





SnapLogic enables organizations to overcome the barriers to adoption of Hadoop (and now Spark with our Fall 2015 release) and realize their vision of the Data Lake. Our Elastic Integration Platform helps organizations in all the three phases of the data lake architecture: ingestion, preparation and delivery.
When we think about enabling organizations to realize the vision of the Data Lake, there are a few factors that play a critical role:
- Ability to ingest structured, unstructured and semi-structured data with a single solution, irrespective of where they are located through a data ingestion pipeline.
- Ability to consume this data in both real time and batch modes.
- Ability to transform this data inside of Hadoop (we call it SnapReduce) without having to write complex MapReduce code. (aka “Hadoop for Humans”)
- Ability to deliver transformed data to any analytics platforms as appropriate – could be directly to Tableau users, could be to AWS Redshift or Microsoft Azure SQL or an on-prem database (here’s a great article by Martin Fowler on the Data Lake and “lakeshore marts”)
In this post (my first!), I’ll review some powerful SnapLogic dataflow pipelines that address these and other requirements. Each of these pipelines, from the data ingestion pipeline to the delivery pipeline, can of course be triggered or scheduled tasks and each can be turned into an API and called by other applications. (More details on that here.)
Pipeline 1: Data Ingestion
SnapLogic 300+ pre-built connectors and microservices called Snaps. This data ingestion pipeline delivers both unstructured and relational data to Hadoop. Snaps include: Microsoft SQL Server and MySQL (structured, on-prem), Twitter (unstructured, cloud).
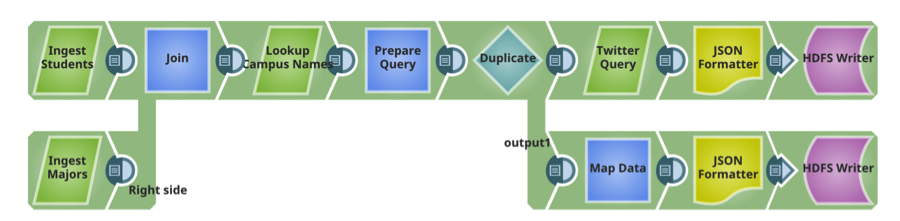
Pipeline 2: Prepare
This pipeline reads the two files delivered onto HDFS in the previous pipeline, performs sorts and filters (transformations) and writes the transformed file back to HDFS.
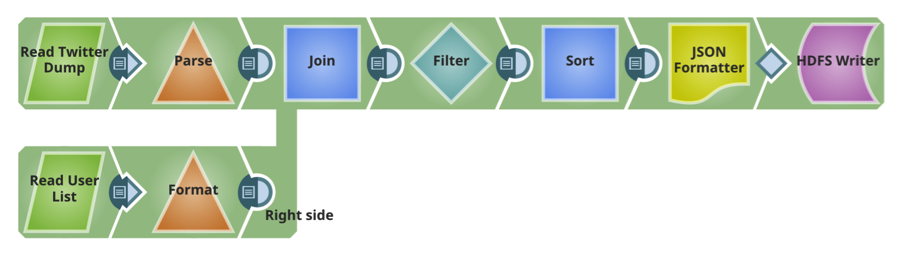
Pipeline 3: Deliver
This pipeline reads the transformed file and delivers as is to an AWS Redshift cloud data warehouse. Also, this pipeline extracts specific information from the file and delivers it directly to users of Birst for further analysis.
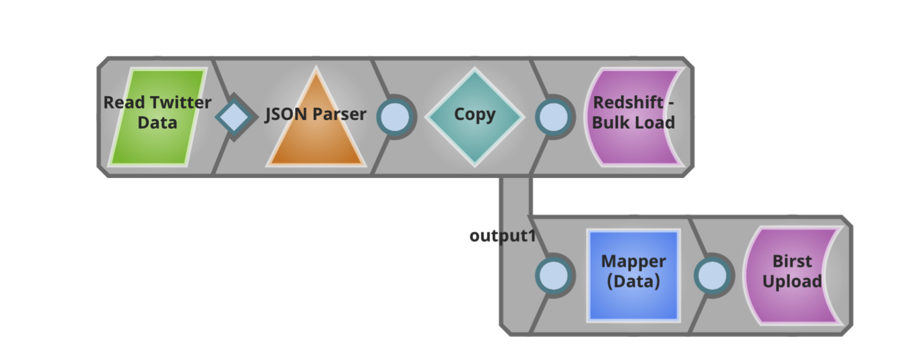
It’s exciting to be able to work with SnapLogic customers, prospects and partners throughout the data ingestion pipeline and to discuss how a new approach to enterprise data and application can deliver a faster time to value. To learn more about SnapLogic big data integration, check out our demo site. Also here’s an overview of our big data processing capabilities that should be useful.





