





SnapLogic consente alle organizzazioni di superare le barriere all'adozione di Hadoop (e ora di Spark con la release dell'autunno 2015) e di realizzare la loro visione del Data Lake. La nostra Elastic Integration Platform aiuta le organizzazioni in tutte e tre le fasi dell'architettura del data lake: ingestione, preparazione e consegna.
Quando pensiamo di consentire alle organizzazioni di realizzare la visione del Data Lake, ci sono alcuni fattori che giocano un ruolo fondamentale:
- Capacità di ingerire dati strutturati, non strutturati e semi-strutturati con un'unica soluzione, indipendentemente dalla loro ubicazione, attraverso una pipeline di ingestione dei dati.
- Possibilità di consumare questi dati sia in tempo reale che in modalità batch.
- Capacità di trasformare questi dati all'interno di Hadoop (lo chiamiamo SnapReduce) senza dover scrivere codice MapReduce complesso. (alias "Hadoop per umani")
- Capacità di fornire i dati trasformati a qualsiasi piattaforma di analisi, a seconda dei casi: direttamente agli utenti di Tableau, ad AWS Redshift o Microsoft Azure SQL o a un database on-premise (ecco un ottimo articolo di Martin Fowler sul Data Lake e sui "lakeshore marts").
In questo post (il mio primo!), esaminerò alcune potenti pipeline dataflow di SnapLogic che rispondono a questi e ad altri requisiti. Ciascuna di queste pipeline, dalla pipeline di ingestione dei dati alla pipeline di consegna, può ovviamente essere attivata o programmata e può essere trasformata in un'API e richiamata da altre applicazioni. (Maggiori dettagli su questo aspetto sono disponibili qui).
Pipeline 1: Acquisizione dei dati
SnapLogic offre oltre 300 connettori predefiniti e microservizi denominati "Snaps". Questa pipeline di acquisizione dei dati trasferisce dati sia non strutturati che relazionali a Hadoop. Gli Snaps includono: Microsoft SQL Server e MySQL (dati strutturati, on-premise), Twitter (dati non strutturati, cloud).
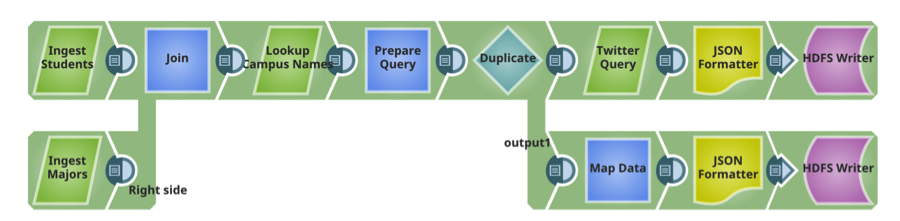
Condotta 2: Preparare
Questa pipeline legge i due file consegnati su HDFS nella pipeline precedente, esegue ordinamenti e filtri (trasformazioni) e scrive il file trasformato su HDFS.
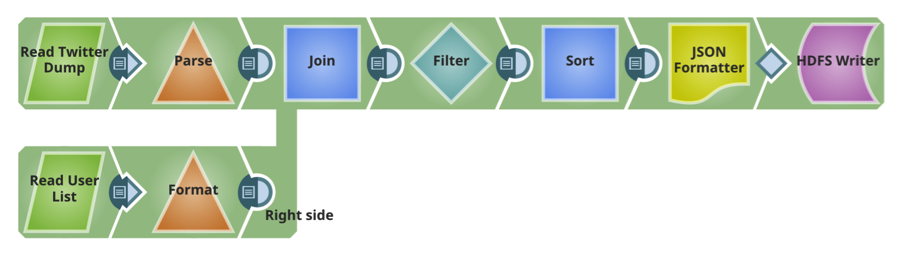
Pipeline 3: Invio a
Questa pipeline legge il file trasformato e lo invia così com'è a un cloud warehouse cloud AWS Redshift. Inoltre, questa pipeline estrae informazioni specifiche dal file e le invia direttamente agli utenti di Birst per ulteriori analisi.
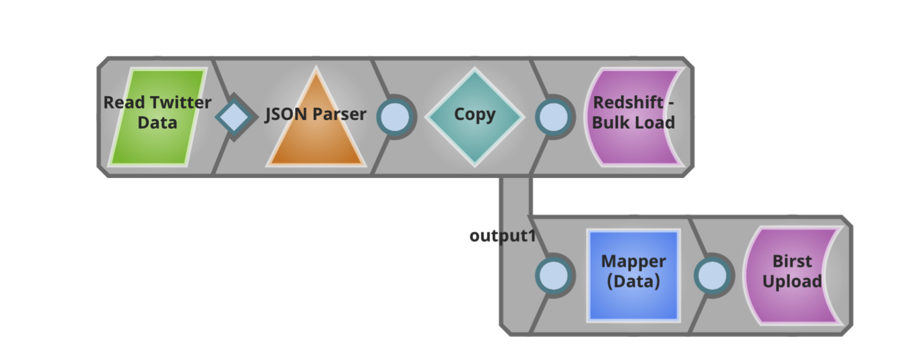
È entusiasmante poter lavorare con i clienti, i potenziali clienti e i partner di SnapLogic lungo tutta la pipeline di ingestione dei dati e discutere di come un nuovo approccio ai dati e alle applicazioni aziendali possa garantire un time to value più rapido. Per saperne di più sull'integrazione dei big data di SnapLogic, visitate il nostro sito demo. Inoltre, ecco una panoramica delle nostre capacità di elaborazione dei big data che dovrebbe essere utile.






