





Le Snap d‘exécution des tâches de SnapLogic a été introduit dans la version de l‘été 2014. Dans la version Fall 2014, la Task Execute Snap a été améliorée avec l‘ajout de la compression (transparente) et de la propagation du type de données. Ce Snap est similaire au Snap ForEach, où une seule exécution du pipeline est déclenchée pour chaque document de données entrant), mais le Snap Task Execute :
- envoie l‘ensemble du document d‘entrée
- peut agréger un certain nombre de lignes d‘entrée pour les acheminer vers le pipeline cible.
- envoie les informations de type de données SnapLogic à la cible, en préservant les types date/heure, numérique et chaîne.
- compresse les données lorsqu‘elles sont transmises au pipeline cible afin d‘optimiser l‘utilisation du réseau et de la mémoire
Le pipeline cible doit être configuré pour recevoir les données d‘entrée (dans le cas d‘un POST) ou pour produire les données (dans le cas d‘un GET), un peu comme un sous-pipeline, bien que le couplage soit encore plus lâche. Le pipeline cible sera invoqué une fois pour chaque lot de données d‘entrée. Entrons dans les détails. J‘ai créé trois exemples :
- Type POST, où nous envoyons des données au pipeline cible et n‘attendons aucune réponse.
- Type GET, où nous obtenons le résultat ou une tâche exécutée à distance
- Type POST et GET, où nous combinons la charge utile entrante et la charge utile récupérée.
Exemple 1 : Type POST
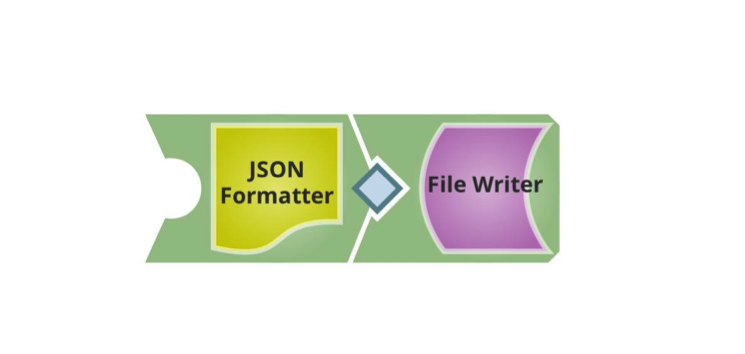
Pour mon premier exemple, j‘ai créé un pipeline simple pour consommer les données, en m‘attendant à ce qu‘elles soient envoyées par POST, en tant que charge utile de la requête URL, composée uniquement du JSON Formatter et d‘un File Writer, bien qu‘il aurait pu s‘agir de n‘importe quel autre Snap avec un document en entrée :
J‘ai ensuite créé une tâche déclenchée dans le gestionnaire pour invoquer le pipeline cible :

Et j‘ai créé un pipeline pour envoyer les données, dans ce cas je les sélectionne à partir de ma base de données Oracle préférée, en les limitant à 50102 lignes (un nombre arbitraire). Comme vous le voyez, j‘ai configuré la tâche Execute Snap pour qu‘elle utilise la tâche que j‘ai définie plus tôt, avec une taille de lot de 10 000 lignes, ce qui implique qu‘elle devrait faire 6 appels, 10 000 x 5, 1 x 102. Chaque requête est effectuée de manière synchrone. Notez que comme tout cela se passe au sein de la même organisation, le Snap s‘occupe de l‘authentification et de l‘autorisation pour vous.
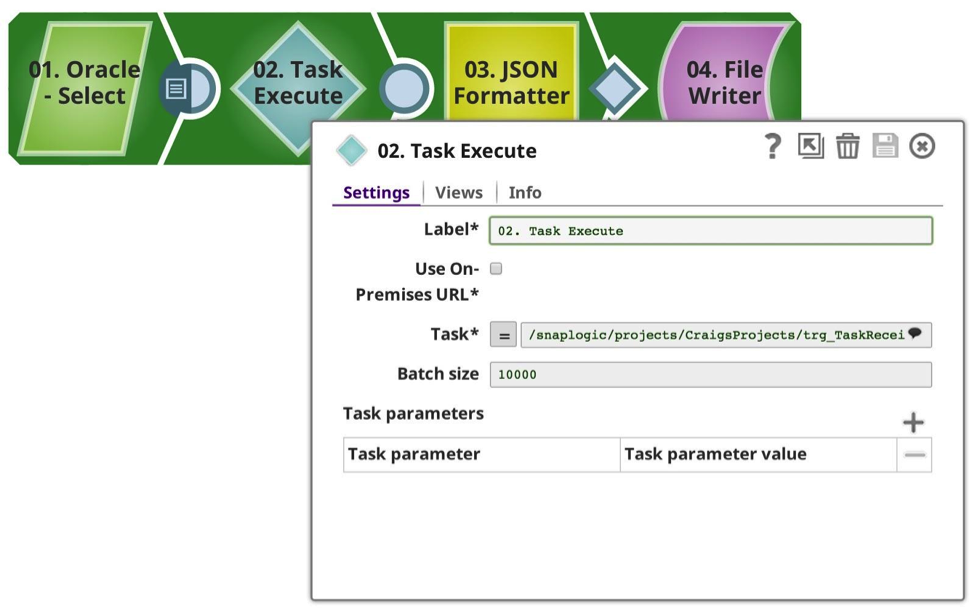
La tâche est sélectionnée dans la liste déroulante, ce qui permet d‘introspecter les métadonnées disponibles et d‘afficher les pipelines déclenchables du projet actuel et des projets partagés. (Remarque : si l‘option Utiliser l‘URL sur site est cochée, seuls les pipelines pour lesquels une URL sur site est disponible seront affichés, c‘est-à-dire ceux qui s‘exécutent dans un Groundplex). Si cette option est sélectionnée et que les Snaplex sont tous sur site, aucune donnée ne sortira par le pare-feu ; toutes les données resteront sécurisées entre les nœuds au niveau local.
La taille du lot peut être adaptée à vos besoins, en équilibrant la charge et l‘utilisation de la mémoire. La préparation, l‘exécution et l‘enregistrement de chaque invocation de pipeline entraînent une certaine surcharge, qui doit être prise en compte si vous utilisez un faible nombre de lignes par lot. Plus le nombre de lignes par lot est élevé, plus la consommation de mémoire est importante.
Lorsque j‘exécute le pipeline, les données sont acheminées depuis la source, dans ce cas dans la tâche exécuter, qui, avec une taille de lot fixée à 10 000, est agrégée en mémoire jusqu‘à ce qu‘elle complète le flux d‘entrée ou qu‘elle atteigne la taille du lot, puis elle envoie les données au pipeline cible avec la charge utile des données.
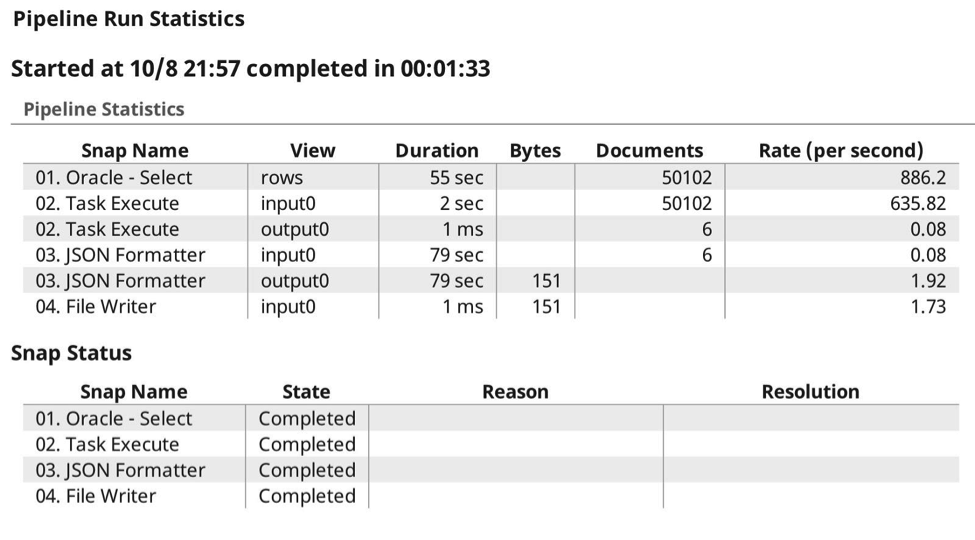
Voici le journal d‘exécution, où vous pouvez voir les 6 appels prévus, où il a transmis les données à la tâche cible, comme prévu, la compression s‘effectuant automatiquement car il sait qu‘il est capable de gzip le contenu et de préserver les types de données.
Le résultat de l‘exécution de la tâche est simplement le code de retour HTTP donné par le pipeline cible :

L‘affichage du tableau de bord des pipelines se présente comme suit :

Exemple 2 : Type GET
Dans cet exemple, j‘ai modifié le premier pipeline pour supprimer la vue d‘entrée, et simplement exécuter la tâche cible et recevoir ses données de sortie.
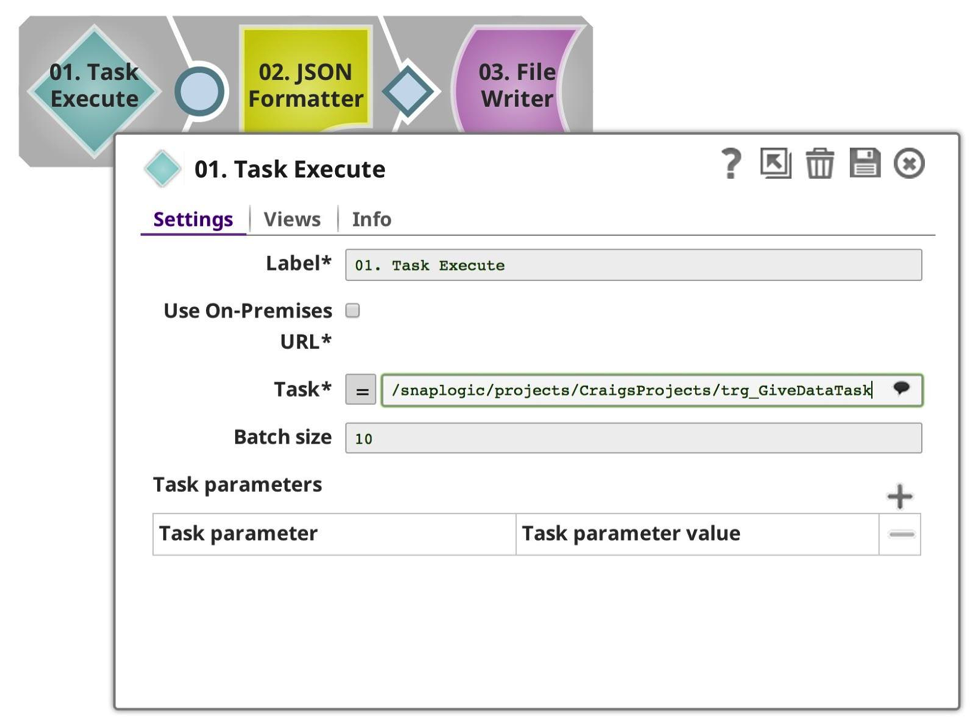
Dans ce cas, la taille du lot n‘est pas pertinente. Ensuite, j‘ai changé le pipeline appelé pour être mon producteur de données :
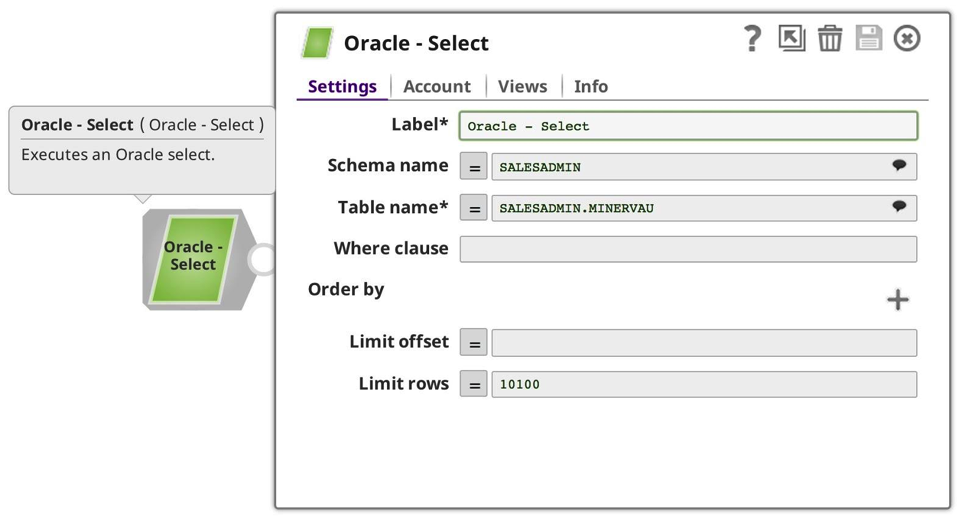
Cette fois, le résultat est un ensemble de données plus petit provenant de ma base de données Oracle. Ensuite, j‘ai créé une nouvelle tâche, cette fois vers mon pipeline de producteurs plus petit :
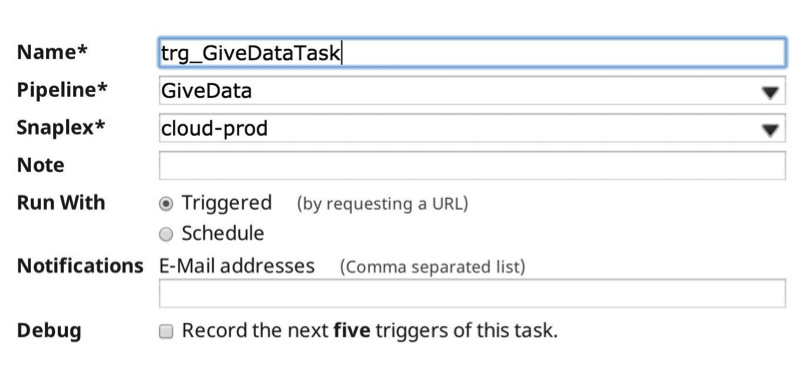
Maintenant, lorsque j‘exécute le pipeline, les statistiques d‘exécution sont les suivantes :
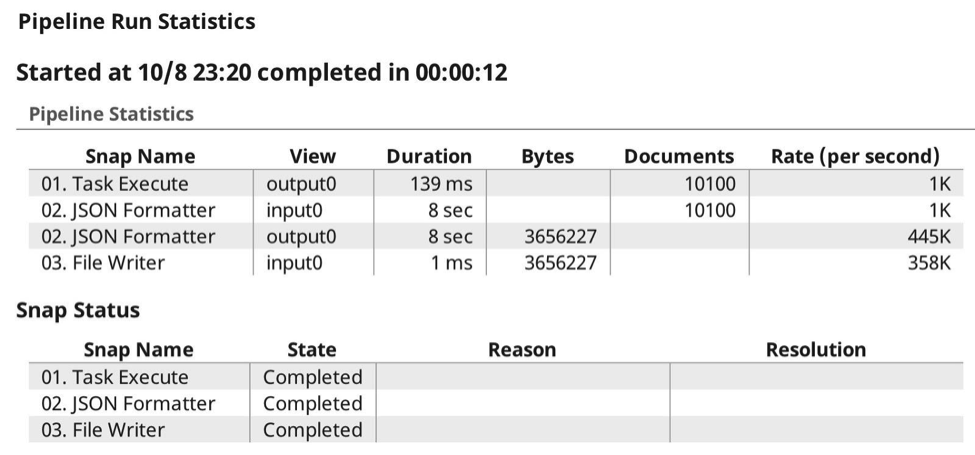
Dans le tableau de bord, l‘affichage des pipelines est le suivant :
![]()
Exemple 3 : Type POST et GET
Le pipeline exécuté peut également être un producteur de données. Dans cet exemple, j‘utilise le même type de pipeline d‘appel, mais cette fois-ci, j‘ai limité le SELECT Oracle à 52 lignes de données. Le pipeline d‘entraînement est remarquablement similaire :
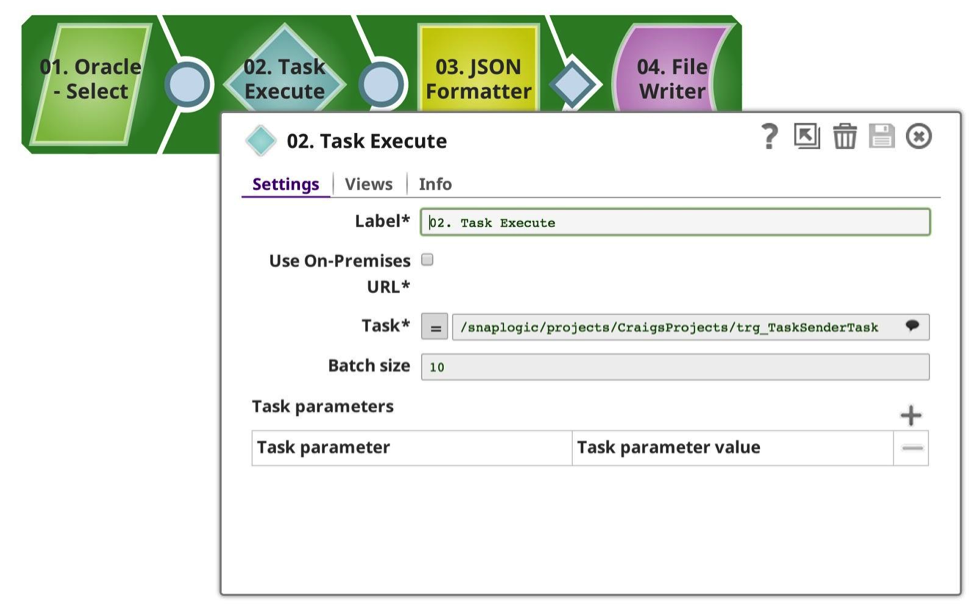
Remarquez que l‘URL cible est différente et que la taille du lot est beaucoup plus faible. Dans le pipeline exécuté, vous pouvez voir qu‘il y a un flux d‘entrée, qui prendra la charge utile entrante, et dans ce cas des données doubles, en copiant et en unissant le résultat. Il y a ensuite une sortie non terminée, qui sera renvoyée à l‘appelant.
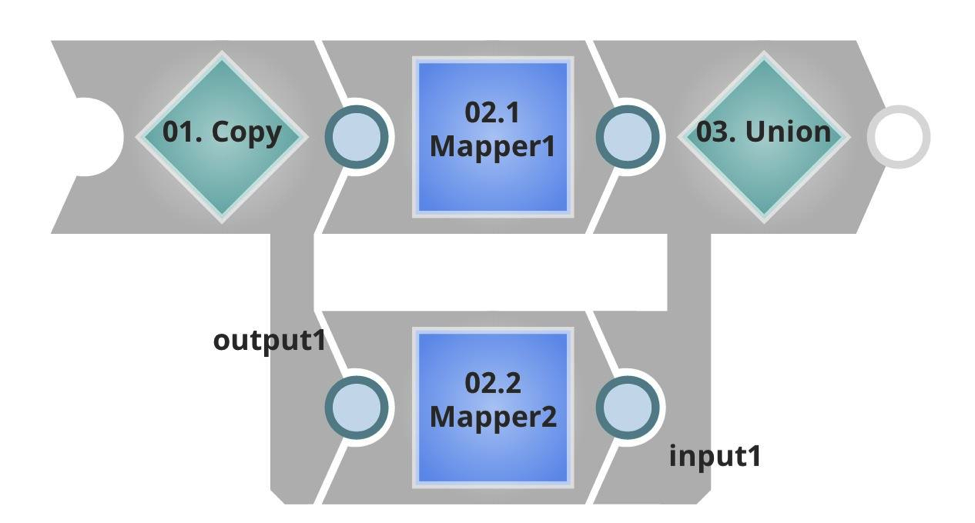
J‘ai de nouveau créé une tâche dans le gestionnaire SnapLogic Integration Cloud :

Maintenant que j‘ai l‘ensemble complet, l‘idée de cette configuration est que je sélectionne un ensemble de données dans ma base Oracle, dans ce cas 52 lignes, que j‘envoie ensuite par lots de 10 au pipeline cible, en profitant de la transmission des types de données, de la compression, etc. comme décrit précédemment. Mais cette fois-ci, je recevrai en retour un ensemble de résultats, en préservant à nouveau les types et les formats de données.
Voici les statistiques d‘exécution :
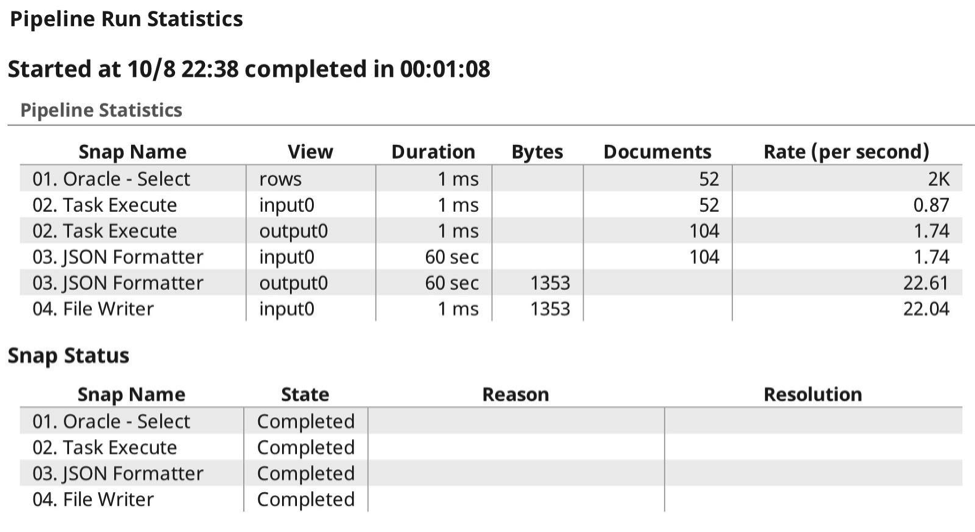
Comme vous pouvez le voir, cette fois-ci, j‘ai envoyé et reçu des payloads, permettant à SnapLogic Elastic Integration Platform de gérer l‘authentification, l‘autorisation et la compression des payloads. Je n‘ai pas eu à me préoccuper des en-têtes ou de toute autre configuration supplémentaire. Ici, vous voyez l‘exécution à partir de l‘affichage du pipeline dans le tableau de bord :

Résumé
En résumé, le Snap d‘exécution de tâches vous permet de transférer des lots de données vers et depuis des pipelines cibles, en agrégeant, authentifiant et compressant automatiquement la charge utile de données, et en attendant que l‘opération soit terminée avec succès. Pour plus de bonnes pratiques, de conseils et d‘astuces concernant SnapLogic, n‘oubliez pas de consulter nos webinaires et enregistrements TechTalk.




