





Il Task Execute Snap di SnapLogic è stato introdotto nella versione dell'estate 2014. Nella versione dell'autunno 2014, lo snap Task Execute è stato migliorato con l'aggiunta della compressione (trasparente) e della propagazione del tipo di dati. Questo snap è simile allo snap ForEach (in cui viene lanciata una singola esecuzione della pipeline per ogni documento di dati in arrivo), ma lo snap Task Execute:
- invia l'intero documento di input
- può aggregare un certo numero di righe di input da trasmettere alla pipeline di destinazione.
- invia le informazioni sul tipo di dati SnapLogic alla destinazione, preservando i tipi di data/ora, numerici e di stringa.
- comprime i dati quando vengono passati alla pipeline di destinazione per ottimizzare l'uso della rete e della memoria.
La pipeline di destinazione deve essere configurata per ricevere i dati di input (nel caso di POST dei dati) o per produrli (nel caso di GET), in modo simile a una sottopiplina, sebbene questa sia ancora più libera di accoppiarsi. La pipeline di destinazione sarà invocata una volta per ogni lotto di dati in ingresso. Vediamo alcuni dettagli. Ho creato tre esempi:
- Tipo POST, in cui si inviano i dati alla pipeline di destinazione e non ci si aspetta alcuna risposta.
- Tipo GET, in cui si ottiene l'output o un'attività eseguita in remoto
- Tipo POST-e-GET, in cui si combinano il payload in entrata e il payload recuperato
Esempio 1: Tipo POST
Per il mio primo esempio, ho creato una semplice pipeline per consumare i dati, aspettandomi che venissero inviati come payload alla richiesta URL, composta semplicemente da JSON Formatter e File Writer, anche se avrebbe potuto essere qualsiasi altro Snap con un input di documento:
Poi ho creato un task attivato nel Manager per invocare la pipeline di destinazione:

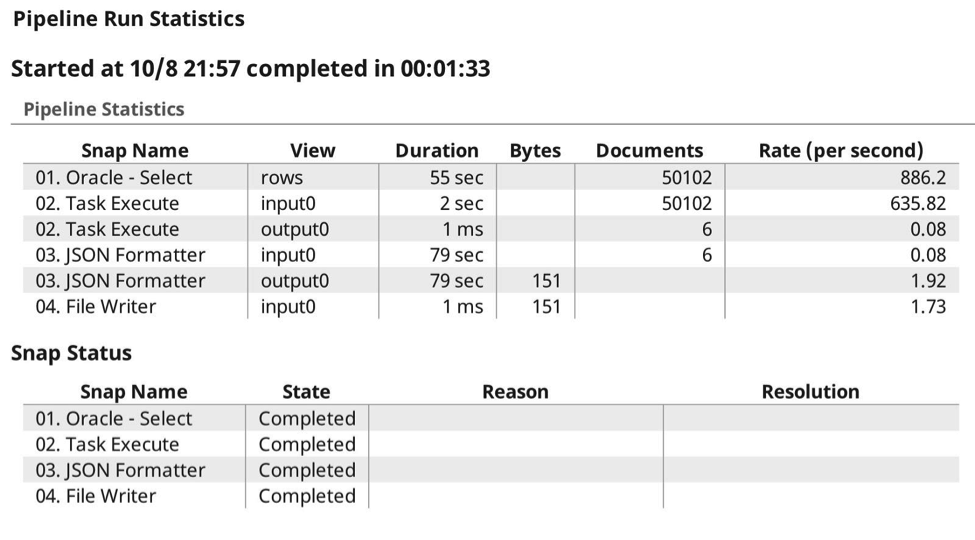
E ho creato una pipeline per inviare i dati, che in questo caso sto selezionando dal mio database Oracle preferito, limitandoli a 50102 righe (un numero arbitrario). Come si vede, ho configurato il task Execute Snap in modo che utilizzi il task che ho definito in precedenza, con una dimensione di batch di 10.000 righe, il che implica che dovrebbe effettuare 6 chiamate, 10.000 x 5, 1 x 102. Ogni richiesta viene effettuata in modo sincrono. Poiché tutto questo avviene all'interno della stessa organizzazione, Snap gestisce l'autenticazione e l'autorizzazione per voi.
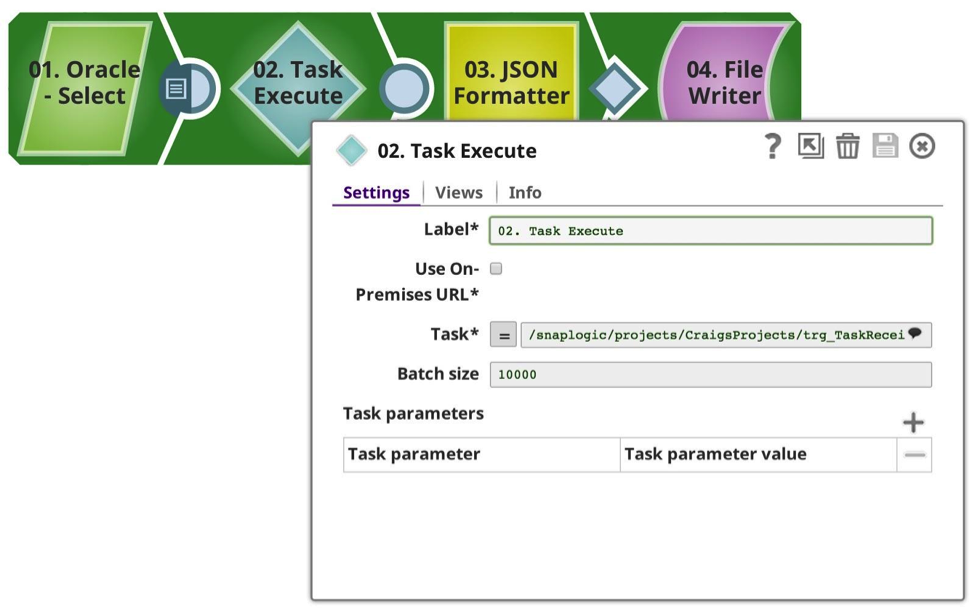
L'attività viene selezionata dall'elenco a discesa, che introduce i metadati disponibili, mostrando le pipeline attivabili sia dal progetto corrente che da quello condiviso. (Nota: se l'opzione Usa URL on-premises è selezionata, verranno mostrate solo le pipeline in cui è disponibile un URL on-premises, cioè in esecuzione in un Groundplex). Se questa opzione è selezionata e gli Snaplex sono tutti on-premises, nessun dato uscirà attraverso il firewall; tutto rimarrà protetto tra i nodi a livello locale.
La dimensione del batch può essere regolata in base alle proprie esigenze, bilanciando il carico e l'utilizzo della memoria. Ogni invocazione della pipeline comporta un certo overhead per la preparazione, l'esecuzione e la registrazione, che deve essere considerato se si utilizza un numero basso di righe per batch. Maggiore è il numero di righe per batch, maggiore è il consumo di memoria.
Quando eseguo la pipeline, i dati vengono trasmessi dall'origine, in questo caso nel task execute, che con la dimensione del batch impostata a 10.000, si aggrega in memoria finché non completa il flusso di input o raggiunge la dimensione del batch, quando invia i dati alla pipeline di destinazione con il payload dei dati.
Ecco il log dell'esecuzione, in cui si possono vedere le 6 chiamate previste, in cui sono stati passati i dati al task di destinazione, come previsto, la compressione avviene automaticamente in quanto sa di essere in grado di gzippare il contenuto e preservare i tipi di dati.
L'output del task execute è solo il codice di ritorno HTTP fornito dalla pipeline di destinazione:

La visualizzazione della pipeline nel Dashboard è la seguente:

Esempio 2: Tipo GET
In questo esempio, ho modificato la prima pipeline per rimuovere la vista di input e limitarmi a eseguire il task di destinazione e a ricevere i suoi dati di output.
In questo caso, la dimensione del batch è irrilevante. Successivamente, ho cambiato la pipeline chiamata in un produttore di dati:
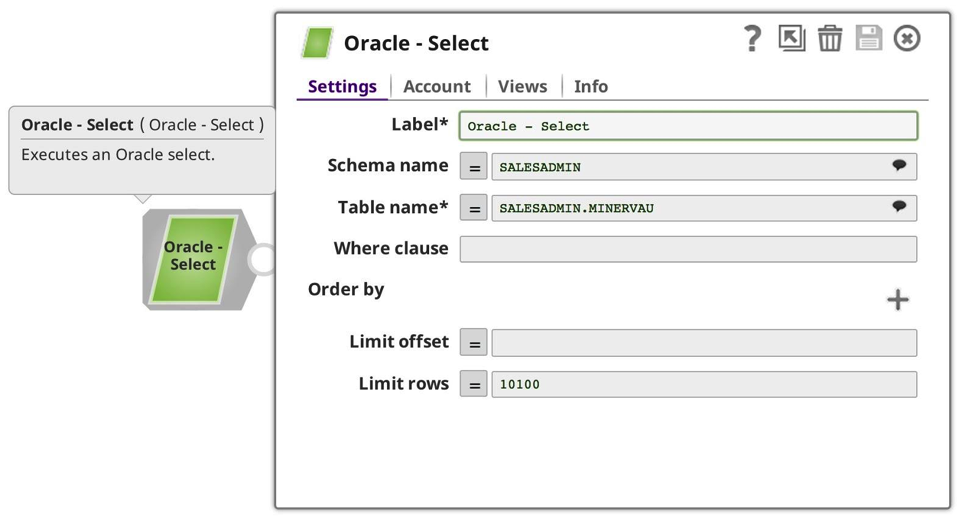
Questa volta, il risultato è un insieme più piccolo di dati provenienti dal mio database Oracle. Successivamente, ho creato un nuovo task, questa volta per la mia pipeline più piccola e produttrice:
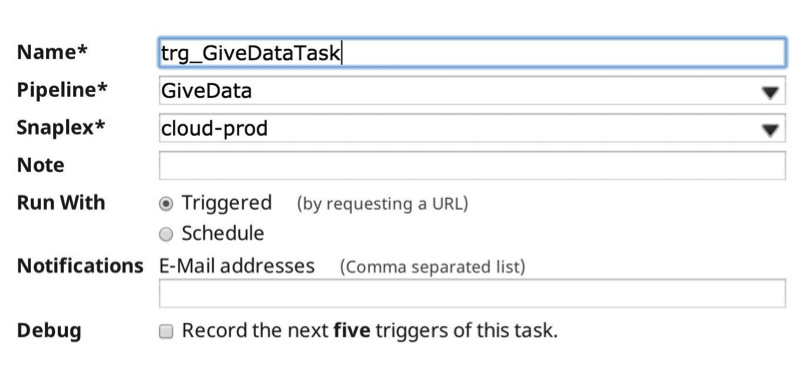
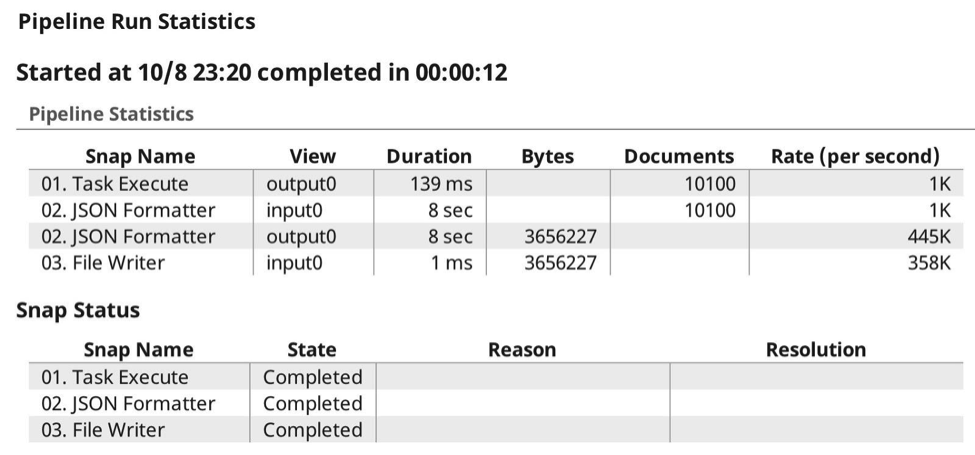
Ora, quando eseguo la pipeline, le statistiche di esecuzione sono le seguenti:
E dal cruscotto la visualizzazione della pipeline è la seguente:
![]()
Esempio 3: tipo POST e GET
La pipeline Eseguito può anche essere un produttore di dati. In questo esempio, sto usando lo stesso tipo di pipeline di chiamata, anche se questa volta ho limitato la SELECT di Oracle a 52 righe di dati. La pipeline di guida è molto simile:
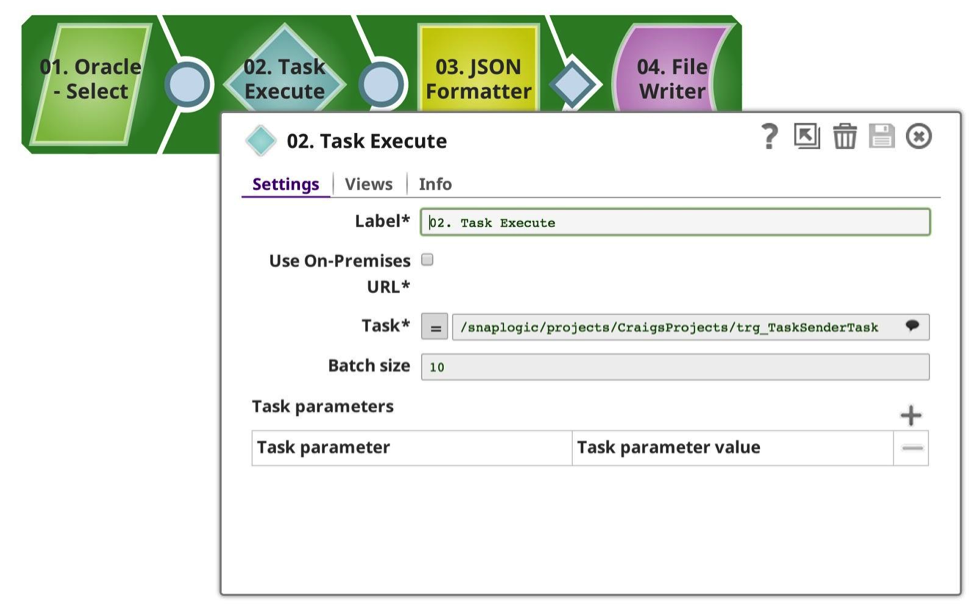
Si noti che ho un URL di destinazione diverso e una dimensione del batch molto più bassa. Nella pipeline Executed questa volta si può vedere che ha un flusso di input, che prenderà il payload in entrata, e in questo caso i dati doppi, copiando e unendo il risultato. Poi ha un output non terminato, che sarà restituito al chiamante.
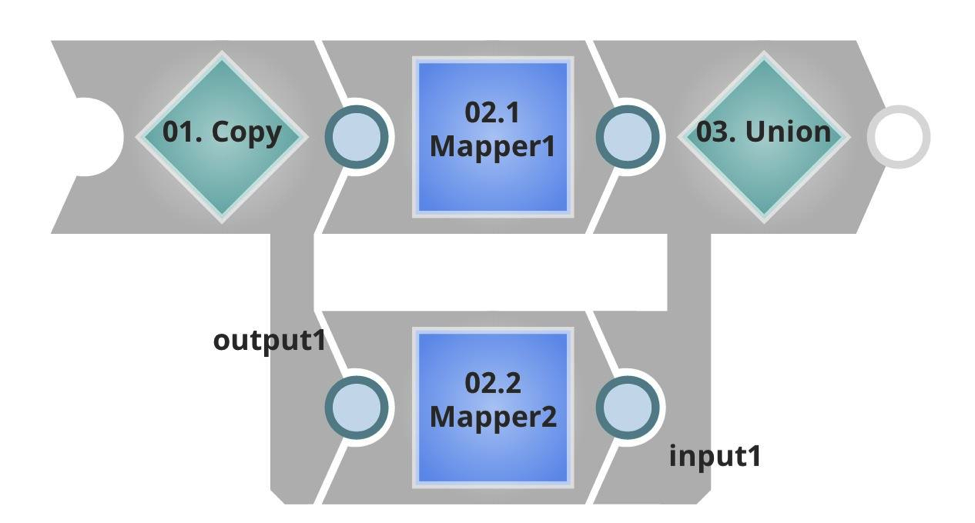
Anche in questo caso ho creato un'attività in SnapLogic Integration Cloud Manager:

Ora ho il set completo; l'idea di questa configurazione è che seleziono un insieme di dati dal mio database Oracle, in questo caso 52 righe, che poi invio in lotti di 10 alla pipeline di destinazione, traendo il vantaggio di passare i tipi di dati, la compressione, ecc. come descritto in precedenza. Ma questa volta otterrò un set di risultati in streaming, sempre preservando i tipi di dati e i formati.
Ecco le statistiche di esecuzione in tempo reale:
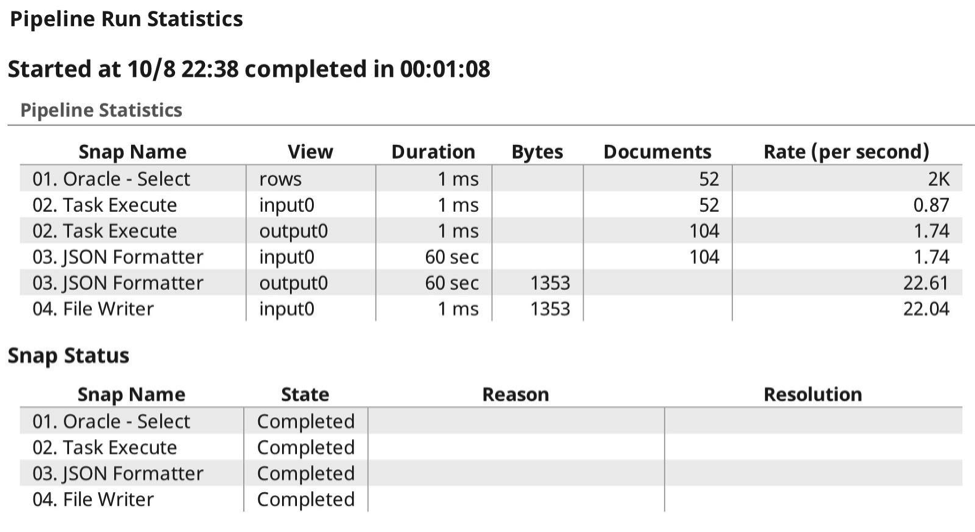
Come si può vedere, questa volta ho sia inviato che ricevuto i payload, permettendo a SnapLogic Elastic Integration Platform di gestire l'autenticazione, l'autorizzazione e la compressione del payload. Non c'è bisogno di intestazioni o altre configurazioni aggiuntive. Qui si vede l'esecuzione dalla visualizzazione della pipeline della dashboard:

Sintesi
In sintesi, il Task Execute Snap consente di passare batch di dati da e verso le pipeline di destinazione, aggregando, autenticando e comprimendo automaticamente il payload dei dati e attendendo il completamento. Per ulteriori best practice, suggerimenti e trucchi di SnapLogic, consultate i nostri webinar TechTalk e le registrazioni.




