






Que sont les intégrations ?
Les intégrations sont des représentations numériques d'objets du monde réel, tels que du texte, des images ou du son. Elles sont générées par des modèles d'apprentissage automatique sous forme de vecteurs, un ensemble de nombres, où la distance entre les vecteurs peut être considérée comme le degré de similitude entre les objets. Bien qu'un modèle d'intégration puisse avoir sa propre signification pour chacune des dimensions, il n'y a aucune garantie entre les modèles d'intégration quant à la signification de chacune des dimensions utilisées par les modèles d'intégration.
Par exemple, les mots « chat », « chien » et « pomme » pourraient être intégrés dans les vecteurs suivants :
chat -> (1, -1, 2)
chien -> (1,5, -1,5, 1,8)
pomme -> (-1, 2, 0)
Ces vecteurs sont inventés pour simplifier l'exemple. Les vecteurs réels sont beaucoup plus grands, voir la section Dimension pour plus de détails.
En visualisant ces vecteurs sous forme de points dans un espace 3D, nous pouvons voir que «chat »et «chien »sont plus proches, tandis que «pomme »est positionné plus loin.
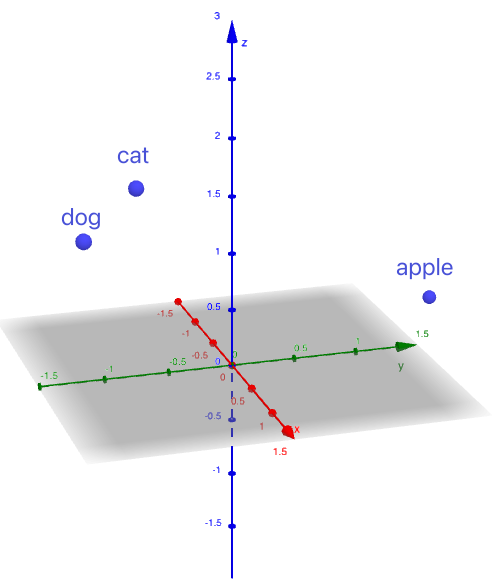
Figure 1. Vecteurs représentés sous forme de points dans un espace 3D
En intégrant des mots et des contextes dans des vecteurs, nous permettons aux systèmes d'évaluer le degré de parenté entre deux éléments intégrés via une comparaison vectorielle.
Dimension des intégrations
La dimension des intégrations fait référence à la longueur du vecteur représentant l'objet.
Dans l'exemple précédent, nous avons intégré chaque mot dans un vecteur à trois dimensions. Cependant, une intégration à trois dimensions entraîne inévitablement une perte massive d'informations. En réalité, les intégrations de mots nécessitent généralement des centaines, voire des milliers de dimensions pour saisir les nuances de la langue.
Par exemple,
- Le modèle text-embedding-ada-002 d'OpenAI génère un vecteur à 1536 dimensions.
- Le modèle text-embedding-004 de Google Gemini génère un vecteur à 768 dimensions.
- Le modèle amazon.titan-embed-text-v2:0 d'Amazon Titan génère un vecteur par défaut à 1024 dimensions.

Figure 2. Utilisation de text-embedding-ada-002 pour intégrer la phrase « J'ai un chat calicot ».
En bref, un encodage est un vecteur qui représente un objet du monde réel. La distance entre ces vecteurs indique la similitude entre les objets.
Limitation des modèles d'intégration
Les modèles d'intégration sont soumis à une limitation cruciale : la limite de jetons, où un jeton peut être un mot, un signe de ponctuation ou une partie de mot. Cette contrainte définit la quantité maximale de texte qu'un modèle peut traiter en une seule entrée. Par exemple, les modèles Amazon Titan Text Embeddings peuvent traiter jusqu'à 8 192 jetons.
Lorsque le texte saisi dépasse la limite, le modèle le tronque généralement, supprimant ainsi les informations restantes. Cela peut entraîner une perte de contexte et une diminution de la qualité de l'intégration, car des détails cruciaux peuvent être omis.
Pour y remédier, plusieurs stratégies peuvent contribuer à atténuer son impact :
- Résumé ou découpage du texte : les textes longs peuvent être résumés ou divisés en morceaux plus petits et plus faciles à gérer avant d'être intégrés.
- Sélection du modèle : les différents modèles d'intégration ont des limites de tokens variables. Choisir un modèle avec une limite plus élevée permet de traiter des entrées plus longues.
Qu'est-ce qu'une base de données vectorielle ?
Les bases de données vectorielles sont optimisées pour stocker des intégrations, ce qui permet une récupération rapide et une recherche par similarité. En calculant la similarité entre le vecteur de requête et les autres vecteurs de la base de données, le système renvoie les vecteurs présentant la plus grande similarité, indiquant ainsi le contenu le plus pertinent.
Le diagramme suivant illustre une recherche dans une base de données vectorielle. Un vecteur de requête « sport préféré » est comparé à un ensemble de vecteurs stockés, chacun représentant une expression textuelle. Le plus proche voisin, « J'aime le football », est renvoyé comme premier résultat.
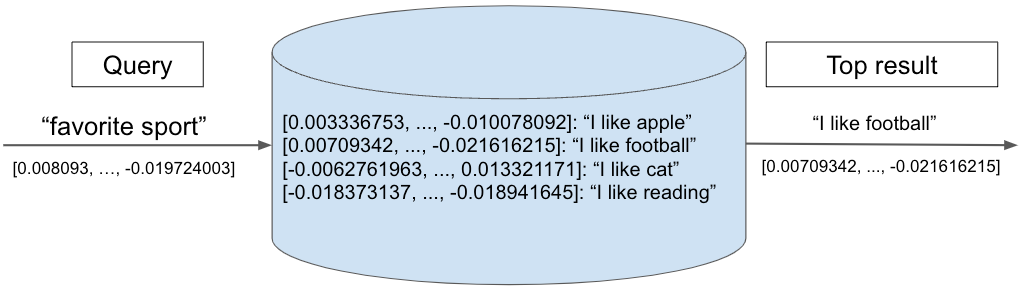
Figure 3. Exemple de requête vectorielle

Figure 4. Stockage des vecteurs dans la base de données

Figure 5. Récupération des vecteurs à partir de la base de données
Lorsque l'on travaille avec des bases de données vectorielles, deux paramètres clés entrent en jeu : Top K et la mesure de similarité (ou fonction de distance).
Top K
Lorsqu'on interroge une base de données vectorielle, l'objectif est souvent de récupérer les éléments les plus similaires à un vecteur de requête donné. C'est là qu'intervient le concept de Top K. Top K fait référence à la récupération des K éléments les plus similaires en fonction d'une mesure de similarité.
Par exemple, si vous développez un système de recommandation de produits, vous pouvez rechercher les 10 produits les plus similaires à celui qu'un utilisateur est en train de consulter. Dans ce cas, K serait égal à 10. La base de données vectorielle renverrait les 10 vecteurs de produits les plus proches du vecteur du produit recherché.
Mesures de similarité
Pour déterminer la similarité entre les vecteurs, diverses mesures de distance sont utilisées, notamment :
- Similitude cosinus : cette mesure calcule le cosinus de l'angle entre deux vecteurs. Elle est souvent utilisée pour les applications textuelles, car elle permet de bien saisir la similitude sémantique. Une valeur proche de 1 indique une similitude plus élevée.
- Distance euclidienne : calcule la distance en ligne droite entre deux points dans l'espace euclidien. Elle est sensible aux différences de magnitude entre les vecteurs.
- Distance de Manhattan : également appelée distance L1, elle calcule la somme des différences absolues entre les éléments correspondants de deux vecteurs. Elle est moins sensible aux valeurs aberrantes que la distance euclidienne.
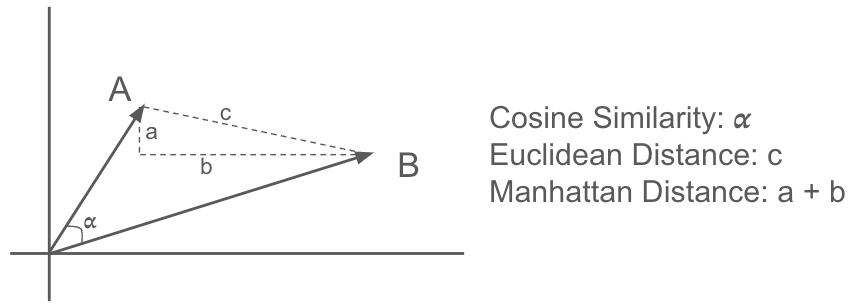
Figure 6. Mesures de similarité
Il existe de nombreuses autres mesures de similarité qui ne sont pas répertoriées ici. Le choix de la métrique de distance dépend de l'application spécifique et de la nature des données. Il est recommandé d'expérimenter différentes métriques de similarité afin de déterminer celle qui produit les meilleurs résultats.
Quels sont les intégrateurs pris en charge dans SnapLogic ?
Depuis octobre 2024, SnapLogic prend en charge les intégrateurs pour les principaux modèles et continue d'étendre sa prise en charge. Les intégrateurs pris en charge sont les suivants :
- Amazon Titan Embedder
- Intégrateur OpenAI
- Intégrateur Azure OpenAI
- Google Gemini Embedder
Quelles bases de données vectorielles sont prises en charge dans SnapLogic ?
- Pomme de pin
- OpenSearch
- MongoDB
- Flocon de neige
- Postgres
- AlloyDB
Exemples de pipelines
Intégrer un fichier texte
- Lisez le fichier à l'aide du snap File Reader.
- Convertissez l'entrée binaire en format document à l'aide du module complémentaire Binary to Document, car tous les modules d'intégration nécessitent une entrée de document.
- Intégrez le document à l'aide du snap d'intégration de votre choix.
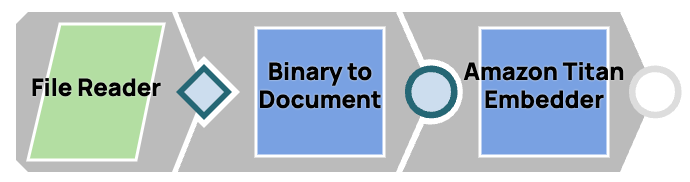
Figure 7. Intégrer un fichier

Figure 8. Résultat de l'Embedder Snap
Stocker un vecteur
- Utilisez le snap JSON Generator pour simuler un document en entrée, contenant le texte original à stocker dans la base de données vectorielle.
- Vectorisez le texte original à l'aide de l'outil Embedder Snap.
- Utilisez un snap mapper pour formater la structure au format requis par Pinecone : le champ vectoriel est nommé « valeurs », et le texte original ainsi que les autres données pertinentes sont placés dans le champ « métadonnées ».
- Stockez les données dans la base de données vectorielle à l'aide du snap upsert/insert de la base de données vectorielle.

Figure 9. Stockage d'un vecteur dans une base de données

Figure 10. Un vecteur dans la base de données Pinecone
Récupérer les vecteurs
- Utilisez le snap JSON Generator pour simuler le texte à interroger.
- Vectorisez le texte original à l'aide de l'outil Embedder Snap.
- Utilisez un snap mapper pour formater la structure au format requis par Pinecone, en nommant le vecteur de requête « vector ».
- Récupérer le vecteur supérieur 1, qui est le plus proche voisin.

Figure 11. Récupération de vecteurs à partir d'une base de données
[
{
"content" : "favorite sport"
}
]Figure 12. Texte de la requête
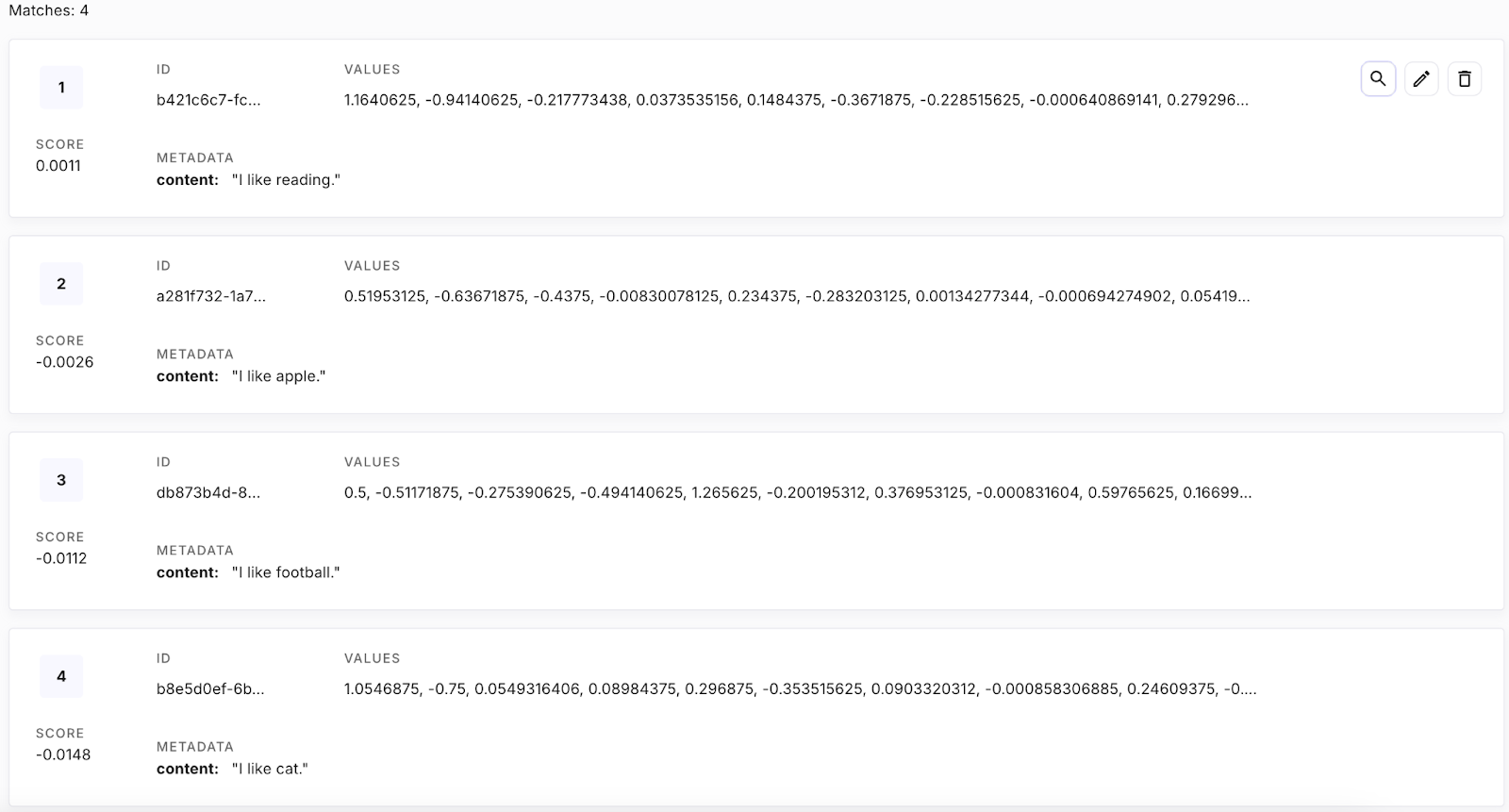
Figure 13. Tous les vecteurs dans la base de données
{
"matches": [
{
"id": "db873b4d-81d9-421c-9718-5a2c2bd9e720",
"score": 0.547461033,
"values": [],
"metadata": {
"content": "I like football."
}
}
]
}Figure 14. Résultat du pipeline : le plus proche voisin de la requête
Les bases de données d'embeddage et vectorielles sont largement utilisées dans des applications telles que la génération augmentée par la recherche (RAG) et la création d'assistants de chat.
Intégrations multimodales
Si, jusqu'à présent, l'accent a été mis sur les intégrations de texte, le concept va au-delà des mots et des phrases. Les intégrations multimodales représentent une avancée considérable, permettant la représentation de divers types de données, telles que les images, l'audio et la vidéo, dans un espace vectoriel unifié. En projetant différentes modalités dans un espace sémantique partagé, il est possible d'explorer les relations et les interactions complexes entre ces types de données.
Par exemple, l'image d'un chat et le mot « chat » peuvent être positionnés à proximité l'un de l'autre dans un espace d'intégration multimodal, reflétant ainsi leur similitude sémantique. Cette capacité ouvre un large éventail de possibilités, notamment la recherche d'images à partir de requêtes textuelles, la compréhension du contenu vidéo et les systèmes de recommandation avancés qui prennent en compte plusieurs modalités de données.





