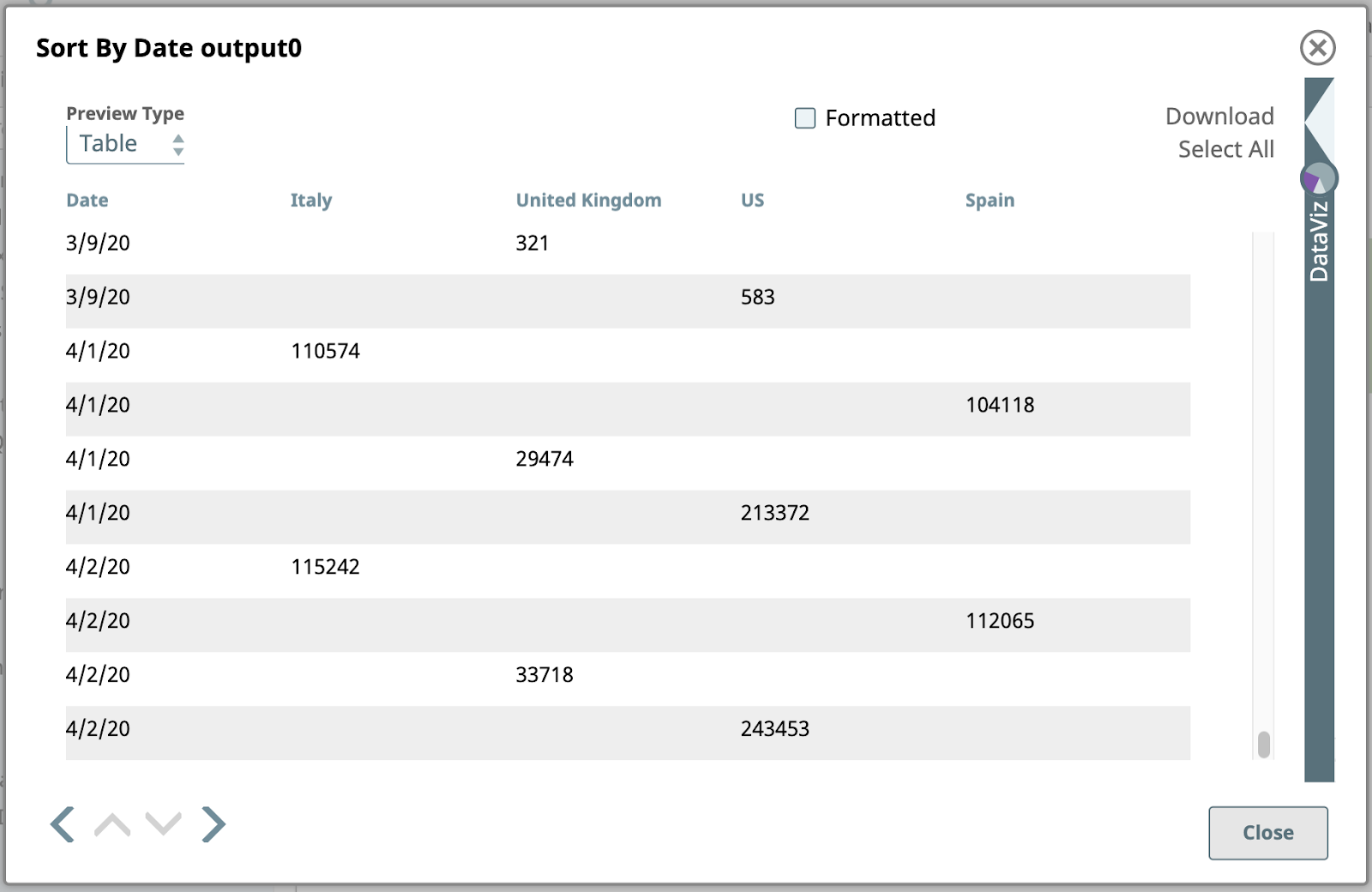
Si noti che i valori delle date sono di tipo stringa, quindi vengono ordinati alfanumericamente, senza interpretarli come date. Ciò significa che "3/9/20" si trova alla fine dei dati di marzo. Potremmo occuparcene se fosse necessario, ma non lo facciamo. Questo risultato è perfettamente adeguato per le fasi rimanenti.
7. Gruppo per data
Ora che i documenti sono ordinati per data, si può usare il metodo Raggruppa per campi per raggruppare i documenti in base alla classificazione dei campi. Si noti che questa operazione funziona correttamente solo se i dati sono effettivamente ordinati.
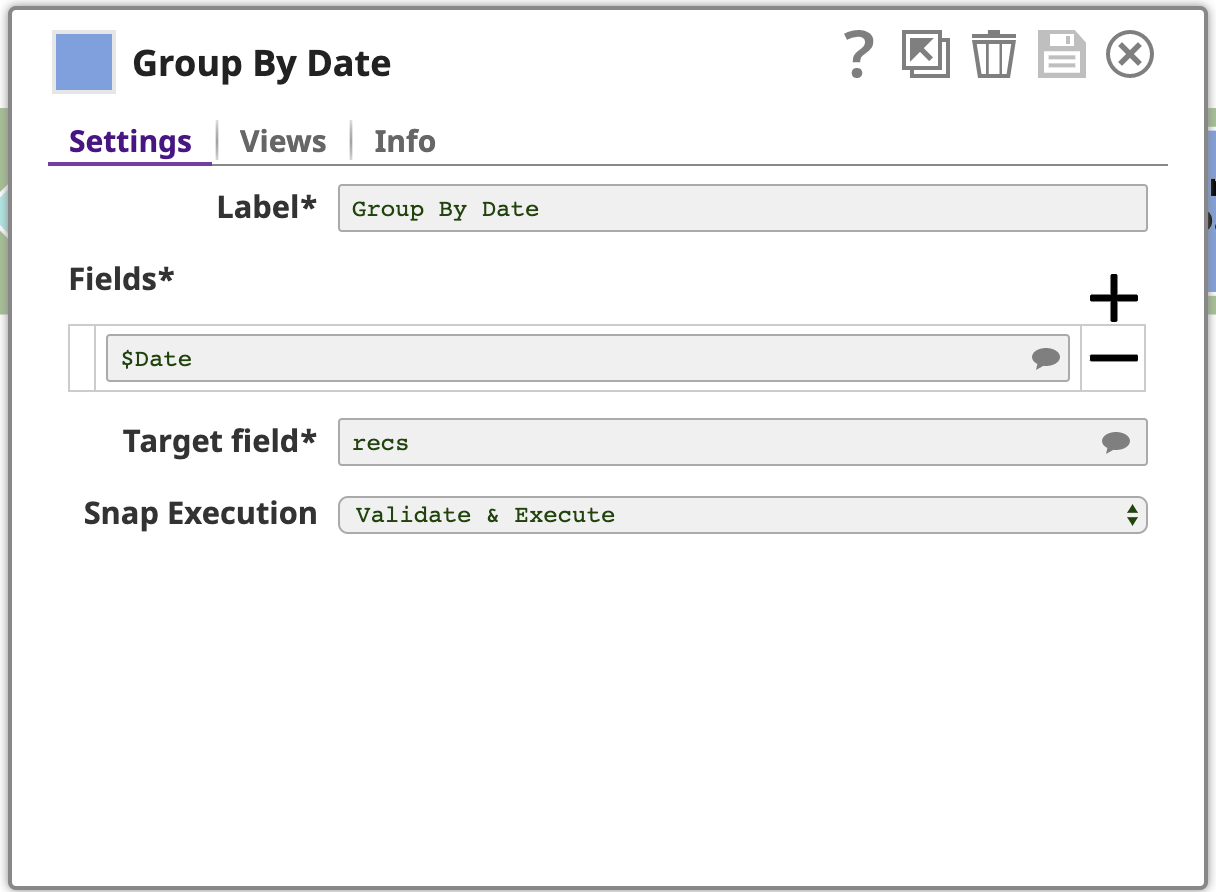
Questo Snap è configurato con uno o più campi da raggruppare, in questo caso solo il campo Data. Lo snap raccoglierà ogni gruppo di documenti di input con la stessa Data e produrrà un singolo documento contenente i dati di questi documenti di input. I dati sono annidati in un array nel documento di output, dove l'array è memorizzato in un campo denominato dal campo Campo di destinazione impostazione: recs. Per chiarire questo aspetto, vediamo l'anteprima dell'output in formato JSON: ecco l'ultima pagina:
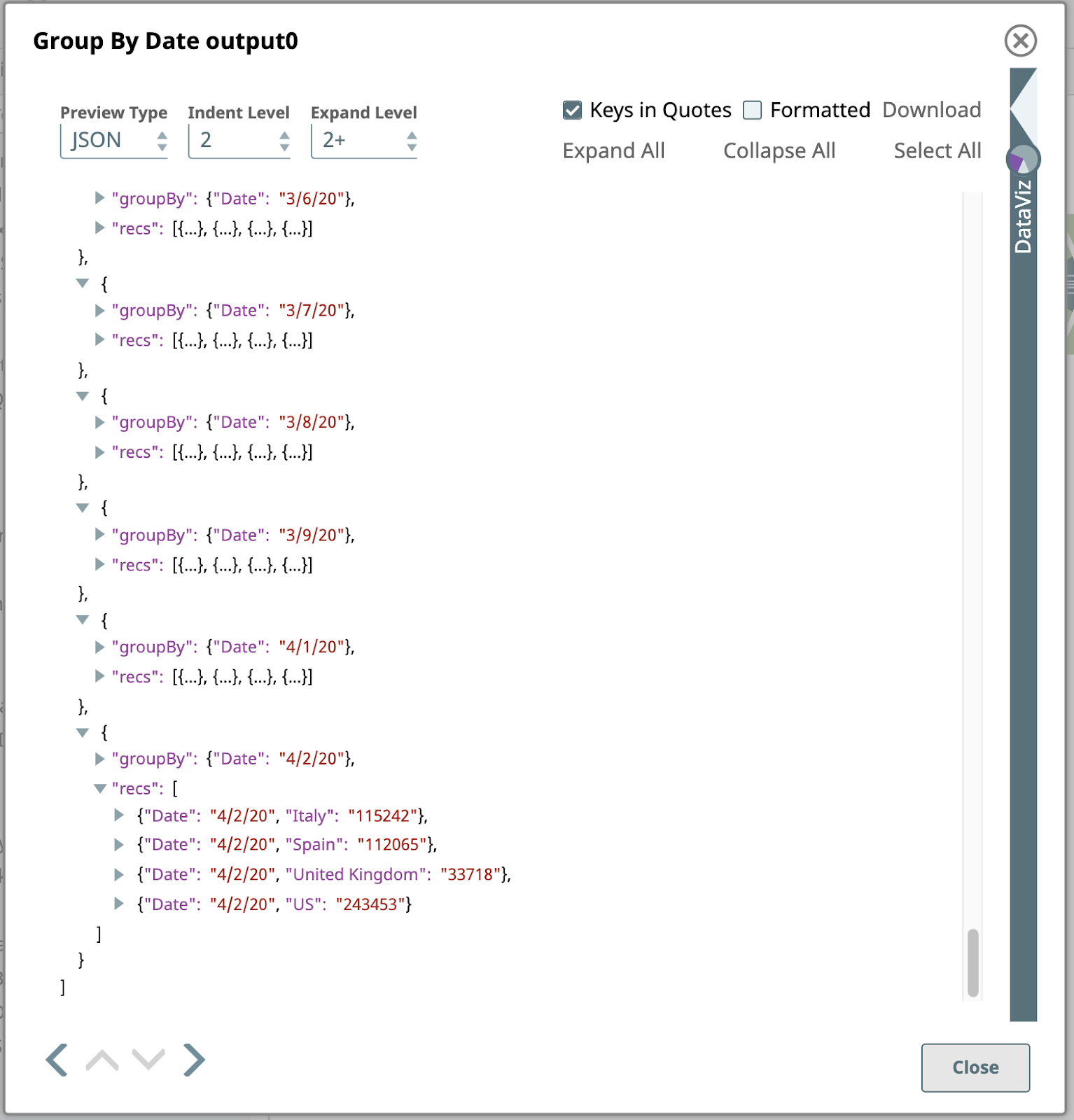
L'ultimo passo di questa pipeline è un altro Mappatore.
8. Ridurre
Avete già visto la mappa del linguaggio di espressione utilizzato nel nostro ultimo Mappatore. Questo potrebbe farvi venire in mente il modello di programmazione MapReduce, alla base dell'elaborazione dei "Big Data". Ebbene, indovinate un po'? Il linguaggio di espressione di SnapLogic ha anche una funzione di ridurre che utilizzeremo nella nostra funzione finale di Mappatore. Ecco la nostra configurazione (con alcuni pannelli laterali chiusi):
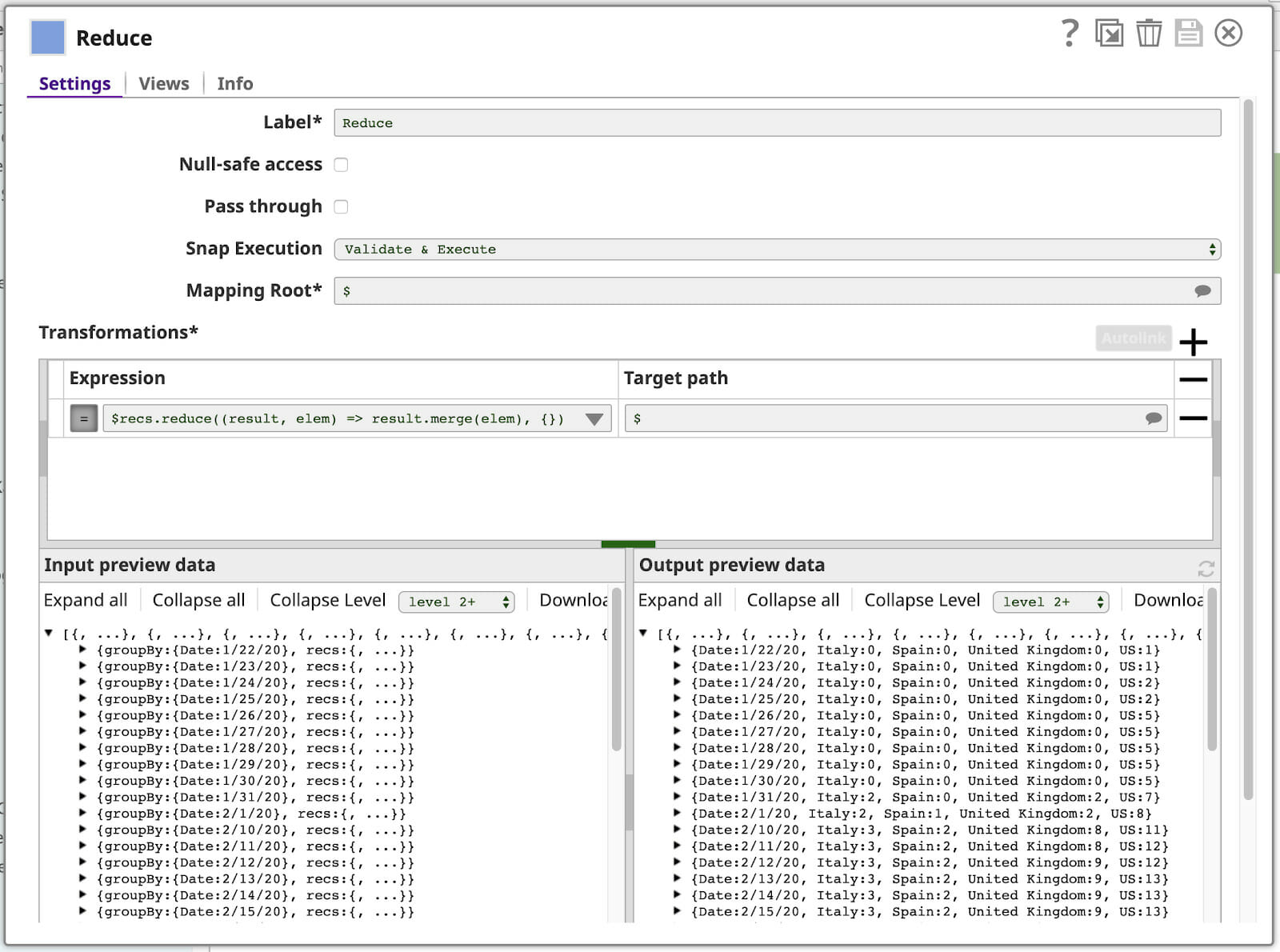
Scomponiamo l'espressione:
$recs.reduce((result, elem) => result.merge(elem), {})
$recs è l'array all'interno di ciascun documento di input, che si presenta in questo modo:

Contiene tutto ciò che serve per il documento di output.
.ridurre(funzione, valore iniziale) ridurrà questo array a un singolo valore utilizzando la funzione indicata, iniziando l'iterazione con il valore iniziale indicato. In questo caso, la funzione è espressa come un'espressione lambda in JavaScript:
(risultato, elem) => result.merge(elem)
I parametri della funzione sono denominati sul lato sinistro dell'espressione => risultato e elem. L'espressione a destra viene utilizzata per calcolare il risultato della funzione. L'espressione ridurre richiamerà questa funzione una volta per ogni elemento dell'array, con l'output di ogni chiamata che servirà come input per la chiamata successiva tramite la funzione risultato e il valore dell'elemento successivo dell'array tramite il parametro elem e il valore del prossimo elemento dell'array. Il parametro valore iniziale dato a ridurre è il valore del parametro risultato da utilizzare per la prima iterazione. In questo caso, stiamo usando il parametro merge per unire questo array in un singolo oggetto.
La comprensione sarà più semplice se mostreremo ogni iterazione:
| Iterazione | Ingresso: risultato | Ingresso: elem | Uscita: result.merge(elem) |
| 1 | {} (il valore valore iniziale) | {“Date”, “4/20/20”, “Italy”: “115242”} | {“Date”, “4/20/20”, “Italy”: “115242”} |
|
2 |
{“Date”, “4/20/20”, “Italy”: “115242”} | {“Date”, “4/20/20”, “Spain”: “112065”} | {“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”} |
|
3 |
{“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”} | {“Date”, “4/20/20”, “United Kingdom”: “33718”} | {“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”, “United Kingdom”: “33718”} |
|
4 |
{“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”, “United Kingdom”: “33718”} | {“Date”, “4/20/20”, “US”: “243453”} | {“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”, “United Kingdom”: “33718”, “US”: “243453”} |
Ad ogni iterazione di ridurreun altro elemento dell'array viene unito all'oggetto di output. Ogni elemento ha lo stesso valore di Data, quindi rimane invariato dopo ogni iterazione, ma alla fine si ottiene un singolo oggetto che contiene tutti i casi di paese per quella data.
È possibile vedere i documenti di output risultanti nella sezione Anteprima dati di output nell'angolo in basso a destra del pannello Riduci Mapper mostrato sopra.
Visualizzare i dati
Vediamo l'anteprima dell'output del metodo Riduci del passo precedente.
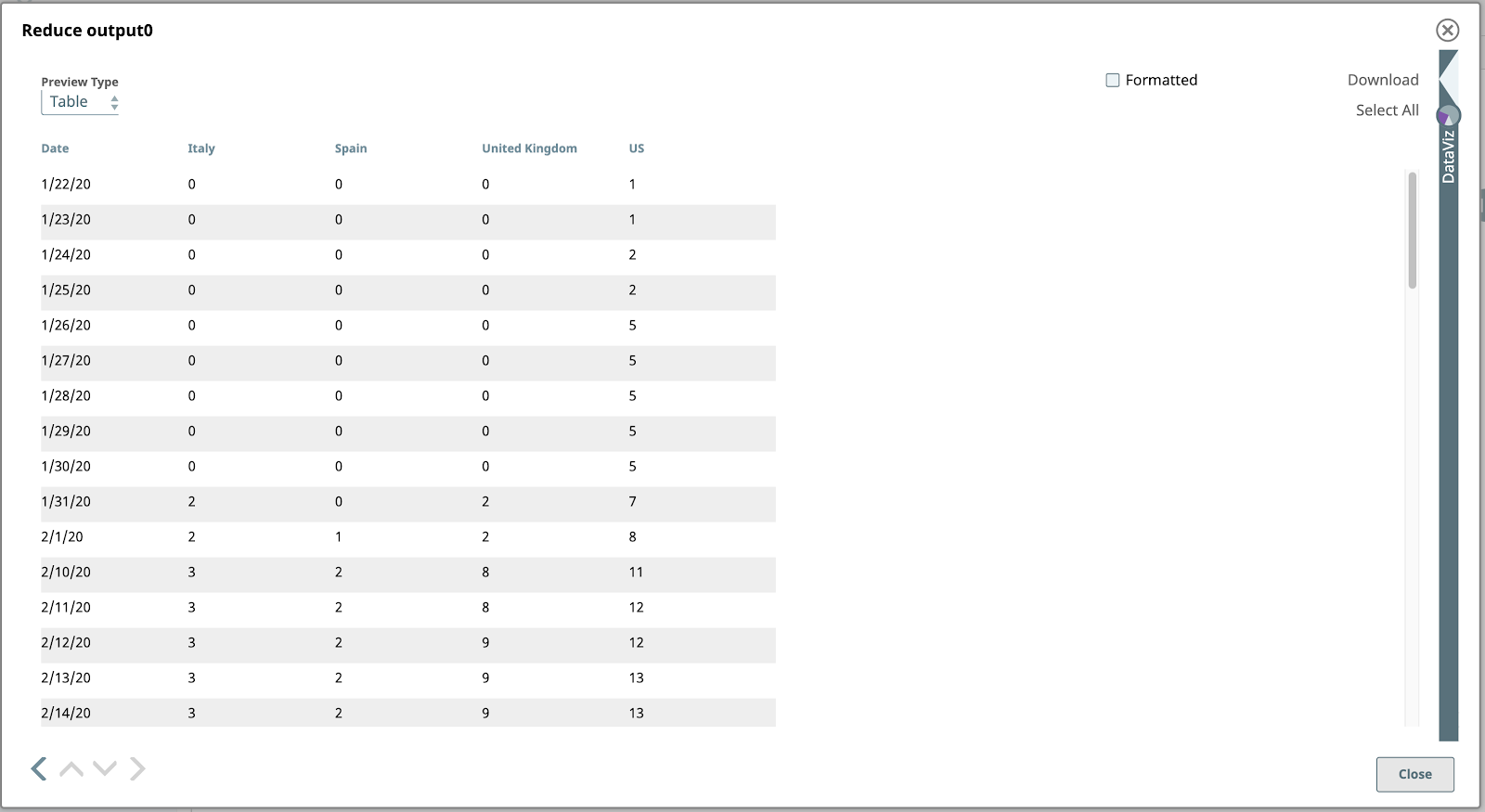
Bingo! I nostri dati hanno finalmente un aspetto grafico. Apriamo il file DataViz facendo clic sulla forma a freccia rivolta a sinistra, appena sopra l'etichetta DataViz sul lato destro della finestra. Il pannello si espande fino a occupare la metà destra.
Per visualizzare il grafico a linee finale, impostare il Tipo di grafico su "Grafico a linee - Data come asse X", asse X su "Data" e Chiave da visualizzare ai nomi dei paesi che si desidera visualizzare.
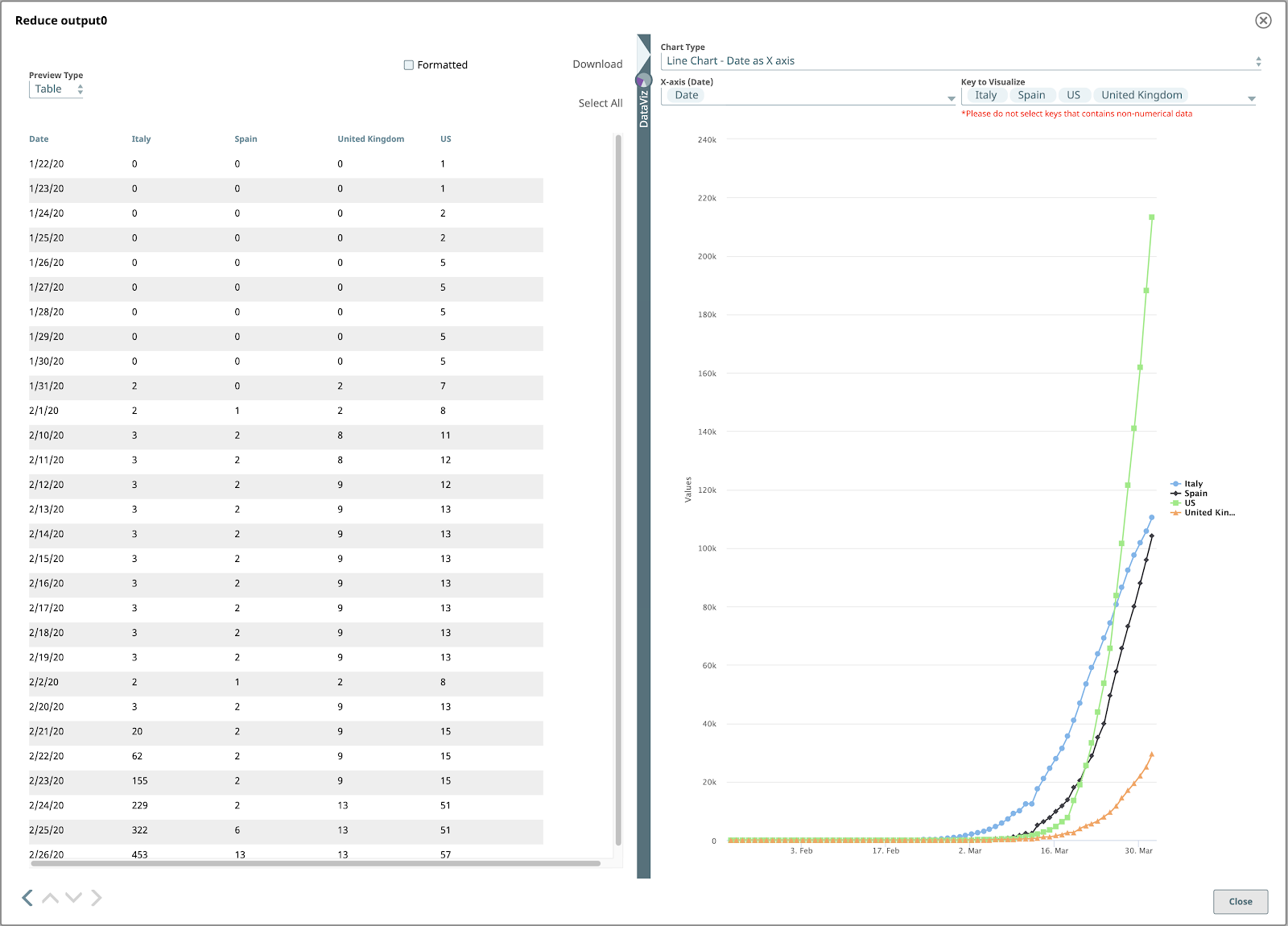
Spero che questo blog vi abbia aiutato a comprendere meglio le potenti funzionalità della piattaforma SnapLogic che consentono di leggere e visualizzare i dati COVID-19.
Spero nella migliore fortuna per voi e i vostri in questo momento difficile.
Rimanete in salute, rimanete al sicuro!







