






Cosa sono gli embedding
Gli embedding sono rappresentazioni numeriche di oggetti del mondo reale, come testo, immagini o audio. Sono generati da modelli di apprendimento automatico come vettori, una serie di numeri, in cui la distanza tra i vettori può essere vista come il grado di somiglianza tra gli oggetti. Sebbene un modello di embedding possa avere un proprio significato per ciascuna delle dimensioni, non vi è alcuna garanzia tra i modelli di embedding del significato per ciascuna delle dimensioni utilizzate dai modelli di embedding.
Ad esempio, le parole "gatto", "cane" e "mela" potrebbero essere incorporate nei seguenti vettori:
gatto -> (1, -1, 2)
cane -> (1,5, -1,5, 1,8)
mela -> (-1, 2, 0)
Questi vettori sono stati inventati per semplificare l'esempio. I vettori reali sono molto più grandi, per maggiori dettagli consultare la sezione Dimensione.
Visualizzando questi vettori come punti in uno spazio 3D, possiamo vedere che"gatto"e "cane"sono più vicini, mentre"mela"è posizionata più lontano.
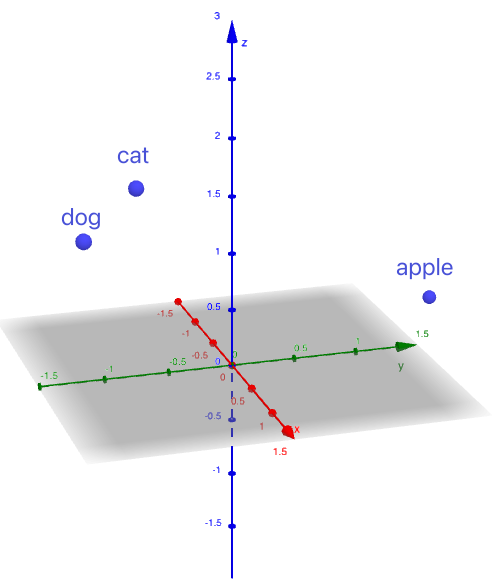
Figura 1. Vettori come punti in uno spazio 3D
Incorporando parole e contesti nei vettori, consentiamo ai sistemi di valutare quanto due elementi incorporati siano correlati tra loro tramite il confronto dei vettori.
Dimensione degli embedding
La dimensione degli embedding si riferisce alla lunghezza del vettore che rappresenta l'oggetto.
Nell'esempio precedente, abbiamo incorporato ogni parola in un vettore tridimensionale. Tuttavia, un'incorporazione tridimensionale porta inevitabilmente a una massiccia perdita di informazioni. In realtà, le incorporazioni di parole richiedono in genere centinaia o migliaia di dimensioni per catturare le sfumature del linguaggio.
Ad esempio,
- Il modello text-embedding-ada-002 di OpenAI genera un vettore a 1536 dimensioni.
- Il modello text-embedding-004 di Google Gemini genera un vettore a 768 dimensioni.
- Il modello amazon.titan-embed-text-v2:0 di Amazon Titan genera un vettore predefinito a 1024 dimensioni.

Figura 2. Utilizzo di text-embedding-ada-002 per incorporare la frase "Ho un gatto calico".
In breve, un embedding è un vettore che rappresenta un oggetto del mondo reale. La distanza tra questi vettori indica la somiglianza tra gli oggetti.
Limitazione dei modelli di incorporamento
I modelli di incorporamento sono soggetti a una limitazione fondamentale: il limite dei token, dove un token può essere una parola, un segno di punteggiatura o una parte di parola. Questo vincolo definisce la quantità massima di testo che un modello può elaborare in un singolo input. Ad esempio, i modelli Amazon Titan Text Embeddings possono gestire fino a 8.192 token.
Quando il testo inserito supera il limite, il modello in genere lo tronca, scartando le informazioni rimanenti. Ciò può comportare una perdita di contesto e una diminuzione della qualità dell'incorporamento, poiché potrebbero essere omessi dettagli cruciali.
Per affrontare questo problema, esistono diverse strategie che possono aiutare a mitigarne l'impatto:
- Sintesi o suddivisione del testo: i testi lunghi possono essere sintetizzati o suddivisi in parti più piccole e gestibili prima dell'incorporamento.
- Selezione del modello: i diversi modelli di incorporamento hanno limiti di token variabili. La scelta di un modello con un limite più elevato consente di gestire input più lunghi.
Che cos'è un database vettoriale
I database vettoriali sono ottimizzati per l'archiviazione di embedding, consentendo un recupero rapido e una ricerca per similarità. Calcolando la similarità tra il vettore di query e gli altri vettori nel database, il sistema restituisce i vettori con la similarità più elevata, indicando i contenuti più pertinenti.
Il diagramma seguente illustra una ricerca in un database vettoriale. Il vettore di query "sport preferito" viene confrontato con un insieme di vettori memorizzati, ciascuno dei quali rappresenta una frase di testo. Il risultato più vicino, "Mi piace il calcio", viene restituito come primo risultato.
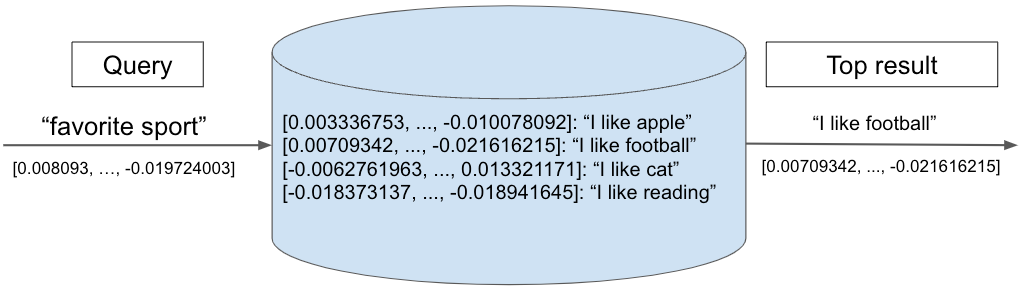
Figura 3. Esempio di query vettoriale

Figura 4. Memorizzazione dei vettori nel database

Figura 5. Recupero dei vettori dal database
Quando si lavora con database vettoriali, entrano in gioco due parametri chiave: Top K e misura di similarità (o funzione di distanza).
Top K
Quando si effettua una query su un database vettoriale, l'obiettivo è spesso quello di recuperare gli elementi più simili a un determinato vettore di query. È qui che entra in gioco il concetto di Top K. Top K si riferisce al recupero dei primi K elementi più simili in base a una metrica di similarità.
Ad esempio, se stai creando un sistema di raccomandazione dei prodotti, potresti voler trovare i 10 prodotti più simili a quello che l'utente sta visualizzando. In questo caso, K sarebbe 10. Il database vettoriale restituirebbe i 10 vettori di prodotti più vicini al vettore del prodotto oggetto della query.
Misure di similarità
Per determinare la somiglianza tra i vettori, vengono utilizzate varie metriche di distanza, tra cui:
- Similarità coseno: misura il coseno dell'angolo tra due vettori. È spesso utilizzata per applicazioni basate sul testo, poiché cattura bene la similarità semantica. Un valore più vicino a 1 indica una maggiore similarità.
- Distanza euclidea: calcola la distanza in linea retta tra due punti nello spazio euclideo. È sensibile alle differenze di grandezza tra i vettori.
- Distanza di Manhattan: nota anche come distanza L1, calcola la somma delle differenze assolute tra gli elementi corrispondenti di due vettori. È meno sensibile ai valori anomali rispetto alla distanza euclidea.
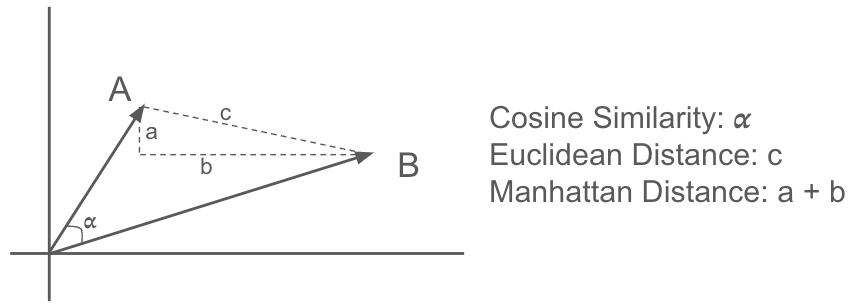
Figura 6. Misure di similarità
Esistono molte altre misure di similarità non elencate qui. La scelta della metrica di distanza dipende dall'applicazione specifica e dalla natura dei dati. Si consiglia di sperimentare varie metriche di similarità per vedere quale produce risultati migliori.
Quali embedder sono supportati in SnapLogic
A partire da ottobre 2024, SnapLogic supporta gli embedder per i modelli principali e continua ad ampliare il proprio supporto. Gli embedder supportati includono:
- Amazon Titan Embedder
- OpenAI Embedder
- Azure OpenAI Embedder
- Google Gemini Embedder
Quali database vettoriali sono supportati in SnapLogic?
- Pigna
- Ricerca aperta
- MongoDB
- Fiocco di neve
- Postgres
- AlloyDB
Esempi di pipeline
Incorpora un file di testo
- Leggi il file utilizzando lo snap File Reader.
- Converti l'input binario in un formato documento utilizzando lo snap Da binario a documento, poiché tutti gli embedder richiedono un input documento.
- Incorpora il documento utilizzando lo snap incorporatore che hai scelto.
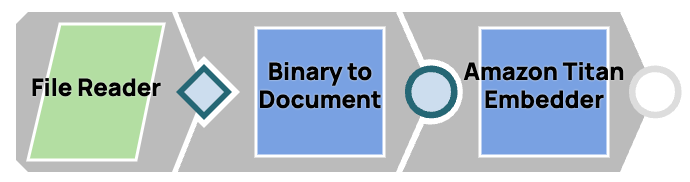
Figura 7. Incorporare un file

Figura 8. Output dello Snap Embedder
Memorizza un vettore
- Utilizza lo snap JSON Generator per simulare un documento come input, contenente il testo originale da memorizzare nel database vettoriale.
- Vectorizza il testo originale utilizzando lo snap dell'embedder.
- Utilizza uno snap mapper per formattare la struttura nel formato richiesto da Pinecone: il campo vettoriale è denominato "valori", mentre il testo originale e altri dati rilevanti sono inseriti nel campo "metadati".
- Memorizza i dati nel database vettoriale utilizzando lo snap upsert/insert del database vettoriale.

Figura 9. Memorizzazione di un vettore nel database

Figura 10. Un vettore nel database Pinecone
Recupera vettori
- Utilizza lo snap Generatore JSON per simulare il testo da interrogare.
- Vectorizza il testo originale utilizzando lo snap dell'embedder.
- Utilizza uno snap mapper per formattare la struttura nel formato richiesto da Pinecone, denominando il vettore di query come "vector".
- Recupera il vettore superiore 1, che è il vicino più prossimo.

Figura 11. Recupero dei vettori da un database
[
{
"content" : "favorite sport"
}
]Figura 12. Testo della query
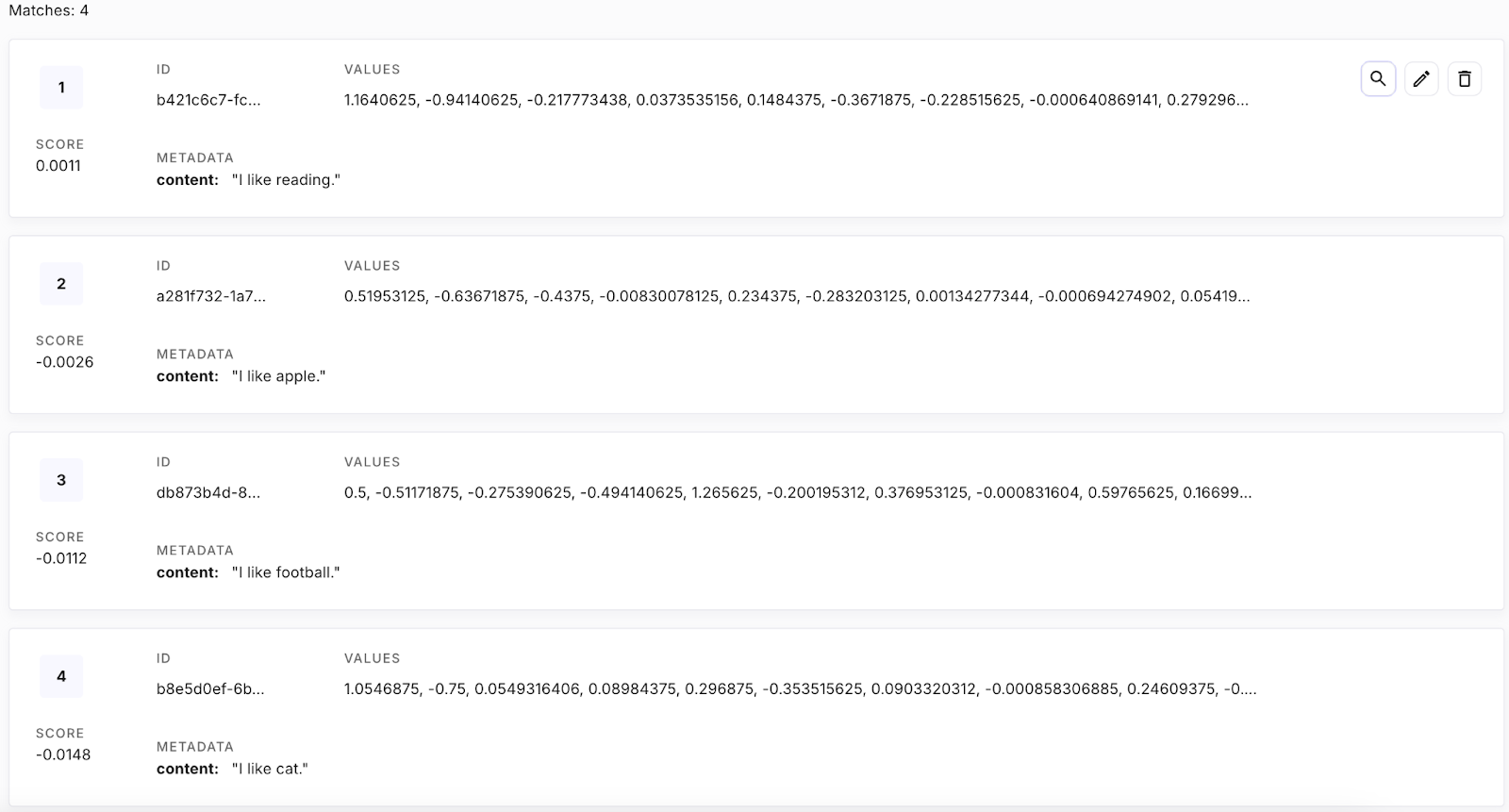
Figura 13. Tutti i vettori presenti nel database
{
"matches": [
{
"id": "db873b4d-81d9-421c-9718-5a2c2bd9e720",
"score": 0.547461033,
"values": [],
"metadata": {
"content": "I like football."
}
}
]
}Figura 14. Output della pipeline: il vicino più prossimo alla query
I database embedder e vettoriali sono ampiamente utilizzati in applicazioni quali Retrieval Augmented Generation (RAG) e nella creazione di assistenti di chat.
Incorporamenti multimodali
Sebbene finora l'attenzione si sia concentrata sugli embedding di testo, il concetto va oltre le parole e le frasi. Gli embedding multimodali rappresentano un potente progresso, consentendo la rappresentazione di vari tipi di dati, come immagini, audio e video, all'interno di uno spazio vettoriale unificato. Proiettando diverse modalità in uno spazio semantico condiviso, è possibile esplorare relazioni e interazioni complesse tra questi tipi di dati.
Ad esempio, l'immagine di un gatto e la parola "gatto" potrebbero essere posizionate vicine tra loro in uno spazio di incorporamento multimodale, riflettendo la loro somiglianza semantica. Questa capacità apre una vasta gamma di possibilità, tra cui la ricerca di immagini con query di testo, la comprensione dei contenuti video e sistemi di raccomandazione avanzati che prendono in considerazione più modalità di dati.





