






Auf hoher Ebene ist die Logik hinter dem Aufruf von Assistenzwerkzeugen und Nicht-Assistenzwerkzeugen im Grunde genommen dieselbe: Das Modell weist den Benutzer an, bestimmte Funktionen aufzurufen, um die Anfrage des Benutzers zu beantworten. Der Benutzer führt dann die Funktion aus und gibt das Ergebnis an das Modell zurück, das es zur Generierung einer Antwort verwendet. Dieser Prozess ist für beide identisch.
Da der Assistent jedoch die Funktionsdefinitionen und den Zugriff auf Tools als Teil der Assistentkonfiguration innerhalb des OpenAI- oder Azure OpenAI-Dashboards und nicht innerhalb Ihrer Pipelines festlegt, gibt es erhebliche Unterschiede in der Pipeline-Konfiguration. Darüber hinaus bringt das Übermitteln von Tool-Antworten an einen Assistenten erhebliche Änderungen und Herausforderungen mit sich, da der Assistent und nicht die Pipeline Eigentümer des Gesprächsverlaufs ist.
Dieser Artikel konzentriert sich auf die Gegenüberstellung dieser Unterschiede. Für ein detailliertes Verständnis von Assistenz-Pipelines und Nicht-Assistenz-Pipelines lesen Sie bitte den folgenden Artikel:
Nicht-Assistenz-Pipelines:Einführung von Tool Calling Snaps und LLM-Agent-Pipelines
Assistent-Pipelines:Einführung in Pipelines zum Aufrufen von Assistenz-Tools
Teil 1: Welches System soll verwendet werden: ohne Assistent oder mit Assistent?
Wann sollten Pipelines ohne Assistenz-Tools verwendet werden?
Nicht-Assistent-Tool-Aufruf-Pipelines bieten mehr Flexibilität und Kontrolle über den Tool-Aufrufprozess und eignen sich daher für die folgenden spezifischen Szenarien.
- Wenn Sie einen „Laufzeit“-Ansatz bevorzugen: Nicht-Assistent-Pipelines bieten eine größere Flexibilität bei der Funktionsdefinition und ermöglichen einen eher „laufzeitorientierten“ Ansatz. Sie können die verfügbaren Funktionen dynamisch anpassen, indem Sie einfach Function Generator-Snaps innerhalb der Pipeline hinzufügen oder entfernen.
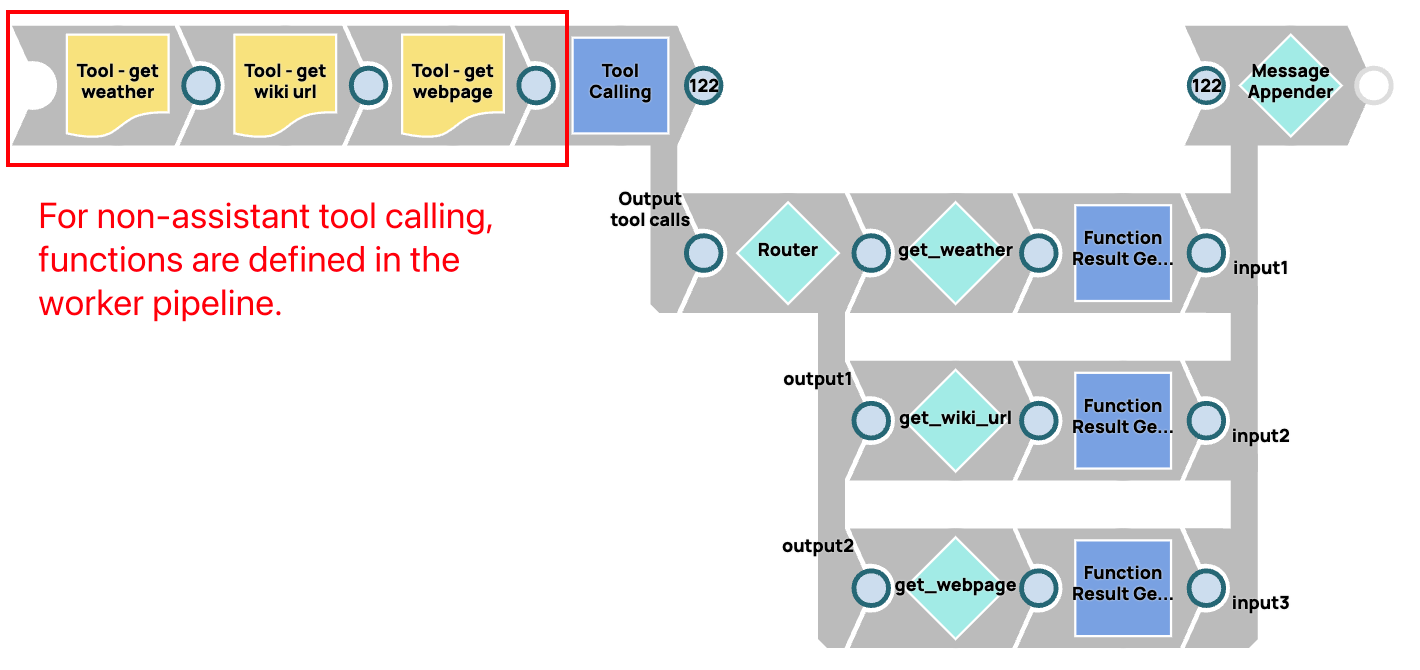
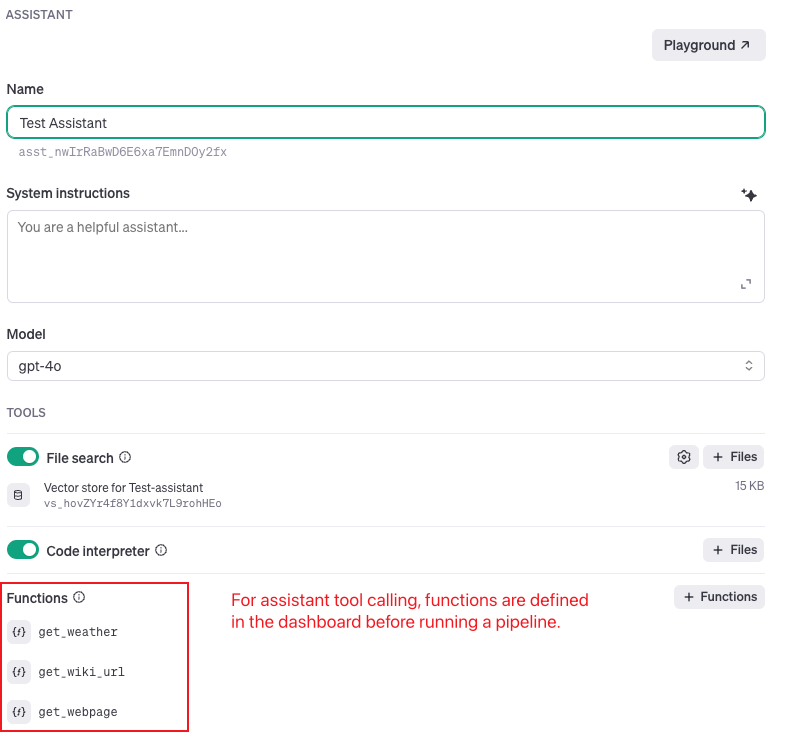
Im Gegensatz dazu erfordern Assistant Tool Calling Pipelines einen „Design-Time“-Ansatz. Alle verfügbaren Funktionen müssen in der Assistant-Konfiguration vordefiniert werden, was Änderungen an der Assistant-Definition im OpenAI/Azure OpenAI-Dashboard erforderlich macht.
- Wenn Sie einen detaillierten Chat-Verlauf wünschen: Nicht-Assistent-Pipelines bieten einen umfassenden Überblick über die Interaktion zwischen dem Modell und den Tools in der Ausgabemeldungsliste. Die Meldungsliste innerhalb der Nicht-Assistent-Pipeline speichert jede Modellantwort und die Ergebnisse jeder Funktionsausführung. Diese detaillierte Protokollierung ermöglicht eine gründliche Fehlerbehebung, Analyse und Überprüfung des Tool-Aufrufprozesses.

Im Gegensatz dazu behalten Assistant-Pipelines einen übersichtlicheren Nachrichtenverlauf bei, indem sie sich auf wichtige Schritte konzentrieren und einige Zwischendetails weglassen. Dies kann zwar die Gesamtübersicht über die Nachrichtenliste vereinfachen, aber auch die Nachverfolgung der genauen Abfolge von Ereignissen oder die Diagnose von Problemen erschweren, die während der Tool-Ausführung in untergeordneten Pipelines auftreten können.

Wann sollte das Assistant-Tool „Calling Pipelines“ verwendet werden?
Assistant Tool Calling Pipelines bieten auch einen optimierten Ansatz für die Integration von LLMs mit externen Tools, wobei Benutzerfreundlichkeit und integrierte Funktionen im Vordergrund stehen. Erwägen Sie den Einsatz von Assistant-Pipelines in den folgenden Situationen:
- Für eine vereinfachte Pipeline-Gestaltung: Assistant-Pipelines reduzieren die Komplexität der Pipeline, da keine Tool Generator-Snaps mehr erforderlich sind. In Non-Assistant-Pipelines sind diese Snaps für die dynamische Generierung von Tool-Definitionen innerhalb der Pipeline selbst unerlässlich. Bei Assistant-Pipelines werden die Tool-Definitionen vorab in den Assistant-Einstellungen im OpenAI/Azure OpenAI-Dashboard konfiguriert. Diese Vorkonfiguration führt zu kürzeren, besser verwaltbaren Pipelines und vereinfacht die Entwicklung und Wartung.
- Wenn die Nutzung integrierter Tools erforderlich ist: Wenn Ihr Anwendungsfall Funktionen wie die Suche in externen Dateien oder die Ausführung von Code erfordert, bieten Assistant-Pipelines diese Funktionen standardmäßig über ihre integrierten Tools „Dateisuche“ und „Code-Interpreter“ (weitere Details finden Sie in Teil 5). Diese Tools bieten eine bequeme und effiziente Möglichkeit, die Funktionen des LLM zu erweitern, ohne dass eine benutzerdefinierte Implementierung innerhalb der Pipeline erforderlich ist.
Teil 2: Eine kurze Einführung in zwei Pipelines
Nicht-Assistent-Tool, das Pipelines aufruft
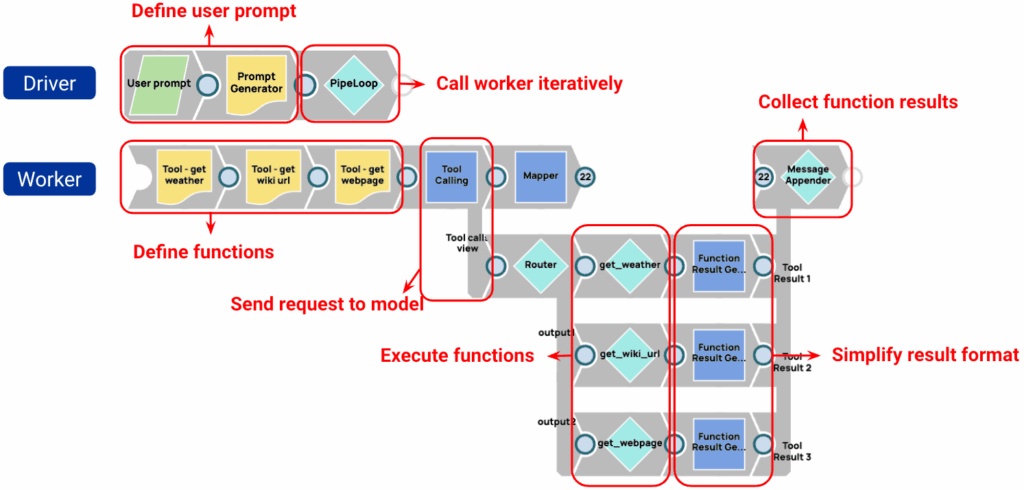
Wichtige Punkte:
- Funktionen werden im Worker definiert.
- Das Tool Calling Snap der Worker-Pipeline verwaltet alle Modellinteraktionen.
- Die Funktionsergebnisse werden gesammelt und in der nächsten Iteration über den Befehl „Tool Calling“ an das Modell gesendet.
Assistententool zum Aufrufen von Pipelines
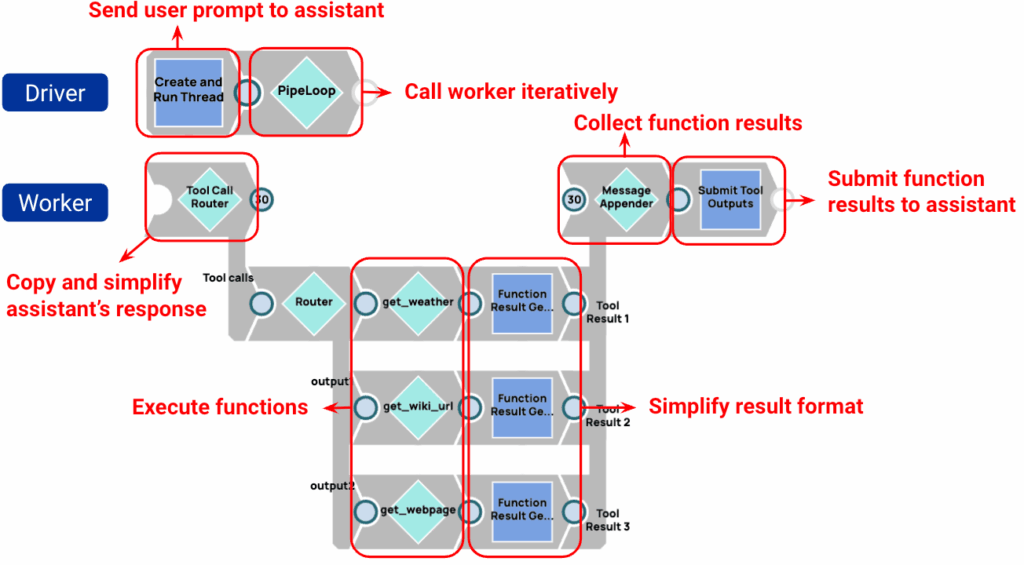
Wichtige Punkte:
- Es ist nicht erforderlich, Funktionen in einer Pipeline zu definieren. Die Funktionen sind im Assistenten vordefiniert.
- Zwei Schaltflächen: Interagieren Sie mit dem Modell:Thread erstellen und ausführen sowieTool-Ausgaben übermitteln.
- Die Funktionsergebnisse werden gesammelt und sofort während der aktuellen Iteration an das Modell gesendet.
Teil 3: Vergleich zwischen zwei Pipelines
Hier sind zwei Hauptgründe, warum sich die Pipelines für Assistenten und Nicht-Assistenten unterscheiden, aufgeführt in absteigender Reihenfolge ihrer Bedeutung:
- Unterschiedliche Methoden zur Übermittlung von Werkzeugergebnissen:
- Bei Nicht-Assistenz-Pipelines werden die Tool-Ergebnisse an die Nachrichtenverlaufsliste angehängt und anschließend bei dernächstenIteration an das Modell weitergeleitet.
Nicht-Assistenz-Pipelines weisen ein „While-Loop“-Verhalten auf, bei dem der Worker zu Beginn der Iteration mit dem Modell interagiert und, solange Tools aufgerufen werden müssen, diese Tools ausführt. - Im Gegensatz dazu werden die Ergebnisse der Tools für Assistenten speziell an einen dedizierten Endpunkt gesendet, der für die Verarbeitung der Tool-Aufrufergebnisse innerhalb deraktuellenIteration ausgelegt ist.
Die Assistenten-Pipelines funktionieren eher wie eine „do-while-Schleife“. Der Treiber initiiert die Interaktion, indem er die Eingabeaufforderung an das Modell sendet. Anschließend führt der Worker zuerst das/die Tool(s) aus und interagiert am Ende der Iteration mit dem Modell, um die Tool-Ergebnisse zu liefern.
- Bei Nicht-Assistenz-Pipelines werden die Tool-Ergebnisse an die Nachrichtenverlaufsliste angehängt und anschließend bei dernächstenIteration an das Modell weitergeleitet.
- Vordefinierte und gespeicherte Werkzeugdefinitionen für Assistenten:
- Im Gegensatz zu Pipelines ohne Assistenten können Assistenten Funktionsdefinitionen vordefinieren und speichern. Dadurch müssen die drei Function Generator-Snaps nicht mehr bei jeder Anfrage wiederholt Werkzeugdefinitionen an das Modell übertragen. Folglich erscheint die Worker-Pipeline für Assistenten kürzer.
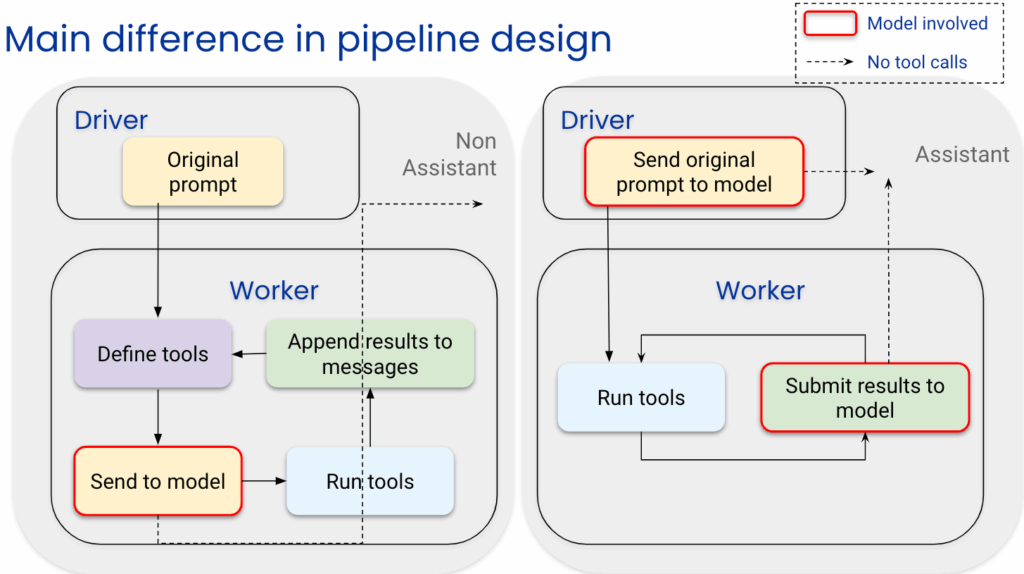
Aufgrund der oben genannten Unterschiede haben Nicht-Assistenz-Pipelines nur einen Interaktionspunkt mit dem Modell, der sich im Worker befindet.
Im Gegensatz dazu gibt es bei Assistenz-Pipelines zwei Interaktionspunkte: Der Fahrer sendet die erste Eingabeanforderung an das Modell, während der Mitarbeiter die Ergebnisse des Tools an das Modell zurücksendet.
Teil 4: Unterschiede bei den Snap-Einstellungen
Stoppbedingung von Pipeloop
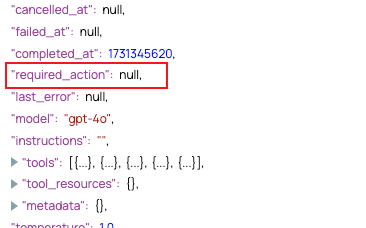
Ein wesentlicher Unterschied bei den Snap-Einstellungen liegt in der Stoppbedingung der Pipeloop.
- Stoppbedingung der Hilfsleitung:
$run.required_action == null. - Stoppbedingung für Nicht-Assistenz-Pipeline:
$finish_reason != "tool_calls".
Leistung des Assistenten
Beispiel, wenn Tool-Aufrufe erforderlich sind:

Beispiel, wenn Tool-Aufrufe NICHT erforderlich sind:
Leistung ohne Assistenten
Beispiel, wenn Tool-Aufrufe erforderlich sind:
Beispiel, wenn Tool-Aufrufe NICHT erforderlich sind:

Teil 5: Zwei integrierte Tools des Assistenten
Der Assistent unterstützt nicht nur alle Funktionen, die in Nicht-Assistent-Pipelines definiert werden können, sondern bietet auch zwei spezielle integrierte Funktionen: Dateisuche und Code-Interpreter, die dem Benutzer die Arbeit erleichtern.
Wenn das Modell feststellt, dass eines dieser Tools erforderlich ist, ruft es das Tool automatisch innerhalb des Assistenten auf und führt es aus, ohne dass ein manueller Eingriff durch den Benutzer erforderlich ist.
Sie benötigen kein Tool namens Pipeline, um mit der Dateisuche und dem Code-Interpreter zu experimentieren. Ein einfacher Thread-Snap zum Erstellen und Ausführen reicht aus.
Dateisuche
Die Dateisuche erweitert den Assistenten um Wissen, das außerhalb seines Modells liegt, wie beispielsweise proprietäre Produktinformationen oder Dokumente, die von Ihren Benutzern bereitgestellt werden. OpenAI analysiert und zerlegt Ihre Dokumente automatisch, erstellt und speichert die Einbettungen und nutzt sowohl die Vektor- als auch die Stichwortsuche, um relevante Inhalte zur Beantwortung von Benutzeranfragen abzurufen.
Beispiel
Frage: Wie viele Brände gab es zwischen 2018 und 2022 auf Bundesebene?
Die Antwort des Assistenten lautet wie folgt:
[
{
"messages": [
{
"id": "msg_cyvIQG7htmHnwTTbfkrES3ms",
"object": "thread.message",
"created_at": 1731106910,
"assistant_id": "asst_nwIrRaBwD6E6xa7EmnDOy2fx",
"thread_id": "thread_ciR3mFR1jEcXK07pX06jCRgM",
"run_id": "run_61Xt9zvpXLYxfgIfF7GV8Nz2",
"role": "assistant",
"content": [
{
"type": "text",
"text": {
"value": "The number of federal fires between 2018 and 2022 is as follows:nn- 2018: 12,500n- 2019: 10,900n- 2020: 14,400n- 2021: 14,000n- 2022: 11,700【4:1†wildfire_stats.pdf】.",
"annotations": [
{
"type": "file_citation",
"text": "【4:1†wildfire_stats.pdf】",
"start_index": 140,
"end_index": 164,
"file_citation": {
"file_id": "file-fJGINZ4R7XlIGtjfvv0W71CH"
}
}
]
}
}
],
"attachments": [],
"metadata": {}
},
{
"id": "msg_LBP4fengd7GlQnu7ZkfqvM2W",
"object": "thread.message",
"created_at": 1731106907,
"assistant_id": null,
"thread_id": "thread_ciR3mFR1jEcXK07pX06jCRgM",
"run_id": null,
"role": "user",
"content": [
{
"type": "text",
"text": {
"value": "What is the number of federal fires between 2018 and 2022",
"annotations": []
}
}
],
"attachments": [],
"metadata": {}
}
],
"run": {...}
}
]Die Antwort des Assistenten ist korrekt. Die Antwort auf die Eingabeaufforderung befindet sich in der ersten Zeile einer Tabelle auf der ersten Seite vonwildfire_stats.pdf, einem Dokument, auf das der Assistent über einen Vektorspeicher zugreifen kann.
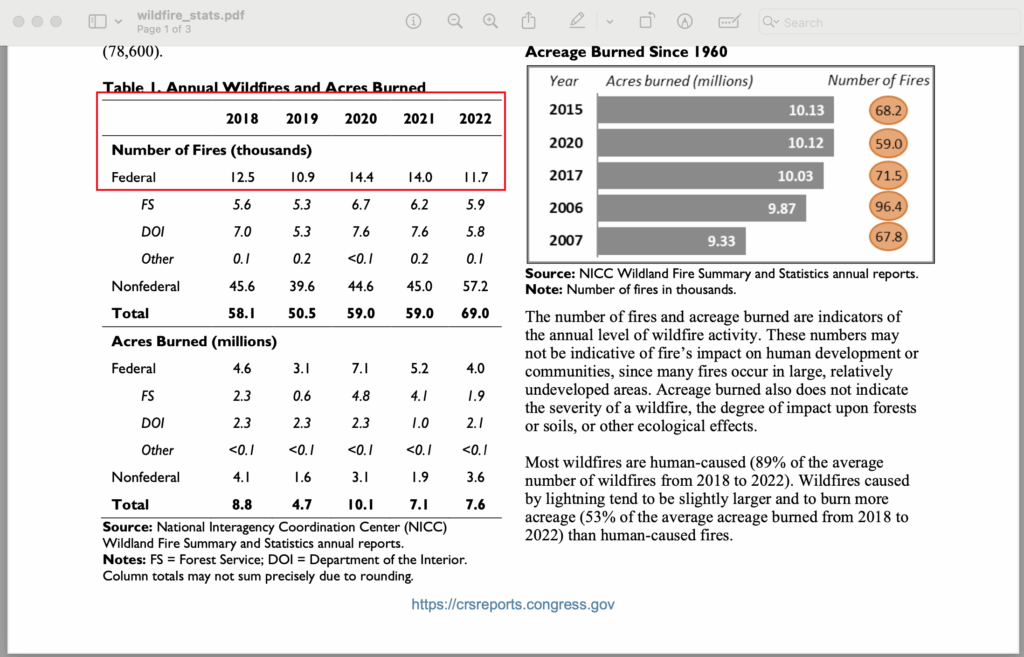
Die Datei wird in einem vom Assistenten verwendeten Vektorspeicher gespeichert:
Code-Interpreter
Mit Code Interpreter können Assistenten Python-Code in einer Sandbox-Ausführungsumgebung schreiben und ausführen. Dieses Tool kann Dateien mit unterschiedlichen Daten und Formatierungen verarbeiten und Dateien mit Daten und Grafiken generieren. Mit Code Interpreter kann Ihr Assistent Code iterativ ausführen, um anspruchsvolle Code- und Mathematikprobleme zu lösen. Wenn Ihr Assistent Code schreibt, der nicht ausgeführt werden kann, kann er diesen Code iterieren, indem er versucht, verschiedenen Code auszuführen, bis die Codeausführung erfolgreich ist.
Beispiel
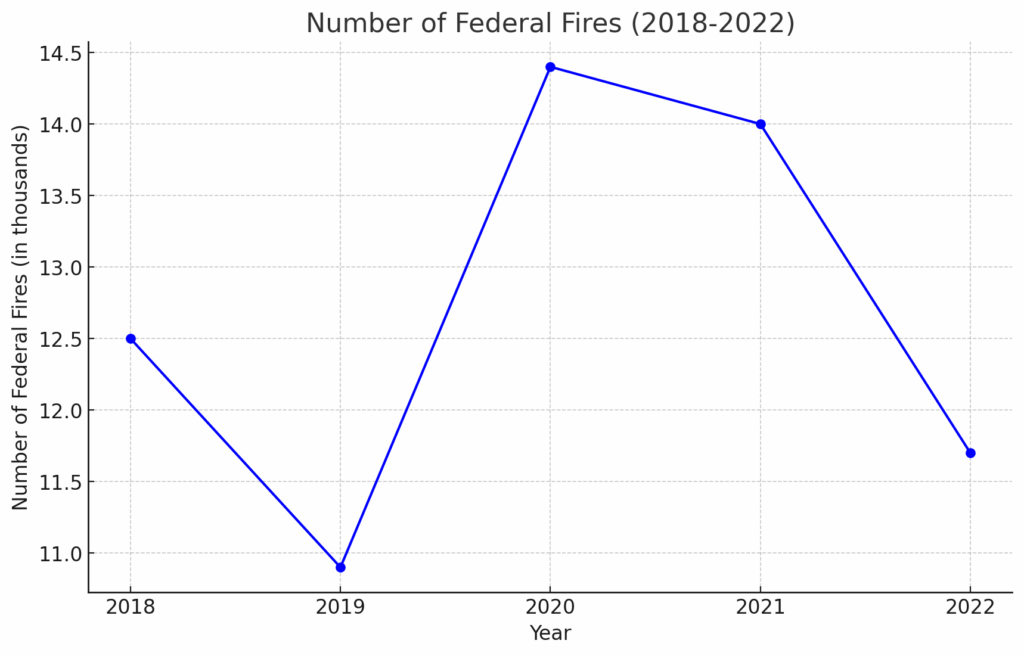
Aufgabe: Ermitteln Sie die Anzahl der Waldbrände zwischen 2018 und 2022 und erstellen Sie mit Matplotlib ein Liniendiagramm.
* Matplotlib ist eine Python-Bibliothek zum Erstellen von Diagrammen.
Die Antwort des Assistenten lautet wie folgt:
[
{
"messages": [
{
"id": "msg_lzBiM0J4sC0Zji510f1NOjjM",
"object": "thread.message",
"created_at": 1731108369,
"assistant_id": "asst_nwIrRaBwD6E6xa7EmnDOy2fx",
"thread_id": "thread_3q9AV6ivrYqqzsexv1rzMFSV",
"run_id": "run_DbjZQbBVQgoVge74PRbyGh44",
"role": "assistant",
"content": [
{
"type": "image_file",
"image_file": {
"file_id": "file-CLHOiYRfuWD45DsN6M4b8ga9"
}
},
{
"type": "text",
"text": {
"value": "Here is the line chart showing the number of federal fires from 2018 to 2022. As you can see, there is a fluctuation in the number of fires over these years, with a peak in 2020.",
"annotations": []
}
}
],
"attachments": [],
"metadata": {}
},
{
...,
"content": [
{
"type": "text",
"text": {
"value": "The number of federal fires between 2018 and 2022 was as follows:nn- 2018: 12.5 thousand firesn- 2019: 10.9 thousand firesn- 2020: 14.4 thousand firesn- 2021: 14.0 thousand firesn- 2022: 11.7 thousand fires【4:0†wildfire_stats.pdf】.nnI will now create a line chart using Matplotlib to represent this data.",
"annotations": [
{
"type": "file_citation",
"text": "【4:0†wildfire_stats.pdf】",
"start_index": 206,
"end_index": 230,
"file_citation": {
"file_id": "file-fJGINZ4R7XlIGtjfvv0W71CH"
}
}
]
}
}
],
...
},
{
...,
"content": [
{
"type": "text",
"text": {
"value": "Find the number of federal fires between 2018 and 2022 and use Matplotlib to draw a line chart.",
"annotations": []
}
}
],
...
}
],
"run": {...}
}
]Aus der Antwort geht hervor, dass der Assistent die Dateisuche verwendet hat, um Daten aus fünf Jahren zu finden, und anschließend eine Bilddatei erstellt hat. Diese Datei kann im Dashboard des Assistenten unter „Speicherdateien” heruntergeladen werden. Fügen Sie einfach eine Dateiendung wie .png hinzu, um das Bild anzuzeigen.
Teil 6: Zusammenfassung der wichtigsten Unterschiede
| Funktion | Nicht-Assistent-Tool-Aufruf-Pipelines | Assistent-Tool-Aufruf-Pipelines |
|---|---|---|
| Funktionsdefinition | Definiert innerhalb der Arbeiter-Pipeline mithilfe von Funktionsgenerator-Snaps. | Vordefiniert und gespeichert in der Assistentenkonfiguration im OpenAI/Azure OpenAI-Dashboard. |
| Einreichung der Werkzeugergebnisse | An den Nachrichtenverlauf angehängt und in dernächstenIteration an das Modell gesendet. | An einen dedizierten Endpunkt innerhalb deraktuellenIteration gesendet. |
| Modell-Interaktionspunkte | Eins (in der Arbeiter-Pipeline). | Zwei (Fahrer sendet erste Aufforderung, Arbeiter sendet Werkzeugergebnisse). |
| Integrierte Tools | Keine. | Dateisuche und Code-Interpreter. |
| Komplexität der Pipeline | Komplexere Pipeline-Struktur aufgrund der Funktionsdefinition innerhalb der Pipeline. | Einfachere Pipeline-Struktur, da Funktionen extern definiert werden. |






