






Le nombre total de cas confirmés de COVID-19 dans le monde approche désormais les deux millions.
De nombreuses ressources sont disponibles sur le web pour suivre et comprendre la croissance de cette pandémie, notamment le tableau de bord géré par le Centre de science et d‘ingénierie des systèmes de l‘université Johns Hopkins. Ce tableau de bord s‘appuie sur un référentiel de données publié sur GitHub. Les données sources sont de haute qualité mais nécessitent une transformation structurelle importante pour une visualisation efficace. La plate-forme d‘intégration intelligente SnapLogic gère facilement les transformations.
Dans ce blog, j‘expliquerai la construction d‘un pipeline SnapLogic, qui lit un sous-ensemble de ces données depuis le dépôt GitHub, filtre les données pour quelques pays, et transforme les données de manière à ce qu‘elles puissent être visualisées avec un graphique linéaire en utilisant la fonctionnalité DataViz de SnapLogic. Si vous souhaitez suivre le processus, rendez-vous dans notre communauté pour télécharger le pipeline illustré dans ce billet. Tout au long de ce blog, vous trouverez des liens vers les sections pertinentes de la documentation produit SnapLogic, où vous trouverez plus d‘informations.
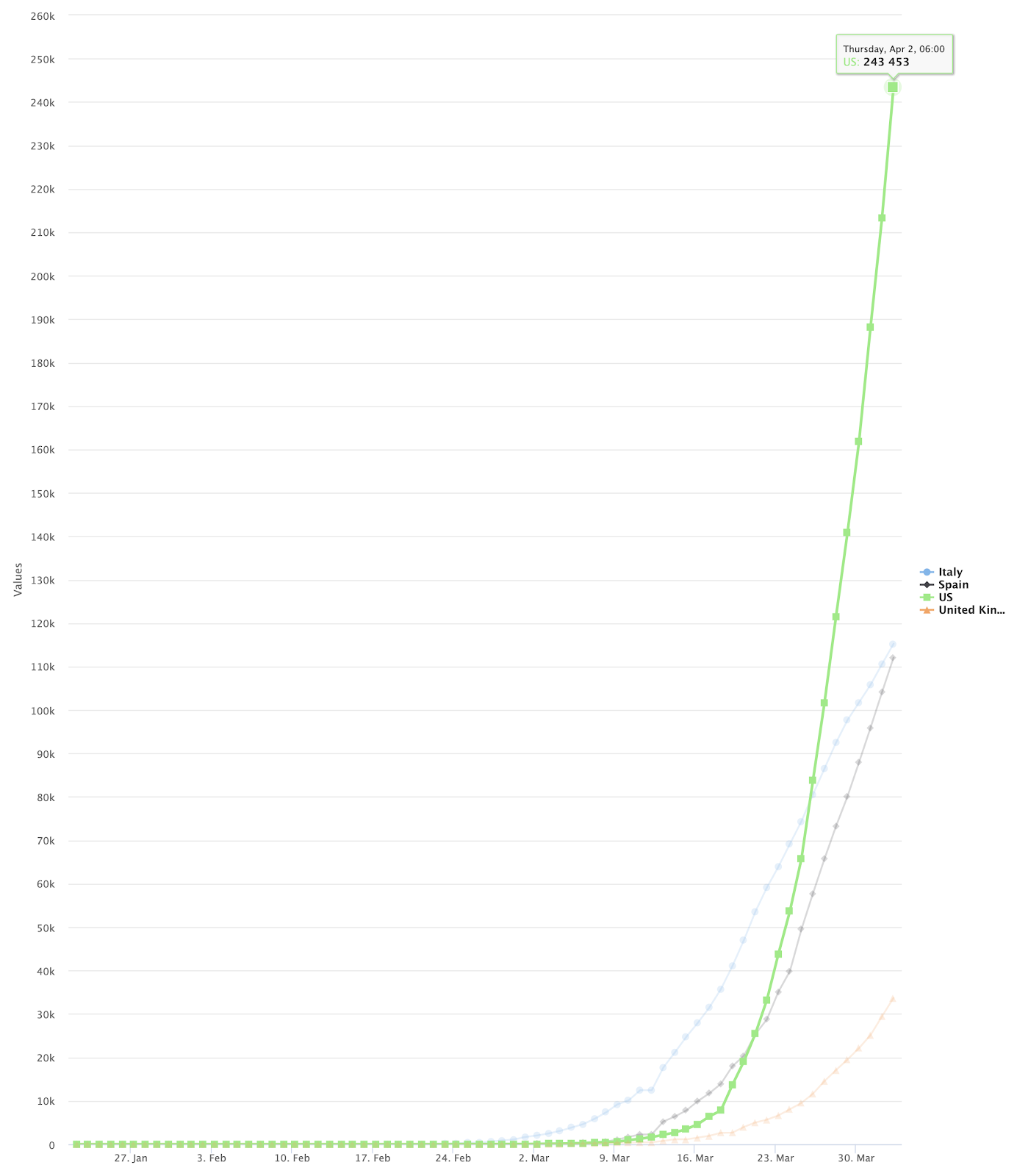
Le résultat final ressemblera à ceci :
Examiner les données sources
Notre source de données est la base de données JHU time_series_covid19_confirmed_global.csv du JHU. Ce fichier contient des données chronologiques sur le nombre total de cas confirmés de COVID-19, par pays/région, et est mis à jour quotidiennement.
GitHub‘s brut de GitHub dans cette vue est lié à l‘URL du fichier CSV brut.
Construire le pipeline
Voici un aperçu de notre pipeline SnapLogic pour lire et transformer ces données :

Découvrons ce pipeline, Snap par Snap.
1. Lecteur de fichiers et analyseur CSV
Les deux premiers snaps de cette filière illustrent une association très fréquente :
- A lecteur de fichiers pour lire les données brutes, configuré avec l URL.
- A Analyseur Snap spécifique au format de données du fichier, dans ce cas le format CSV.
Il est important de savoir avec quelle quantité de données nous travaillons. Nous pouvons le faire en exécutant le pipeline et en affichant les Statistiques d‘exécution du pipelinequi montre que l‘analyseur CSV Parser a généré 258 documents de sortie, un par ligne du fichier CSV.
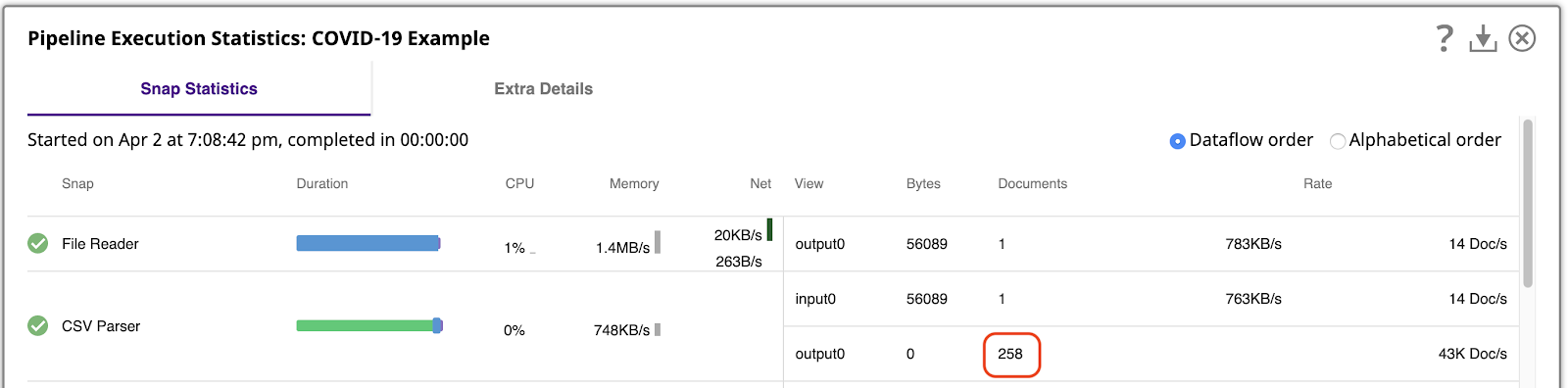
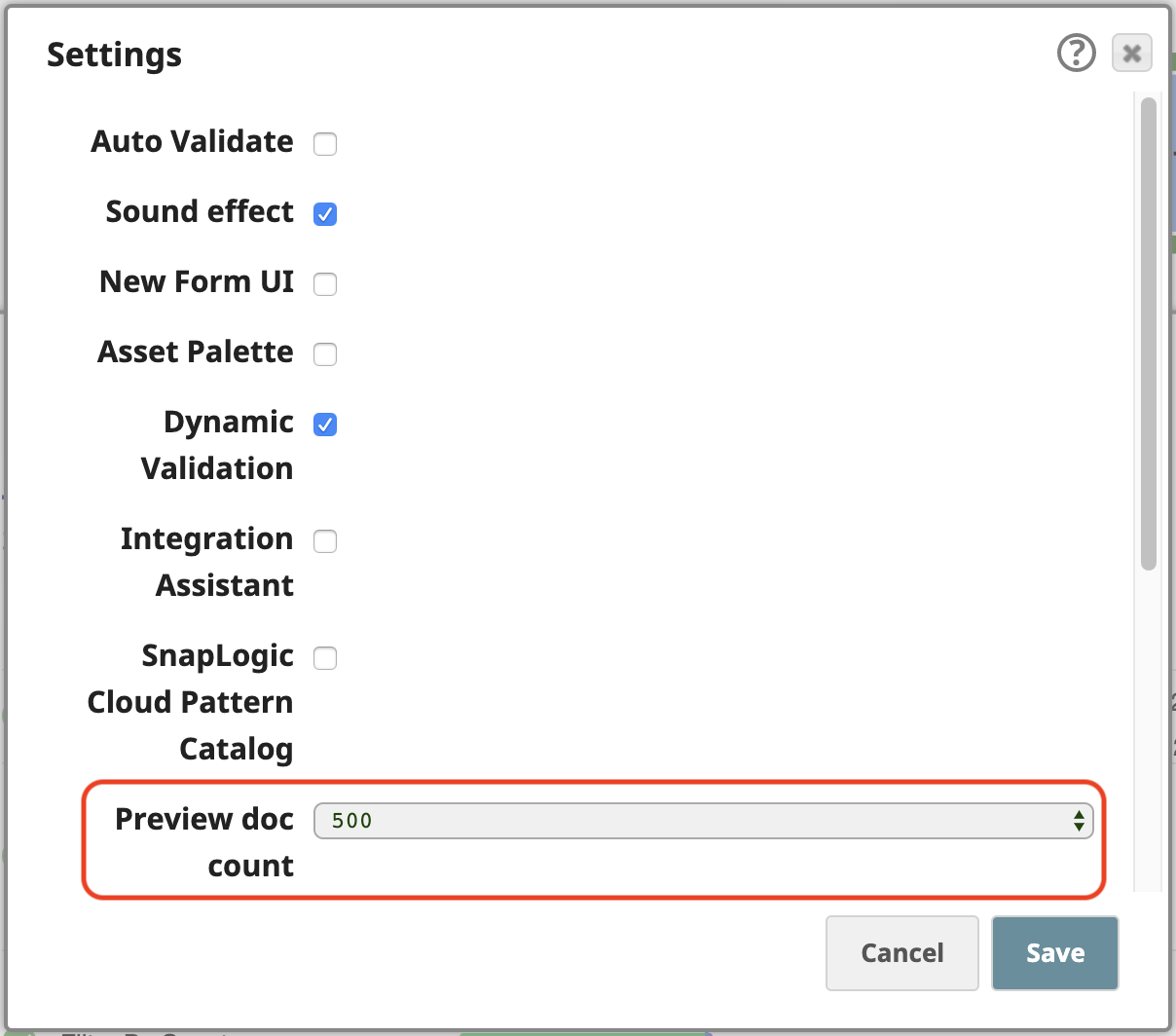
SnapLogic plateforme vous permet de traiter les données même en mode prévisualisation, pendant que vous construisez vos pipelines. Pour travailler facilement avec ces 258 documents de sortie en mode prévisualisation, ouvrez les Paramètres du Concepteur et modifiez le paramètre Nombre de documents de prévisualisation à 500 :
Maintenant, si nous validons le pipeline, nous pouvons prévisualiser tous les éléments de l‘analyseur CSV Parserde l‘analyseur CSV. Le document par défaut Tableau par défaut est le meilleur format pour afficher ces données étant donné leur structure tabulaire.
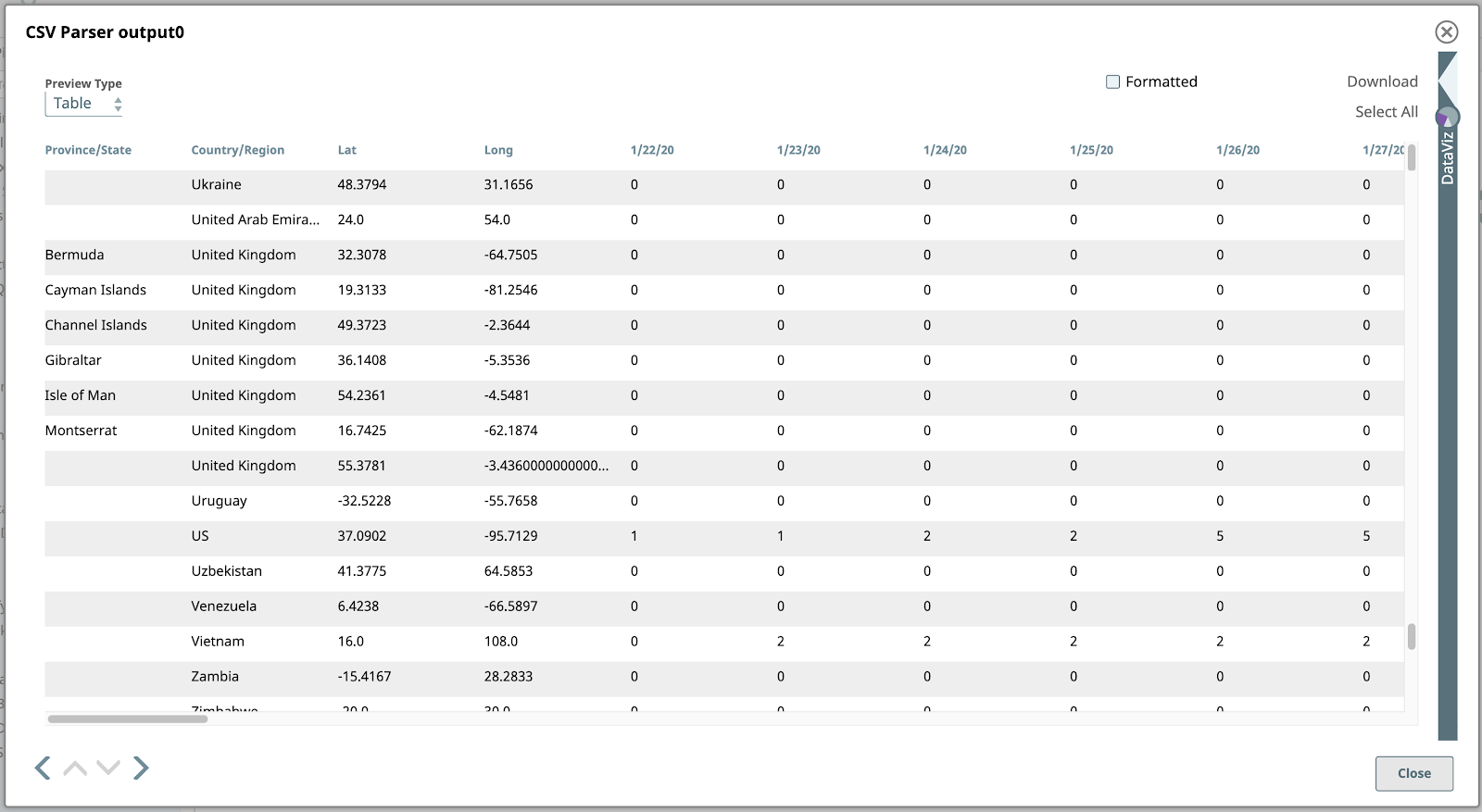
2. Filtrer par pays
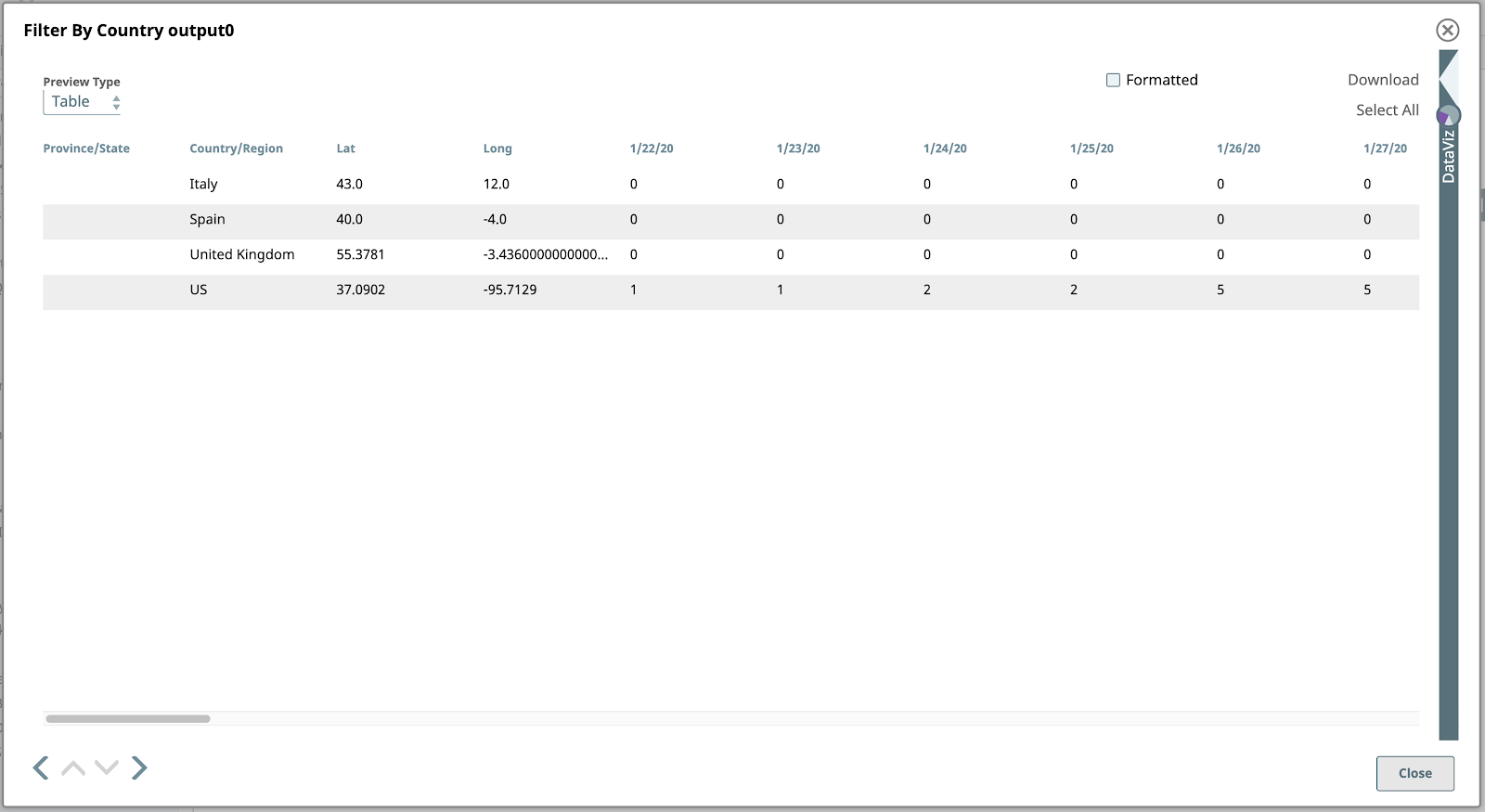
Ensuite, filtrons ces données pour trouver les lignes (documents) correspondant aux quatre pays sur lesquels nous nous concentrons pour cet exemple. Ces pays sont les États-Unis, l‘Espagne, l‘Italie et le Royaume-Uni.
Utiliser un filtre Snap, configuré avec une expression utilisant le langage d‘expression de le langage d‘expression de SnapLogicqui est basé sur JavaScript, mais avec des fonctionnalités supplémentaires pour travailler avec les documents SnapLogic. Cette expression est évaluée pour chaque document d‘entrée comme vrai ou faux. Si l‘expression est évaluée à vrai pour un document d‘entrée donné, il passera en tant que document de sortie de ce Snap, si falsele document sera ignoré.
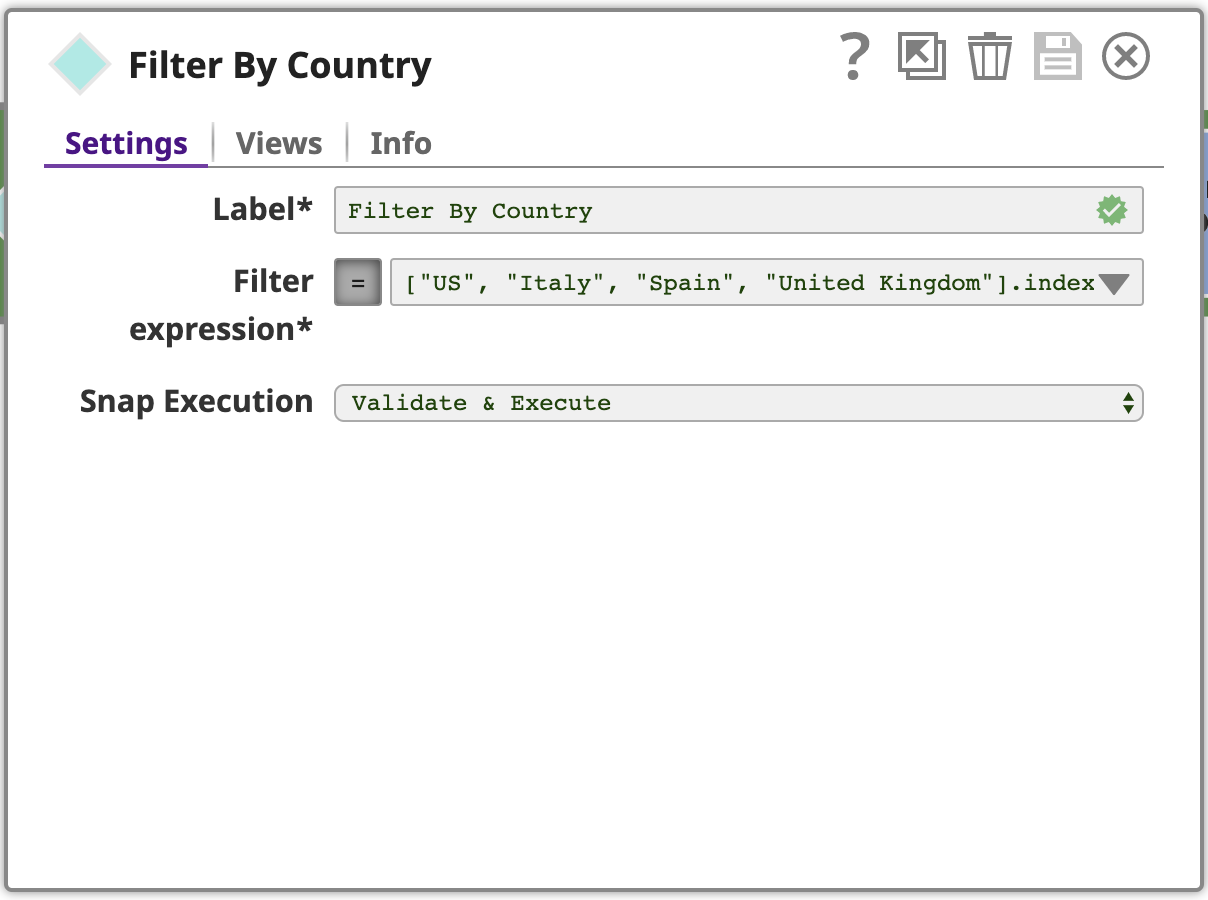
Pour voir l‘expression complète du expression du filtrecliquez sur la flèche vers le bas, puis sur l‘éditeur de développement développer l‘éditeur pour ouvrir la fenêtre Constructeur d‘expression:
Examinons cette expression de plus près :
["US", "Italie", "Espagne", "Royaume-Uni"] .indexOf($[‘Pays/Région‘]) >= 0 && $[‘Province/État‘] == ""
Cette expression utilise un tableau pour spécifier les pays d‘intérêt et l‘attribut indexOf pour vérifier si le Pays/Région est un élément de ce tableau. Elle vérifie également si la valeur Province/État est vide, puisque nous ne sommes pas pas pas intéressés par les lignes contenant une valeur pour cette colonne.
Si nous prévoyons la sortie de ce Snap, nous voyons les quatre lignes (documents !) qui nous intéressent :
3. Élaguer les champs
La prochaine étape est la création d‘un Mapper qui est de loin la plus puissante et la plus fréquemment utilisée dans SnapLogic. Ici, nous utilisons le Snap Mapper pour mettre en œuvre un autre modèle typique utilisé dans un pipeline de cette nature : le filtrage des colonnes de données, que nous appellerons champs ou clés puisque chaque document est représenté par un objet JSON. Jetons un coup d‘œil à l‘outil Mapperest en cours de configuration :
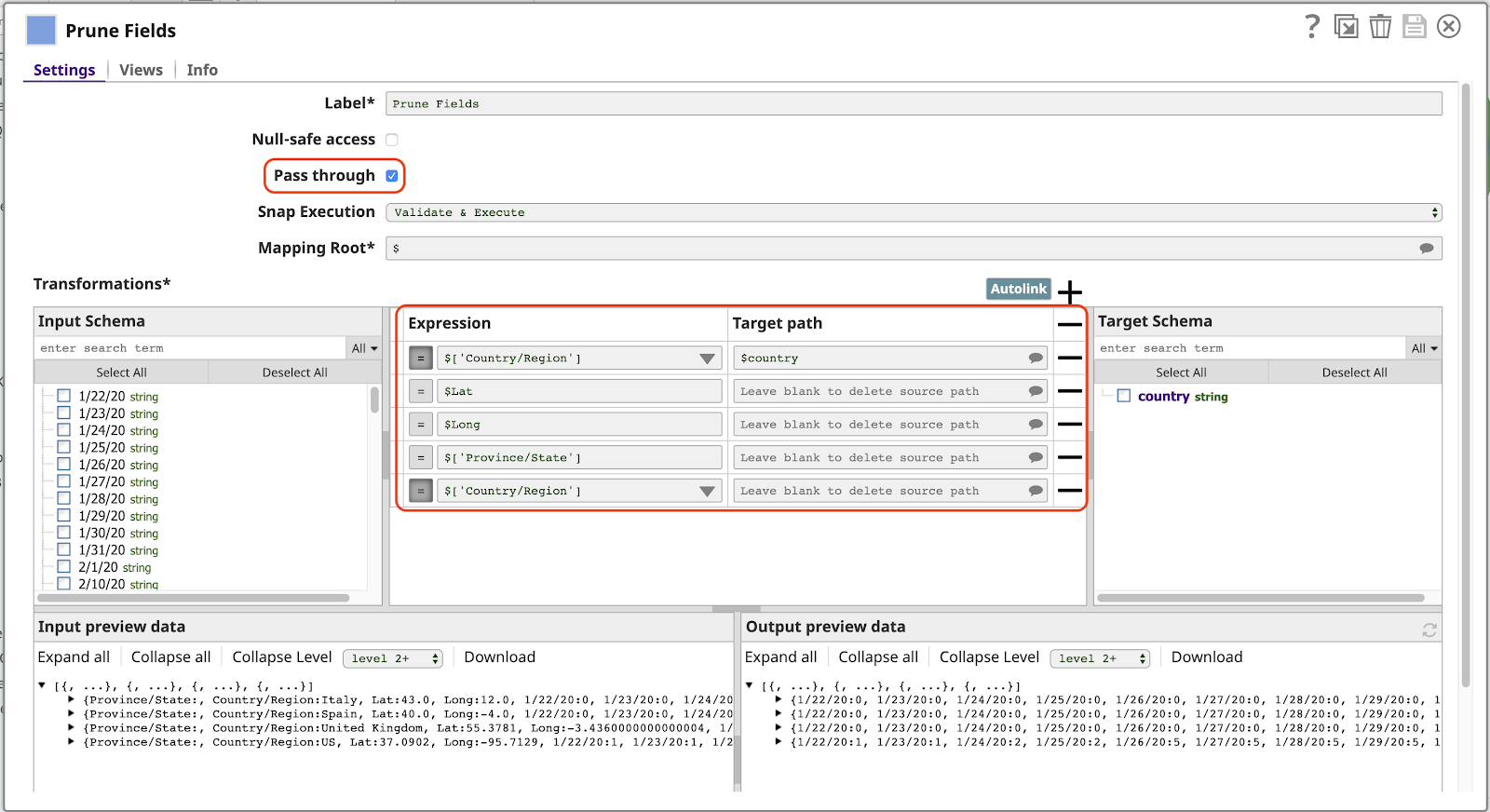
Notez ce qui suit à propos de cette configuration :
- Le Transmettre est activé. Cela permet à tous les champs de passer par défaut, sans les mapper explicitement, y compris les champs correspondant à des dates (1/22/20, etc.). Cela signifie que la sortie inclura automatiquement les nouvelles données pour les dates supplémentaires la prochaine fois que nous exécuterons ce pipeline.
- La première ligne de la section Transformations met en correspondance la valeur de l‘élément Pays/Région au nom pays dans la sortie. La présence de l‘élément / dans le nom original rend invalide l‘utilisation de l‘expression $Pays/Région. Nous devrions utiliser la syntaxe alternative plus longue $[‘Pays/Région‘]ce qui n‘est pas souhaitable. Avec ce mappage, nous pouvons nous référer à cette valeur simplement en tant que $country.
- Toute ligne comportant une Expression mais sans valeur pour Chemin cible sera supprimée de la sortie. Ceci n‘est nécessaire que lorsque Passer par est activé. Notez que nous devons avoir une ligne pour le Pays/Région sinon la valeur de ce champ apparaîtra deux fois dans le document de sortie, en tant que Pays/Région (parce que Passer par est activé) et en tant que payscomme spécifié par le premier mappage.
Voici un aperçu de ce Snap, avec seulement les champs de date et de pays à l‘extrême droite :
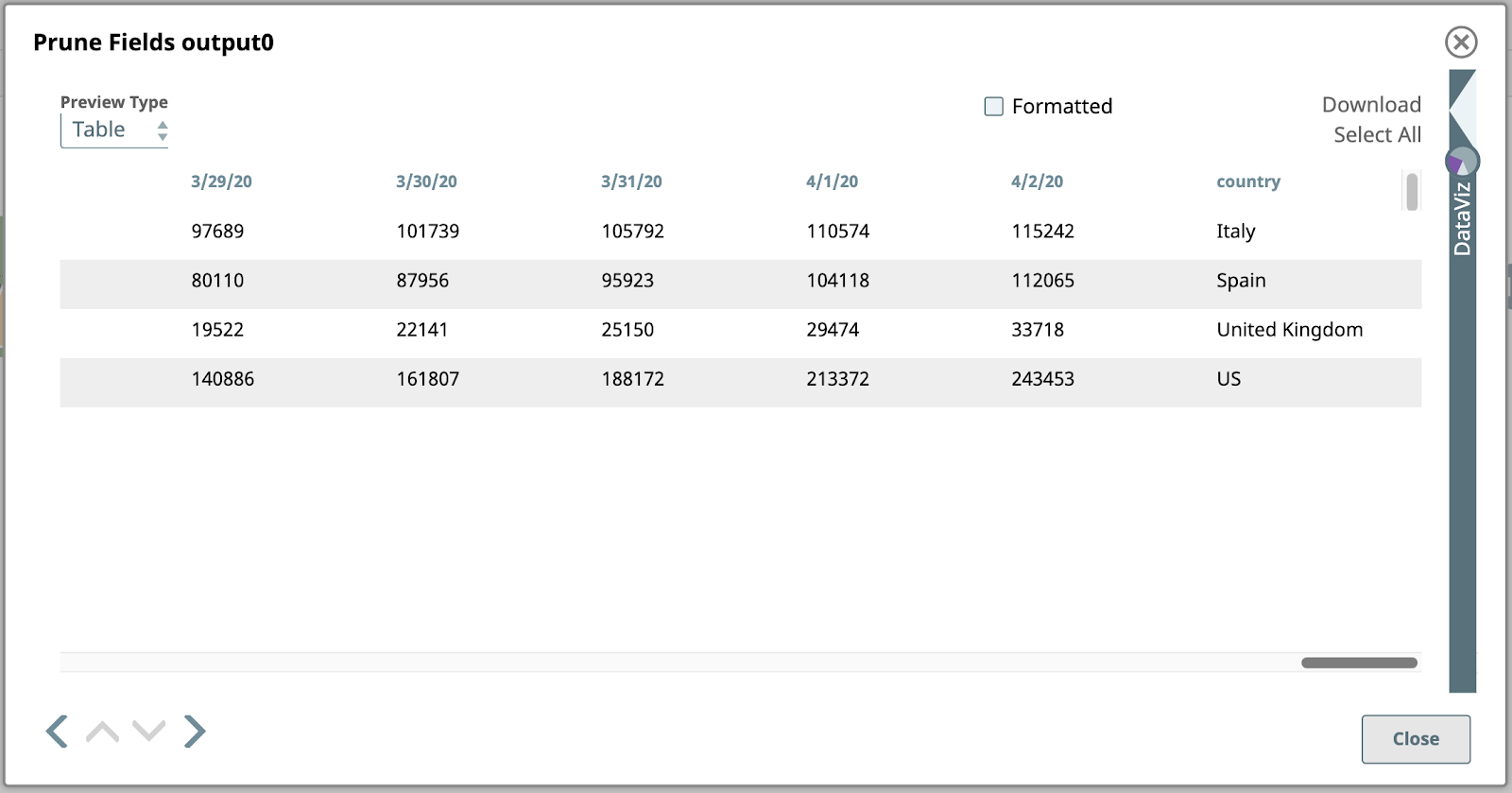
Examinons de plus près ce résultat. Chaque valeur sous une colonne de date dans ce tableau est le nombre total de cas confirmés à cette date dans le pays correspondant dans la colonne la plus à droite. Il s‘agit des données que nous voulons représenter graphiquement, mais nous devons d‘abord inverser la structure pour que les colonnes deviennent des lignes. Pour ce faire, nous devrons recourir à une cartographie et à des expressions plus avancées.
4. Mapper des colonnes sur des tableaux
Le prochain projet dans notre pipeline est un autre Mapper:
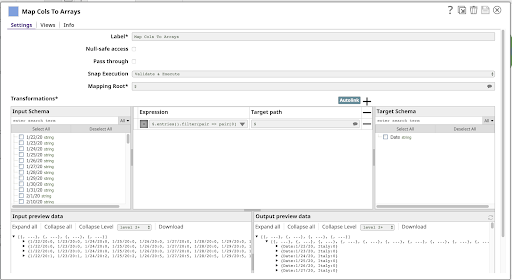
Il s‘agit d‘une expression unique :
$.entries().filter(pair => pair[0] != ‘country’) .map(pair => { Date: pair[0], [$country]: pair[1] })
Voyons ce qu‘il en est.
$.entrées()
Cette sous-expression produira un tableau des paires clé/valeur de l‘objet, où chaque paire est un sous-réseau à deux éléments : la clé et la valeur. Vous pouvez voir ce résultat à l‘aide de la sous-expression sous-expression de l‘outil de construction d‘expressions Constructeur d‘expression:

.filtre(paire => paire[0] != ‘pays‘)
Cette sous-expression filtrera le tableau de paires clé/valeur produit par entréesce qui donne un nouveau tableau de paires qui correspondent à la fonction de rappel donnée en argument. Dans la capture d‘écran ci-dessus, nous voyons les premières paires du document contenant les données américaines : ["1/22/20", "1"], ["1/23/20", "1"], ["1/24/20", "2"], etc. Si vous regardez la sortie de Prune Fields, vous pouvez voir les paires finales dans cette ligne : ["4/2/20", "243453"], ["country", "US"]. Notre fonction de filtrage correspondra à toutes les paires sauf à la dernière, où paire[0] == "pays".
.map(pair => { Date: pair[0], [$country]: pair[1] })
L‘entrée de cette map est un tableau de paires clé/valeur représentant chaque date et le nombre de cas pour cette date : ["1/22/20", "1"], ..., ["4/2/20", "243453"] pour la ligne des États-Unis.
La carte renvoie un nouveau tableau où chaque paire sera transformée par l‘expression à droite de l‘expression. renvoie un nouveau tableau où chaque paire sera transformée par l‘expression à droite de la fonction =>qui est un littéral objet ce qui donne un objet avec deux propriétés :
- Date : pair[0] résulte en une propriété nommée Date contenant la première moitié de chaque paire (la valeur de la date).
- [$country] : paire[1] résulte en une propriété dont le nom est la valeur de l'expression payset dont la valeur est la seconde moitié de chaque paire (le nombre de cas).
Pour la dernière paire de la ligne de données américaines, la fonction map produira un objet comme celui-ci :
{“Date”: “4/2/20”, “US”: “243453”}
Cette forme est beaucoup plus proche de celle dont nous avons besoin pour commencer à tracer des points sur un graphique.
Lorsque vous modifiez le Type d‘aperçu à JSON, voici l‘aperçu de la sortie de la fonction Mapper les colonnes vers les tableaux Snap :
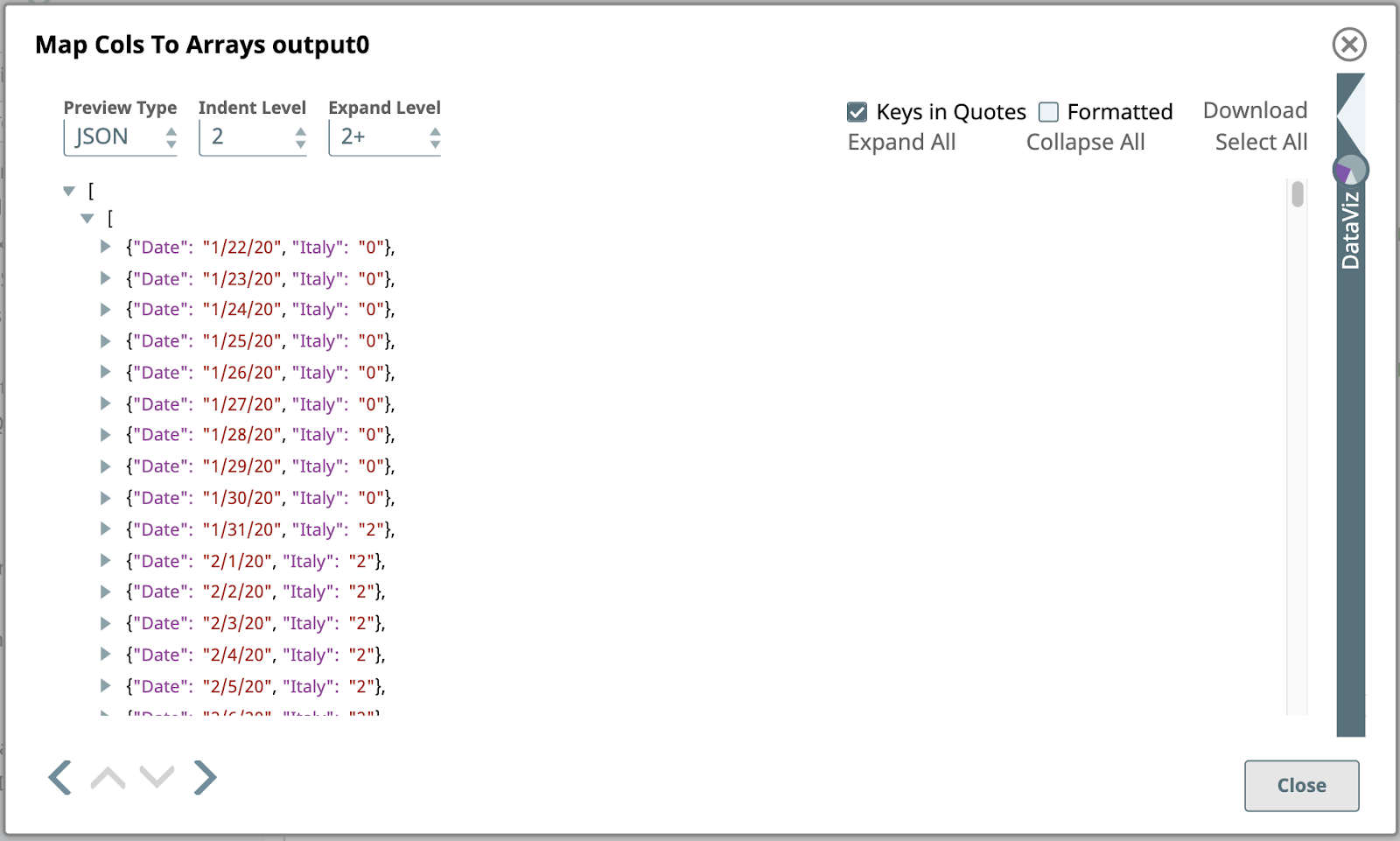
Il s‘agit d‘une vue partielle de la premier de ce Snap, créé en transformant le premier document d‘entrée contenant les données pour l‘Italie. Contrairement au document d‘entrée, qui était un simple objet JSON composé de paires nom/valeur, l‘objet de sortie est un tableau JSON d‘objets JSON.
Si vous changez le Type d‘aperçu sur Tableau et que vous cliquez sur quelques cellules de la dernière ligne, représentant ces mêmes données, vous pouvez examiner cette structure de tableau imbriqué.
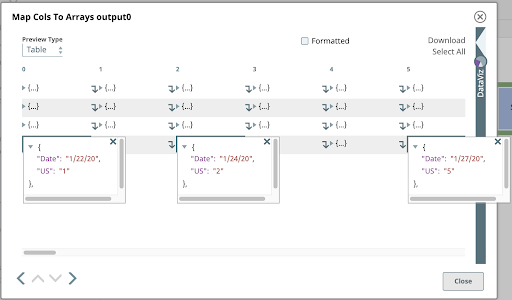
5. Fractionnement
Comme nous l‘avons vu plus haut, chaque document d‘entrée pour le Snap suivant dans notre pipeline est un tableau d‘objets. Nous voulons diviser ces tableaux en leurs objets constitutifs. Utilisez l‘outil Fractionneur JSON avec l‘option Chemin Json configuré avec le chemin référençant les éléments du tableau qui doivent être mappés en tant que documents de sortie. En cliquant sur l‘icône de suggestion à l‘extrémité droite du paramètre Chemin Json nous aide à le faire. En cliquant sur le nœud supérieur de l‘arbre, le chemin est défini comme suit $[*].
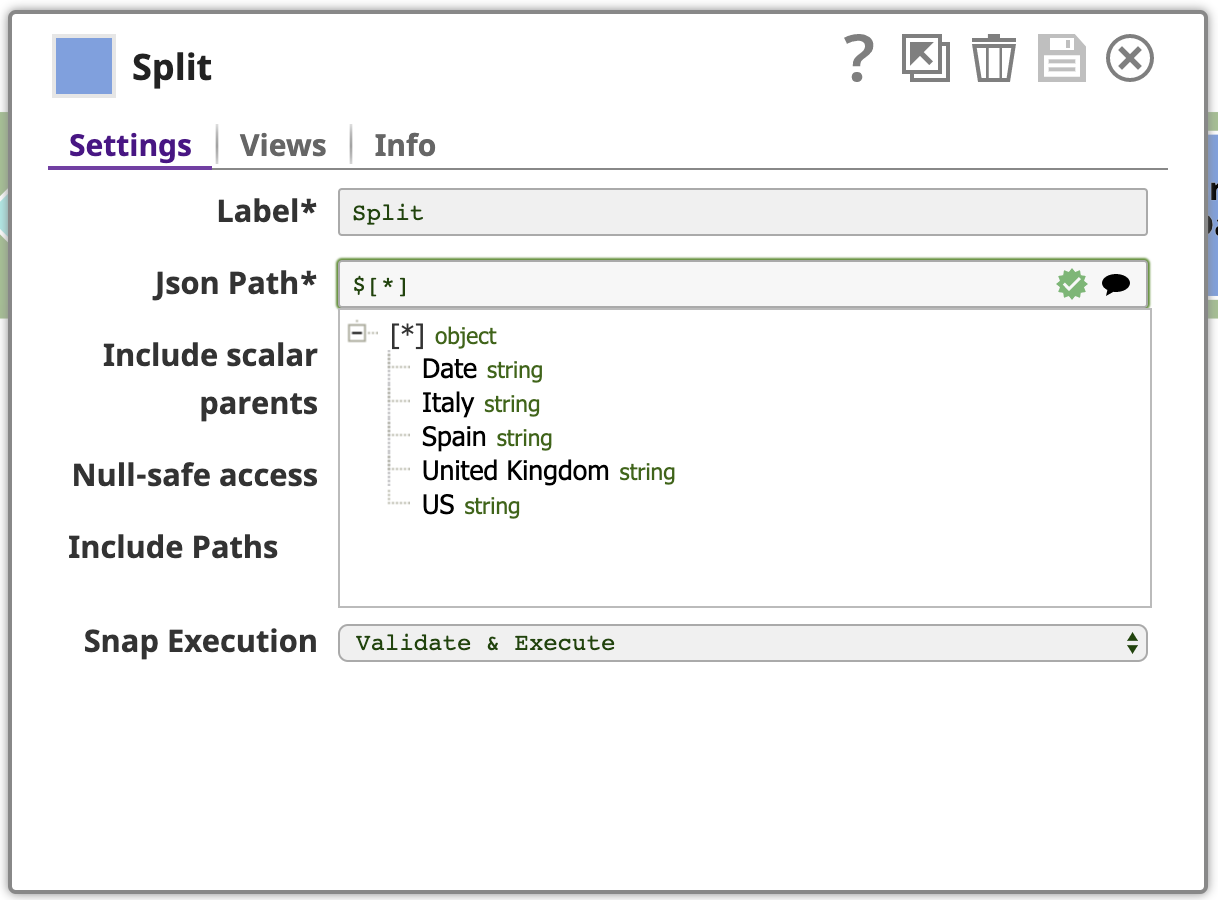
Voici la sortie du séparateur JSON pour les lignes contenant des valeurs américaines :
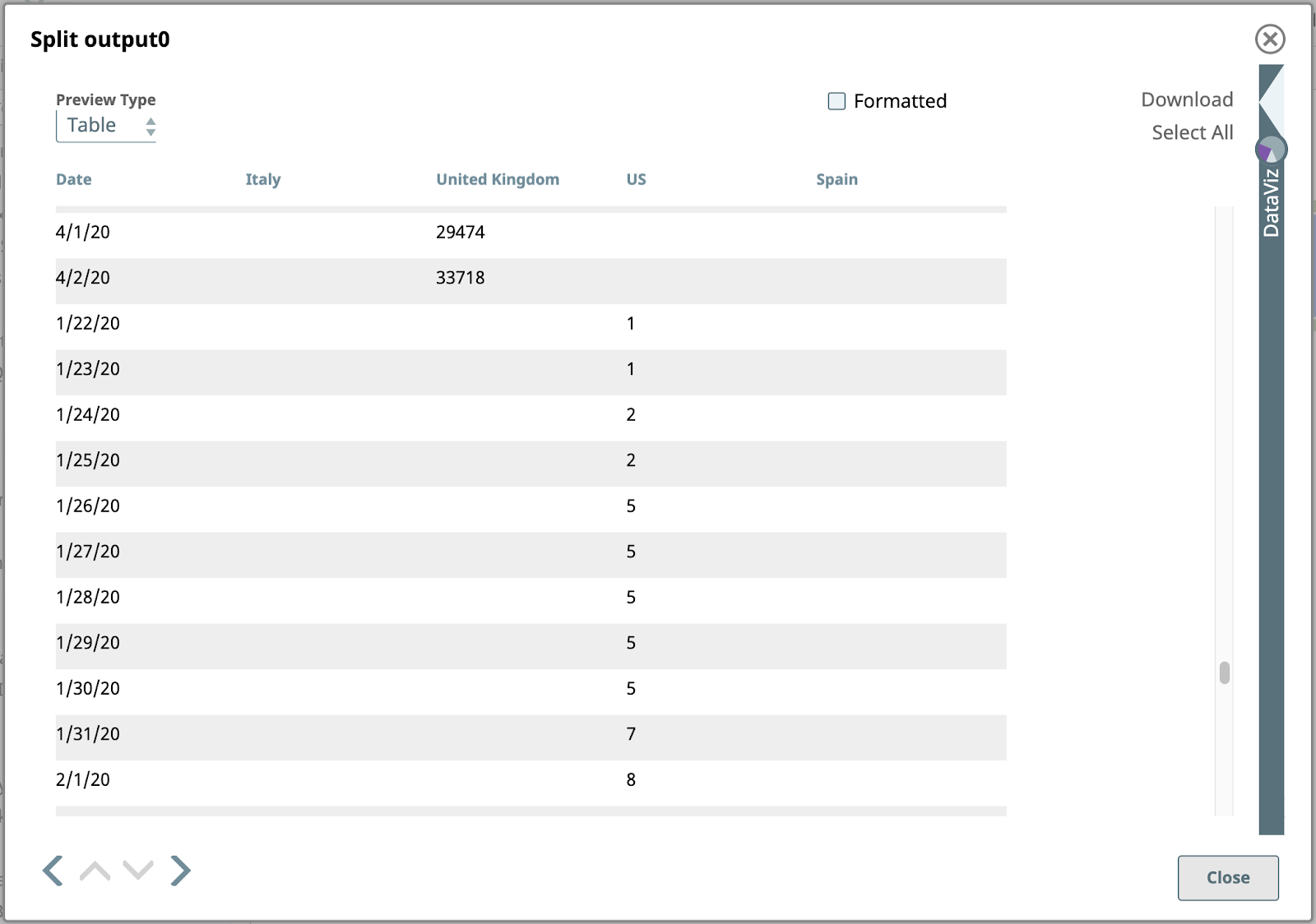
6. Trier par date
Ensuite, triez les données par date. C‘est facile avec la fonction Trier Snap, configuré comme indiqué :
Voici le résultat trié :
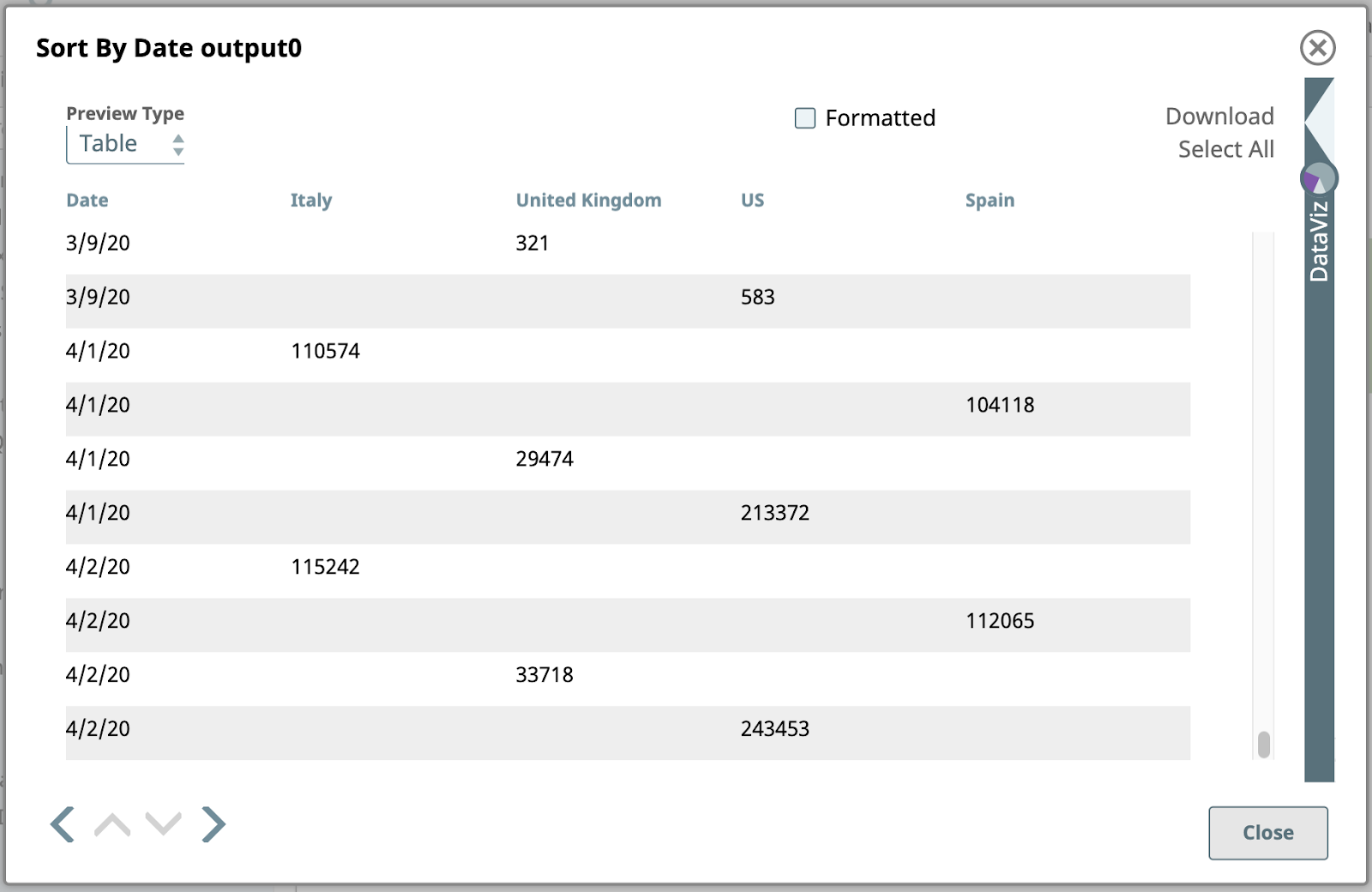
Notez que les valeurs de date sont ici de type chaîne de caractères, et qu‘elles sont donc triées par ordre alphanumérique, sans être interprétées comme des dates. Cela signifie que "3/9/20" se trouve à la fin des données pour le mois de mars. Nous pourrions nous en occuper si nous en avions besoin, mais ce n‘est pas le cas. Cette sortie est parfaitement adéquate pour les étapes restantes.
7. Regroupement par date
Maintenant que les documents sont triés par date, nous pouvons utiliser la fonction Grouper par champs pour regrouper les documents en fonction de la classification des champs. Attention, cette opération ne fonctionnera correctement que si les données sont effectivement triées.
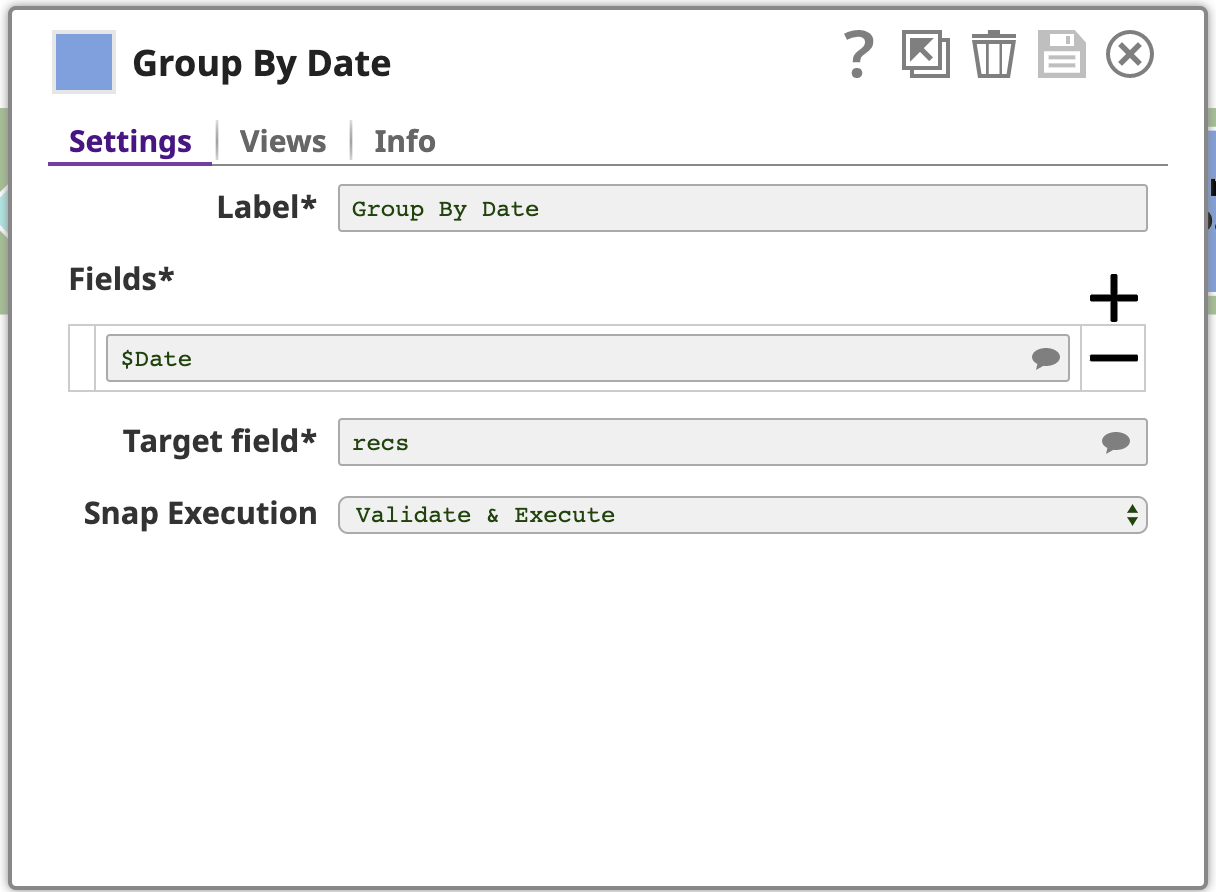
Cet instantané est configuré avec un ou plusieurs champs à regrouper, dans ce cas, juste le champ date. L‘instantané recueillera chaque groupe de documents d‘entrée ayant la même date et produira un document unique contenant les données de ces documents d‘entrée. Les données sont imbriquées dans un tableau dans le document de sortie, où le tableau est stocké dans un champ nommé par le champ Champ cible du champ cible : recs. Pour plus de clarté, prévoyons la sortie au format JSON, dont voici la dernière page :
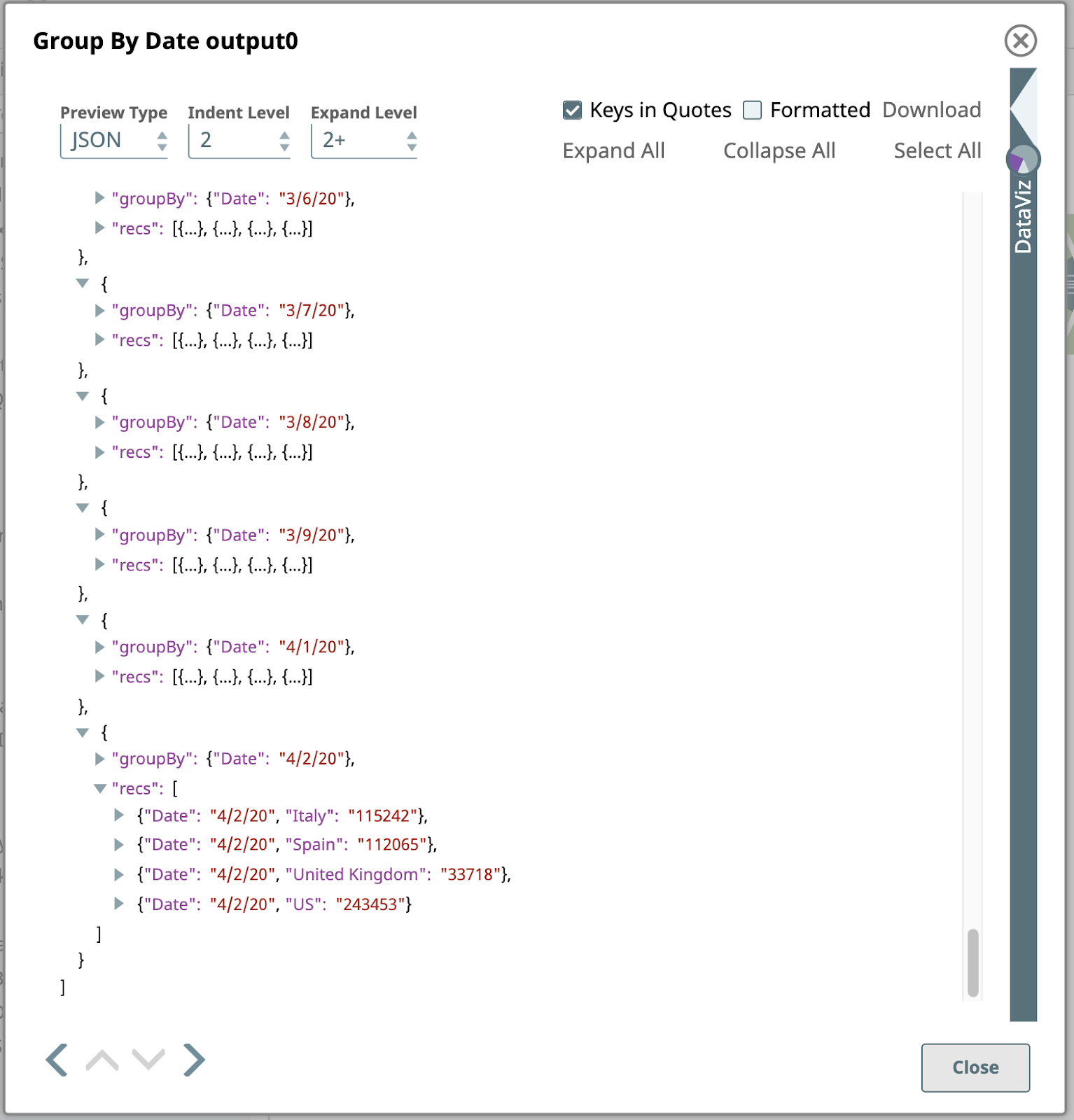
La dernière étape de ce pipeline est un autre Mapper.
8. Réduire
Vous avez déjà vu la carte du langage d‘expression utilisé dans notre dernier Mapper. Cela vous rappelle peut-être le modèle de programmation MapReduce, au cœur du traitement des "Big Data". Et bien, devinez quoi ? Le langage d‘expression SnapLogic possède également une fonction réduire que nous utiliserons dans notre dernière fonction de Mapper. Voici notre configuration (avec certains panneaux latéraux fermés) :
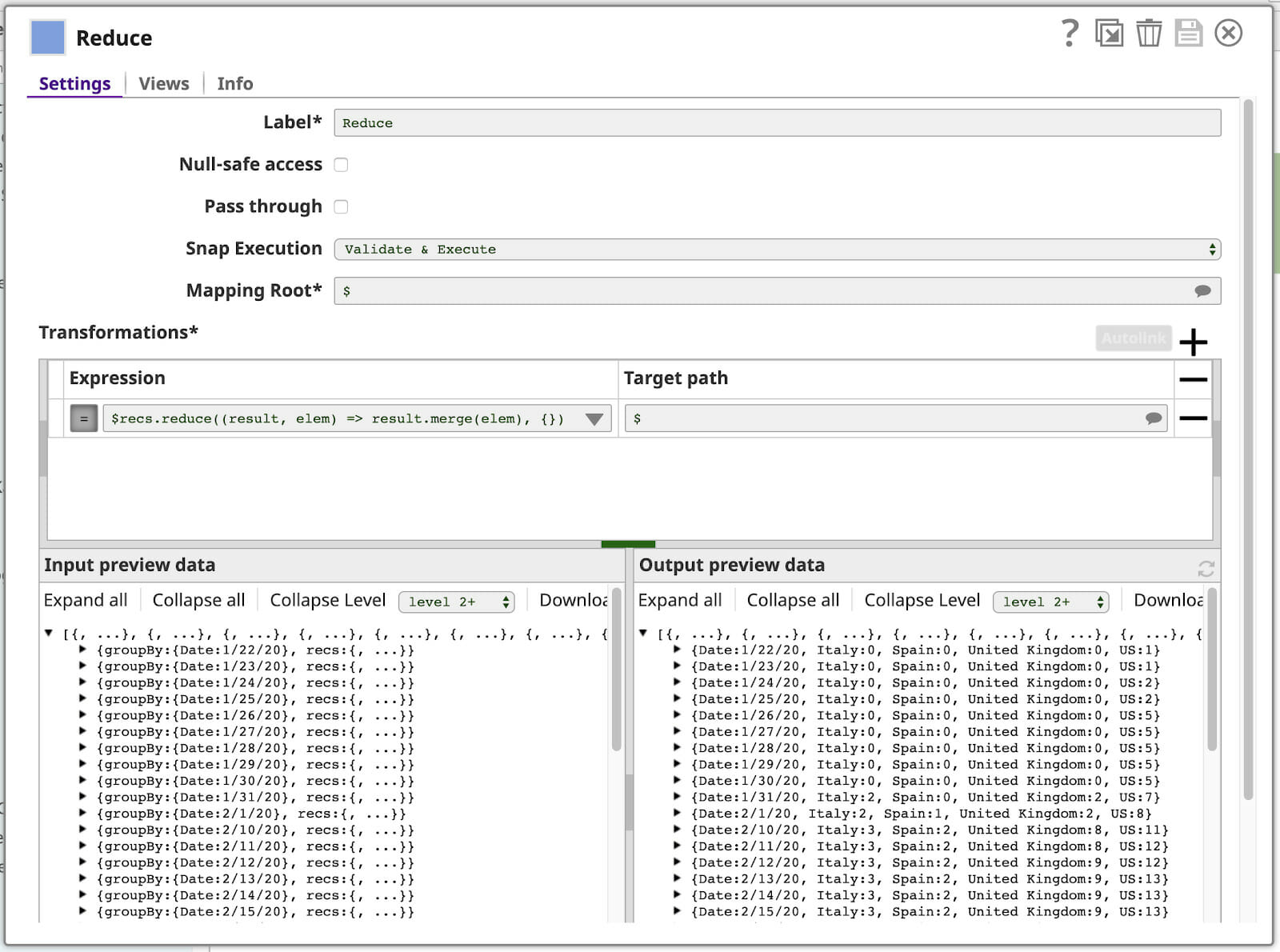
Décortiquons l‘expression :
$recs.reduce((result, elem) => result.merge(elem), {})
$recs est le tableau contenu dans chaque document d‘entrée, qui ressemble à ceci :

Il contient tout ce dont nous avons besoin pour le document de sortie.
.réduire(fonction, valeur initiale) réduit ce tableau en une seule valeur en utilisant la fonction donnée, en commençant l‘itération avec la valeur initiale donnée. Ici, cette fonction est exprimée sous la forme d‘une expression lambda JavaScript :
(result, elem) => result.merge(elem)
Les paramètres de la fonction sont nommés sur le côté gauche de l‘attribut => résultat et elem. L‘expression de droite est utilisée pour calculer le résultat de la fonction. La fonction réduire appellera cette fonction une fois pour chaque élément du tableau, le résultat de chaque appel servant d‘entrée à l‘appel suivant via la fonction résultat et la valeur de l‘élément suivant du tableau via le paramètre elem paramètre. La fonction valeur initiale donnée à réduire est la valeur du paramètre résultat à utiliser pour la première itération. Dans ce cas, nous utilisons la méthode merge pour fusionner ce tableau en un seul objet.
Cela sera plus facile à comprendre si nous montrons chaque itération :
| Itération | Entrée: résultat | Entrée: elem | Sortie: result.merge(elem) |
| 1 | {} (la valeurinitiale) | {“Date”, “4/20/20”, “Italy”: “115242”} | {“Date”, “4/20/20”, “Italy”: “115242”} |
|
2 |
{“Date”, “4/20/20”, “Italy”: “115242”} | {“Date”, “4/20/20”, “Spain”: “112065”} | {“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”} |
|
3 |
{“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”} | {“Date”, “4/20/20”, “United Kingdom”: “33718”} | {“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”, “United Kingdom”: “33718”} |
|
4 |
{“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”, “United Kingdom”: “33718”} | {“Date”, “4/20/20”, “US”: “243453”} | {“Date”, “4/20/20”, “Italy”: “115242”, “Spain”: “112065”, “United Kingdom”: “33718”, “US”: “243453”} |
À chaque itération de réduireun autre élément du tableau est fusionné dans l‘objet de sortie. Chaque élément a la même valeur Date, qui reste donc inchangée après chaque itération, mais nous obtenons un seul objet contenant tous les cas de pays pour cette date.
Vous pouvez voir les documents de sortie résultants dans la section Données de prévisualisation de la sortie dans le coin inférieur droit de la fenêtre Réduire Mapper illustré ci-dessus.
Visualiser les données
Prévisualisons la sortie de la fonction Réduire de l‘étape précédente.
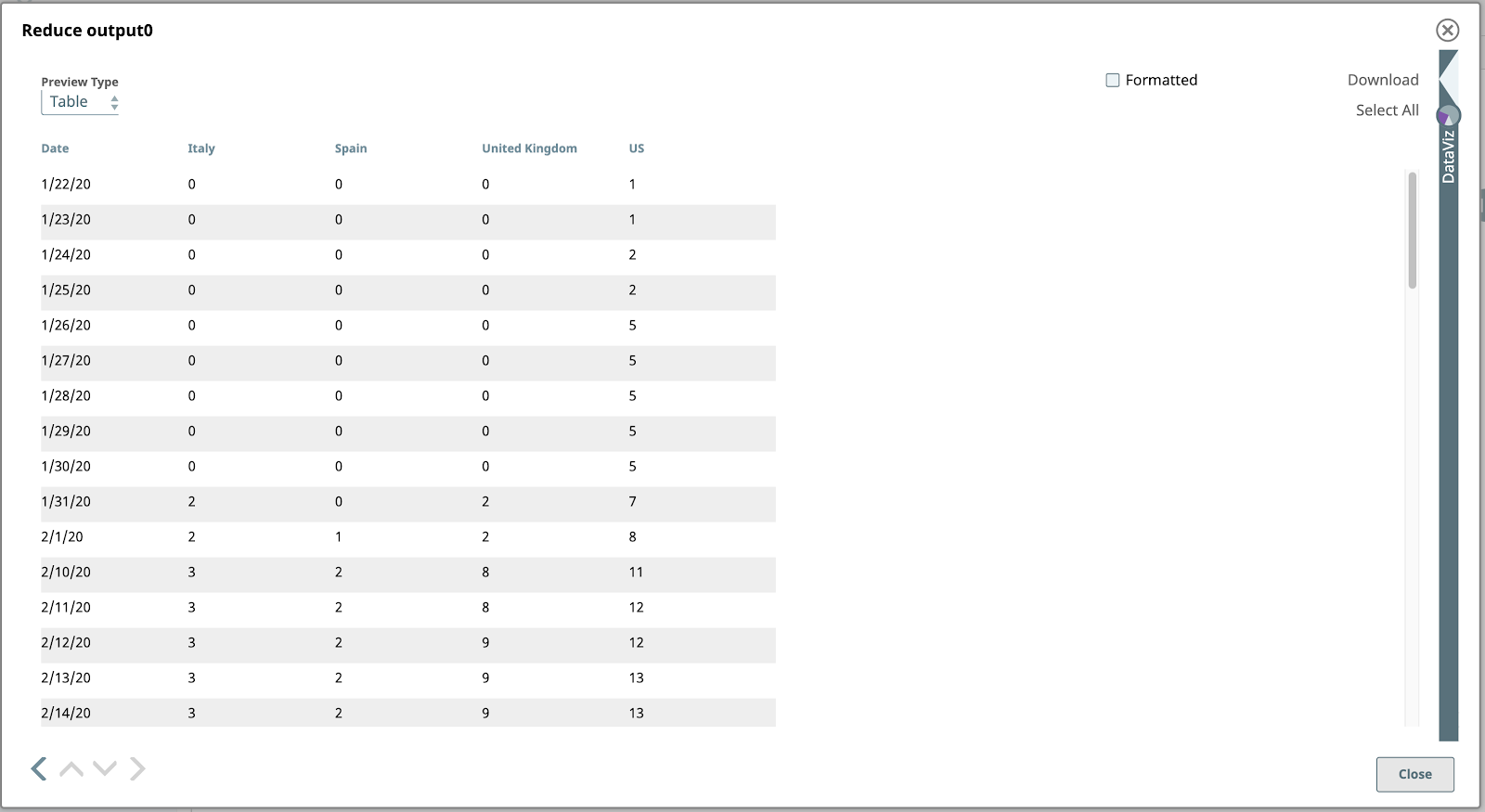
Bingo ! Nos données se prêtent enfin à la création d‘un graphique. Ouvrons la fenêtre DataViz en cliquant sur la flèche pointant vers la gauche, juste au-dessus de l‘étiquette DataViz, sur le côté droit de la fenêtre. Le panneau s‘agrandit pour occuper la moitié droite de la fenêtre.
Pour afficher le graphique linéaire final, définissez le paramètre Type de graphique à "Graphique linéaire - Date comme axe X", l‘axe X à "Date", et Clé à visualiser aux noms des pays que vous souhaitez visualiser.
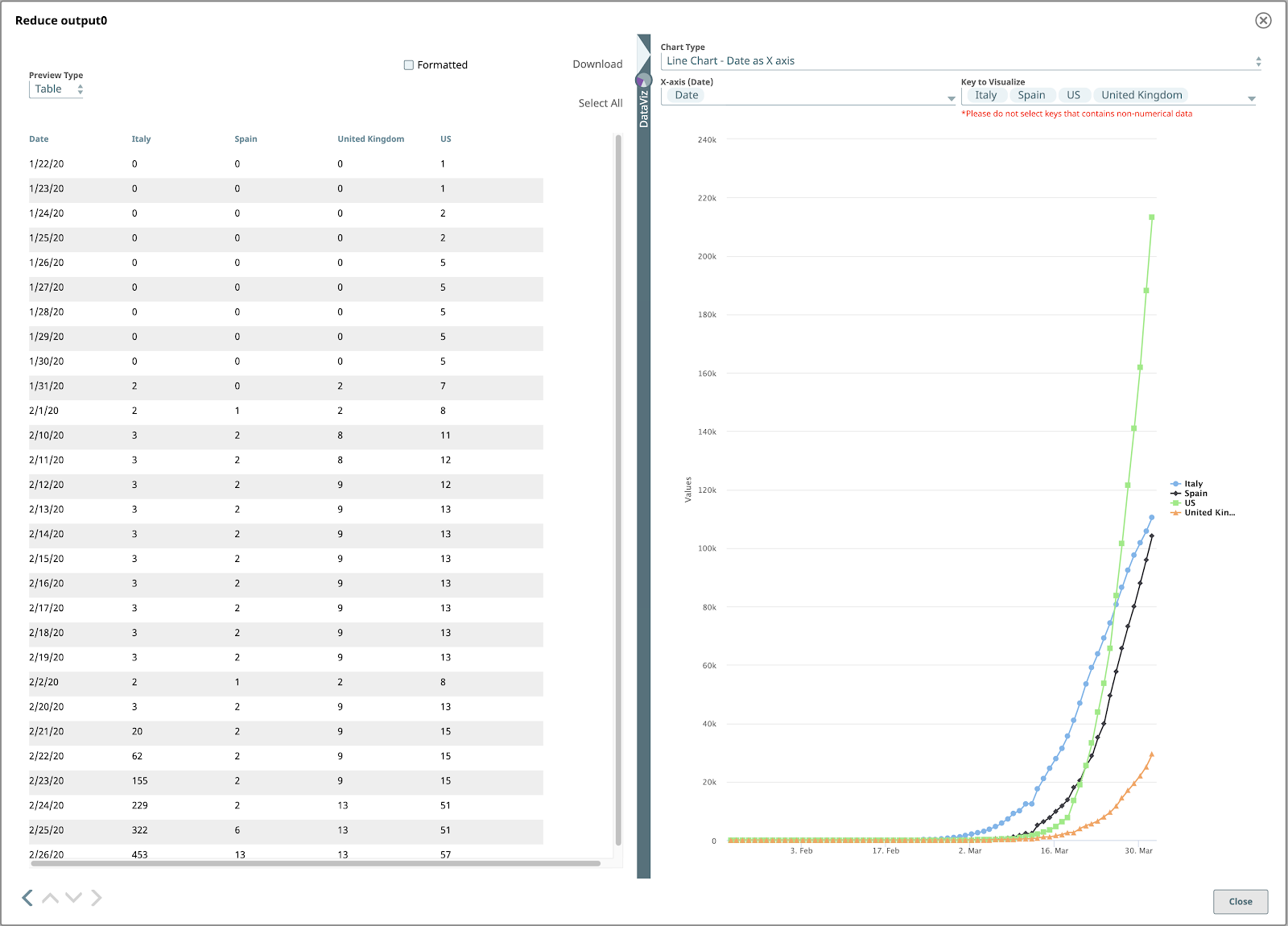
J‘espère que ce blog vous a aidé à mieux comprendre les puissantes fonctionnalités de SnapLogic plateforme qui vous permettent de lire et de visualiser les données COVID-19.
Je vous souhaite bonne chance, à vous et aux vôtres, dans cette période difficile.
Restez en bonne santé, restez en sécurité !







