





This post illustrates two of our commonly encountered customer scenarios:
a) An example of complex XML processing, and
b) A real-world example of what HR On-Boarding/Off-boarding might look like with Workday data
Below is a screenshot of the pipeline and a detailed walkthrough of what it attempts to achieve.
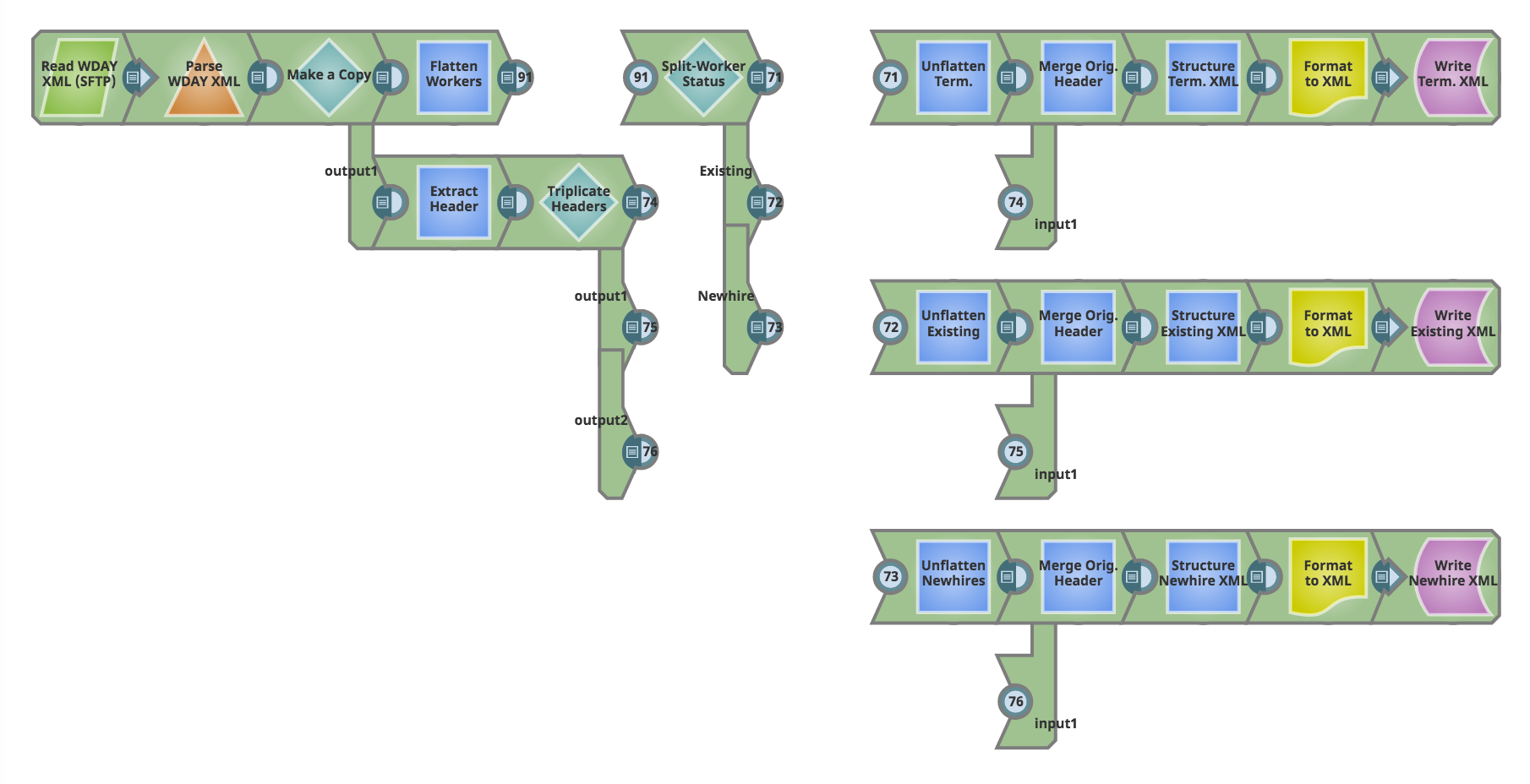
Lets review this pipeline.
On the left, we start by reading an XML extract from Workday, that contains,
a) New Hires,
b) Terminated Workers, and
c) Active (that are neither new hires or terminated)
Our goal in this pipeline is to separate out these three kinds of workers and write them in their own XML files. These target XMLs represent feeds to one or more systems that process employee on/off-boarding.
Workday’s Employee extract also provides some aggregate data in the XML header. This header information is present in our source extract. Our goal is also to preserve this header, and introduce this in each of the target XMLs, with an update to a specific header field (worker count) that reflects the total number of workers being written to each target XML file.
Pipeline Walkthrough
As soon as we read in the source Worker XML and part the file, we make a copy. Along the top path, we process the XML payload. Along the bottom path of the copy, we extract and preserve the header for use at a later time. Lets look at each of these paths separately.
A. XML Payload processing
We first remove the hierarchy in the Worker data by using a JSON splitter (Flatten Workers).The core of the Worker processing happens within the ‘Split-Worker Status’ stage which is implemented using a Router snap with ‘First Match’ enabled. We separate out the three types of workers using the logic below:
a) Add back the ws: prefix:
This is done using the Group By N snap with a $ws target field.
b) Reintroduce the XML Header
We introduce the preserved XML header into the output of stage a) above. More details on header introduction covered below.
B. XML Header Processing
We preserve the root element name(Worker_Sync) through the mapping:

We add the processed payload (the workers separated by type) under Worker_Sync through the mapping: 
Finally, we use update the worker count field ($[‘ws:Worker_Sync’][‘ws:Header’][‘ws:Worker_Count’]) within the newly introduced header through:

Once this is done, our XML is ready to be formatted and written to its target file (or fed to another endpoint). Please note that you need to leave the root element empty in the XML formatter in order to eliminate the default tags from being introduced.
Hari Shankar is a SnapLogic Solutions Engineer Advisor.






