Dans le passé, il était impossible de lire directement les tables de votre système ERP SAP, non pas d'un point de vue technique, mais en raison de restrictions de licence. Aujourd'hui, je constate que de plus en plus de clients SAP disposent d'une licence leur permettant d'accéder à la base de données de leur système S/4HANA. Cependant, l'un des problèmes qui expliquait pourquoi SAP ne l'autorisait pas auparavant subsiste : il n'existe tout simplement pas de types de données disponibles, car ceux-ci se trouvent dans ce que SAP appelle le dictionnaire de données, ou DDIC en abrégé.
Si vous passez par la couche applicative pour lire le tableau, vous obtenez les types de données via le runtime ABAP. L'une de vos options consiste donc à utiliser les modules SAP Remote Function Call. Cela dit, cet article ne vise pas à trouver le module fonction RFC adapté à la lecture des tableaux, mais plutôt à présenter le vaste potentiel des expressions SnapLogics, que vous pouvez utiliser dans presque tous les champs de saisie de n'importe quel Snap, y compris la sortie des RFC SAP. Plongeons-nous donc dans le vif du sujet et voyons ce qu'il peut faire pour vous.
Conditions préalables
Le RFC Execute Snap ne peut fonctionner que sur les Groundplex SnapLogic ; il nécessite SAP JCo et des bibliothèques natives. L'installation Linux de notre Groundplex comprend toutes les bibliothèques et ne nécessite aucune configuration supplémentaire, contrairement à la version Windows. Pour que RFC fonctionne sur un Groundplex basé sur Windows, vous devez télécharger JCo depuis SAP, installer le package redistribuable Windows 2013 et ajouter le dossier contenant la bibliothèque native SAP JCo à la variable PATH de Windows, comme décrit dans notre documentation.
La configuration d'un compte pour SAP Snaps est simple. Elle peut être effectuée directement sur un serveur d'applications ou via l'instance centrale.
Appel du module fonction RFC
La lecture d'une table SAP à l'aide du protocole RFC nécessite un module fonction compatible RFC côté SAP et le snap-in SAP Execute dans SnapLogic. Je suis certain que d'autres modules fonction peuvent lire directement une table spécifique, mais je souhaite me concentrer sur RFC_READ_TABLE dans cet article. Ce module fonction compatible RFC vous permet de spécifier la table que vous souhaitez lire depuis l'extérieur, y compris une clause WHERE si vous choisissez de l'utiliser. Ce module fonction existe depuis plusieurs décennies et est utilisé dans de nombreux projets chez les clients SAP. Bien qu'il comporte certaines restrictions que nous examinerons un peu plus loin, je pense que c'est une option à envisager plutôt que d'écrire soi-même un module fonction personnalisé.
Utilisation de SAP Execute Snap
La configuration du SAP Execute Snap est assez simple, comme le montre la capture d'écran ci-dessous ; il suffit de spécifier RFC_READ_TABLE comme module fonction à utiliser, et le tour est joué.
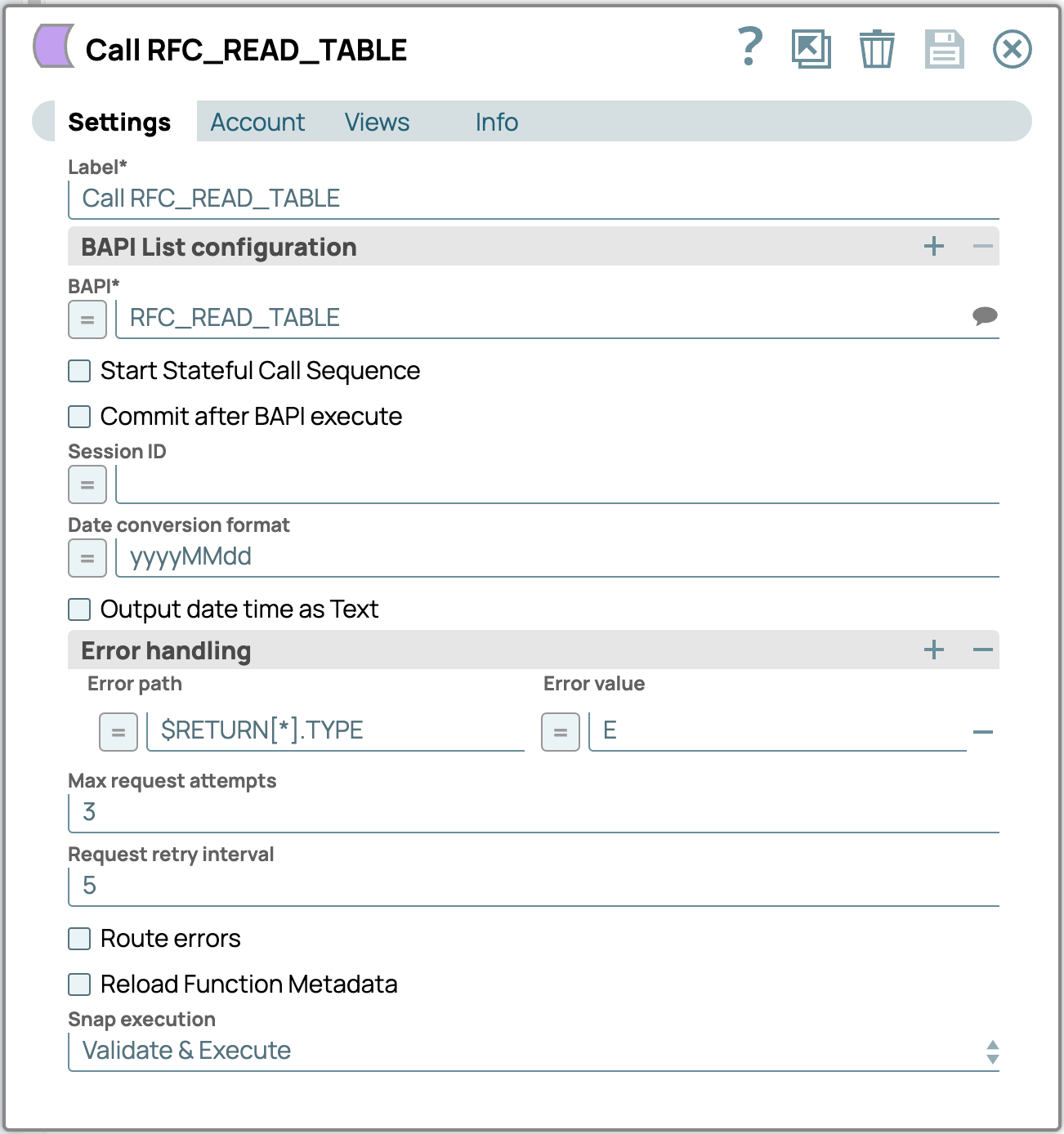
Idéalement, vous devriez placer un Snap Mapper devant et derrière le Snap SAP Execute afin de comprendre le comportement du module fonction.
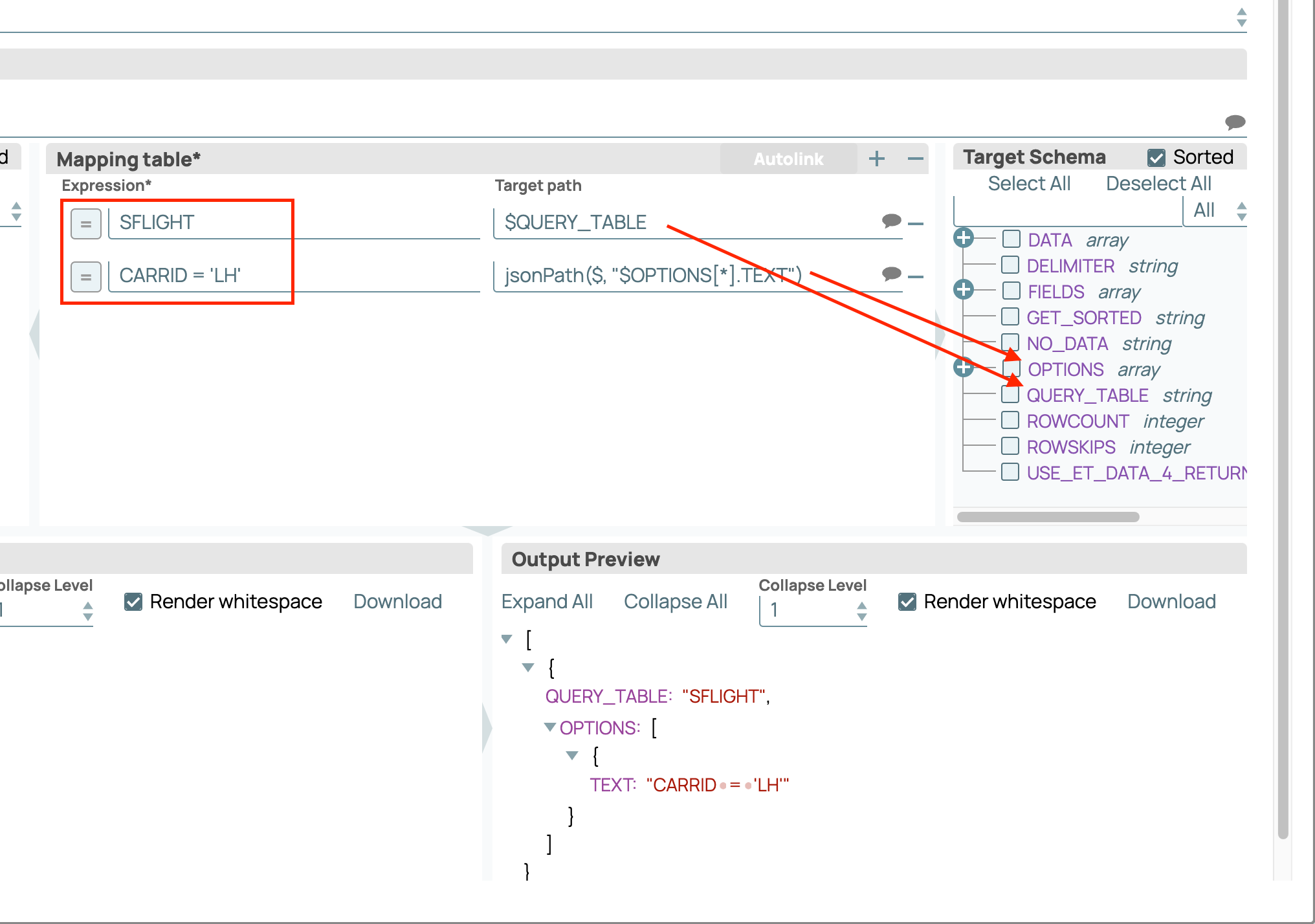
Une fois ce pipeline validé, vous pouvez utiliser le Snap Mapper avant le Snap SAP Execute pour spécifier la table que vous souhaitez lire en mappant le nom de la table sous forme de chaîne au paramètre d'entrée QUERY_TABLE. En option, le tableau d'entrée OPTIONS vous permet de spécifier une clause WHERE, comme illustré dans la capture d'écran ci-dessous.
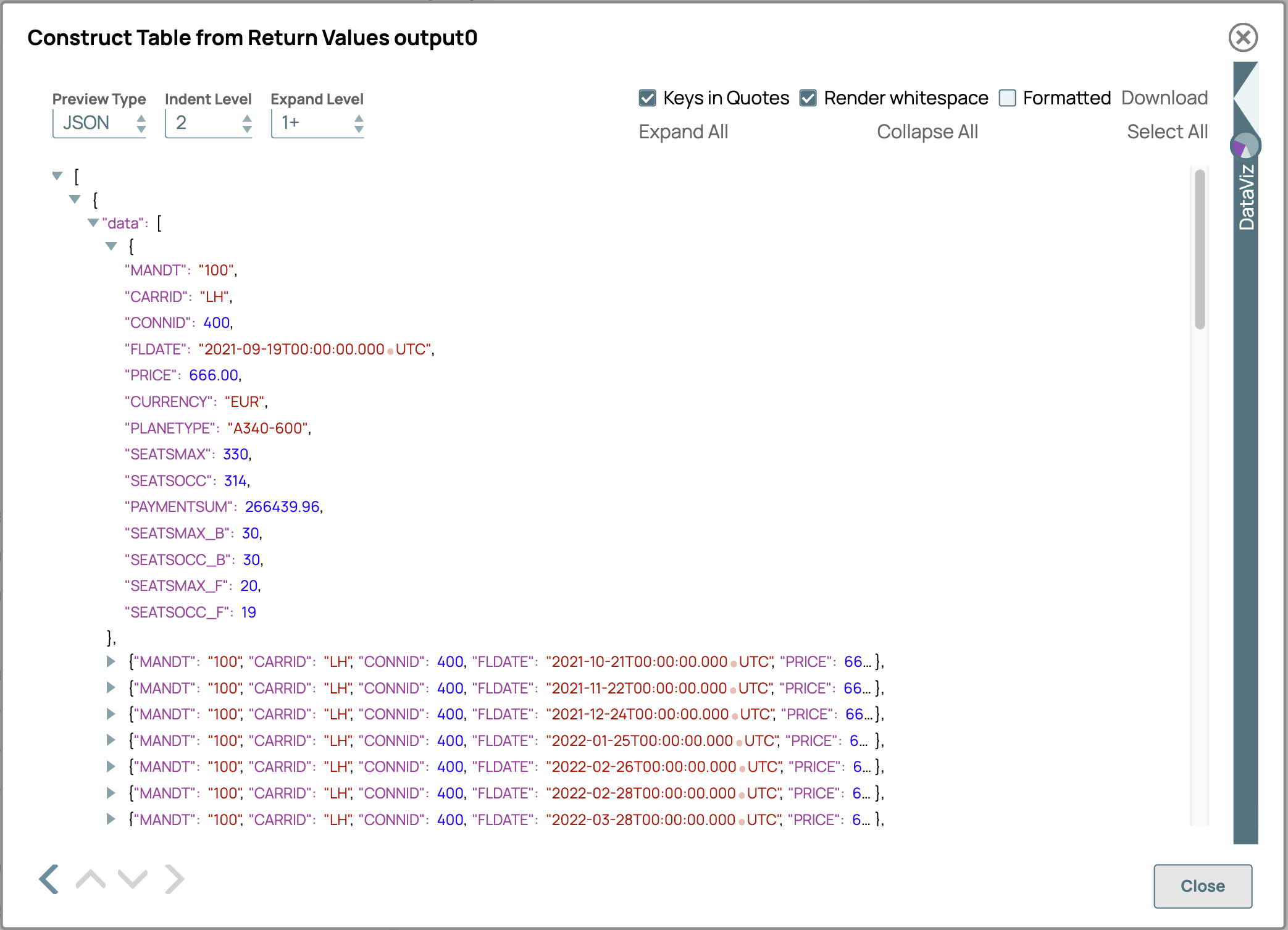
Une deuxième validation du pipeline renverra les données lues à partir de la table spécifiée dans le champ DATA, tous les champs étant regroupés dans une seule chaîne. La restriction du module fonction devient évidente lorsque vous examinez la définition de ce champ dans SAP Gui dans la transaction SE37. Le champ est de type TAB512 et sa longueur est de 512 caractères. Cela signifie que les tables dont la longueur combinée de tous les champs est supérieure à 512 ne renverront que partiellement les informations, voire aucune.
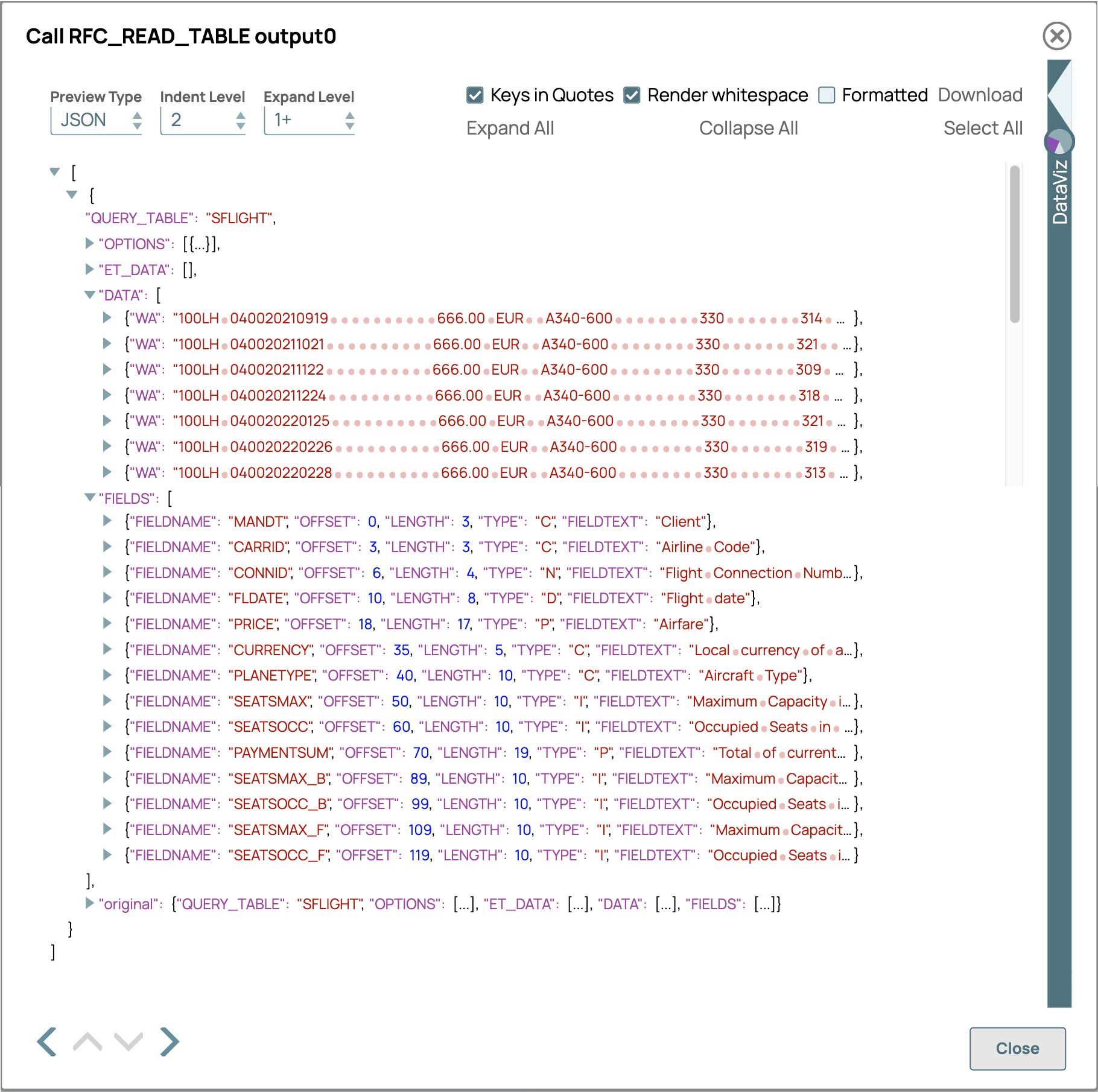
La transformation de ces chaînes en données utilisables avec les types corrects peut ensuite être réalisée à l'aide du tableau de sortie nommé FIELD. Ce tableau contient les informations de type, de longueur et de décalage utilisées pour diviser la chaîne en champs individuels en exploitant le .map, .toObject, match, parse fonctions pour int float, date, et les substr dans les expressions SnapLogics. Match est utilisé pour trouver le type dans le tableau de sortie FIELD, susbstr renvoie la partie de la chaîne DATA qui contient les données du champ, parse(Int, Float, Date) analyse la chaîne dans le type SnapLogic correspondant , .toObject crée un nouvel objet avec le nom des champs et le contenu analysé, et map ajoute chaque ligne à un tableau dans le document SnapLogic.
$DATA.map(d=> $FIELDS
.toObject(
f=> f.FIELD NAME
, f=> match f.TYPE {
'I' => parseInt(d.WA.substr(f.OFFSET, f.LENGTH))
, 'N' => parseFloat(d.WA.substr(f.OFFSET, f.LENGTH))
, 'P' => parseFloat(d.WA.substr(f.OFFSET, f.LENGTH))
, 'D' => Date.parse(d.WA.substr(f.OFFSET, f.LENGTH), 'yyyyMMdd')
, _ => d.WA.substr(f.OFFSET, f.LENGTH).trim()
}
)
)
La validation du pipeline pour la troisième fois vous permettra d'obtenir un résultat parfaitement structuré.