






Was ist Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) ist der Prozess der Verbesserung der von Sprachmodellen (LLMs) verwendeten Referenzdaten durch deren Integration in traditionelle Informationsabrufsysteme. Dieser hybride Ansatz ermöglicht es LLMs, auf externe Wissensdatenbanken, Datenbanken und andere maßgebliche Informationsquellen zuzugreifen und diese zu nutzen, wodurch die Genauigkeit, Relevanz und Aktualität der generierten Antworten verbessert wird, ohne dass eine umfangreiche Nachschulung erforderlich ist. Ohne RAG generieren LLMs Antworten auf der Grundlage der Informationen, mit denen sie trainiert wurden. Mit RAG wird der Prozess der Antwortgenerierung durch die Integration externer Informationen bereichert.
Wie funktioniert die Retrieval-Augmented Generation?
Retrieval-Augmented Generation funktioniert, indem mehrere Systeme oder Dienste zusammengeführt werden, um die Eingabeaufforderung für das LLM zu generieren. Das bedeutet, dass eine entsprechende Konfiguration erforderlich ist, um die verschiedenen Systeme und Dienste zu unterstützen, damit die richtigen Daten für einen RAG-Workflow bereitgestellt werden können. Dazu sind mehrere wichtige Schritte erforderlich:
1. Erstellung externer Datenquellen:
Externe Daten beziehen sich auf Informationen außerhalb der ursprünglichen Trainingsdaten des LLM. Diese Daten können aus einer Vielzahl von Quellen stammen, wie z. B. APIs, Datenbanken, Dokumentenarchiven und Webseiten. Die Daten werden vorverarbeitet und mithilfe von Einbettungsmodellen in numerische Darstellungen (Einbettungen) umgewandelt und dann zusammen mit einem Verweis auf die Daten, die zur Erzeugung der Einbettung verwendet wurden, in einer durchsuchbaren Vektordatenbank gespeichert. Dies bildet eine Wissensbibliothek, die verwendet werden kann, um eine Eingabeaufforderung zu ergänzen, wenn das LLM zur Generierung einer Antwort auf eine bestimmte Eingabe aufgerufen wird.
2. Abruf relevanter Informationen:
Wenn ein Benutzer eine Suchanfrage eingibt, wird diese in eine Vektordarstellung eingebettet und mit den Einträgen in der Vektordatenbank abgeglichen. Die Vektordatenbank ruft die relevantesten Dokumente oder Daten auf der Grundlage semantischer Ähnlichkeit ab. Eine Suchanfrage zu den Urlaubsrichtlinien eines Unternehmens würde beispielsweise sowohl das allgemeine Dokument zu den Urlaubsrichtlinien als auch die spezifischen Urlaubsrichtlinien für bestimmte Positionen abrufen.
3. Erweiterung der LLM-Eingabeaufforderung:
Die abgerufenen Informationen werden dann mithilfe von Prompt-Engineering-Techniken in die Eingabeaufforderung integriert, die an das LLM gesendet wird. Diese vollständig ausgearbeitete Eingabeaufforderung wird an das LLM gesendet und liefert zusätzlichen Kontext und relevante Daten, die es dem Modell ermöglichen, genauere und kontextbezogenere Antworten zu generieren.
4. Generierung der Antwort:
Der LLM verarbeitet die erweiterte Eingabeaufforderung und generiert eine Antwort, die kohärent und kontextuell angemessen ist und mit genauen, aktuellen Informationen angereichert ist.
Das folgende Diagramm veranschaulicht den Datenfluss bei der Verwendung von RAG mit LLMs.

Warum Retrieval-Augmented Generation verwenden?
RAG geht mehrere inhärente Herausforderungen bei der Verwendung von LLMs an, indem es externe Datenquellen nutzt:
1. Verbesserte Genauigkeit und Relevanz:
Durch den Zugriff auf aktuelle und zuverlässige Informationen stellt RAG sicher, dass die generierten Antworten korrekt, spezifisch und für die Anfrage des Benutzers relevant sind. Dies ist besonders wichtig für Anwendungen, die präzise und aktuelle Informationen erfordern, wie z. B. spezifische Unternehmensdetails, Veröffentlichungsdaten und -artikel, neue Funktionen für ein Produkt, individuelle Produktdetails usw.
2. Kosteneffiziente Umsetzung:
RAG ermöglicht es Unternehmen, die Leistung von LLMs zu verbessern, ohne dass eine kostspielige und zeitaufwändige Feinabstimmung oder ein individuelles Modelltraining erforderlich ist. Durch die Einbindung externer Wissensbibliotheken bietet RAG eine effizientere Möglichkeit, die Wissensbasis des Modells zu aktualisieren und zu erweitern.
3. Verbessertes Vertrauen der Nutzer:
Mit RAG können Antworten Zitate oder Verweise auf die ursprünglichen Informationsquellen enthalten, was die Transparenz und das Vertrauen erhöht. Benutzer können die Quelle der Informationen überprüfen, was die Glaubwürdigkeit und das Vertrauen in ein KI-System stärkt.
4. Größere Kontrolle für Entwickler:
Entwickler können die vom LLM verwendeten externen Wissensquellen einfach aktualisieren und verwalten, was eine flexible Anpassung an sich ändernde Anforderungen oder spezifische Domänenanforderungen ermöglicht. Diese Kontrolle umfasst die Möglichkeit, den Abruf sensibler Informationen zu beschränken und die Richtigkeit der generierten Antworten sicherzustellen. In Verbindung mit einem Bewertungsrahmen (Link zum Artikel über die Bewertungspipeline) kann dies dazu beitragen, neuere Inhalte schneller für nachgelagerte Verbraucher bereitzustellen.
Snaplogic GenAI App Builder: Einfaches Erstellen von RAG
Mit Snaplogic GenAI App Builder können Geschäftsanwender Lösungen auf Basis großer Sprachmodelle (LLM) erstellen, ohne dass dafür Programmierkenntnisse erforderlich sind. Dieses Tool bietet den schnellsten Weg zur Entwicklung generativer Unternehmensanwendungen, indem es Dienste von Branchenführern wie OpenAI, Azure OpenAI, Amazon Bedrock, Anthropic Claude auf AWS und Google Gemini nutzt. Mit dieser robusten Plattform können Benutzer mühelos LLM-Anwendungen und Workflows erstellen.
Mit Snaplogic GenAI App Builder können Sie mit minimalem Aufwand sowohl eine Indizierungspipeline als auch eine Retrieval-Augmented Generation (RAG)-Pipeline erstellen.
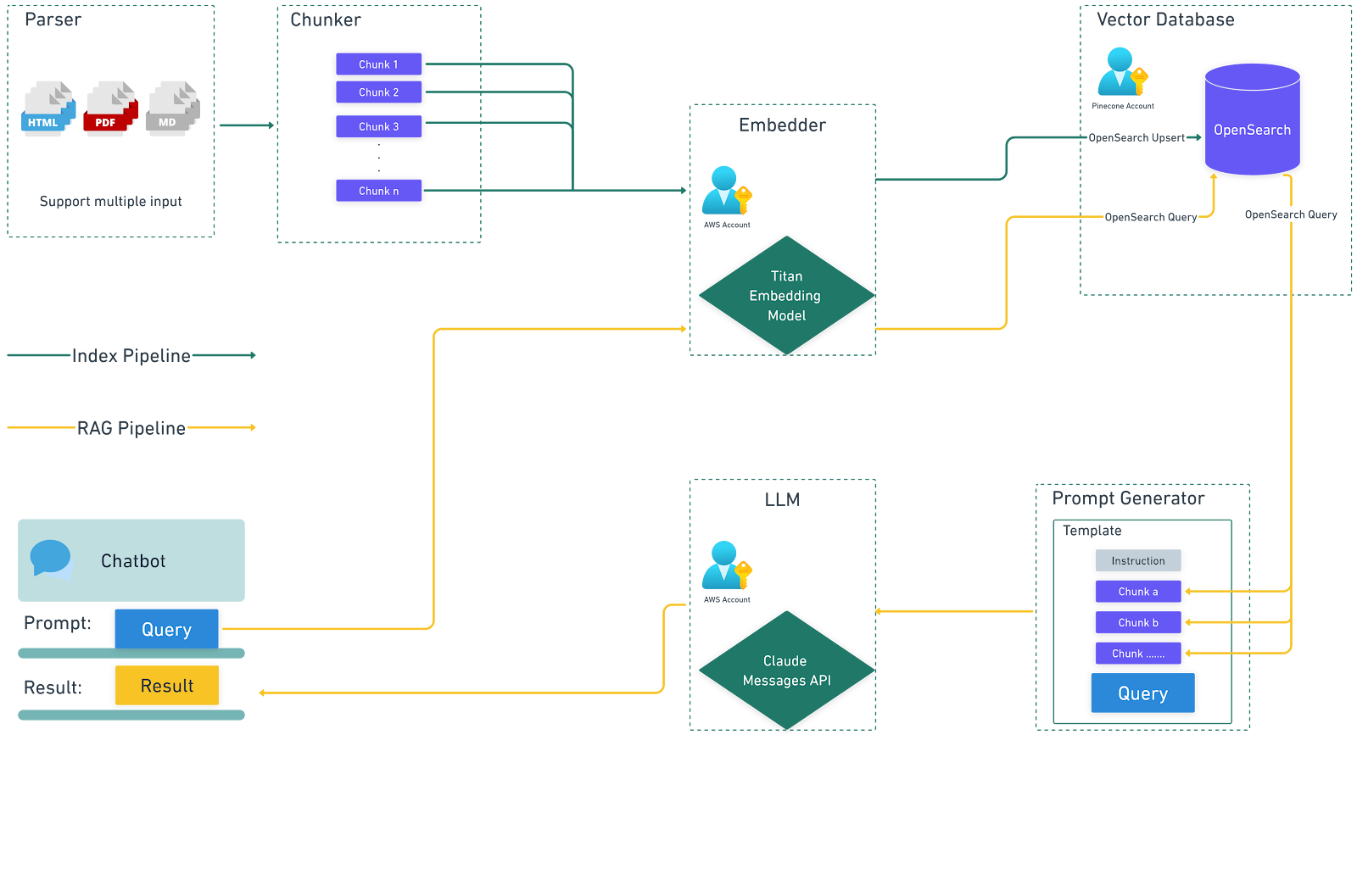
Indizierungspipeline
Diese Pipeline dient dazu, den Inhalt einer PDF-Datei in einer Wissensbibliothek zu speichern, sodass der Inhalt für die zukünftige Verwendung leicht zugänglich ist.

Nach dem Ausführen dieser Pipeline können wir diese Vektoren in OpenSearch anzeigen.
RAG-Pipeline
Diese Pipeline ermöglicht die Erstellung eines Chatbots, der Fragen auf der Grundlage der in der Wissensbibliothek gespeicherten Informationen beantworten kann.

Zur Implementierung dieser Pipelines nutzt die Lösung das Amazon Bedrock Snap Pack und das OpenSearch Snap Pack. Benutzer haben jedoch die Möglichkeit, andere LLM- und Vektordatenbank-Snaps zu verwenden, um ähnliche Funktionen zu erzielen.






