






Was sind Einbettungen?
Einbettungen sind numerische Darstellungen von Objekten aus der realen Welt, wie Text, Bilder oder Audio. Sie werden von maschinellen Lernmodellen als Vektoren generiert, also als Zahlenreihen, wobei der Abstand zwischen den Vektoren als Grad der Ähnlichkeit zwischen den Objekten angesehen werden kann. Während ein Einbettungsmodell für jede der Dimensionen seine eigene Bedeutung haben kann, gibt es keine Garantie zwischen Einbettungsmodellen hinsichtlich der Bedeutung für jede der von den Einbettungsmodellen verwendeten Dimensionen.
Beispielsweise könnten die Wörter „Katze“, „Hund“ und „Apfel“ in die folgenden Vektoren eingebettet sein:
Katze -> (1, -1, 2)
Hund -> (1,5, -1,5, 1,8)
Apfel -> (-1, 2, 0)
Diese Vektoren sind für ein einfacheres Beispiel erfunden. Reale Vektoren sind viel größer, siehe Abschnitt „Dimension“ für Details.
Wenn wir diese Vektoren als Punkte in einem 3D-Raum visualisieren, können wir sehen, dass„Katze”und„Hund”näher beieinander liegen, während„Apfel”weiter entfernt positioniert ist.
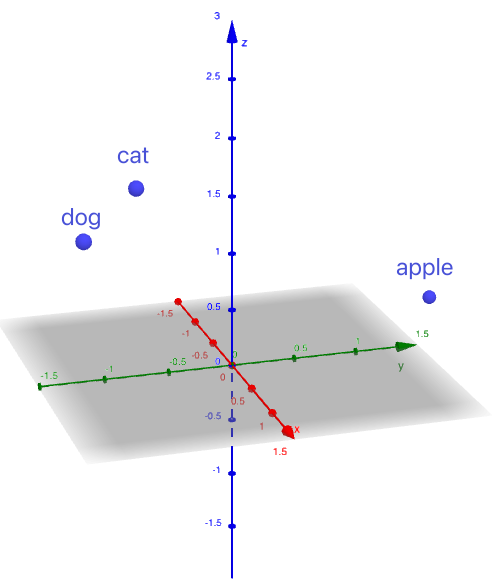
Abbildung 1. Vektoren als Punkte in einem 3D-Raum
Durch die Einbettung von Wörtern und Kontexten in Vektoren ermöglichen wir es Systemen, anhand eines Vektorvergleichs zu beurteilen, wie stark zwei eingebettete Elemente miteinander in Beziehung stehen.
Dimension der Einbettungen
Die Dimension von Einbettungen bezieht sich auf die Länge des Vektors, der das Objekt darstellt.
Im vorherigen Beispiel haben wir jedes Wort in einen dreidimensionalen Vektor eingebettet. Eine dreidimensionale Einbettung führt jedoch zwangsläufig zu einem massiven Informationsverlust. In der Realität erfordern Wort-Einbettungen in der Regel Hunderte oder Tausende von Dimensionen, um die Nuancen der Sprache zu erfassen.
Zum Beispiel
- Das Modell „text-embedding-ada-002“ von OpenAI gibt einen 1536-dimensionalen Vektor aus.
- Das Text-Embedding-004-Modell von Google Gemini gibt einen 768-dimensionalen Vektor aus.
- Das Modell amazon.titan-embed-text-v2:0 von Amazon Titan gibt einen standardmäßigen 1024-dimensionalen Vektor aus.

Abbildung 2. Verwendung von text-embedding-ada-002 zum Einbetten des Satzes „Ich habe eine Calico-Katze.“
Kurz gesagt ist eine Einbettung ein Vektor, der ein reales Objekt darstellt. Der Abstand zwischen diesen Vektoren gibt die Ähnlichkeit zwischen den Objekten an.
Einschränkung der Einbettungsmodelle
Einbettungsmodelle unterliegen einer entscheidenden Einschränkung: dem Token-Limit, wobei ein Token ein Wort, ein Satzzeichen oder ein Teil eines Wortes sein kann. Diese Einschränkung definiert die maximale Textmenge, die ein Modell in einer einzigen Eingabe verarbeiten kann. Beispielsweise können die Amazon Titan Text Embeddings-Modelle bis zu 8.192 Token verarbeiten.
Wenn der eingegebene Text die Grenze überschreitet, kürzt das Modell ihn in der Regel und verwirft die restlichen Informationen. Dies kann zu einem Verlust des Kontexts und einer verminderten Einbettungsqualität führen, da wichtige Details möglicherweise weggelassen werden.
Um dem entgegenzuwirken, können verschiedene Strategien helfen, die Auswirkungen abzuschwächen:
- Textzusammenfassung oder Chunking: Lange Texte können vor dem Einbetten zusammengefasst oder in kleinere, überschaubare Abschnitte unterteilt werden.
- Modellauswahl: Verschiedene Einbettungsmodelle haben unterschiedliche Token-Limits. Durch die Auswahl eines Modells mit einem höheren Limit können längere Eingaben verarbeitet werden.
Was ist eine Vektordatenbank?
Vektordatenbanken sind für die Speicherung von Einbettungen optimiert und ermöglichen ein schnelles Abrufen und eine Ähnlichkeitssuche. Durch die Berechnung der Ähnlichkeit zwischen dem Abfragevektor und den anderen Vektoren in der Datenbank gibt das System die Vektoren mit der höchsten Ähnlichkeit zurück, die den relevantesten Inhalt anzeigen.
Das folgende Diagramm veranschaulicht eine Suche in einer Vektordatenbank. Ein Suchvektor „Lieblingssportart” wird mit einer Reihe gespeicherter Vektoren verglichen, die jeweils eine Textphrase darstellen. Der nächstgelegene Nachbar, „Ich mag Fußball”, wird als oberstes Ergebnis zurückgegeben.
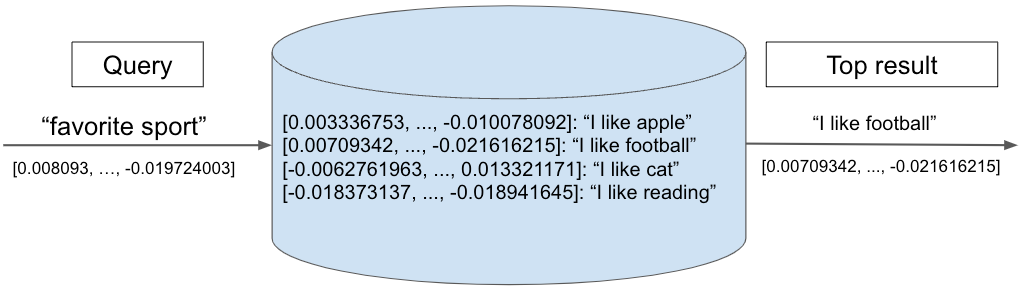
Abbildung 3. Beispiel für eine Vektorabfrage

Abbildung 4. Speichern von Vektoren in der Datenbank

Abbildung 5. Vektoren aus der Datenbank abrufen
Bei der Arbeit mit Vektordatenbanken kommen zwei wichtige Parameter ins Spiel: Top K und Ähnlichkeitsmaß (oder Distanzfunktion).
Top K
Bei der Abfrage einer Vektordatenbank besteht das Ziel häufig darin, die Elemente abzurufen, die einem bestimmten Abfragevektor am ähnlichsten sind. Hier kommt das Top-K-Konzept ins Spiel. Top K bezieht sich auf das Abrufen der K ähnlichsten Elemente auf der Grundlage einer Ähnlichkeitsmetrik.
Wenn Sie beispielsweise ein Produktempfehlungssystem entwickeln, möchten Sie vielleicht die zehn Produkte finden, die dem Produkt am ähnlichsten sind, das sich ein Benutzer gerade ansieht. In diesem Fall wäre K gleich 10. Die Vektordatenbank würde die zehn Produktvektoren zurückgeben, die dem Vektor des abgefragten Produkts am nächsten kommen.
Ähnlichkeitsmaße
Um die Ähnlichkeit zwischen Vektoren zu bestimmen, werden verschiedene Distanzmetriken verwendet, darunter:
- Kosinusähnlichkeit: Diese misst den Kosinus des Winkels zwischen zwei Vektoren. Sie wird häufig für textbasierte Anwendungen verwendet, da sie die semantische Ähnlichkeit gut erfasst. Ein Wert näher an 1 weist auf eine höhere Ähnlichkeit hin.
- Euklidischer Abstand: Berechnet den geradlinigen Abstand zwischen zwei Punkten im euklidischen Raum. Er reagiert empfindlich auf Größenunterschiede zwischen Vektoren.
- Manhattan-Distanz: Auch als L1-Distanz bekannt, berechnet sie die Summe der absoluten Differenzen zwischen entsprechenden Elementen zweier Vektoren. Im Vergleich zur euklidischen Distanz ist sie weniger empfindlich gegenüber Ausreißern.
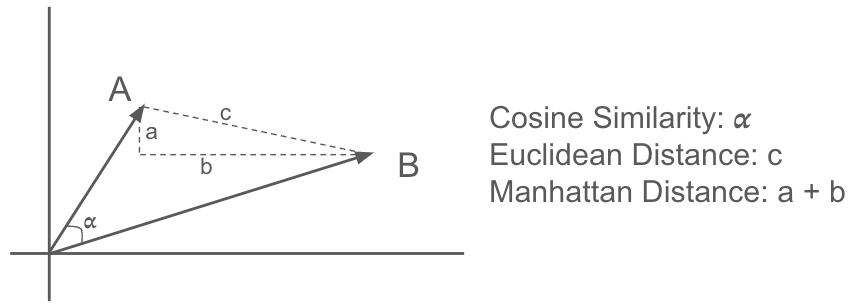
Abbildung 6. Ähnlichkeitsmaße
Es gibt viele weitere Ähnlichkeitsmaße, die hier nicht aufgeführt sind. Die Wahl der Distanzmetrik hängt von der jeweiligen Anwendung und der Art der Daten ab. Es wird empfohlen, mit verschiedenen Ähnlichkeitsmetriken zu experimentieren, um herauszufinden, welche die besten Ergebnisse liefert.
Welche Embedder werden in SnapLogic unterstützt?
Seit Oktober 2024 unterstützt SnapLogic Embedder für wichtige Modelle und baut seine Unterstützung kontinuierlich aus. Zu den unterstützten Embeddern gehören:
- Amazon Titan Einbettungsprogramm
- OpenAI-Einbettungsprogramm
- Azure OpenAI Embedder
- Google Gemini Embedder
Welche Vektordatenbanken werden in SnapLogic unterstützt?
- Kiefernzapfen
- OpenSearch
- MongoDB
- Schneeflocke
- Postgres
- AlloyDB
Beispiele für Pipelines
Eine Textdatei einbetten
- Lesen Sie die Datei mit dem Snap „File Reader “.
- Konvertieren Sie die Binäreingabe mithilfe des Snap-Funktions „Binary to Document“ in ein Dokumentformat, da alle Einbettungsprogramme eine Dokumenteingabe erfordern.
- Betten Sie das Dokument mit dem von Ihnen gewählten Einbettungs- Snap ein.
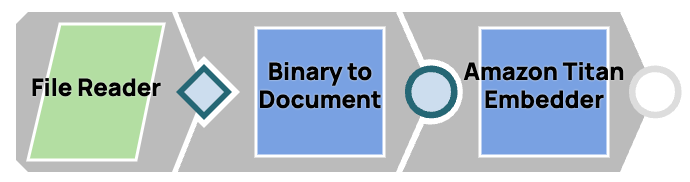
Abbildung 7. Eine Datei einbetten

Abbildung 8. Ausgabe des Embedder Snap
Einen Vektor speichern
- Verwenden Sie den JSON Generator Snap , um ein Dokument als Eingabe zu simulieren, das den Originaltext enthält, der in der Vektordatenbank gespeichert werden soll.
- Vektorisieren Sie den Originaltext mit dem Embedder-Snap.
- Verwenden Sie einen Mapper- Snap, um die Struktur in das von Pinecone geforderte Format zu bringen – das Vektorfeld heißt „values“ und der Originaltext sowie andere relevante Daten werden im Feld „metadata“ abgelegt.
- Speichern Sie die Daten in der Vektordatenbank mithilfe des Upsert/Insert -Snapshots der Vektordatenbank.

Abbildung 9. Speichern eines Vektors in der Datenbank

Abbildung 10. Ein Vektor in der Pinecone-Datenbank
Vektoren abrufen
- Verwenden Sie den JSON Generator Snap, um den abzufragenden Text zu simulieren.
- Vektorisieren Sie den Originaltext mit dem Embedder-Snap.
- Verwenden Sie einen Mapper-Snap, um die Struktur in das von Pinecone erforderliche Format zu bringen, und benennen Sie den Abfragevektor als „Vektor“.
- Rufen Sie den obersten Vektor ab, der der nächste Nachbar ist.

Abbildung 11. Vektoren aus einer Datenbank abrufen
[
{
"content" : "favorite sport"
}
]Abbildung 12. Abfragetext
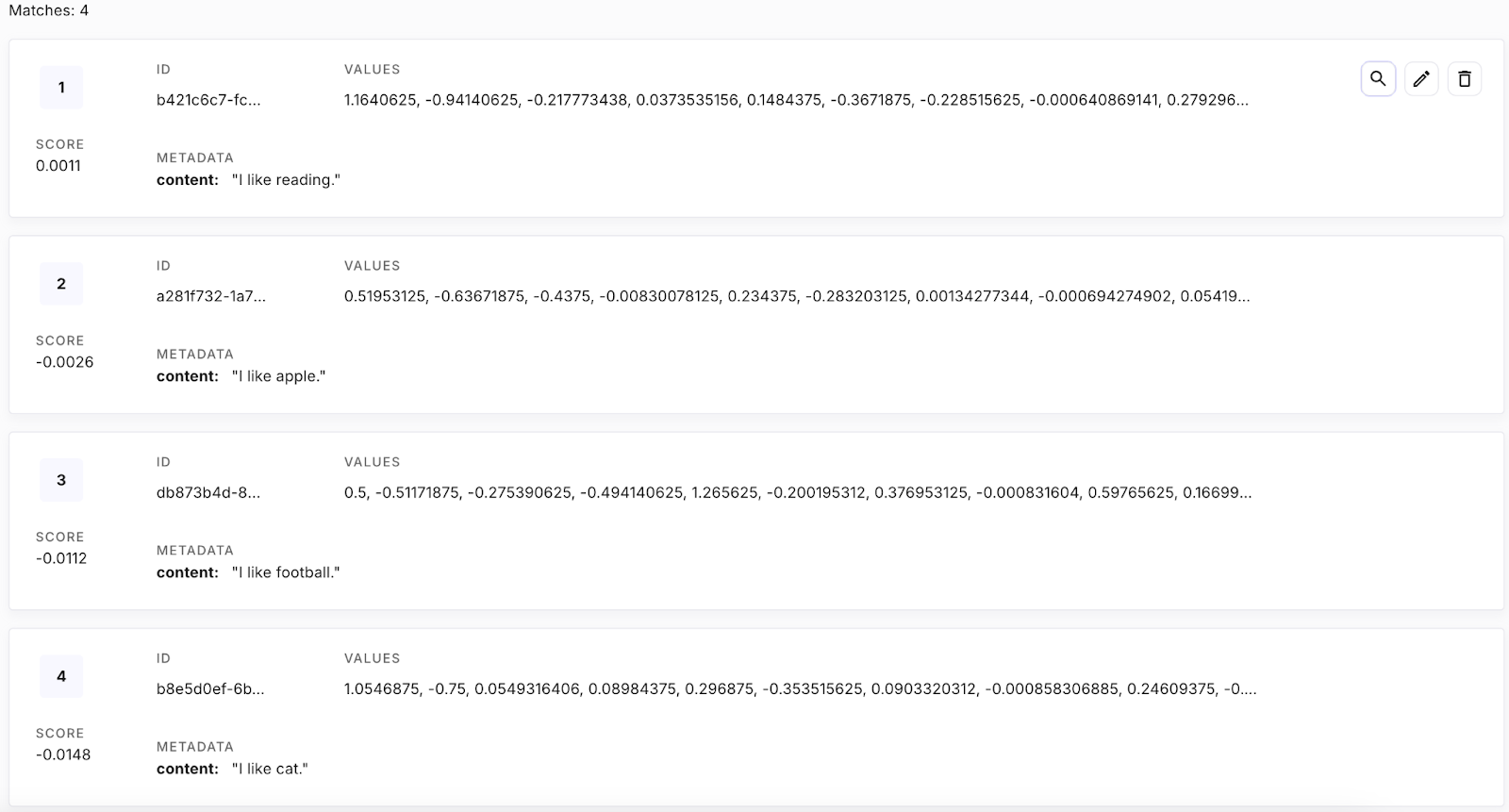
Abbildung 13. Alle Vektoren in der Datenbank
{
"matches": [
{
"id": "db873b4d-81d9-421c-9718-5a2c2bd9e720",
"score": 0.547461033,
"values": [],
"metadata": {
"content": "I like football."
}
}
]
}Abbildung 14. Pipeline-Ausgabe: Der nächstgelegene Nachbar zur Abfrage
Embedder- und Vektordatenbanken werden häufig in Anwendungen wie Retrieval Augmented Generation (RAG) und der Entwicklung von Chat-Assistenten eingesetzt.
Multimodale Einbettungen
Während der Schwerpunkt bisher auf Text-Embeddings lag, geht das Konzept über Wörter und Sätze hinaus. Multimodale Embeddings stellen einen bedeutenden Fortschritt dar, da sie die Darstellung verschiedener Datentypen wie Bilder, Audio und Video in einem einheitlichen Vektorraum ermöglichen. Durch die Projektion verschiedener Modalitäten in einen gemeinsamen semantischen Raum können komplexe Beziehungen und Interaktionen zwischen diesen Datentypen untersucht werden.
Beispielsweise könnten ein Bild einer Katze und das Wort „Katze“ in einem multimodalen Einbettungsraum nahe beieinander positioniert sein, was ihre semantische Ähnlichkeit widerspiegelt. Diese Fähigkeit eröffnet eine Vielzahl von Möglichkeiten, darunter die Bildersuche mit Textabfragen, das Verstehen von Videoinhalten und fortschrittliche Empfehlungssysteme, die mehrere Datenmodalitäten berücksichtigen.





