





Der Task Execute Snap von SnapLogic wurde in der Version vom Sommer 2014 eingeführt. In der Herbstversion 2014 wurde der Task Execute Snap um (transparente) Komprimierung und Datentyp-Propagation erweitert. Dieser Snap ähnelt dem ForEach-Snap, bei dem für jedes eingehende Datendokument eine einzelne Ausführung der Pipeline abgefeuert wird, aber der Task Execute Snap:
- sendet das gesamte Eingabedokument
- kann eine Anzahl von Eingabezeilen aggregieren, die in die Ziel-Pipeline gestreamt werden sollen
- sendet die SnapLogic-Datentyp-Informationen an das Ziel, wobei Datum/Uhrzeit, numerische und String-Typen beibehalten werden
- komprimiert Daten bei der Übergabe an die Ziel-Pipeline zur Optimierung der Netzwerk- und Speichernutzung
Die Ziel-Pipeline sollte so konfiguriert werden, dass sie die Eingabedaten empfängt (im Falle eines POSTing der Daten) oder die Daten produziert (im Falle eines GET), ähnlich wie eine Sub-Pipeline, obwohl diese noch lockerer gekoppelt ist. Die Zielpipeline wird für jeden Stapel von Eingabedaten einmal aufgerufen. Gehen wir nun ins Detail. Ich habe drei Beispiele erstellt:
- POST-Typ, bei dem wir Daten an die Zielpipeline senden und keine Antwort erwarten
- GET-Typ, bei dem wir die Ausgabe oder eine fernausgeführte Aufgabe erhalten
- POST- und GET-Typ, bei dem die eingehende Nutzlast mit der abgerufenen Nutzlast kombiniert wird
Beispiel 1: POST-Typ
Für mein erstes Beispiel habe ich eine einfache Pipeline erstellt, um die Daten zu konsumieren, in der Erwartung, dass sie als Nutzlast an die URL-Anforderung gepostet werden, die nur aus dem JSON Formatter und einem File Writer besteht, obwohl es auch jeder andere Snap mit einer Dokumenteneingabe hätte sein können:
Dann habe ich im Manager eine ausgelöste Aufgabe erstellt, um die Ziel-Pipeline aufzurufen:

Und ich habe eine Pipeline erstellt, um die Daten zu senden, in diesem Fall wähle ich aus meiner bevorzugten Oracle-Datenbank aus und beschränke sie auf 50102 Zeilen (eine beliebige Zahl). Wie Sie sehen, habe ich die Aufgabe Execute Snap it so konfiguriert, dass sie die Aufgabe verwendet, die ich zuvor definiert habe, mit einer Stapelgröße von 10.000 Zeilen, was bedeutet, dass sie 6 Aufrufe machen sollte, 10.000 x 5, 1 x 102. Jede Anfrage wird synchron ausgeführt. Da dies alles innerhalb derselben Organisation geschieht, übernimmt der Snap die gesamte Authentifizierung und Autorisierung für Sie.
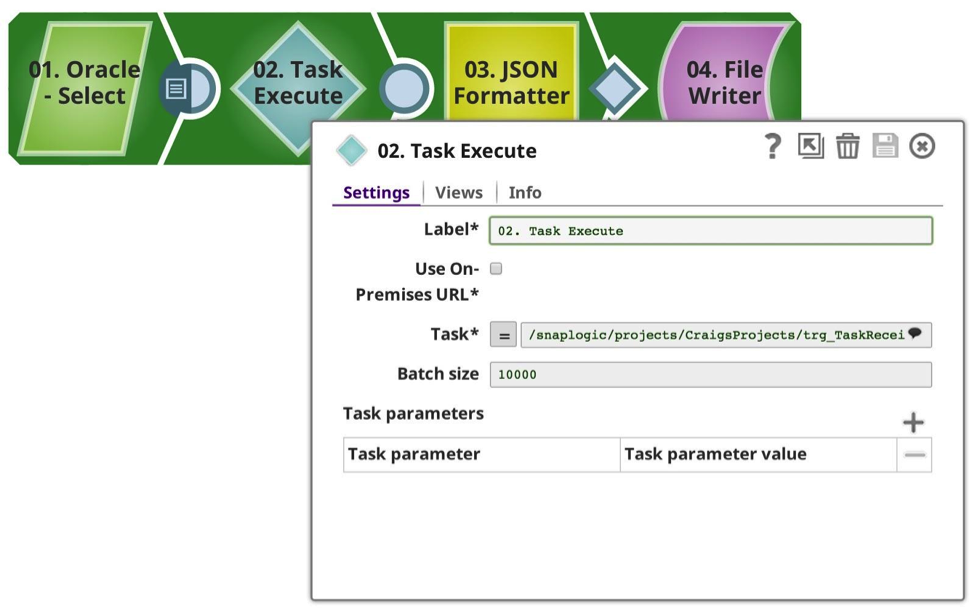
Die Aufgabe wird aus der Dropdown-Liste ausgewählt, die sich mit den verfügbaren Metadaten befasst und die auslösbaren Pipelines sowohl des aktuellen als auch des gemeinsamen Projekts anzeigt. (Hinweis: Wenn die Option Vor-Ort-URL verwenden aktiviert ist, werden nur die Pipelines angezeigt, für die eine Vor-Ort-URL verfügbar ist, d. h. die in einem Groundplex laufen). Wenn diese Option ausgewählt ist und die Snaplexes alle vor Ort sind, werden keine Daten durch die Firewall übertragen; sie bleiben alle lokal zwischen den Knoten sicher.
Die Stapelgröße kann an Ihre Anforderungen angepasst werden, um die Last und die Speichernutzung auszugleichen. Jeder Pipeline-Aufruf ist mit einem gewissen Overhead bei der Vorbereitung, Ausführung und Protokollierung verbunden, der bei einer geringen Anzahl von Zeilen pro Stapel berücksichtigt werden sollte. Je höher die Anzahl der Zeilen pro Stapel ist, desto höher ist der Speicherverbrauch.
Wenn ich die Pipeline ausführe, werden die Daten von der Quelle gestreamt, in diesem Fall in die Aufgabe execute, die mit der auf 10.000 eingestellten Stapelgröße im Speicher aggregiert wird, bis sie entweder den Eingabestrom abschließt oder die Stapelgröße erreicht, wenn sie dann die Daten mit der Datennutzlast an die Zielpipeline sendet.
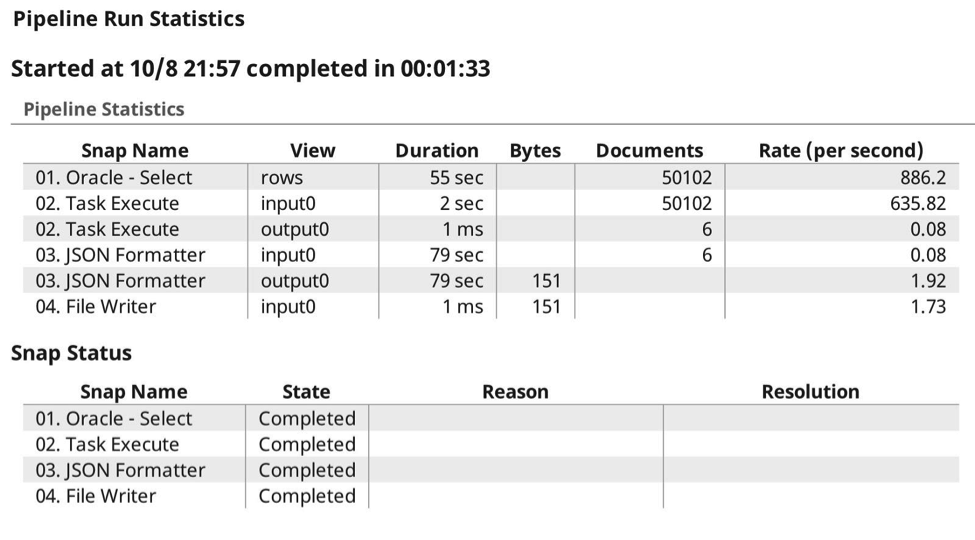
Hier ist das Ausführungsprotokoll, in dem die erwarteten 6 Aufrufe zu sehen sind, bei denen die Daten erwartungsgemäß an die Zielaufgabe übergeben wurden, wobei die Komprimierung automatisch erfolgt, da sie weiß, dass sie in der Lage ist, den Inhalt zu gzipen und die Datentypen zu erhalten.
Die Ausgabe der Task-Ausführung ist lediglich der HTTP-Rückgabecode, der von der Ziel-Pipeline angegeben wird:

Dies wird in der Pipeline-Anzeige des Dashboards wie folgt angezeigt:

Beispiel 2: GET-Typ
In diesem Beispiel habe ich die erste Pipeline geändert, um die Eingabeansicht zu entfernen und nur die Zielaufgabe auszuführen und ihre Ausgabedaten zu empfangen.
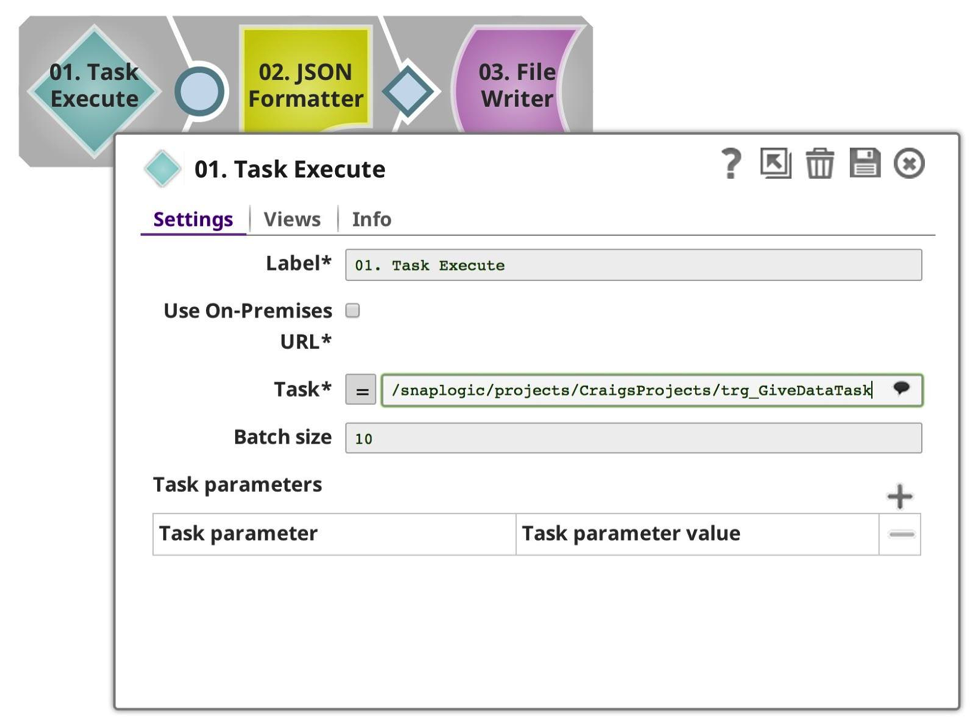
In diesem Fall ist die Stapelgröße irrelevant. Als nächstes änderte ich die aufgerufene Pipeline in meinen Datenproduzenten:
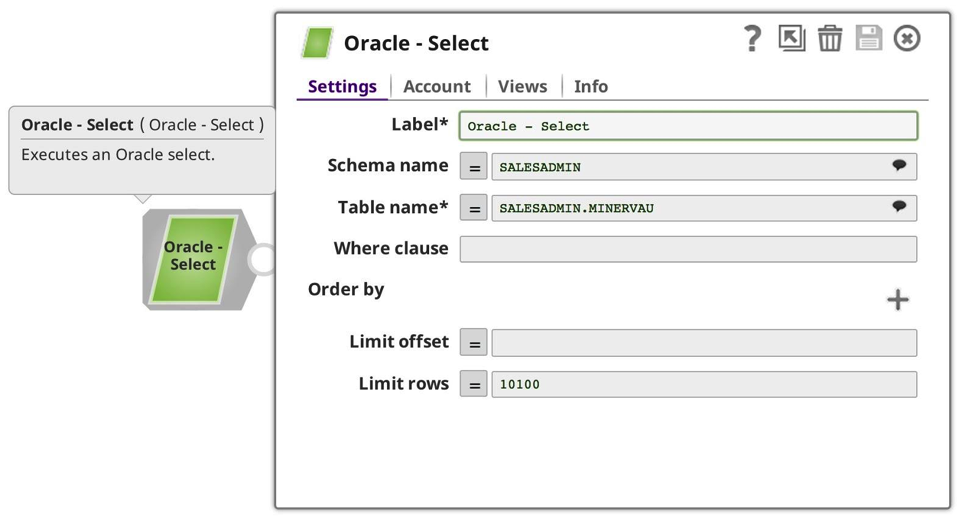
Diesmal ist das Ergebnis ein kleinerer Satz von Daten aus meiner Oracle-Datenbank. Als Nächstes habe ich einen neuen Task erstellt, diesmal für meine kleinere Produzenten-Pipeline:
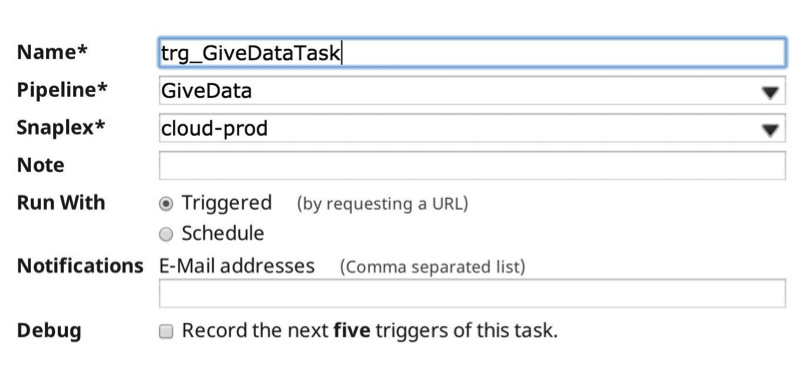
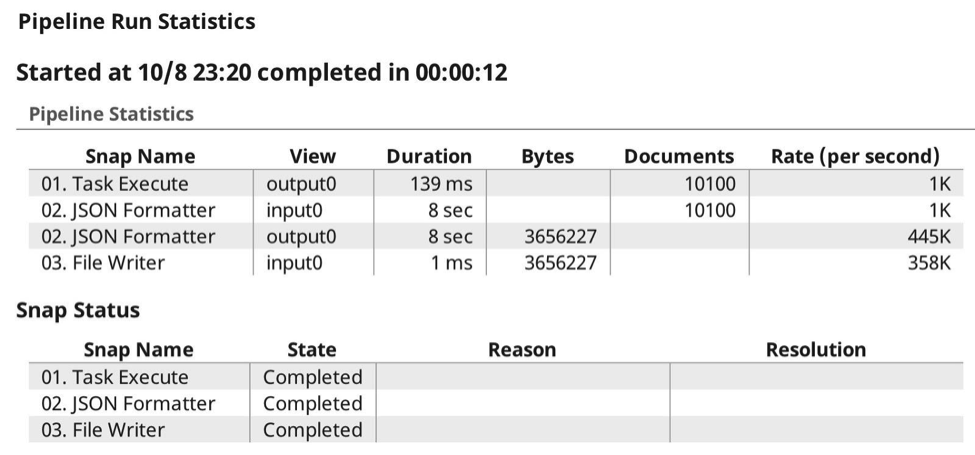
Wenn ich nun die Pipeline ausführe, sieht die Laufzeitstatistik wie folgt aus:
Auf dem Dashboard wird die Pipeline wie folgt angezeigt:
![]()
Beispiel 3: POST-und-GET-Typ
Die Executed-Pipeline kann auch ein Datenproduzent sein. In diesem Beispiel verwende ich dieselbe Art von aufrufender Pipeline, obwohl ich dieses Mal das Oracle SELECT auf 52 Datenzeilen beschränkt habe. Die Driving-Pipeline sieht bemerkenswert ähnlich aus:
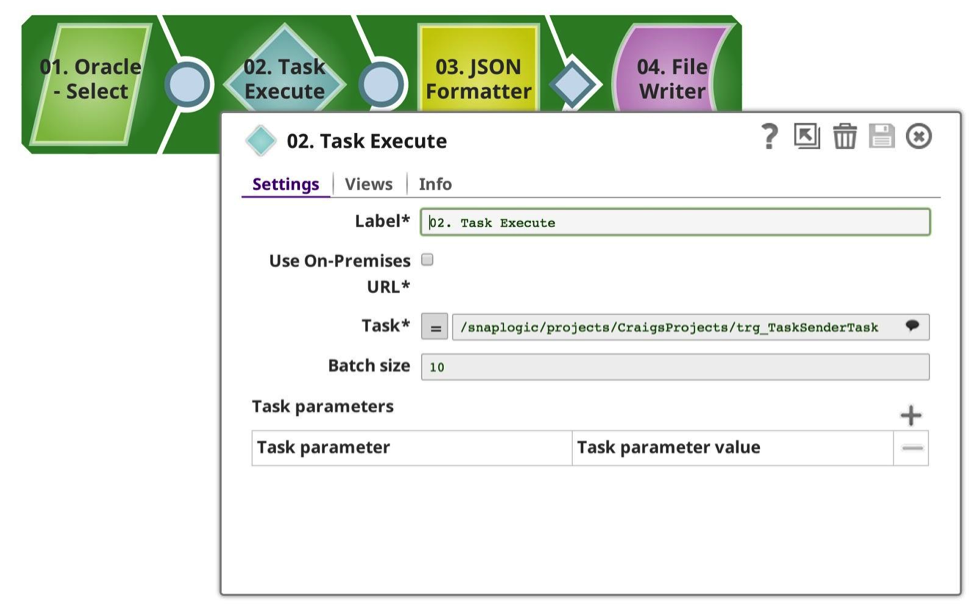
Wie Sie sehen, habe ich eine andere Ziel-URL und eine viel geringere Stapelgröße. In der Executed-Pipeline sehen Sie diesmal einen Input-Stream, der die eingehende Nutzlast und in diesem Fall doppelte Daten aufnimmt, indem er das Ergebnis kopiert und vereinigt. Dann gibt es eine unterminierte Ausgabe, die an den Aufrufer zurückgegeben wird.
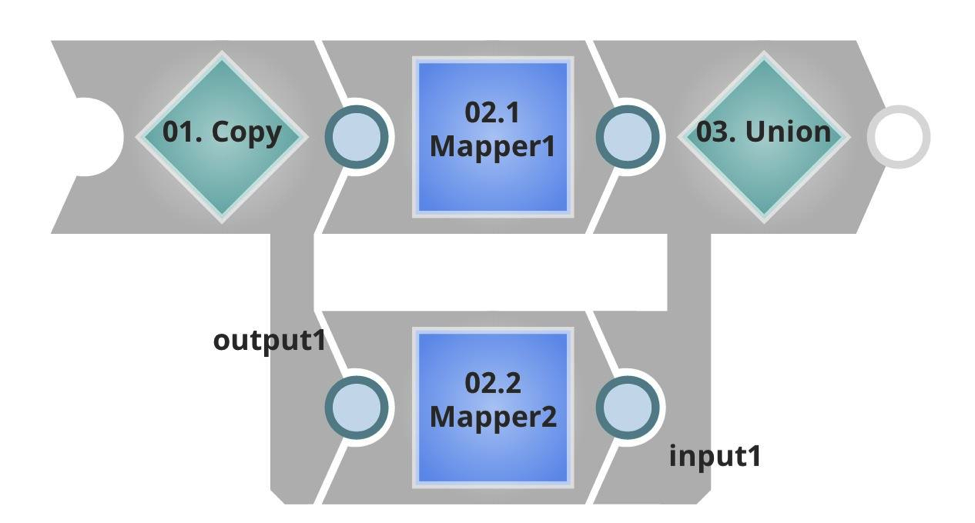
Auch hierfür habe ich einen Task im SnapLogic Integration Cloud Manager erstellt:

Die Idee dieser Konfiguration ist, dass ich einen Datensatz aus meiner Oracle-Datenbank auswähle, in diesem Fall 52 Zeilen, die ich dann in Stapeln von 10 Zeilen an die Ziel-Pipeline sende, wobei ich die Vorteile der Weitergabe der Datentypen, der Komprimierung usw. wie zuvor beschrieben nutze. Diesmal erhalte ich aber tatsächlich eine Ergebnismenge zurück, wobei wiederum die Datentypen und -formate erhalten bleiben.
Hier sind die Ausführungsstatistiken zur Laufzeit:
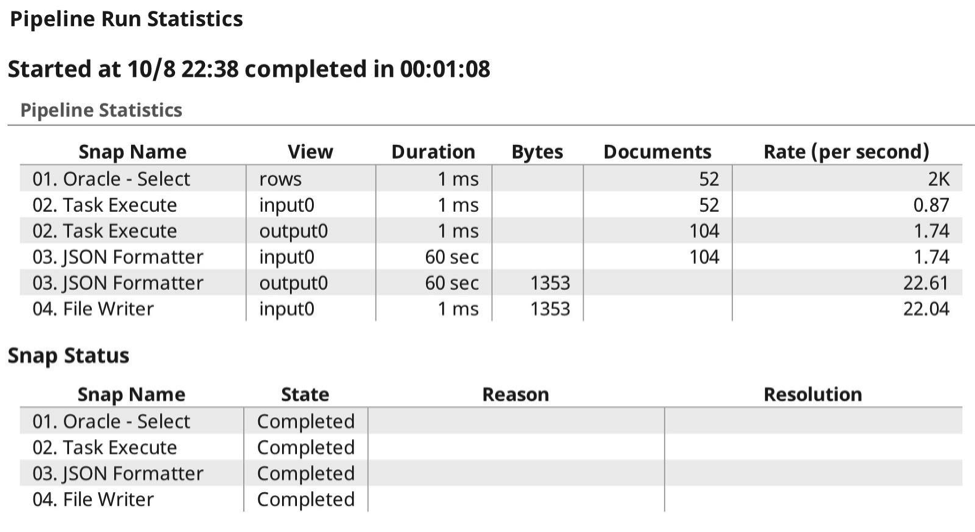
Wie Sie sehen können, habe ich dieses Mal sowohl Nutzdaten gesendet als auch empfangen, wobei die SnapLogic Elastic Integration Platform die Authentifizierung, Autorisierung und Komprimierung der Nutzdaten übernommen hat. Keine Probleme mit Headern oder einer anderen zusätzlichen Konfiguration. Hier sehen Sie die Ausführung in der Pipeline-Anzeige des Dashboards:

Zusammenfassung
Zusammenfassend lässt sich sagen, dass der Task Execute Snap es Ihnen ermöglicht, Datenstapel an und von Zielpipelines zu übergeben, die Daten automatisch zu aggregieren, zu authentifizieren, zu komprimieren und auf den erfolgreichen Abschluss zu warten. Weitere Best Practices sowie Tipps und Tricks zu SnapLogic finden Sie in unseren TechTalk-Webinaren und Aufzeichnungen.




