






Che cos'è la generazione potenziata dal recupero (RAG)?
La generazione potenziata dal recupero (RAG) è il processo di miglioramento dei dati di riferimento utilizzati dai modelli linguistici (LLM) attraverso la loro integrazione con i tradizionali sistemi di recupero delle informazioni. Questo approccio ibrido consente agli LLM di accedere e utilizzare basi di conoscenza esterne, database e altre fonti di informazioni autorevoli, migliorando così l'accuratezza, la pertinenza e l'attualità delle risposte generate senza richiedere un addestramento approfondito. Senza RAG, gli LLM generano risposte basate sulle informazioni su cui sono stati addestrati. Con il RAG, il processo di generazione delle risposte viene arricchito integrando informazioni esterne nella generazione.
Come funziona la generazione potenziata dal recupero?
La generazione potenziata dal recupero (RAG) funziona integrando più sistemi o servizi per generare il prompt per l'LLM. Ciò significa che sarà necessaria una configurazione per supportare i diversi sistemi e servizi al fine di fornire i dati appropriati per un flusso di lavoro RAG. Ciò comporta diversi passaggi chiave:
1. Creazione di fonti di dati esterne:
I dati esterni sono informazioni che non fanno parte dei dati di addestramento originali dell'LLM. Questi dati possono provenire da diverse fonti, come API, database, archivi di documenti e pagine web. I dati vengono pre-elaborati e convertiti in rappresentazioni numeriche (embedding) utilizzando modelli di embedding, quindi memorizzati in un database vettoriale ricercabile insieme al riferimento ai dati utilizzati per generare l'embedding. Ciò costituisce una libreria di conoscenze che può essere utilizzata per aumentare un prompt quando si richiama l'LLM per generare una risposta a un determinato input.
2. Recupero delle informazioni rilevanti:
Quando un utente inserisce una query, questa viene incorporata in una rappresentazione vettoriale e confrontata con le voci presenti nel database vettoriale. Il database vettoriale recupera i documenti o i dati più rilevanti in base alla somiglianza semantica. Ad esempio, una query relativa alle politiche aziendali in materia di ferie recupererebbe sia il documento generale sulle politiche in materia di ferie sia le politiche specifiche relative ai singoli ruoli.
3. Aumento del prompt LLM:
Le informazioni recuperate vengono quindi integrate nel prompt da inviare all'LLM utilizzando tecniche di prompt engineering. Questo prompt completo viene inviato all'LLM, fornendo un contesto aggiuntivo e dati rilevanti che consentono al modello di generare risposte più accurate e contestualmente appropriate.
4. Generazione della risposta:
L'LLM elabora il prompt potenziato e genera una risposta coerente, contestualmente appropriata e arricchita con informazioni accurate e aggiornate.
Il diagramma seguente illustra il flusso di dati quando si utilizza RAG con LLM.

Perché utilizzare la generazione potenziata dal recupero?
RAG affronta diverse sfide inerenti all'utilizzo dei modelli LLM sfruttando fonti di dati esterne:
1. Maggiore accuratezza e pertinenza:
Accedendo a informazioni aggiornate e autorevoli, RAG garantisce che le risposte generate siano accurate, specifiche e pertinenti alla richiesta dell'utente. Ciò è particolarmente importante per le applicazioni che richiedono informazioni precise e aggiornate, come dettagli specifici sull'azienda, date e articoli di rilascio, nuove funzionalità disponibili per un prodotto, dettagli sui singoli prodotti, ecc.
2. Implementazione conveniente:
RAG consente alle organizzazioni di migliorare le prestazioni dei modelli LLM senza la necessità di costose e lunghe operazioni di messa a punto o di addestramento personalizzato dei modelli. Incorporando librerie di conoscenze esterne, RAG fornisce un modo più efficiente per aggiornare ed espandere la base di conoscenze del modello.
3. Maggiore fiducia degli utenti:
Con RAG, le risposte possono includere citazioni o riferimenti alle fonti originali delle informazioni, aumentando la trasparenza e la fiducia. Gli utenti possono verificare la fonte delle informazioni, il che migliora la credibilità e l'affidabilità di un sistema di IA.
4. Maggiore controllo da parte degli sviluppatori:
Gli sviluppatori possono facilmente aggiornare e gestire le fonti di conoscenza esterne utilizzate dall'LLM, consentendo un adattamento flessibile alle mutevoli esigenze o alle necessità specifiche del settore. Questo controllo include la possibilità di limitare il recupero di informazioni sensibili e garantire la correttezza delle risposte generate. Farlo in combinazione con un quadro di valutazione (link all'articolo sulla pipeline di valutazione) può aiutare a distribuire più rapidamente i nuovi contenuti ai consumatori a valle.
Snaplogic GenAI App Builder: Creare RAG con facilità
Snaplogic GenAI App Builder consente agli utenti aziendali di creare soluzioni basate su modelli linguistici di grandi dimensioni (LLM) senza richiedere alcuna competenza di programmazione. Questo strumento offre il percorso più veloce per lo sviluppo di applicazioni aziendali generative sfruttando i servizi di leader del settore come OpenAI, Azure OpenAI, Amazon Bedrock, Anthropic Claude su AWS e Google Gemini. Gli utenti possono creare senza sforzo applicazioni LLM e flussi di lavoro utilizzando questa solida piattaforma.
Con Snaplogic GenAI App Builder, puoi costruire sia una pipeline di indicizzazione che una pipeline di generazione potenziata dal recupero (RAG) con il minimo sforzo.
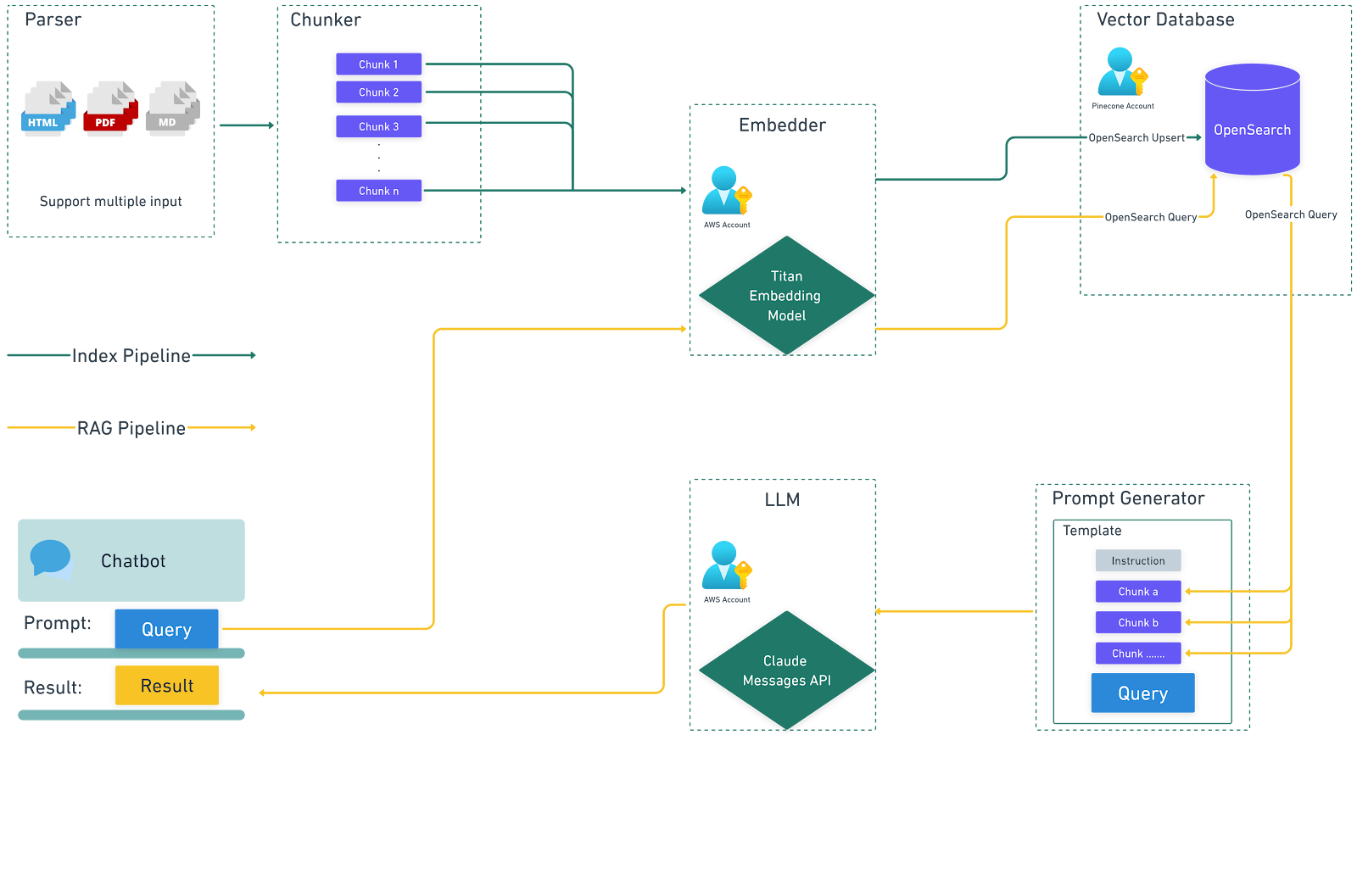
Pipeline di indicizzazione
Questa pipeline è progettata per archiviare il contenuto di un file PDF in una libreria di conoscenze, rendendo il contenuto facilmente accessibile per un utilizzo futuro.

Dopo aver eseguito questa pipeline, saremo in grado di visualizzare questi vettori in OpenSearch.
Pipeline RAG
Questa pipeline consente la creazione di un chatbot in grado di rispondere alle domande sulla base delle informazioni memorizzate nella libreria di conoscenze.

Per implementare queste pipeline, la soluzione utilizza Amazon Bedrock Snap Pack e OpenSearch Snap Pack. Tuttavia, gli utenti hanno la possibilità di utilizzare altri Snap LLM e database vettoriali per ottenere funzionalità simili.






