





SnapLogic ermöglicht es Unternehmen, die Hürden für die Einführung von Hadoop (und jetzt Spark mit unserer Version vom Herbst 2015) zu überwinden und ihre Vision eines Data Lake zu verwirklichen. Unsere Elastic Integration Platform unterstützt Unternehmen in allen drei Phasen der Data Lake-Architektur: Ingestion, Vorbereitung und Bereitstellung.
Wenn wir darüber nachdenken, wie wir Unternehmen in die Lage versetzen können, die Vision des Data Lake zu verwirklichen, spielen einige Faktoren eine entscheidende Rolle:
- Möglichkeit der Aufnahme strukturierter, unstrukturierter und halbstrukturierter Daten mit einer einzigen Lösung, unabhängig davon, wo sie sich befinden, durch eine Datenaufnahme-Pipeline.
- Fähigkeit, diese Daten sowohl in Echtzeit als auch im Batch-Modus zu nutzen.
- Die Fähigkeit, diese Daten innerhalb von Hadoop umzuwandeln (wir nennen es SnapReduce), ohne komplexen MapReduce-Code schreiben zu müssen. (auch bekannt als "Hadoop für Menschen")
- Fähigkeit, umgewandelte Daten an beliebige Analyseplattformen zu liefern - direkt an Tableau-Benutzer, an AWS Redshift oder Microsoft Azure SQL oder an eine On-Premise-Datenbank (hier ist ein großartiger Artikel von Martin Fowler über den Data Lake und "Lakeshore-Marts")
In diesem Beitrag (meinem ersten!) werde ich einige leistungsstarke SnapLogic-Datenfluss-Pipelines vorstellen, die diese und andere Anforderungen erfüllen. Jede dieser Pipelines, von der Pipeline für die Datenaufnahme bis zur Pipeline für die Bereitstellung, kann natürlich ausgelöst oder als Task geplant werden, und jede kann in eine API umgewandelt und von anderen Anwendungen aufgerufen werden. (Weitere Einzelheiten dazu finden Sie hier.)
Pipeline 1: Daten-Ingestion
SnapLogic verfügt über mehr als 300 vorgefertigte Konnektoren und Microservices, die Snaps genannt werden. Diese Dateningestionspipeline liefert sowohl unstrukturierte als auch relationale Daten an Hadoop. Snaps umfassen: Microsoft SQL Server und MySQL (strukturiert, On-Premise), Twitter (unstrukturiert, Cloud).
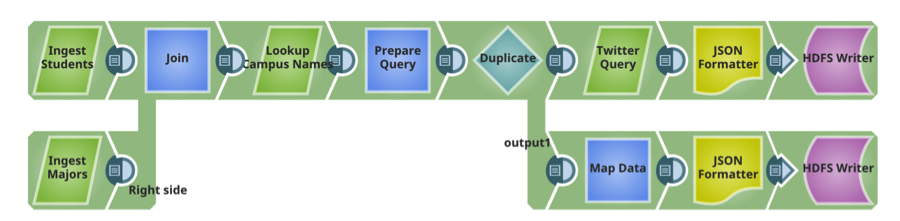
Rohrleitung 2: Vorbereiten
Diese Pipeline liest die beiden Dateien, die in der vorherigen Pipeline auf HDFS übertragen wurden, führt Sortierungen und Filter (Transformationen) durch und schreibt die transformierte Datei zurück auf HDFS.
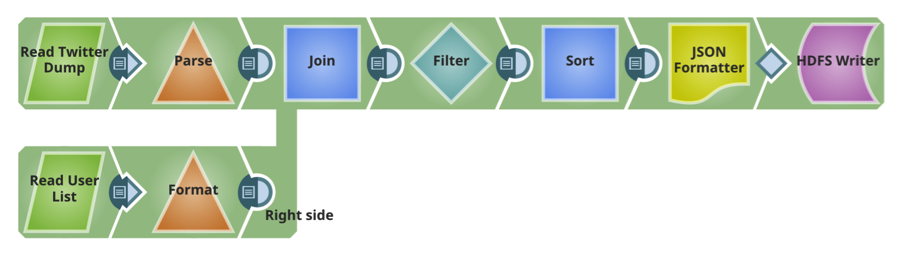
Pipeline 3: Bereitstellen
Diese Pipeline liest die umgewandelte Datei und übergibt sie unverändert an ein AWS Redshift Cloud Data Warehouse. Außerdem extrahiert diese Pipeline bestimmte Informationen aus der Datei und liefert sie direkt an Benutzer von Birst zur weiteren Analyse.
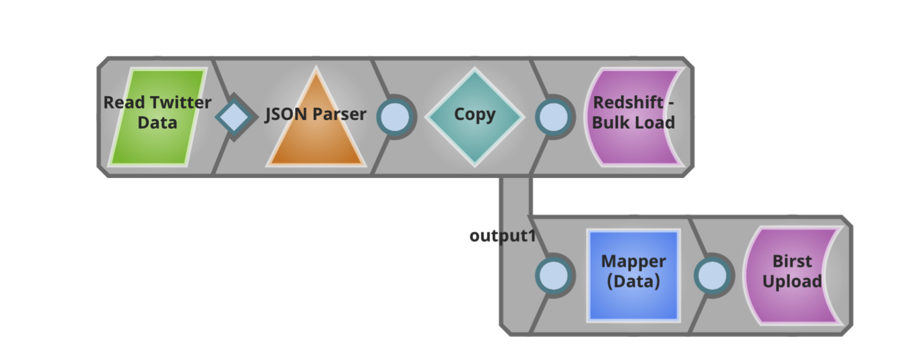
Es ist spannend, mit SnapLogic-Kunden, Interessenten und Partnern über die gesamte Dateneingabe-Pipeline hinweg zusammenzuarbeiten und zu erörtern, wie ein neuer Ansatz für Unternehmensdaten und -anwendungen zu einer schnelleren Wertschöpfung führen kann. Wenn Sie mehr über SnapLogic Big Data Integration erfahren möchten, besuchen Sie unsere Demo-Site. Außerdem finden Sie hier einen nützlichen Überblick über unsere Big Data-Verarbeitungsfunktionen.





