





Questo post illustra due scenari comunemente riscontrati dai nostri clienti:
a) Un esempio di elaborazione XML complessa e
b) Un esempio reale di come potrebbe essere l' On-Boarding/Off-boarding delle risorse umane con i dati di Workday.
Di seguito è riportata una schermata della pipeline e una descrizione dettagliata di ciò che tenta di ottenere.
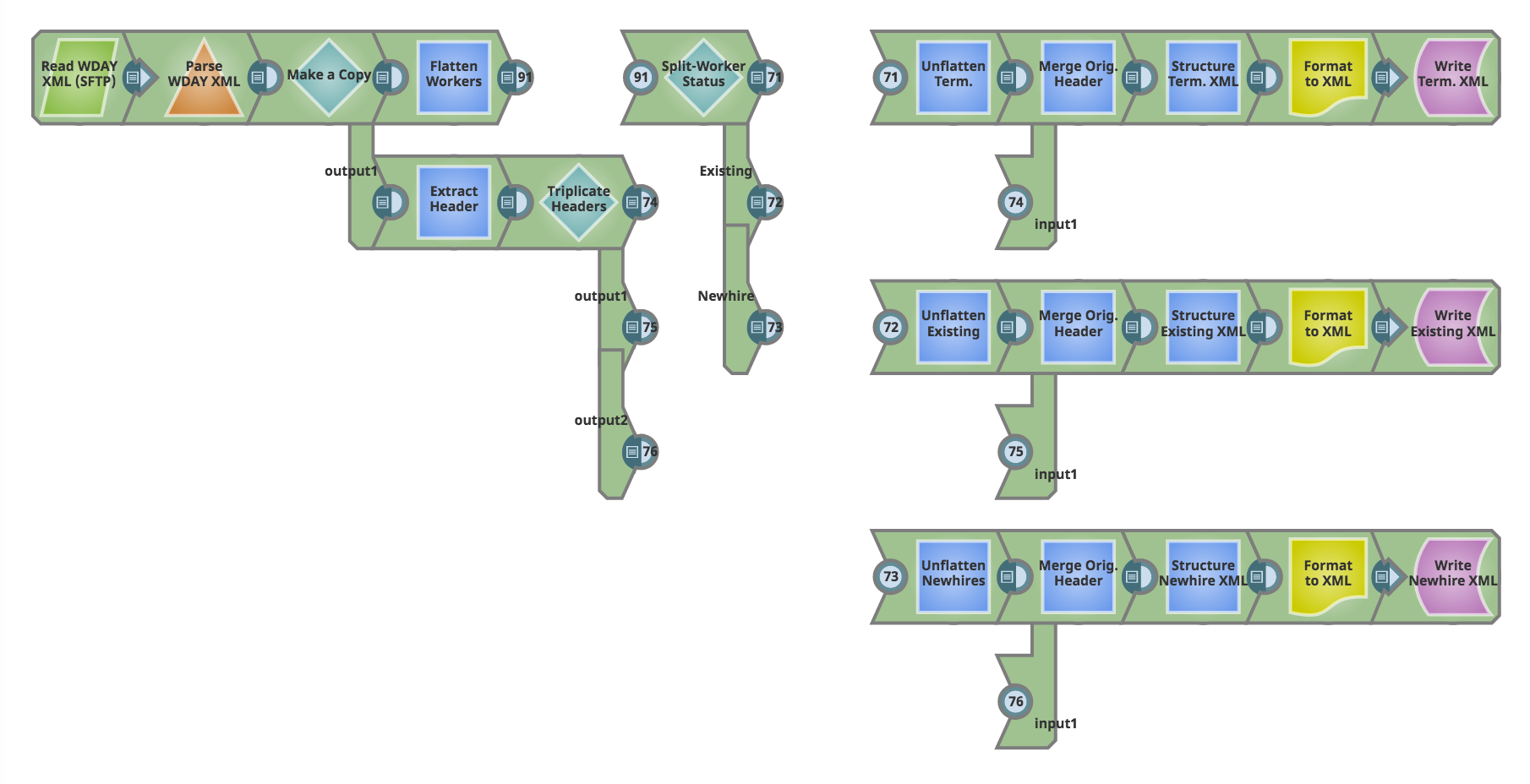
Esaminiamo questa conduttura.
A sinistra, iniziamo leggendo un estratto XML da Workday, che contiene,
a) Nuovi assunti,
b) lavoratori cessati e
c) Attivi (che non sono né nuovi assunti né cessati)
Il nostro obiettivo in questa pipeline è separare questi tre tipi di lavoratori e scriverli nei propri file XML. Questi XML di destinazione rappresentano i feed per uno o più sistemi che elaborano l'imbarco e lo sbarco dei dipendenti.
L'estratto Employee di Workday fornisce anche alcuni dati aggregati nell'intestazione XML. Queste informazioni di intestazione sono presenti nel nostro estratto di origine. Il nostro obiettivo è conservare questa intestazione e introdurla in ciascuno degli XML di destinazione, con un aggiornamento di un campo specifico dell'intestazione (conteggio dei lavoratori) che rifletta il numero totale di lavoratori scritti in ciascun file XML di destinazione.
Passaggio alla pipeline
Non appena leggiamo l'XML del Lavoratore sorgente e dividiamo il file, ne facciamo una copia. Lungo il percorso superiore, elaboriamo il payload XML. Lungo il percorso inferiore della copia, estraiamo e conserviamo l'intestazione per utilizzarla in un secondo momento. Analizziamo ciascuno di questi percorsi separatamente.
A. Elaborazione del carico utile XML
Per prima cosa rimuoviamo la gerarchia nei dati dei lavoratori utilizzando uno splitter JSON (Flatten Workers). Il cuore dell'elaborazione dei lavoratori avviene nella fase "Split-Worker Status", implementata utilizzando uno snap Router con "First Match" abilitato. Separiamo i tre tipi di lavoratori utilizzando la logica seguente:
a) Aggiungere nuovamente il prefisso ws::
Questo viene fatto usando lo snap Group By N con un campo di destinazione $ws.
b) Reintrodurre l'intestazione XML
Introduciamo l'intestazione XML conservata nell'output della fase a) di cui sopra. Maggiori dettagli sull'introduzione dell'intestazione sono riportati di seguito.
B. Elaborazione dell'intestazione XML
Manteniamo il nome dell'elemento principale (Worker_Sync) attraverso la mappatura:

Aggiungiamo il payload elaborato (i lavoratori separati per tipo) sotto Worker_Sync attraverso la mappatura: 
Infine, utilizziamo l'aggiornamento del campo del conteggio dei lavoratori ($['ws:Worker_Sync']['ws:Header']['ws:Worker_Count']) all'interno della nuova intestazione:

Una volta fatto questo, il nostro XML è pronto per essere formattato e scritto nel file di destinazione (o inviato a un altro endpoint). Si noti che è necessario lasciare vuoto l'elemento radice nel formattatore XML, per evitare che vengano introdotti i tag predefiniti.
Hari Shankar è un Solutions Engineer Advisor di SnapLogic.






