





SnapLogic permet aux entreprises de surmonter les obstacles à l‘adoption d‘Hadoop (et maintenant de Spark avec notre version de l‘automne 2015) et de réaliser leur vision du lac de données. Notre plateforme d‘intégration élastique aide les organisations dans les trois phases de l‘architecture du lac de données : ingestion, préparation et livraison.
Lorsqu‘il s‘agit de permettre aux organisations de concrétiser la vision du lac de données, quelques facteurs jouent un rôle essentiel :
- Capacité d‘ingérer des données structurées, non structurées et semi-structurées à l‘aide d‘une solution unique, quel que soit l‘endroit où elles se trouvent, grâce à un pipeline d‘ingestion de données.
- Possibilité de consommer ces données à la fois en temps réel et en mode batch.
- Possibilité de transformer ces données à l‘intérieur de Hadoop (nous l‘appelons SnapReduce) sans avoir à écrire un code MapReduce complexe. (alias "Hadoop pour les humains")
- Capacité à fournir des données transformées à n‘importe quelle plateforme d‘analyse, le cas échéant - cela peut être directement aux utilisateurs de Tableau, à AWS Redshift ou Microsoft Azure SQL ou à une base de données sur site (voici un excellent article de Martin Fowler sur le lac de données et les "lakeshore marts").
Dans ce billet (mon premier !), je vais passer en revue quelques puissants pipelines de flux de données SnapLogic qui répondent à ces exigences et à d‘autres. Chacun de ces pipelines, depuis le pipeline d‘ingestion des données jusqu‘au pipeline de livraison, peut bien sûr être déclenché ou planifié et chacun peut être transformé en API et appelé par d‘autres applications. (Plus de détails à ce sujet ici.)
Pipeline 1 : Ingestion de données
SnapLogic compte plus de 300 connecteurs et microservices préconstruits appelés Snaps. Ce pipeline d'ingestion de données fournit des données non structurées et relationnelles à Hadoop. Les Snaps incluent Microsoft SQL Server et MySQL (structurées, sur site), Twitter (non structurées, cloud).
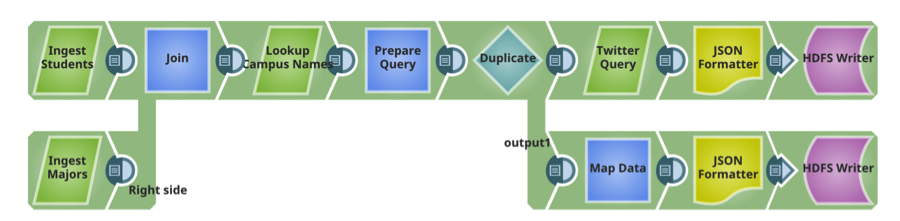
Pipeline 2 : Préparer
Ce pipeline lit les deux fichiers livrés sur HDFS dans le pipeline précédent, effectue des tris et des filtres (transformations) et écrit le fichier transformé sur HDFS.
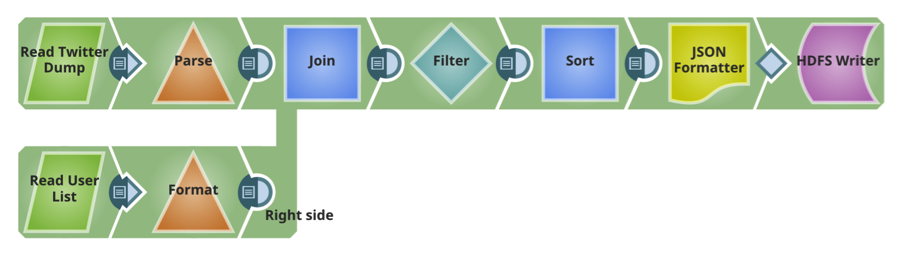
Pipeline 3 : Livraison
Ce pipeline lit le fichier transformé et le livre tel quel à un entrepôt de données cloud AWS Redshift. Ce pipeline extrait également des informations spécifiques du fichier et les transmet directement aux utilisateurs de Birst pour une analyse plus approfondie.
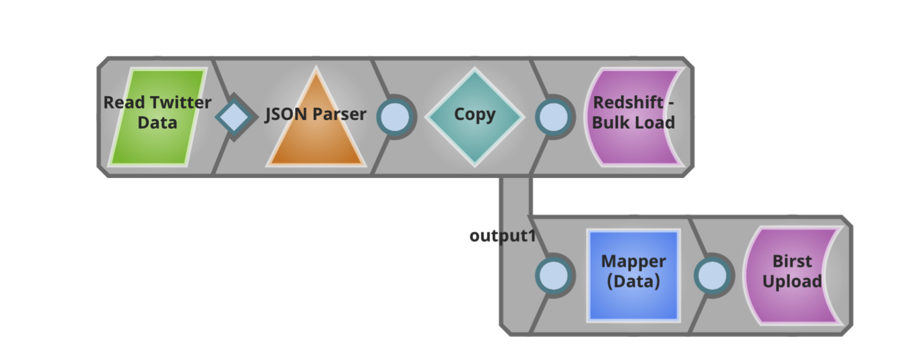
Il est passionnant de pouvoir travailler avec les clients, prospects et partenaires de SnapLogic tout au long du pipeline d‘ingestion des données et de discuter de la manière dont une nouvelle approche des données et des applications d‘entreprise peut permettre d‘accélérer la création de valeur. Pour en savoir plus sur l‘intégration des big data SnapLogic, consultez notre site de démonstration. Voici également un aperçu de nos capacités de traitement des big data qui devrait vous être utile.






