






À un niveau élevé, la logique qui sous-tend l'appel d'un outil assistant et l'appel d'un outil non assistant est fondamentalement la même : le modèle demande à l'utilisateur d'appeler une ou plusieurs fonctions spécifiques afin de répondre à sa requête. L'utilisateur exécute alors la fonction et renvoie le résultat au modèle, qui l'utilise pour générer une réponse. Ce processus est identique pour les deux.
Cependant, étant donné que l'assistant spécifie les définitions de fonction et l'accès aux outils dans le cadre de la configuration de l'assistant dans le tableau de bord OpenAI ou Azure OpenAI plutôt que dans vos pipelines, il y aura des différences majeures dans la configuration du pipeline. De plus, la soumission des réponses des outils à un assistant s'accompagne de changements et de défis importants, car c'est l'assistant qui détient l'historique des conversations plutôt que le pipeline.
Cet article se concentre sur la mise en évidence de ces différences. Pour une compréhension détaillée des pipelines assistants et non assistants, veuillez vous reporter à l'article suivant :
Pipelines sans assistant :présentation des snaps d'appel d'outils et des pipelines d'agents LLM
Pipelines d'assistant :présentation des pipelines d'appel d'outils d'assistant
Partie 1 : Quel système utiliser : sans assistant ou avec assistant ?
Quand utiliser les pipelines d'appel d'outils non assistants :
Les pipelines d'appel d'outils non assistants offrent une plus grande flexibilité et un meilleur contrôle sur le processus d'appel d'outils, ce qui les rend adaptés aux scénarios spécifiques suivants.
- Lorsque vous préférez une approche « runtime » : Les pipelines non assistants offrent une plus grande flexibilité dans la définition des fonctions, proposant une approche plus axée sur le « temps d'exécution ». Vous pouvez ajuster dynamiquement les fonctions disponibles en ajoutant ou en supprimant simplement des snaps Générateur de fonctions dans le pipeline.
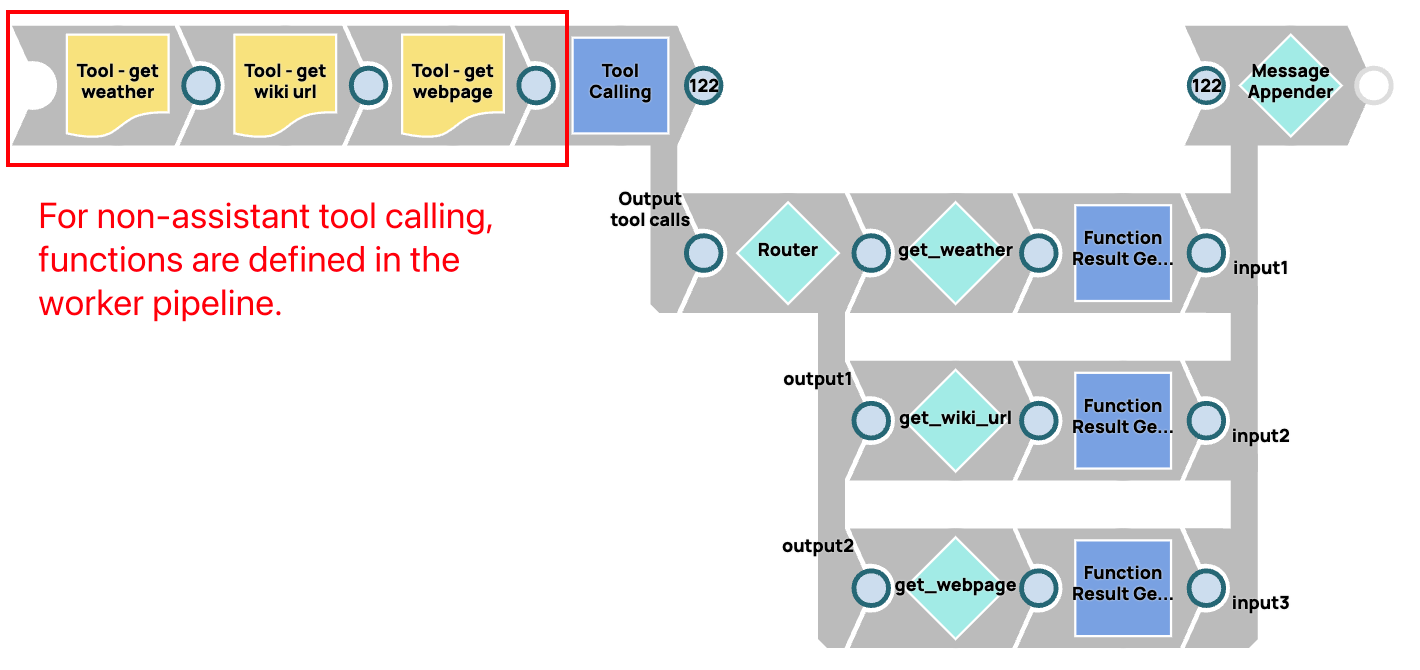
En revanche, les pipelines d'appel d'outils Assistant nécessitent une approche « au moment de la conception ». Toutes les fonctions disponibles doivent être prédéfinies dans la configuration Assistant, ce qui nécessite des modifications de la définition Assistant dans le tableau de bord OpenAI/Azure OpenAI.
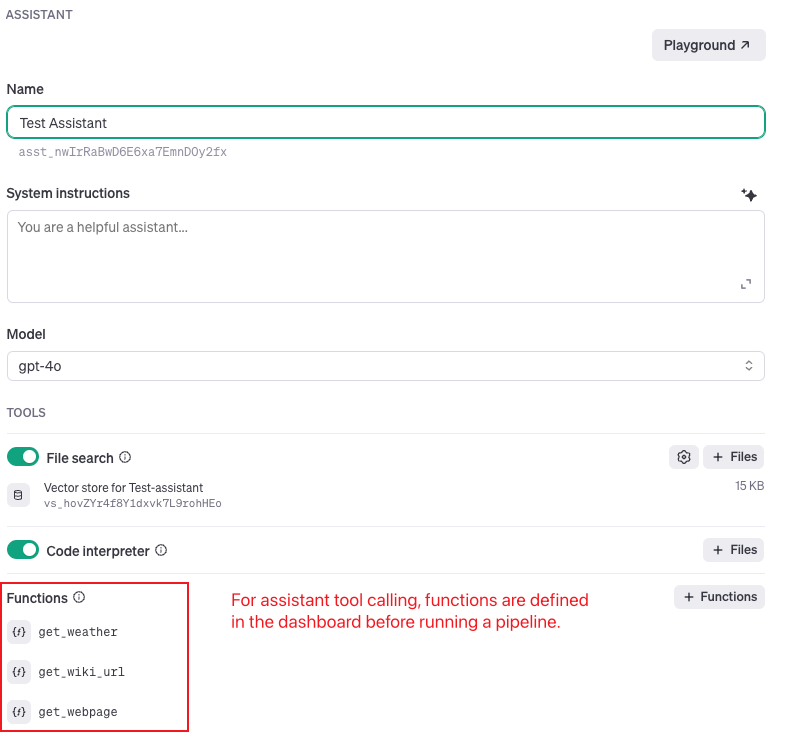
- Lorsque vous souhaitez obtenir l'historique détaillé des discussions : Les pipelines non assistants fournissent un historique complet des interactions entre le modèle et les outils dans la liste des messages de sortie. La liste des messages dans le pipeline non assistant conserve chaque réponse du modèle et les résultats de chaque exécution de fonction. Cette journalisation détaillée permet un débogage, une analyse et un audit approfondis du processus d'appel de l'outil.

En revanche, les pipelines assistants conservent un historique des messages plus concis, en se concentrant sur les étapes clés et en omettant certains détails intermédiaires. Si cela peut simplifier la vue d'ensemble de la liste des messages, cela peut également rendre plus difficile le suivi de la séquence exacte des événements ou le diagnostic des problèmes pouvant survenir lors de l'exécution des outils dans les pipelines enfants.

Quand utiliser l'outil Assistant Calling Pipelines :
Les pipelines d'appel d'outils Assistant offrent également une approche simplifiée pour intégrer les LLM à des outils externes, en privilégiant la facilité d'utilisation et les fonctionnalités intégrées. Envisagez d'utiliser les pipelines Assistant dans les situations suivantes :
- Pour une conception simplifiée des pipelines : les pipelines Assistant réduisent la complexité des pipelines en éliminant le besoin de snaps Tool Generator. Dans les pipelines Non-Assistant, ces snaps sont essentiels pour générer dynamiquement des définitions d'outils au sein même du pipeline. Avec les pipelines Assistant, les définitions d'outils sont configurées à l'avance dans les paramètres Assistant du tableau de bord OpenAI/Azure OpenAI. Cette préconfiguration permet d'obtenir des pipelines plus courts et plus faciles à gérer, ce qui simplifie le développement et la maintenance.
- Lorsque l'utilisation d'outils intégrés est nécessaire : si votre cas d'utilisation nécessite des fonctionnalités telles que la recherche de fichiers externes ou l'exécution de code, les pipelines Assistant offrent ces capacités prêtes à l'emploi grâce à leurs outils intégrés de recherche de fichiers et d'interprétation de code (voir la partie 5 pour plus de détails). Ces outils constituent un moyen pratique et efficace d'étendre les capacités du LLM sans nécessiter de mise en œuvre personnalisée au sein du pipeline.
Partie 2 : Brève présentation de deux pipelines
Outils non assistants appelant des pipelines
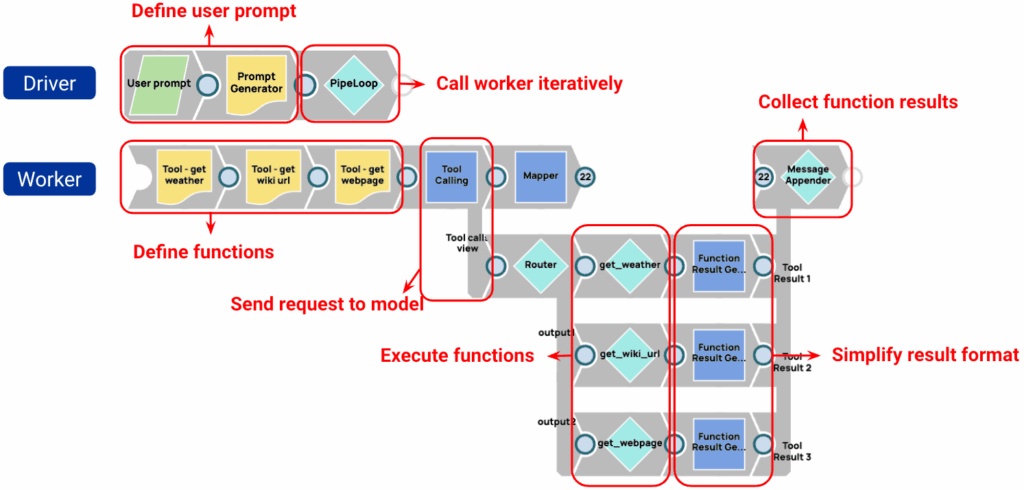
Points clés :
- Les fonctions sont définies dans le worker.
- Le snap Tool Calling du pipeline de travail gère toutes les interactions avec les modèles.
- Les résultats des fonctions sont collectés et envoyés au modèle lors de la prochaine itération via le snap Tool Calling.
Outil assistant appelant des pipelines
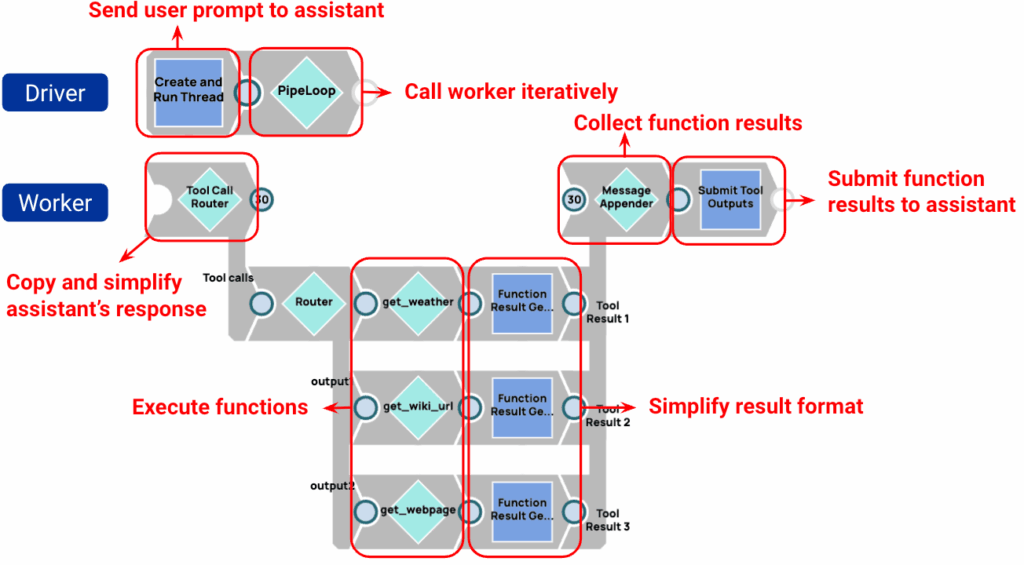
Points clés :
- Il n'est pas nécessaire de définir des fonctions dans un pipeline. Les fonctions sont prédéfinies dans l'assistant.
- Deux clics : interagir avec le modèle :créer et exécuter un thread, etsoumettre les résultats de l'outil.
- Les résultats des fonctions sont collectés et envoyés immédiatement au modèle pendant l'itération en cours.
Partie 3 : Comparaison entre deux pipelines
Voici deux raisons principales pour lesquelles les pipelines assistant et non assistant diffèrent, classées par ordre décroissant d'importance :
- Différentes méthodes pour soumettre les résultats des outils :
- Pour les pipelines non assistants, les résultats des outils sont ajoutés à la liste de l'historique des messages, puis transmis au modèle lors de l'itérationsuivante.
Les pipelines non assistants présentent un comportement de type « boucle while », dans lequel le travailleur interagit avec le modèle au début de l'itération et, si des outils doivent être appelés, il exécute ces outils. - En revanche, pour les assistants, les résultats des outils sont spécifiquement envoyés à un point de terminaison dédié conçu pour traiter les résultats des appels d'outils dans l'itérationen cours.
Les pipelines des assistants fonctionnent davantage comme une « boucle do-while ». Le pilote initie l'interaction en envoyant l'invite au modèle. Ensuite, le travailleur exécute d'abord le ou les outils et interagit avec le modèle à la fin de l'itération pour fournir les résultats des outils.
- Pour les pipelines non assistants, les résultats des outils sont ajoutés à la liste de l'historique des messages, puis transmis au modèle lors de l'itérationsuivante.
- Définitions d'outils prédéfinies et enregistrées pour les assistants :
- Contrairement aux pipelines sans assistant, les assistants ont la capacité de prédéfinir et de stocker des définitions de fonctions. Cela élimine la nécessité pour les trois snaps Function Generator de transmettre de manière répétée les définitions d'outils au modèle à chaque requête. Par conséquent, le pipeline de travail pour les assistants semble plus court.
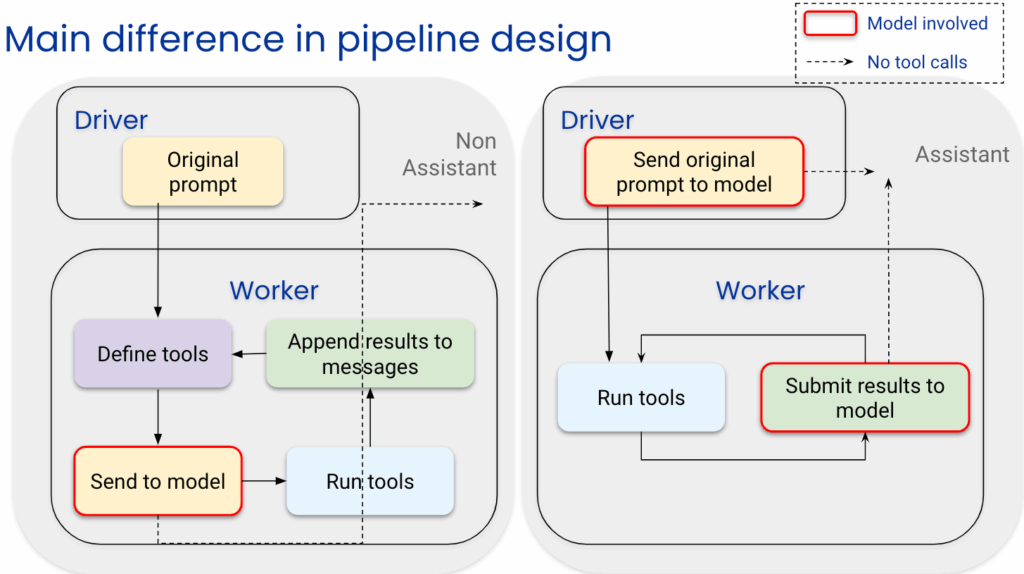
En raison des différences susmentionnées, les pipelines non assistants n'ont qu'un seul point d'interaction avec le modèle, situé dans le travailleur.
En revanche, les pipelines assistants impliquent deux points d'interaction : le pilote envoie la requête initiale au modèle, tandis que le travailleur renvoie les résultats de l'outil au modèle.
Partie 4 : Différences dans les paramètres de snap
Condition d'arrêt de Pipeloop
Une différence essentielle dans les paramètres de snap réside dans la condition d'arrêt de la boucle de pipeline.
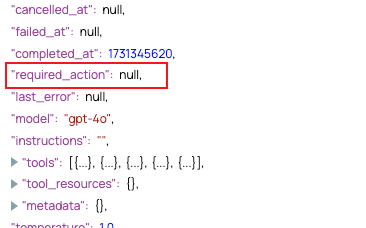
- Condition d'arrêt du pipeline assistant :
$run.required_action == null. - Condition d'arrêt du pipeline non assistant :
$finish_reason != "tool_calls".
Résultats de l'assistant
Exemple où des appels d'outils sont nécessaires :

Exemple où les appels d'outils ne sont PAS nécessaires :
Production des non-assistants
Exemple où des appels d'outils sont nécessaires :
Exemple où les appels d'outils ne sont PAS nécessaires :

Partie 5 : Les deux outils intégrés de l'assistant
L'assistant prend non seulement en charge toutes les fonctions pouvant être définies dans les pipelines sans assistant, mais fournit également deux fonctions intégrées spéciales, recherche de fichiers et interprétation de code, pour plus de commodité pour l'utilisateur.
Si le modèle détermine que l'un de ces outils est nécessaire, il appellera et exécutera automatiquement l'outil dans l'assistant sans nécessiter d'intervention manuelle de l'utilisateur.
Vous n'avez pas besoin d'un outil appelé pipeline pour tester la recherche de fichiers et l'interpréteur de code. Il suffit de créer et d'exécuter un simple thread snap.
Recherche de fichiers
La recherche de fichiers enrichit l'assistant avec des connaissances provenant de l'extérieur de son modèle, telles que des informations propriétaires sur les produits ou des documents fournis par vos utilisateurs. OpenAI analyse et découpe automatiquement vos documents, crée et stocke les intégrations, et utilise à la fois la recherche vectorielle et la recherche par mot-clé pour récupérer le contenu pertinent afin de répondre aux requêtes des utilisateurs.
Exemple
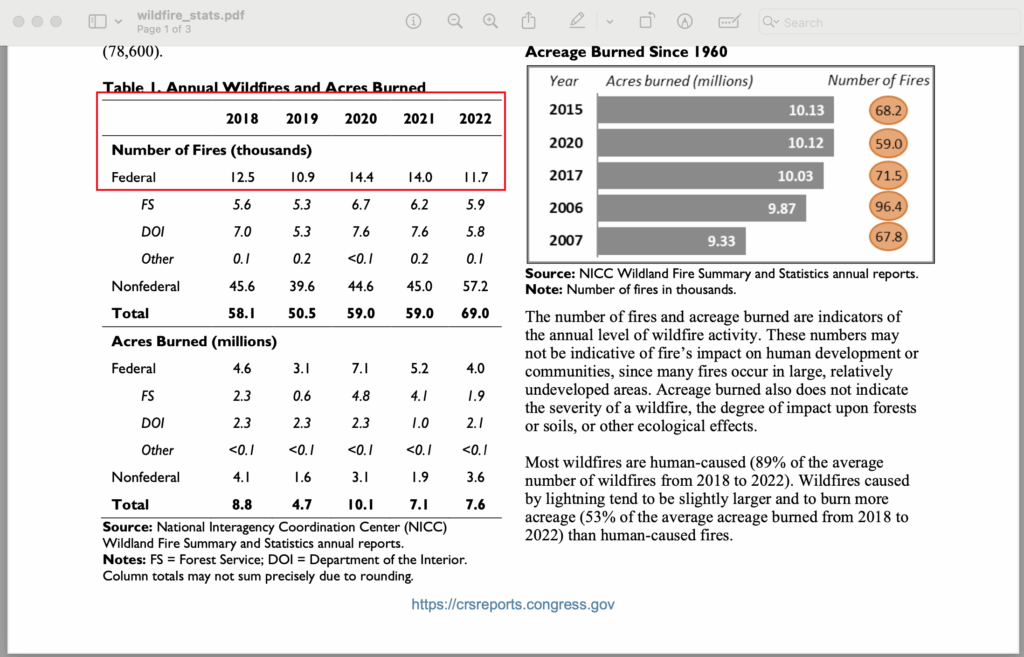
Question : Quel est le nombre d'incendies fédéraux entre 2018 et 2022 ?
La réponse de l'assistant est la suivante :
[
{
"messages": [
{
"id": "msg_cyvIQG7htmHnwTTbfkrES3ms",
"object": "thread.message",
"created_at": 1731106910,
"assistant_id": "asst_nwIrRaBwD6E6xa7EmnDOy2fx",
"thread_id": "thread_ciR3mFR1jEcXK07pX06jCRgM",
"run_id": "run_61Xt9zvpXLYxfgIfF7GV8Nz2",
"role": "assistant",
"content": [
{
"type": "text",
"text": {
"value": "The number of federal fires between 2018 and 2022 is as follows:nn- 2018: 12,500n- 2019: 10,900n- 2020: 14,400n- 2021: 14,000n- 2022: 11,700【4:1†wildfire_stats.pdf】.",
"annotations": [
{
"type": "file_citation",
"text": "【4:1†wildfire_stats.pdf】",
"start_index": 140,
"end_index": 164,
"file_citation": {
"file_id": "file-fJGINZ4R7XlIGtjfvv0W71CH"
}
}
]
}
}
],
"attachments": [],
"metadata": {}
},
{
"id": "msg_LBP4fengd7GlQnu7ZkfqvM2W",
"object": "thread.message",
"created_at": 1731106907,
"assistant_id": null,
"thread_id": "thread_ciR3mFR1jEcXK07pX06jCRgM",
"run_id": null,
"role": "user",
"content": [
{
"type": "text",
"text": {
"value": "What is the number of federal fires between 2018 and 2022",
"annotations": []
}
}
],
"attachments": [],
"metadata": {}
}
],
"run": {...}
}
]La réponse de l'assistant est correcte. La réponse à la question se trouve dans la première ligne d'un tableau figurant à la première page du documentwildfire_stats.pdf, accessible à l'assistant via un magasin vectoriel.
Le fichier est stocké dans un magasin vectoriel utilisé par l'assistant :
Interprète de code
Code Interpreter permet aux assistants d'écrire et d'exécuter du code Python dans un environnement d'exécution sandboxé. Cet outil peut traiter des fichiers contenant des données et des formats variés, et générer des fichiers contenant des données et des images de graphiques. Code Interpreter permet à votre assistant d'exécuter du code de manière itérative afin de résoudre des problèmes complexes liés au code et aux mathématiques. Lorsque votre assistant écrit du code qui ne fonctionne pas, il peut itérer sur ce code en essayant d'exécuter différents codes jusqu'à ce que l'exécution du code aboutisse.
Exemple
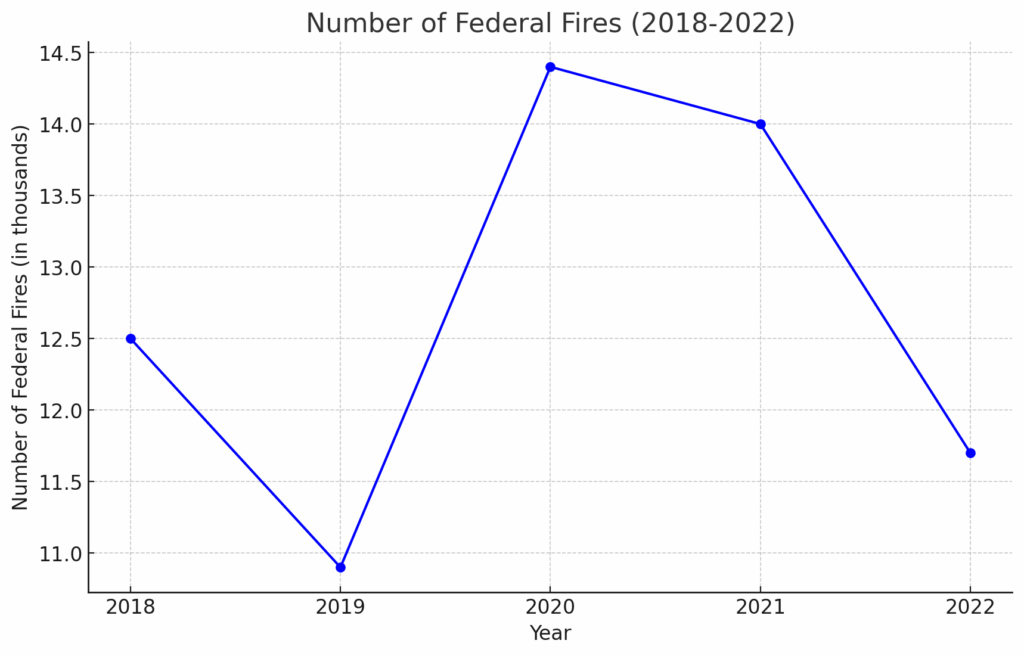
Consigne : Trouvez le nombre d'incendies fédéraux entre 2018 et 2022 et utilisez Matplotlib pour tracer un graphique linéaire.
* Matplotlib est une bibliothèque Python permettant de créer des graphiques.
La réponse de l'assistant est la suivante :
[
{
"messages": [
{
"id": "msg_lzBiM0J4sC0Zji510f1NOjjM",
"object": "thread.message",
"created_at": 1731108369,
"assistant_id": "asst_nwIrRaBwD6E6xa7EmnDOy2fx",
"thread_id": "thread_3q9AV6ivrYqqzsexv1rzMFSV",
"run_id": "run_DbjZQbBVQgoVge74PRbyGh44",
"role": "assistant",
"content": [
{
"type": "image_file",
"image_file": {
"file_id": "file-CLHOiYRfuWD45DsN6M4b8ga9"
}
},
{
"type": "text",
"text": {
"value": "Here is the line chart showing the number of federal fires from 2018 to 2022. As you can see, there is a fluctuation in the number of fires over these years, with a peak in 2020.",
"annotations": []
}
}
],
"attachments": [],
"metadata": {}
},
{
...,
"content": [
{
"type": "text",
"text": {
"value": "The number of federal fires between 2018 and 2022 was as follows:nn- 2018: 12.5 thousand firesn- 2019: 10.9 thousand firesn- 2020: 14.4 thousand firesn- 2021: 14.0 thousand firesn- 2022: 11.7 thousand fires【4:0†wildfire_stats.pdf】.nnI will now create a line chart using Matplotlib to represent this data.",
"annotations": [
{
"type": "file_citation",
"text": "【4:0†wildfire_stats.pdf】",
"start_index": 206,
"end_index": 230,
"file_citation": {
"file_id": "file-fJGINZ4R7XlIGtjfvv0W71CH"
}
}
]
}
}
],
...
},
{
...,
"content": [
{
"type": "text",
"text": {
"value": "Find the number of federal fires between 2018 and 2022 and use Matplotlib to draw a line chart.",
"annotations": []
}
}
],
...
}
],
"run": {...}
}
]D'après la réponse, nous pouvons voir que l'assistant a indiqué avoir utilisé la recherche de fichiers pour trouver 5 ans de données, puis généré un fichier image. Ce fichier peut être téléchargé à partir du tableau de bord de l'assistant, sous « storage-files » (fichiers de stockage). Il suffit d'ajouter une extension de fichier telle que .png pour voir l'image.
Partie 6 : Résumé des principales différences
| Fonctionnalité | Outils non assistants appelant des pipelines | Outils d'assistance appelant des pipelines |
|---|---|---|
| Définition de fonction | Défini dans le pipeline de travail à l'aide des snaps du générateur de fonctions. | Pré-définis et enregistrés dans la configuration de l'Assistant dans le tableau de bord OpenAI/Azure OpenAI. |
| Soumission des résultats des outils | Ajouté à l'historique des messages et envoyé au modèle lors de laprochaineitération. | Envoyé à un point de terminaison dédié dans l'itérationactuelle. |
| Points d'interaction du modèle | Un (dans le pipeline des travailleurs). | Deux (le conducteur envoie la demande initiale, l'ouvrier envoie les résultats de l'outil). |
| Outils intégrés | Aucun. | Recherche de fichiers et interpréteur de code. |
| Complexité des pipelines | Structure de pipeline plus complexe en raison de la définition des fonctions au sein du pipeline. | Structure de pipeline simplifiée grâce à la définition externe des fonctions. |






