






Dans le domaine en pleine évolution de l'IA générative (GenAI), les connaissances fondamentales peuvent vous mener loin, mais c'est la maîtrise des modèles avancés qui vous permet véritablement de créer des applications sophistiquées, évolutives et efficaces. À mesure que la complexité des tâches basées sur l'IA augmente, il devient nécessaire de disposer de stratégies robustes capables de gérer divers scénarios, du maintien du contexte dans les conversations à plusieurs tours à la génération dynamique de contenu en fonction des entrées de l'utilisateur.
Ce guide explore ces modèles avancés et propose une analyse approfondie des stratégies susceptibles d'améliorer vos applications GenAI. Que vous soyez un administrateur cherchant à optimiser vos systèmes d'IA ou un développeur souhaitant repousser les limites du possible, la compréhension et la mise en œuvre de ces modèles vous permettront de gérer et de résoudre des défis complexes en toute confiance.
1. Ingénierie avancée des invites
1.1 Contrôle complet du format de réponse
Dans les applications GenAI, le contrôle du format de sortie est essentiel pour garantir que les réponses correspondent aux exigences spécifiques des utilisateurs. L'ingénierie avancée des invites vous permet de créer des invites qui fournissent des instructions précises sur la manière dont l'IA doit structurer sa sortie. Cette approche améliore non seulement la cohérence des réponses, mais les rend également plus conformes aux objectifs souhaités.
Par exemple, vous pouvez concevoir des invites avec une structure détaillée qui comprend plusieurs éléments tels que le contexte, l'objectif, le style, le public et la longueur de réponse souhaitée. Cette méthode permet un contrôle granulaire de la sortie. Voici un exemple d'invite :
- Contexte : Fournir des informations générales sur le sujet afin de planter le décor.
- Objectif : définir clairement le but de la réponse.
- Style : précisez si la réponse doit être formelle, informelle, technique ou créative.
- Public : Identifiez le public cible, qui influence le langage et le niveau de détail des explications.
- Format de réponse : demandez à l'IA de générer une réponse qui prend environ 3 minutes à lire, en veillant à ce qu'elle soit approfondie et exhaustive, et qu'elle comporte généralement 4 à 5 paragraphes.
Ce niveau de détail dans l'ingénierie des invites garantit que le contenu généré par l'IA répond à des besoins spécifiques, ce qui le rend adapté à divers cas d'utilisation, tels que la génération de matériel éducatif, de rapports détaillés ou de communications avec les clients.
1.2 Apprentissage en quelques essais
L'apprentissage en quelques essaisest une technique avancée dans laquelle le modèle d'IA reçoit un petit nombre d'exemples (souvent seulement quelques-uns) dans l'invite afin de guider sa sortie. Cette méthode est particulièrement efficace lorsqu'il s'agit de tâches qui exigent du modèle qu'il comprenne et reproduise des modèles ou des formats complexes avec un minimum d'entrées.
En intégrant des exemples directement dans l'invite, vous pouvez entraîner le modèle à produire des réponses plus précises et plus adaptées au contexte, même dans des scénarios où de grandes quantités de données d'entraînement ne sont pas disponibles.
Cette approche est précieuse pour personnaliser le comportement de l'IA dans le cadre d'applications spécialisées où les données d'entraînement généralisées peuvent s'avérer insuffisantes.
Exemple de consigne :
« Générez une description produit pour les articles suivants. La description doit être concise, mettre en avant les caractéristiques clés et séduire un public cible intéressé par la qualité et l'innovation. »
Exemple 1 :
- Nom du produit : Thermostat WiFi SmartHome
- Description : « Le thermostat WiFi SmartHome est la solution ultime pour un contrôle économe en énergie de la température. S'intégrant parfaitement à votre écosystème domotique, il offre des commandes intuitives, des paramètres personnalisables et des rapports en temps réel sur la consommation d'énergie. Conçu pour la vie moderne, il garantit votre confort tout en vous aidant à réduire vos factures d'énergie. »
Exemple 2 :
- Nom du produit : Cafetière en acier inoxydable EcoBrew
- Description : « La cafetière en acier inoxydable EcoBrew allie durabilité et performances haut de gamme. Fabriquée en acier inoxydable durable, cette cafetière écologique prépare à chaque fois une tasse parfaite, avec un impact minimal sur l'environnement. Idéale pour les amateurs de café soucieux de l'environnement, elle offre une préparation précise et un design élégant qui s'intègre à toutes les cuisines. »
Nouvel article :
- Nom du produit : Sac à dos de voyage ultra-léger
Description :
Résultat généré par l'IA :
«Sac à dos de voyage UltraLight: le sac à dos de voyage UltraLight est conçu pour les aventuriers modernes. Pesant moins d'une livre, il offre une portabilité inégalée sans sacrifier la capacité de rangement. Doté d'un tissu résistant à l'eau, de multiples compartiments et de bretelles ergonomiques, ce sac à dos est conçu pour ceux qui ont besoin de durabilité et de commodité lors de leurs déplacements. Parfait pour les randonnées d'une journée, les escapades du week-end ou l'usage quotidien, le sac à dos de voyage UltraLight est votre compagnon fiable pour tous vos voyages. »
Explication :
Dans cet exemple, l'IA a reçu deux descriptions de produits illustrant le style, le ton et la structure souhaités pour le résultat. Lorsqu'on lui a demandé de générer une nouvelle description pour le « sac à dos de voyage UltraLight », l'IA a utilisé les modèles des exemples fournis pour créer une description de produit similaire et adaptée au contexte. Bien qu'on ne lui ait montré que deux exemples, le modèle a efficacement saisi les éléments clés nécessaires pour générer un nouveau résultat de haute qualité.
Cette approche est très utile lorsque vous avez besoin que l'IA produise des résultats cohérents pour des tâches similaires, en particulier dans les cas où il n'est pas possible de créer des données d'entraînement exhaustives. En fournissant seulement quelques exemples, vous guidez la compréhension de l'IA, lui permettant d'appliquer le modèle appris à des tâches nouvelles, mais connexes.
1.3 Chaîne de pensée
La chaîne de schémas de pensée encourage l'IA à générer des réponses qui suivent une séquence logique, reflétant le raisonnement humain. Cette technique est particulièrement utile dans les scénarios complexes où l'IA doit prendre des décisions, résoudre des problèmes ou expliquer des concepts étape par étape.
En structurant des invites qui guident l'IA à travers une série de processus de réflexion, vous pouvez l'amener à produire des résultats plus cohérents et rationnels. Cette méthode est particulièrement efficace dans les applications nécessitant des explications détaillées, telles que le raisonnement scientifique, la résolution de problèmes techniques ou toute situation dans laquelle l'IA doit justifier ses conclusions. Par exemple, une invite peut demander à l'IA de décomposer un problème complexe en plusieurs parties plus petites et plus faciles à gérer, puis de les traiter chacune à tour de rôle. L'IA identifierait d'abord les éléments clés du problème, puis traiterait chacun d'entre eux, en expliquant son raisonnement à chaque étape. Cette méthode améliore non seulement la clarté de la réponse, mais aussi la précision et la pertinence des conclusions de l'IA.
2. Traitement multimodal
Le traitement multimodal dans l'IA générative est une approche de pointe qui permet aux systèmes d'IA d'intégrer et de traiter simultanément plusieurs types de données, telles que du texte, des images, de l'audio et de la vidéo. Cette capacité est cruciale pour les applications qui nécessitent une compréhension approfondie du contenu dans différentes modalités, ce qui permet d'obtenir des résultats plus précis et plus riches sur le plan contextuel.
Par exemple, dans un scénario où une IA est chargée de générer une description d'une scène à partir d'une vidéo, le traitement multimodal lui permet d'analyser à la fois les éléments visuels et l'audio qui les accompagne afin de produire une description qui reflète non seulement ce qui est vu, mais aussi le contexte fourni par le son. De même, lorsqu'elle traite à la fois du texte et des images, comme dans le cas d'une tâche de sous-titrage, l'IA peut mieux comprendre la relation entre les mots et le contenu visuel, ce qui permet d'obtenir des sous-titres plus précis et plus pertinents.
Ce modèle avancé est particulièrement utile dans les environnements complexes où la compréhension des nuances entre différents types de données est essentielle pour fournir des résultats de haute qualité. Par exemple, dans le domaine du diagnostic médical, les systèmes d'IA utilisant le traitement multimodal peuvent analyser des images médicales ainsi que les dossiers des patients et les notes vocales afin de fournir des diagnostics plus précis. Dans le domaine du service à la clientèle, l'IA peut interpréter et répondre aux demandes des clients en analysant simultanément le texte et le ton de la voix, améliorant ainsi la qualité des interactions.
De plus, le traitement multimodal améliore la capacité de l'IA à apprendre à partir de sources de données variées, lui permettant ainsi de construire des modèles plus robustes qui se généralisent mieux à différentes tâches. Cela en fait un outil essentiel dans le développement d'applications d'IA qui doivent fonctionner dans des scénarios réels où les données sont rarement homogènes.
En tirant parti du traitement multimodal, les systèmes d'IA peuvent générer des réponses non seulement plus complètes, mais également adaptées aux besoins spécifiques de la tâche à accomplir, ce qui les rend très efficaces dans un large éventail d'applications. À mesure que cette technologie continue d'évoluer, elle promet d'ouvrir de nouvelles possibilités dans des domaines aussi divers que le divertissement, l'éducation, la santé et bien d'autres encore.
Exemple
Dans de nombreux cas, les données peuvent inclure à la fois des images et du texte qui doivent être analysés ensemble pour obtenir des informations complètes. Pour traiter et intégrer efficacement ces différents types de données, vous pouvez utiliser un pipeline de traitement multimodal dans SnapLogic. Cette approche permet au modèle d'IA générative d'analyser simultanément les données provenant des deux sources, tout en conservant l'intégrité de chaque modalité.

Ce pipeline se compose de deux étapes distinctes. La première étape consiste à extraire les images des données sources et à les convertir au format base64. La deuxième étape consiste à générer une invite à l'aide de techniques avancées d'ingénierie des invites, qui est ensuite transmise au modèle linguistique à grande échelle (LLM). La représentation visuelle de ce processus est divisée en deux parties, comme le montre l'image ci-dessus.
Extraire l'image de la source
- Ajouter le Snap File Reader: glissez-déposez le Snap « File Reader » dans le concepteur.
- Configurer le Snap Lecteur de fichiers: Cliquez sur le Snap « File Reader » pour accéder à son panneau de paramètres. Sélectionnez ensuite un fichier contenant des images. Dans ce cas, nous sélectionnons un fichier pdf.
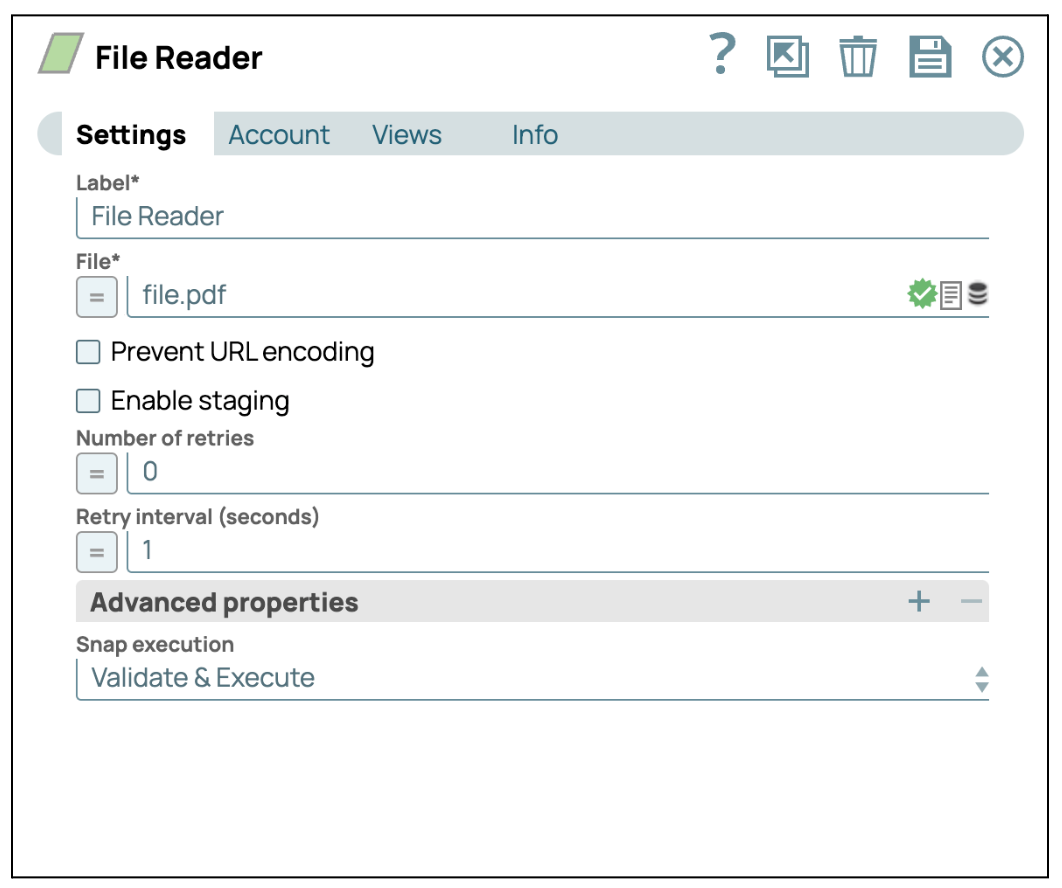
- Ajouter le Snap PDF Parser : Glissez-déposez le Snap « PDF Parser » dans le concepteur et définissez le type d'analyseur sur « Pages to images converter » (Convertisseur de pages en images).
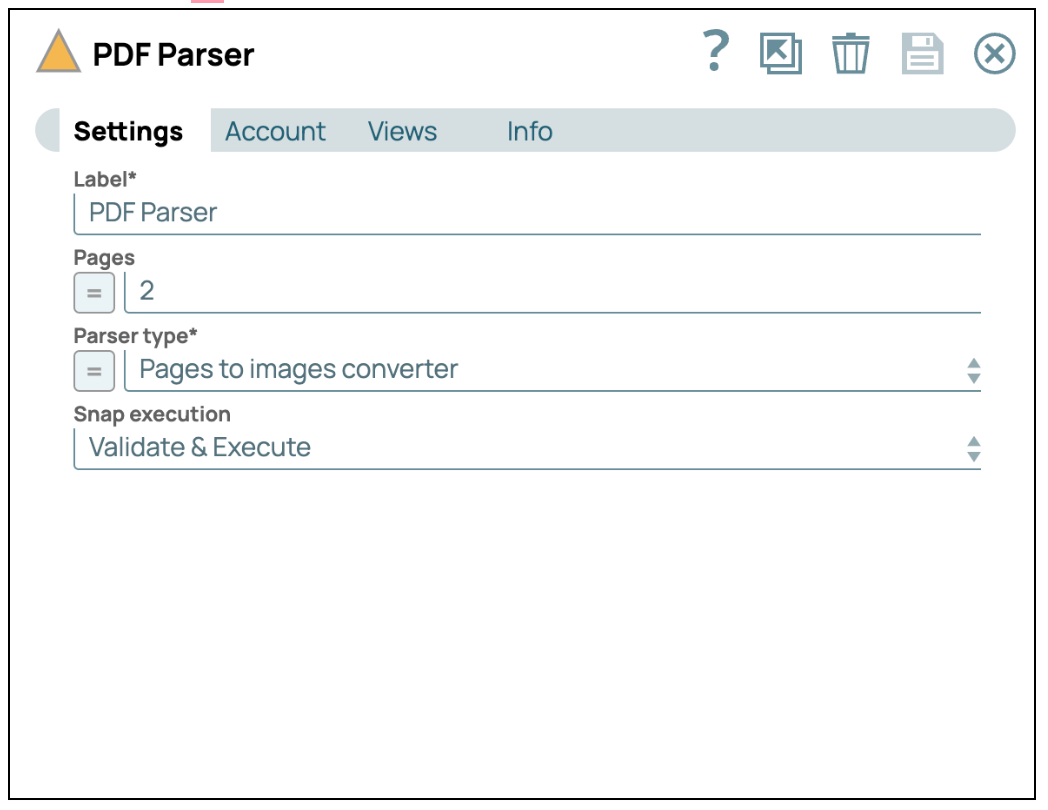
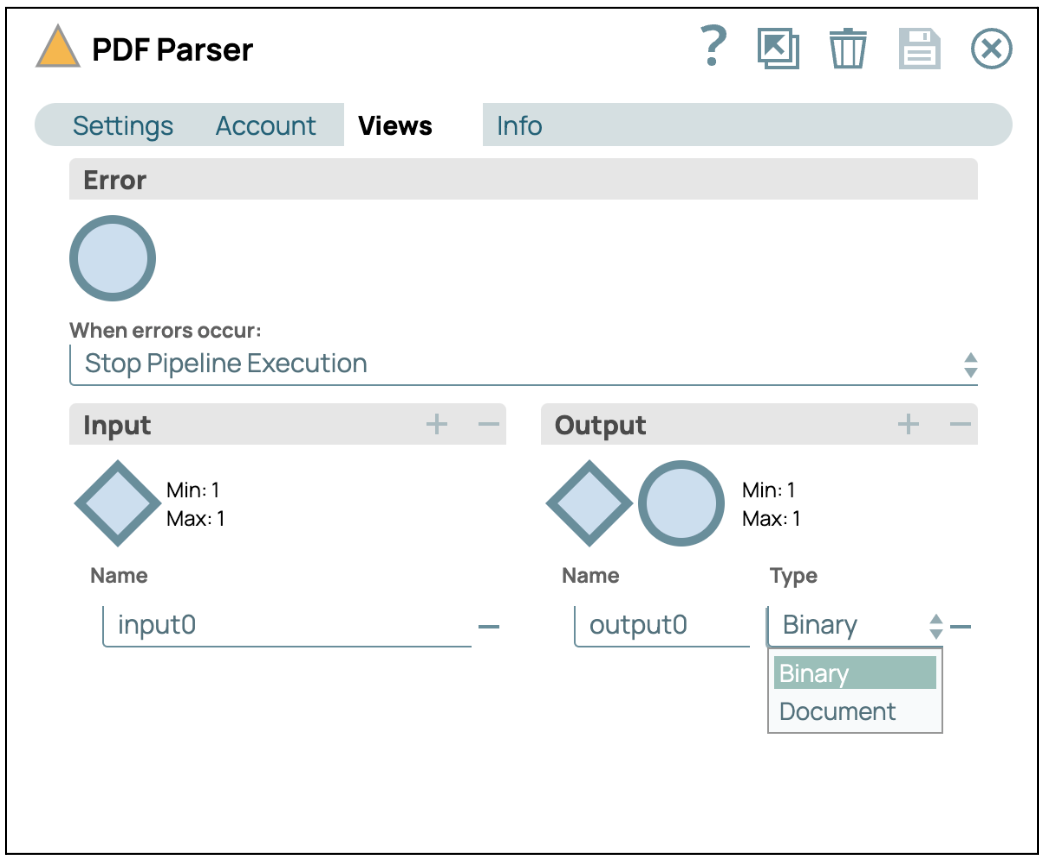
- Configurer les vues : Cliquez sur l'onglet « Vues », puis sélectionnez « Binaire » comme format de sortie.
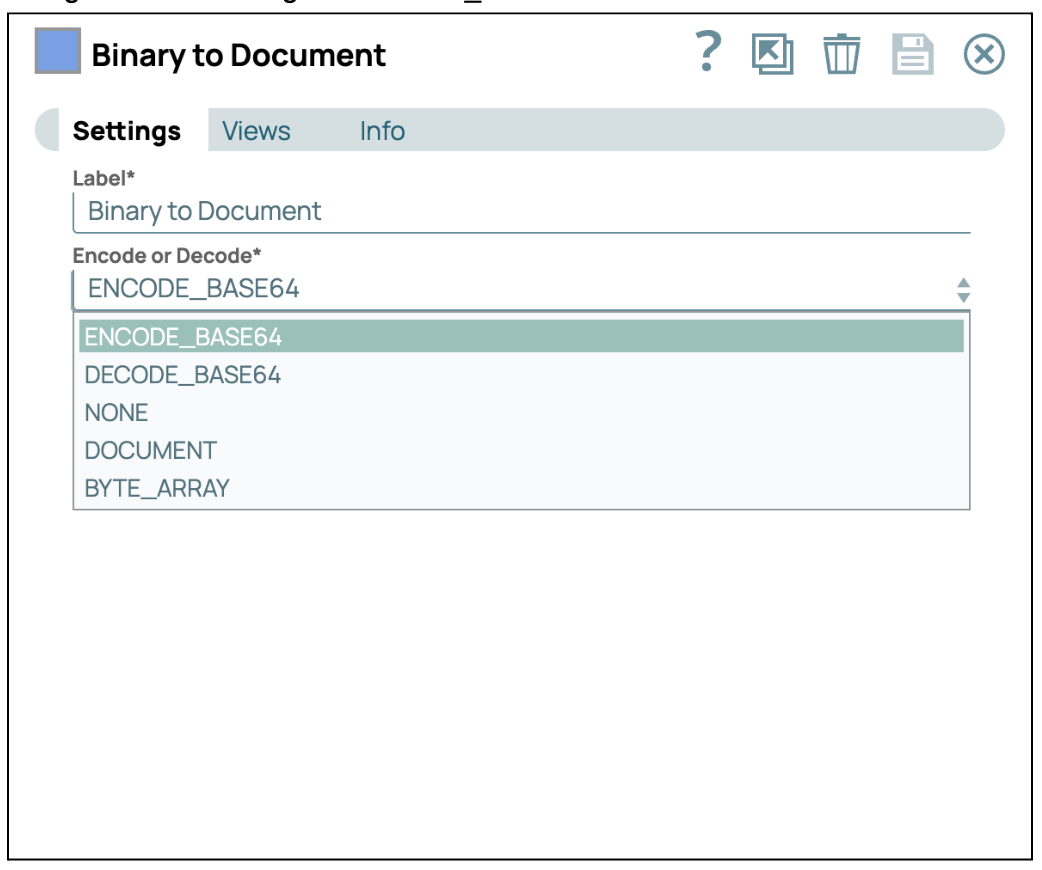
- Convertir en Base64 : Ajoutez et connectez le module « Binary to Document » au module PDF Parser. Configurez ensuite l'encodage sur ENCODE_BASE64.
Construisez l'invite et envoyez-la à GenAI.
- Ajouter un Snap générateur JSON : Faites glisser le Snap JSON Generator et connectez-le au Snap Mapper précédent. Cliquez ensuite sur « Edit JSON » pour modifier la chaîne JSON dans le mode éditeur JSON. AWS Claude on Message vous permet d'envoyer des images via l'invite en configurant l'attribut source dans le contenu. Vous pouvez créer l'invite d'image comme indiqué dans la capture d'écran.

- Fournir des instructions avec le générateur de messages : Ajoutez le générateur de prompt Snap et connectez-le au générateur JSON Snap. Ensuite, cochez la case « Advanced Prompt Output » (Sortie de prompt avancée) pour activer la charge utile avancée du prompt. Enfin, cliquez sur « Edit Prompt » (Modifier le prompt) pour saisir vos instructions spécifiques.
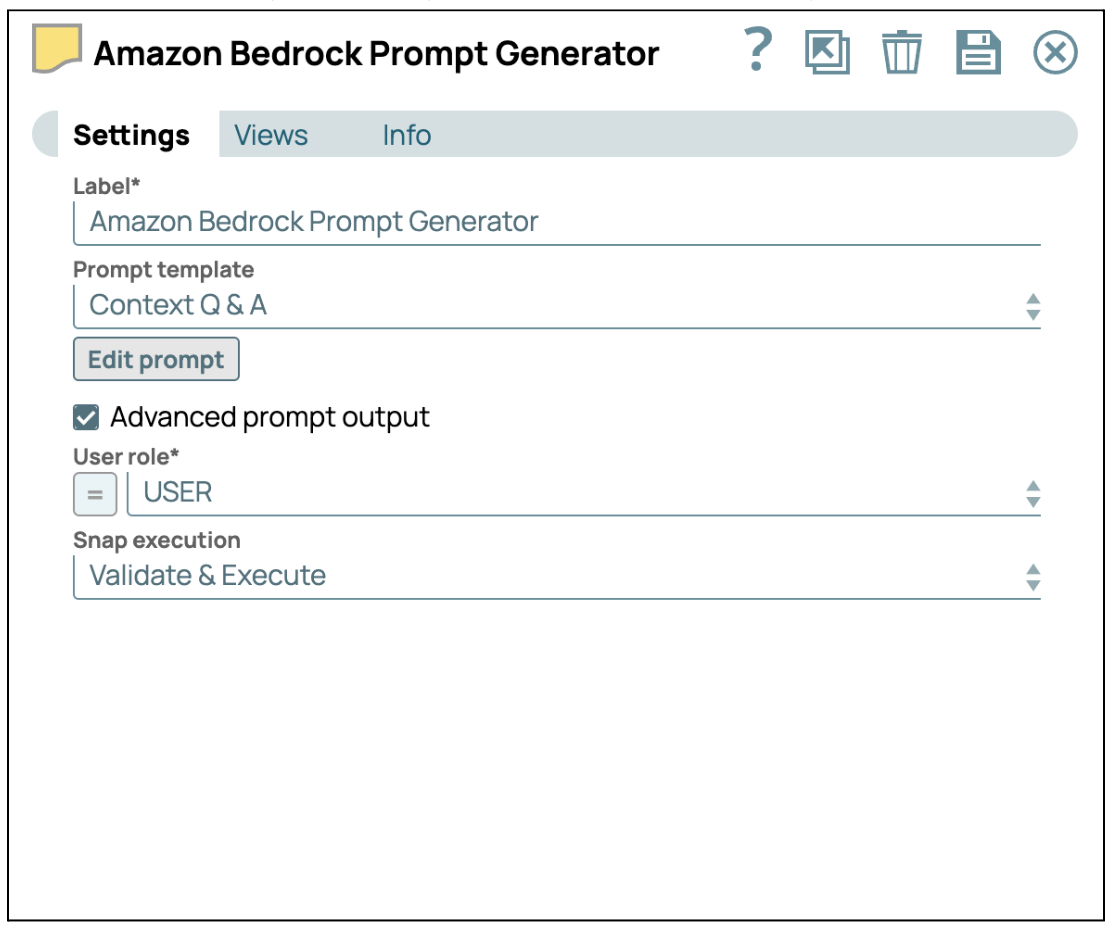
La sortie avancée sera structurée sous forme d'un ensemble de messages, comme illustré dans la capture d'écran ci-dessous.
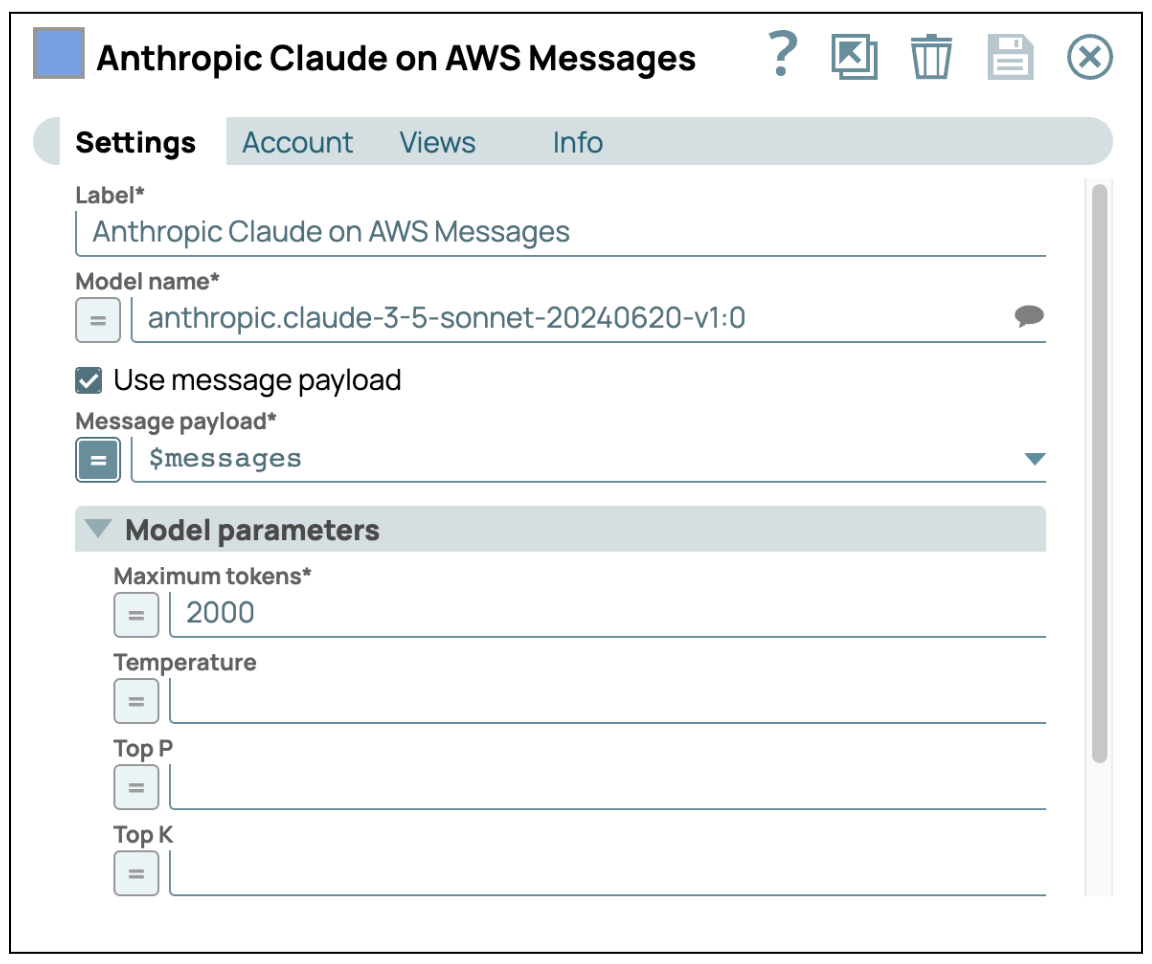
- Envoyer à GenAI : Ajoutez AWS Claude sur AWS Message Snap et entrez vos identifiants pour accéder au service AWS Bedrock. Assurez-vous que la case « Use Message Payload » (Utiliser la charge utile du message) est cochée, puis configurez la charge utile du message à l'aide de $messages, qui est la sortie du Snap précédent.
Une fois ces étapes terminées, vous pouvez traiter l'image à l'aide du LLM de manière indépendante. Cette approche permet au LLM de se concentrer sur l'extraction d'informations détaillées à partir de l'image. Une fois l'image traitée, vous pouvez combiner ces données avec d'autres sources, telles que du texte ou des données structurées, afin de générer une analyse plus complète et plus précise. Cette intégration multimodale garantit que les informations tirées de différents types de données sont synthétisées efficacement, ce qui permet d'obtenir des résultats plus riches et plus précis.
3. Mise en cache sémantique
Pour optimiser à la fois le coût et le temps de réponse associés à l'utilisation de grands modèles linguistiques (LLM), la mise en œuvre d'un mécanisme de mise en cache sémantique est une stratégie très efficace. La mise en cache sémantique consiste à stocker les réponses générées par le modèle et à les réutiliser lorsque le système rencontre des requêtes ayant une signification identique ou similaire. Cette approche améliore non seulement l'efficacité globale du système, mais réduit également de manière significative les coûts opérationnels liés à l'utilisation du modèle.
Le principe fondamental du cache sémantique repose sur le fait que de nombreuses requêtes utilisateur sont souvent similaires sur le plan sémantique, même si elles sont formulées différemment. En identifiant et en mettant en cache les réponses à ces requêtes sémantiquement équivalentes, le système peut éviter d'avoir à invoquer de manière répétée le LLM, qui est gourmand en ressources. Au lieu de cela, le système peut rapidement récupérer et renvoyer la réponse mise en cache, ce qui se traduit par des temps de réponse plus rapides et une expérience utilisateur plus fluide.
Du point de vue des coûts, la mise en cache sémantique se traduit directement par des économies. Chaque fois que le système fournit une réponse à partir du cache plutôt que d'interroger le LLM, il évite les coûts de calcul associés à la génération d'une nouvelle réponse. Cette réduction du nombre d'appels au LLM est directement corrélée à une baisse des coûts de service, ce qui rend la solution plus viable sur le plan économique, en particulier dans les environnements où le volume de requêtes est élevé.
De plus, la mise en cache sémantique contribue à l'évolutivité du système. À mesure que la demande sur le LLM augmente, le mécanisme de mise en cache aide à gérer la charge plus efficacement, garantissant ainsi des temps de réponse constants même lorsque le système évolue. Cela est essentiel pour maintenir la qualité du service, en particulier dans les applications en temps réel où la latence est un facteur critique.
La mise en œuvre de la mise en cache sémantique dans le cadre de la stratégie de déploiement LLM offre un double avantage : optimisation des temps de réponse pour les utilisateurs finaux et minimisation des coûts opérationnels liés à l'utilisation du modèle. Cette approche améliore non seulement les performances et l'évolutivité des systèmes basés sur l'IA, mais garantit également leur rentabilité et leur réactivité à mesure que la demande des utilisateurs augmente.
Concept de mise en œuvre pour la mise en cache sémantique
La mise en cache sémantique est une approche stratégique conçue pour optimiser à la fois le temps de réponse et l'efficacité computationnelle dans les systèmes basés sur l'IA. La mise en œuvre de la mise en cache sémantique comprend les étapes clés suivantes :
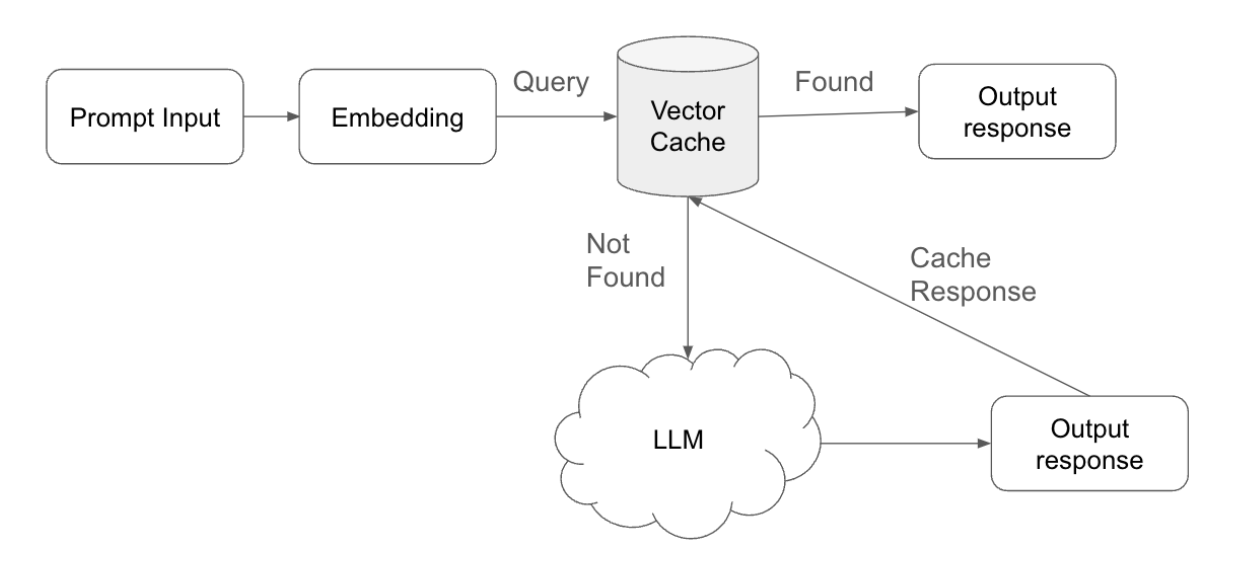
- Soumission et vectorisation des requêtes: lorsqu'un utilisateur soumet une requête, le système traite d'abord cette entrée en la convertissant en un encodage, c'est-à-dire une représentation vectorisée de la requête. Cet encodage capture la signification sémantique de la requête, ce qui permet une comparaison efficace avec les données précédemment stockées.
- Recherche et correspondance dans le cache: Le système effectue ensuite une recherche dans le cache vectoriel, qui contient les intégrations des requêtes précédentes ainsi que les réponses correspondantes. Au cours de cette recherche, le système recherche une intégration existante qui correspond étroitement à l'intégration de la nouvelle requête.
- Seuil de correspondance: le seuil de correspondance, qui peut être ajusté pour contrôler la sensibilité de l'algorithme de correspondance, est un élément essentiel de ce processus. Ce seuil détermine le degré de correspondance entre la nouvelle requête et un emplacement stocké pour que le cache la considère comme une correspondance.
- Accès au cache et récupération de la réponse: si le système identifie une correspondance dans les limites du seuil défini, il récupère la réponse correspondante dans le cache. Cet « accès au cache » permet au système de fournir rapidement la réponse à l'utilisateur, sans avoir besoin de traitement supplémentaire. En fournissant les réponses directement à partir du cache, le système économise des ressources informatiques et réduit les temps de réponse.
- Échec de cache et traitement LLM: lorsqu'aucune correspondance appropriée n'est trouvée dans le cache (échec de cache), le système transmet la requête au modèle linguistique à grande échelle (LLM). Le LLM traite la requête et génère une nouvelle réponse, garantissant ainsi à l'utilisateur une réponse pertinente et précise, même pour les requêtes inédites.
- Stockage des réponses et gestion du cache: Une fois que le LLM a généré une nouvelle réponse, le système non seulement la transmet à l'utilisateur, mais la stocke également avec la requête associée dans le cache vectoriel. Cette étape garantit que si une requête similaire est soumise à l'avenir, le système pourra fournir la réponse directement à partir du cache, optimisant ainsi davantage l'efficacité du système.
- Ajustement du délai d'expiration (TTL): afin de maintenir la pertinence et l'exactitude des réponses mises en cache, le système peut ajuster le délai d'expiration (TTL) pour chaque entrée dans le cache. Le TTL détermine la durée pendant laquelle une réponse reste valide dans le cache avant d'être considérée comme obsolète et automatiquement supprimée. En ajustant les paramètres TTL, le système garantit que seules les réponses à jour et adaptées au contexte sont fournies, empêchant ainsi l'utilisation de données obsolètes ou non pertinentes.
Mettre en œuvre la mise en cache sémantique dans SnapLogic
Le concept de mise en cache sémantique peut être mis en œuvre efficacement dans SnapLogic, en tirant parti de ses solides capacités de pipeline. Vous trouverez ci-dessous un aperçu de la manière dont cette mise en œuvre peut être réalisée :

- Intégration de la requête: le processus commence par l'intégration de la requête (invite) de l'utilisateur. Grâce aux capacités de SnapLogic, un intégrateur, tel qu'Amazon Titan Embedder, est utilisé pour convertir l'invite en une représentation vectorisée. Cette intégration capture la signification sémantique de l'invite, ce qui la rend adaptée à la comparaison avec des intégrations précédemment stockées.
- Recherche dans le cache vectoriel: une fois l'invite intégrée, le système recherche une entrée correspondante dans le cache vectoriel. Dans cette implémentation, la base de données vectorielle Snowflake sert de cache vectoriel, stockant les intégrations des requêtes passées ainsi que leurs réponses correspondantes. Cette recherche est cruciale pour déterminer si une requête similaire a déjà été traitée auparavant.
- Acheminement de flux avec Router SnapAprès la recherche, le système utilise un Router Snap pour gérer le flux en fonction de la présence ou non d'une correspondance (cache hit) ou d'une absence de correspondance (cache miss). Le Router Snap dirige le workflow suit :
- Cache Hit: si une intégration correspondante est trouvée dans le cache vectoriel, le Router Snap achemine le processus afin de renvoyer immédiatement la réponse mise en cache à l'utilisateur. Cela garantit des temps de réponse rapides en évitant tout traitement inutile.
- Échec de la mise en cache: si aucune correspondance n'est trouvée, le Router Snap dirige le workflow une nouvelle requête auprès du modèle linguistique à grande échelle (LLM). Le LLM traite la requête et génère une nouvelle réponse pertinente.
- Stockage et réponse: en cas d'échec de la mise en cache, une fois que le LLM a généré une nouvelle réponse, le système envoie non seulement cette réponse à l'utilisateur, mais stocke également le nouvel encodage et la nouvelle réponse dans la base de données vectorielle Snowflake pour une utilisation future. Cette étape améliore l'efficacité des requêtes suivantes, car les invites similaires peuvent être traitées directement à partir du cache.
4. Multiplexage des agents IA
Le multiplexage d'agents IA désigne une stratégie consistant à utiliser en parallèle plusieurs modèles d'IA générative, chacun spécialisé dans une tâche spécifique, afin de traiter des requêtes complexes. Cette approche s'apparente à la constitution d'un panel d'experts, où chaque agent apporte son expertise afin de fournir une solution complète. Voici la principale caractéristique de l'utilisation du multiplexage d'agents IA
- Spécialisation : l'un des principaux avantages du multiplexage des agents IA réside dans la spécialisation de chaque agent dans la gestion de tâches ou de domaines spécifiques. Le multiplexage garantit des réponses plus pertinentes et plus précises en attribuant à chaque modèle d'IA un domaine d'expertise particulier. Par exemple, un agent peut être optimisé pour la compréhension du langage naturel, un autre pour la résolution de problèmes techniques et un troisième pour la synthèse de données complexes. Cela permet au système de traiter efficacement des requêtes multidimensionnelles, chaque agent se concentrant sur ce qu'il fait le mieux. Cette spécialisation réduit considérablement le risque d'erreurs ou de réponses non pertinentes, car les agents IA sont adaptés à leurs tâches spécifiques.
Dans les cas où une requête couvre plusieurs domaines, par exemple une question technique ayant un aspect commercial, le système peut acheminer les différentes parties de la requête vers l'agent approprié. Cette approche structurée permet d'extraire des informations plus pertinentes et plus précises, ce qui conduit à une solution qui aborde toutes les facettes du problème. - Traitement parallèle : les agents IA multiplexés tirent pleinement parti des capacités de traitement parallèle. En exécutant plusieurs agents simultanément, le système peut traiter différents aspects d'une requête en même temps, ce qui accélère le temps de réponse global. Cette approche parallèle améliore à la fois les performances et l'évolutivité, car la charge de travail est répartie entre plusieurs agents plutôt que de s'appuyer sur un seul modèle pour traiter l'ensemble de la tâche.
Par exemple, dans une application de support client, un agent peut se charger de l'analyse des interactions précédentes d'un client, tandis qu'un autre agent génère une réponse à un problème technique et qu'un troisième crée un plan d'action de suivi. Chaque agent travaille en parallèle sur sa tâche respective, et le système intègre leurs résultats dans une réponse cohérente. Cette méthode accélère non seulement la résolution des problèmes, mais garantit également que les différentes dimensions du problème sont traitées simultanément. - Répartition dynamique des tâches : dans un système multiplexé, la répartition dynamique des tâches est essentielle pour distribuer efficacement les tâches entre les agents spécialisés. Un modèle plus grand et polyvalent, tel que AWS Claude 3 Sonet, peut agir comme un orchestrateur, évaluant le contexte de la requête et déterminant quelles parties de la tâche doivent être déléguées à des agents plus petits et plus spécialisés. L'orchestrateur veille à ce que chaque tâche soit attribuée au modèle le mieux équipé pour la traiter.
Par exemple, si un utilisateur soumet une requête complexe concernant la réglementation juridique et la sécurité des données, le modèle général peut décomposer la requête, en envoyant les questions juridiques à un agent IA spécialisé dans l'analyse juridique et les questions liées à la sécurité à un agent axé sur la sécurité comme TinyLlama ou un modèle similaire. Cette délégation dynamique permet d'utiliser les modèles les plus pertinents au bon moment, améliorant ainsi l'efficacité et la précision de la réponse globale. - Intégration des résultats : une fois que les agents spécialisés ont traité leurs tâches respectives, le système doit intégrer leurs résultats afin de former une réponse cohérente et complète. Cette intégration est une caractéristique essentielle du multiplexage, car elle garantit que tous les aspects d'une requête sont traités sans chevauchement ni contradiction. Le système combine les informations générées par chaque agent, créant ainsi une sortie finale qui reflète l'ensemble de la demande de l'utilisateur.
Dans de nombreux cas, le processus d'intégration comprend également le filtrage ou le raffinement des résultats afin d'éliminer toute incohérence ou redondance, garantissant ainsi une réponse logique et cohérente. Cette approche collaborative augmente la fiabilité du système, car elle permet à différents agents de compléter leurs connaissances et leur expertise respectives.
De plus, le multiplexage réduit le risque d'hallucinations, c'est-à-dire de résultats incorrects ou absurdes qui peuvent parfois se produire avec des modèles uniques à grande échelle. En répartissant les tâches entre des agents spécialisés, le système garantit que chaque partie du problème est traitée par une IA spécifiquement formée pour ce domaine, ce qui minimise le risque de réponses erronées ou hors contexte. - Précision et compréhension contextuelle améliorées : Les agents IA multiplexés contribuent à améliorer la précision globale en répartissant les tâches entre des modèles mieux adaptés à des contextes ou des sujets spécifiques. Cette approche permet au système IA de mieux comprendre et traiter les nuances d'une requête, en particulier lorsque les données saisies sont complexes ou hautement spécialisées. La concentration de chaque agent sur une tâche spécifique permet d'atteindre un niveau de précision supérieur, ce qui se traduit par un résultat final plus précis.
De plus, le multiplexage permet au système de développer une compréhension contextuelle plus détaillée. Étant donné que différents agents sont responsables de différents éléments d'une tâche, le système peut synthétiser des réponses plus détaillées et plus adaptées au contexte. Cette vision holistique est essentielle pour garantir que la solution fournie est non seulement précise, mais également pertinente par rapport à la situation spécifique présentée par l'utilisateur.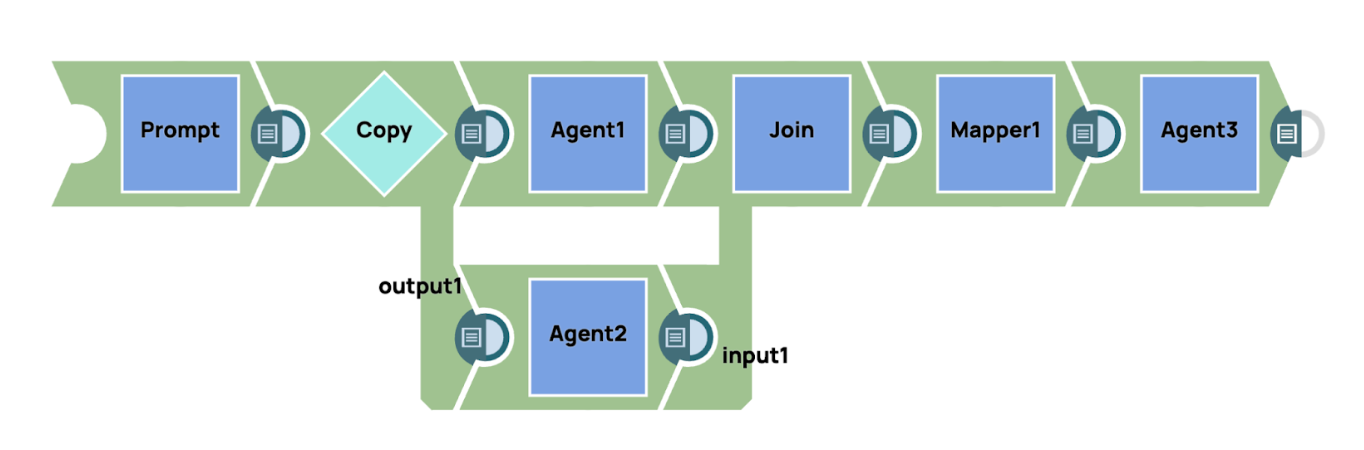
Chez SnapLogic, nous offrons une prise en charge complète pour la création les workflows avancés les workflows l'intégration de notre Snap GenAI Builder. Cette fonctionnalité permet aux utilisateurs d'intégrer de manière transparente des capacités d'IA générative dans leurs processus d'automatisation des workflows. En tirant parti de GenAI Builder Snap, les utilisateurs peuvent exploiter la puissance de l'intelligence artificielle pour automatiser des tâches complexes de prise de décision, de traitement des données et de génération de contenu dans leurs les workflows existants. Cette intégration offre une approche rationalisée pour l'intégration de fonctionnalités basées sur l'IA, améliorant à la fois l'efficacité et la précision dans divers domaines opérationnels. Par exemple, les utilisateurs peuvent concevoir les workflows GenAI Builder Snap collabore avec d'autres composants SnapLogic, tels que des pipelines de données et des processus de transformation, afin de fournir une automatisation intelligente et contextuelle adaptée à leurs besoins commerciaux uniques.
Dans les pipelines d'exemple, le système envoie simultanément une invite à plusieurs agents IA, chacun ayant son domaine d'expertise spécialisé. Ces agents traitent indépendamment les aspects spécifiques de l'invite liés à leur spécialisation. Une fois que les agents ont généré leurs résultats respectifs, ceux-ci sont ensuite regroupés pour former une réponse cohérente. Afin d'améliorer encore la clarté et la concision du résultat final, un agent de synthèse est utilisé. Cet agent de synthèse agrège et affine les réponses détaillées de chaque agent spécialisé, distillant les informations en un résumé concis et unifié qui reprend les points clés de tous les agents, garantissant ainsi une réponse finale cohérente et bien structurée.
5. Conversation multi-agents
La conversation multi-agents désigne l'interaction et la communication entre plusieurs agents autonomes, généralement des systèmes d'IA, qui travaillent ensemble pour atteindre un objectif commun. Ce cadre est largement utilisé dans des domaines tels que la résolution collaborative de problèmes, les systèmes multi-utilisateurs et la coordination de tâches complexes nécessitant plusieurs points de vue ou domaines d'expertise. Contrairement à une conversation à agent unique, où une seule IA gère toutes les entrées et sorties, un système multi-agents répartit les tâches entre plusieurs agents spécialisés, ce qui permet une plus grande efficacité, une compréhension contextuelle plus approfondie et des capacités de résolution de problèmes améliorées. Voici les principales caractéristiques de l'utilisation des conversations multi-agents.
- Spécialisation et expertise : chaque agent d'un système multi-agents est conçu avec un rôle ou un domaine d'expertise spécifique. Cela permet au système d'exploiter les capacités spécialisées des agents pour traiter différents aspects d'une tâche. Par exemple, un agent peut se concentrer sur le traitement du langage naturel (NLP) pour comprendre les entrées, tandis qu'un autre peut gérer des calculs complexes ou récupérer des données provenant de sources externes. Cette division du travail garantit que les tâches sont traitées par les agents les plus compétents, ce qui permet d'obtenir des résultats plus précis et plus efficaces. La spécialisation réduit le risque d'erreurs et permet une compréhension plus approfondie et spécifique du domaine concerné.
- Collaboration et coordination : dans une conversation multi-agents, les agents ne travaillent pas de manière isolée, mais collaborent pour atteindre un objectif commun. Chaque agent contribue à la conversation générale en partageant des informations et en coordonnant ses actions afin de garantir la réussite de la tâche globale. Cette collaboration est essentielle pour traiter des problèmes complexes qui nécessitent l'apport de plusieurs domaines. Une coordination efficace permet d'éviter que les agents ne dupliquent le travail ou ne provoquent des conflits. Grâce à des protocoles prédéfinis ou à des mécanismes de négociation, les agents sont en mesure de travailler ensemble de manière harmonieuse, produisant une solution cohérente qui intègre leurs différentes contributions.
- Évolutivité : les systèmes multi-agents sont intrinsèquement évolutifs, ce qui les rend idéaux pour traiter des tâches de plus en plus complexes. À mesure que le système gagne en complexité ou rencontre de nouveaux défis, des agents supplémentaires dotés de compétences spécifiques peuvent être introduits sans surcharger le système. Chaque agent peut travailler de manière indépendante, et la conception modulaire du système permet une expansion en douceur. L'évolutivité garantit que le système peut traiter des ensembles de données plus volumineux, des entrées plus diverses ou des tâches plus complexes à mesure que l'environnement évolue. Cette adaptabilité est essentielle dans les environnements dynamiques où les charges de travail ou les exigences changent au fil du temps.
- Prise de décision décentralisée : dans un système multi-agents, la prise de décision est souvent décentralisée, ce qui signifie que chaque agent dispose de l'autonomie nécessaire pour prendre des décisions en fonction de son expertise et des informations dont il dispose. Ce processus décisionnel décentralisé permet aux agents de traiter des tâches en parallèle, sans avoir besoin d'une surveillance constante de la part d'un contrôleur central. Les agents pouvant fonctionner de manière indépendante, les décisions sont prises plus rapidement et les goulots d'étranglement sont évités. Cette approche décentralisée renforce également la résilience du système, car elle évite une dépendance excessive à un seul point de décision et permet une résolution des problèmes plus adaptative et localisée.
- Tolérance aux pannes et redondance : les systèmes multi-agents sont naturellement résistants aux erreurs et aux pannes. Chaque agent fonctionnant de manière indépendante, la défaillance d'un agent ne perturbe pas l'ensemble du système. Les autres agents peuvent poursuivre leurs tâches ou, si nécessaire, prendre le relais de l'agent défaillant. Cette redondance intégrée garantit le fonctionnement continu du système même lorsque certains agents rencontrent des problèmes. La tolérance aux pannes est particulièrement utile dans les systèmes complexes, car elle améliore la fiabilité et minimise les temps d'arrêt, permettant au système de maintenir ses performances même dans des conditions défavorables.
SnapLogic offre des fonctionnalités robustes pour intégrer l'automatisation des flux de travail à l'IA générative (GenAI), permettant aux utilisateurs de créer en toute transparence des systèmes de conversation multi-agents avancés en combinant le Snap GenAI avec d'autres Snaps au sein de leur pipeline. Cette intégration permet aux utilisateurs de créer les workflows sophistiqués les workflows plusieurs agents IA, chacun avec sa spécialisation, collaborent pour traiter des requêtes et des tâches complexes.
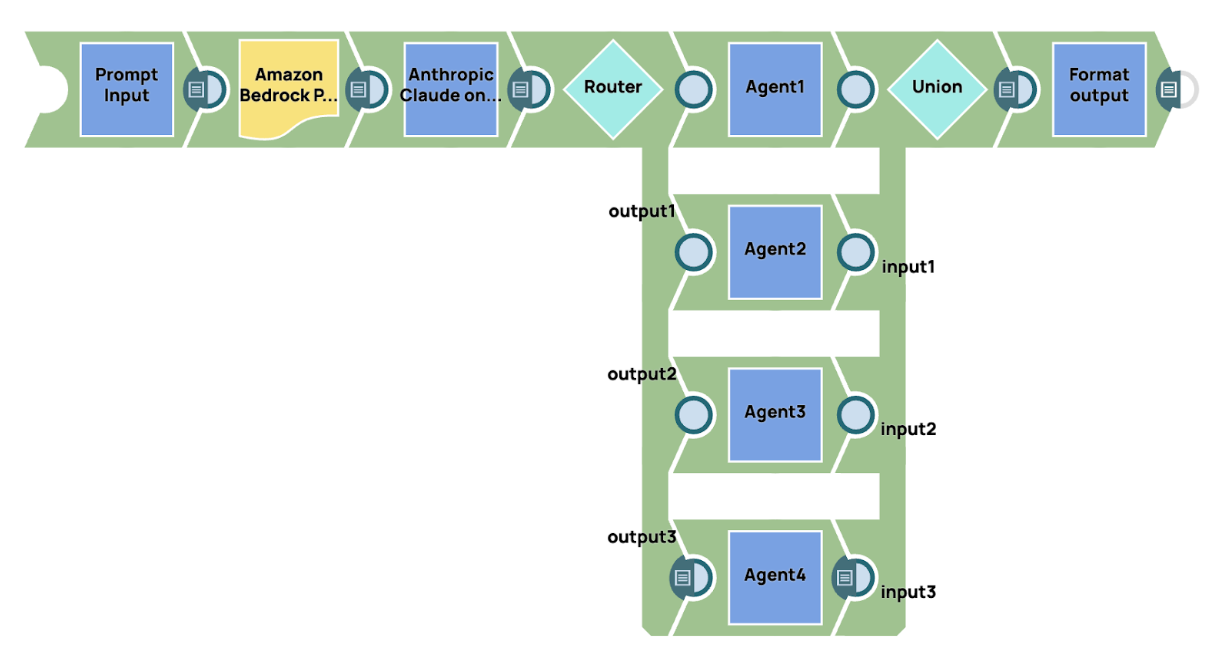
Dans cet exemple, nous présentons une implémentation simple d'un système de conversation multi-agents, qui utilise un agent gestionnaire pour superviser et contrôler le workflow. Le processus commence par l'envoi d'une invite à un grand modèle fondamental, qui, dans ce cas, est AWS Claude 3 Sonet. Ce modèle agit comme l'agent gestionnaire chargé d'interpréter l'invite et de déterminer le routage approprié pour les différentes parties de la tâche. En fonction du contenu et du contexte de l'invite, l'agent gestionnaire prend des décisions sur la manière de répartir la charge de travail entre les agents spécialisés.
Une fois la requête initiale traitée, nous utilisons le Router Snap pour acheminer dynamiquement la sortie vers les agents spécialisés correspondants. Chaque agent est conçu pour traiter un domaine ou une tâche spécifique, telle que l'analyse de données, le traitement du langage naturel ou la recherche de connaissances, garantissant ainsi que l'agent le plus pertinent et le plus spécialisé traite chaque partie de la requête.
Une fois que les agents spécialisés ont terminé leurs tâches respectives, leurs résultats sont rassemblés et consolidés. Le système envoie ensuite le résultat final agrégé à la destination de sortie. Cette approche garantit que tous les aspects de la requête sont traités de manière efficace et précise, chaque agent apportant son expertise à la solution globale.
La flexibilité de plateforme SnapLogic, combinée à l'intégration des modèles GenAI et Snaps, permet aux utilisateurs de concevoir, de dimensionner et d'optimiser facilement les workflows conversationnels multi-agents complexes. En automatisant le routage des tâches et la collaboration entre agents, SnapLogic offre des solutions plus intelligentes, évolutives et adaptées au contexte pour répondre à un large éventail de cas d'utilisation, de l'automatisation du service client au traitement avancé des données.
6. Génération d'augmentation de la récupération (RAG)
Pour améliorer la spécificité et la pertinence des réponses générées par un modèle d'IA générative (GenAI), il est essentiel de fournir au modèle un contexte suffisant. Les informations contextuelles aident le modèle à comprendre les nuances de la tâche à accomplir, ce qui lui permet de générer des résultats plus précis et plus pertinents. Cependant, dans de nombreux cas, la quantité de contexte nécessaire pour informer pleinement le modèle dépasse la limite de tokens que le modèle peut traiter en une seule invite. C'est là qu'une technique connue sous le nom de génération augmentée par la récupération (RAG) devient particulièrement utile.
RAG est conçu pour optimiser la manière dont le contexte est intégré au modèle GenAI. Plutôt que d'essayer d'intégrer toutes les informations nécessaires dans un espace d'entrée limité, RAG utilise un mécanisme de récupération qui extrait de manière dynamique les informations pertinentes à partir d'une base de connaissances externe. Cette approche permet aux utilisateurs de surmonter le défi de la limite de jetons en ne récupérant que les informations les plus pertinentes au moment de la génération de la requête, garantissant ainsi que le contexte fourni au modèle reste ciblé et concis.
Le cadre RAG peut être divisé en deux phases principales :
- Intégration des connaissances dans une base de données vectorielle : Dans la phase initiale, le contenu pertinent est intégré dans un espace vectoriel à l'aide d'un modèle d'apprentissage automatique qui transforme les données textuelles en un format propice à la recherche de similitudes. Ce processus d'intégration convertit efficacement le texte en vecteurs, ce qui facilite son stockage et sa récupération ultérieure en fonction de sa signification sémantique. Une fois intégrées, les connaissances sont stockées dans une base de données vectorielle pour un accès futur.
 Dans SnapLogic, l'intégration des connaissances dans une base de données vectorielle peut être réalisée grâce à un pipeline rationalisé conçu pour être efficace et évolutif. Le processus commence par la lecture d'un fichier PDF à l'aide du Lecteur de fichiers Snap, puis en extrayant le contenu à l'aide de la commande Analyseur PDF Snap, qui convertit le document en un format de texte structuré. Une fois le texte disponible, le Chunker Snap est utilisé pour segmenter intelligemment le contenu en morceaux plus petits et plus faciles à gérer. Ces morceaux sont spécialement dimensionnés pour s'aligner sur les contraintes d'entrée du modèle, garantissant ainsi des performances optimales lors des étapes ultérieures de la récupération.
Dans SnapLogic, l'intégration des connaissances dans une base de données vectorielle peut être réalisée grâce à un pipeline rationalisé conçu pour être efficace et évolutif. Le processus commence par la lecture d'un fichier PDF à l'aide du Lecteur de fichiers Snap, puis en extrayant le contenu à l'aide de la commande Analyseur PDF Snap, qui convertit le document en un format de texte structuré. Une fois le texte disponible, le Chunker Snap est utilisé pour segmenter intelligemment le contenu en morceaux plus petits et plus faciles à gérer. Ces morceaux sont spécialement dimensionnés pour s'aligner sur les contraintes d'entrée du modèle, garantissant ainsi des performances optimales lors des étapes ultérieures de la récupération.
Après avoir découpé le texte, chaque segment est traité et intégré dans une représentation vectorielle, qui est ensuite stockée dans la base de données vectorielle. Cela permet une recherche efficace basée sur la similarité, permettant au système d'accéder rapidement aux informations pertinentes selon les besoins. En utilisant ce pipeline dans SnapLogic, les utilisateurs peuvent facilement gérer et stocker de grands volumes de connaissances d'une manière qui prend en charge des applications d'IA contextuelles hautement performantes. - Récupération du contexte par comparaison de similarité : Lorsqu'une requête est reçue, le système effectue une comparaison de similarité afin de récupérer le contenu le plus pertinent dans la base de données vectorielle. En évaluant la similarité entre la requête intégrée et les vecteurs stockés, RAG identifie les informations les plus pertinentes, qui sont ensuite utilisées pour enrichir l'invite de saisie. Cette étape garantit que le modèle GenAI reçoit des données ciblées et enrichies contextuellement, ce qui lui permet de générer des réponses plus pertinentes et plus précises.

Pour récupérer le contexte pertinent à partir de la base de données vectorielle dans SnapLogic, les utilisateurs peuvent exploiter un bouton d'intégration, comme le AWS Titan Embedder, afin de transformer la requête entrante en une représentation vectorielle. Ce vecteur sert de clé pour effectuer une recherche basée sur la similarité dans la base de données vectorielle où sont stockées les connaissances préalablement intégrées. Le mécanisme de recherche vectorielle identifie efficacement les informations les plus pertinentes, garantissant ainsi que seul le contenu le plus approprié au contexte est récupéré.
Une fois les connaissances pertinentes récupérées, elles peuvent être intégrées de manière transparente dans le processus global de génération de messages. Pour ce faire, on introduit généralement le contexte récupéré dans un générateur de messages snap, qui structure les informations dans un format optimisé pour être utilisé par le modèle d'IA générative. Dans ce cas, la requête finale, enrichie du contexte pertinent, est envoyée au GenAI Snap, comme Claude d'Anthropic au sein du Messages AWS SnapCette approche garantit que le modèle reçoit des informations très spécifiques et pertinentes, ce qui améliore en fin de compte la précision et la pertinence des réponses générées.
En mettant en œuvre le RAG, les utilisateurs peuvent exploiter pleinement le potentiel des modèles GenAI, même lorsqu'ils traitent des requêtes complexes qui exigent une quantité importante de contexte. Cette approche améliore non seulement la précision des réponses du modèle, mais garantit également que celui-ci reste efficace et évolutif, ce qui en fait un outil puissant pour un large éventail d'applications concrètes.
7. Appel d'outils et instructions contextuelles
Les modèles GenAI traditionnels sont limités par les données sur lesquelles ils ont été entraînés. Une fois entraînés, ces modèles ne peuvent pas accéder à des informations nouvelles ou mises à jour, à moins d'être réentraînés. Cette limitation signifie que sans apport externe, les modèles ne peuvent générer que des réponses basées sur le contenu statique de leur corpus d'entraînement. Cependant, dans un monde où les données évoluent constamment, s'appuyer sur des connaissances statiques est souvent insuffisant, en particulier pour les tâches qui nécessitent des informations actuelles ou en temps réel. Dans de nombreuses applications concrètes, les modèles d'IA générative (GenAI) ont besoin d'accéder à des données en temps réel pour générer des réponses contextuellement précises et pertinentes. Par exemple, si un utilisateur demande la météo actuelle dans un endroit particulier, le modèle ne peut pas se fier uniquement aux connaissances pré-entraînées, car ces données sont dynamiques et en constante évolution. Dans de tels scénarios, les techniques traditionnelles d'ingénierie des invites sont insuffisantes, car elles s'appuient principalement sur des informations statiques qui étaient disponibles au moment de l'entraînement du modèle. C'est là que la technique d'appel d'outils devient inestimable.
L'appel d'outils fait référence à la capacité d'un modèle GenAI à interagir avec des outils externes, des API ou des bases de données afin de récupérer des informations spécifiques en temps réel. Au lieu de s'appuyer sur ses connaissances internes, qui peuvent être obsolètes ou incomplètes, le modèle peut demander des données actualisées à des sources externes et les utiliser pour générer une réponse à la fois précise et pertinente dans son contexte. Ce processus élargit considérablement les capacités de GenAI, lui permettant d'aller au-delà du contenu statique et pré-entraîné et d'intégrer des données dynamiques et réelles dans ses réponses.
Par exemple, lorsqu'un utilisateur demande des informations météorologiques en temps réel, les cours de la bourse ou les conditions de circulation, le modèle GenAI peut déclencher un appel vers une API externe (telle qu'un service météorologique, un fournisseur de données financières ou un service de cartographie) afin de récupérer les données nécessaires. Ces données sont ensuite intégrées à la réponse du modèle, ce qui lui permet de fournir une réponse précise et opportune, ce qui aurait été impossible en utilisant uniquement des invites statiques.
L'instruction contextuelle joue un rôle essentiel dans le processus d'appel d'outils. Avant d'appeler un outil externe, le modèle GenAI doit comprendre la nature de la demande de l'utilisateur et identifier quand des données externes sont nécessaires. Par exemple, si un utilisateur demande « Quel temps fait-il à Paris en ce moment ? », le modèle reconnaît que la question nécessite des informations météorologiques en temps réel et qu'il ne peut y répondre en se basant uniquement sur ses connaissances internes. Le modèle est donc programmé pour déclencher l'appel d'un outil vers une API de service météorologique pertinente, récupérer les données météorologiques en direct pour Paris et les intégrer dans la réponse finale. Cette capacité à comprendre et à différencier les connaissances statiques (qui peuvent être répondues à l'aide de données pré-entraînées) et les informations dynamiques en temps réel (qui nécessitent l'appel d'un outil externe) est essentielle pour que les modèles GenAI fonctionnent efficacement dans des environnements complexes et réels.
Cas d'utilisation pour l'appel d'outils
- Récupération de données en temps réel: les modèles GenAI peuvent appeler des API externes pour récupérer des données en temps réel telles que les conditions météorologiques, les cours boursiers, les dernières actualités ou les résultats sportifs en direct. Ces appels d'outils garantissent que l'IA fournit des réponses à jour et précises qui reflètent les dernières informations.
- Calculs complexes et tâches spécialisées: l'appel d'outils permet aux modèles d'IA de traiter des tâches qui nécessitent des calculs spécifiques ou une expertise dans un domaine particulier. Par exemple, un modèle d'IA traitant une requête financière peut faire appel à un outil d'analyse financière externe pour effectuer des calculs complexes ou récupérer des données historiques sur les marchés boursiers.
- Intégration avec les systèmes d'entreprise: dans les environnements professionnels, les modèles GenAI peuvent interagir avec des systèmes externes tels que les plateformes CRM, les systèmes ERP ou les bases de données afin de récupérer ou de mettre à jour des informations en temps réel. Par exemple, un bot de service client basé sur GenAI peut extraire des informations de compte d'un système CRM ou vérifier le statut des commandes à partir d'un outil externe de gestion des commandes.
- Accès à des connaissances spécialisées: l'appel d'outils permet aux modèles d'IA d'extraire des informations spécialisées à partir de bases de données ou de référentiels de connaissances qui ne relèvent pas de leur domaine de formation. Par exemple, un assistant médical basé sur l'IA pourrait consulter une base de données externe contenant des articles de recherche médicale afin de fournir les options de traitement les plus récentes pour une affection particulière.
Mise en œuvre de l'appel d'outils dans les systèmes d'IA générative
L'appel d'outils est devenu une fonctionnalité intégrée à de nombreux modèles avancés d'IA générative (GenAI), leur permettant d'étendre leurs fonctionnalités en interagissant avec des systèmes et services externes. Par exemple, AWS Anthropic Claude prend en charge l'appel d'outils via l'API Message, offrant aux développeurs un moyen structuré d'intégrer des données et des fonctionnalités externes directement dans le flux de travail de réponse du modèle. Cette capacité permet au modèle d'améliorer ses réponses en incorporant des informations en temps réel, en exécutant des fonctions spécifiques ou en utilisant des API externes qui fournissent des données spécialisées au-delà de la formation du modèle.
Pour mettre en œuvre l'appel d'outils avec AWS Anthropic Claude, les utilisateurs peuvent exploiter l'API Message, qui permet une intégration transparente avec des systèmes externes. Le mécanisme d'appel d'outils est activé en envoyant un message avec un paramètre « tools » spécifique. Ce paramètre définit la manière dont l'outil ou l'API externe sera appelé, en utilisant un schéma JSON pour structurer l'appel de fonction. Cette approche permet au modèle GenAI de reconnaître quand une entrée externe est requise et de lancer un appel d'outil en fonction des instructions fournies.
Processus de mise en œuvre
- Définition du schéma de l'outil: Pour lancer un appel d'outil, les utilisateurs doivent envoyer une requête avec le « outils » paramètre. Ce paramètre est défini dans un schéma JSON structuré, qui comprend des détails sur l'outil externe ou l'API que le modèle GenAI appellera. Le schéma JSON décrit comment l'outil doit être utilisé, y compris le nom de la fonction, les paramètres et toutes les entrées nécessaires pour effectuer l'appel.

Par exemple, si l'outil est une API météo, le schéma peut définir des paramètres tels que l'emplacement et l'heure, permettant au modèle d'interroger l'API avec ces entrées pour récupérer les données météorologiques actuelles.
- Structure du message et lancement de la requête: une fois le schéma de l'outil défini, l'utilisateur peut envoyer un message à AWS Anthropic Claude contenant le paramètre « tools » ainsi que l'invite ou la requête. Le modèle interprète alors la requête et, en fonction du contexte de la conversation ou de la tâche, détermine s'il doit faire appel à l'outil externe spécifié dans le schéma. Si un appel à l'outil est nécessaire, le modèle répond avec une valeur « stop_reason » de « tool_use ». Cette réponse indique que le modèle interrompt sa génération pour faire appel à l'outil externe, plutôt que de compléter la réponse en utilisant uniquement ses connaissances internes.
- Exécution de l'appel d'outil: lorsque le modèle répond avec « stop_reason » : « tool_use », cela signifie que l'API ou la fonction externe doit être appelée avec les entrées fournies. À ce stade, l'API externe (telle que spécifiée dans le schéma JSON) est déclenchée pour récupérer les données requises ou effectuer la tâche désignée. Par exemple, si l'utilisateur demande « Quel temps fait-il à New York en ce moment ? » et que le schéma JSON définit un outil API météo, le modèle fera une pause et appellera l'API avec le paramètre de localisation défini sur « New York » et le paramètre de temps défini sur « actuel ».
- Traitement de la réponse API: une fois que l'outil externe a traité la requête et renvoyé le résultat, l'utilisateur (ou le système) envoie un message de suivi contenant le « tool_result ». Ce message comprend le résultat de l'appel à l'outil, qui peut ensuite être intégré à la conversation ou à la tâche en cours. En pratique, cela peut ressembler à une API météo renvoyant un objet JSON avec la température, l'humidité et les conditions météorologiques. La réponse est renvoyée au modèle GenAI via un message utilisateur, qui contient les données « tool_result ».
- Génération de la réponse finale: une fois que le modèle reçoit le « tool_result », il traite les données et finalise la réponse. Cela permet au modèle GenAI de fournir une réponse finale qui intègre des informations en temps réel ou spécialisées récupérées à partir du système externe. Dans notre exemple météorologique, la réponse finale pourrait être : « La température actuelle à New York est de 22 °C avec un ciel dégagé. »
Actuellement, SnapLogic ne fournit pas encore de prise en charge native pour l'appel d'outils dans le GenAI Snap Pack. Cependant, nous reconnaissons l'immense potentiel et la valeur que cette fonctionnalité peut apporter aux utilisateurs, en permettant une intégration transparente avec des systèmes et services externes pour des données en temps réel et des fonctionnalités avancées. Nous travaillons activement à l'intégration de capacités d'appel d'outils dans les futures mises à jour de la plateforme. Cette amélioration permettra aux utilisateurs de créer les workflows plus dynamiques et plus intelligents, élargissant ainsi les possibilités d'automatisation et de solutions basées sur l'IA. Nous sommes enthousiasmés par le potentiel qu'elle recèle et nous sommes impatients de partager ces innovations très prochainement.
8. Mémoire et cognition pour les modèles linguistiques à grande échelle (LLM)
La plupart des grands modèles linguistiques (LLM) fonctionnent dans les limites d'une fenêtre contextuelle, ce qui signifie qu'ils ne peuvent traiter et analyser qu'un nombre fini de tokens (mots, phrases ou symboles) à un moment donné. Cette limitation pose des défis importants, en particulier lorsqu'il s'agit de tâches complexes, de dialogues prolongés ou d'interactions qui nécessitent une compréhension contextuelle à long terme. Par exemple, si une conversation ou une tâche dépasse la limite de tokens, le modèle perd la conscience des parties précédentes de l'interaction, ce qui conduit à des réponses qui peuvent devenir incohérentes, répétitives ou hors contexte.
Cette limitation devient particulièrement problématique dans les applications où il est essentiel de maintenir la continuité et la cohérence tout au long d'interactions prolongées. Dans les scénarios de service à la clientèle, les outils de gestion de projet ou les applications éducatives, il est souvent nécessaire de se souvenir d'informations détaillées issues d'échanges antérieurs ou de suivre les progrès au fil du temps. Cependant, les modèles traditionnels limités par une fenêtre de jetons fixe ont du mal à rester pertinents dans de telles situations, car ils sont incapables de « se souvenir » ou d'accéder aux parties antérieures de la conversation une fois que la fenêtre contextuelle est dépassée.
Pour pallier ces limites et permettre aux LLM de gérer des interactions plus longues et plus complexes, nous utilisons une technique appelée « cognition mémorielle ». Cette technique étend les capacités des LLM en introduisant des mécanismes qui permettent au modèle de conserver, de rappeler et d'intégrer de manière dynamique les interactions ou informations passées, même lorsque ces interactions ne font pas partie du contexte immédiat.
Composants de cognition mémorielle dans les applications d'IA générative
Pour mettre en œuvre avec succès la cognition mémorielle dans les applications d'IA générative (GenAI), une approche globale et structurée est nécessaire. Cela implique l'intégration de divers composants mémoriels qui fonctionnent ensemble pour permettre au système d'IA de conserver, de récupérer et d'utiliser les informations pertinentes dans différentes interactions. La cognition mémorielle permet au modèle d'IA d'aller au-delà du traitement sans état et à court terme, créant ainsi un système plus sensible au contexte, adaptatif et intelligent, capable d'interactions et de prises de décision à long terme. Voici les composants clés de la cognition mémorielle qui doivent être pris en compte lors du développement d'une application GenAI :
de la mémoire à court terme (mémoire de session) La mémoire à court terme, communément appelée mémoire de session, englobe la capacité du modèle à conserver le contexte et les informations au cours d'une seule interaction ou session. Cette composante est essentielle pour maintenir la cohérence dans les conversations à plusieurs tours et les tâches à court terme. Elle permet au modèle de maintenir la continuité de ses réponses en se référant aux parties précédentes de la conversation, évitant ainsi à l'utilisateur de répéter des informations déjà fournies.
En général, la mémoire à court terme est limitée à la durée de l'interaction. Une fois la session terminée ou une nouvelle session commencée, la mémoire est soit réinitialisée, soit progressivement effacée. Cela permet au modèle de se souvenir des détails pertinents de la même session, créant ainsi une expérience conversationnelle plus fluide et plus naturelle. Par exemple, dans un chatbot de service client, la mémoire à court terme permet à l'IA de se souvenir du problème d'un client tout au long de la conversation, garantissant ainsi que le problème est traité de manière cohérente sans que l'utilisateur ait besoin de le répéter plusieurs fois.
Cependant, dans les grands modèles linguistiques, la mémoire à court terme est souvent limitée par la fenêtre contextuelle du modèle, qui est contrainte par le nombre maximal de tokens qu'il peut traiter en une seule invite. À mesure que de nouvelles entrées sont ajoutées au cours de la conversation, les parties les plus anciennes du dialogue peuvent être supprimées ou oubliées, en fonction de la limite de tokens. Cela nécessite une gestion minutieuse de la mémoire à court terme afin de garantir que les informations critiques sont conservées tout au long de la session.
de la mémoire à long terme La mémoire à long terme améliore considérablement les capacités du modèle en lui permettant de conserver des informations au-delà d'une seule session. Contrairement à la mémoire à court terme, qui se limite à une seule interaction, la mémoire à long terme persiste à travers plusieurs interactions, permettant à l'IA de se souvenir d'informations importantes sur les utilisateurs, leurs préférences, leurs conversations passées ou des détails spécifiques à une tâche, quel que soit le temps écoulé entre les sessions. Ce type de mémoire est généralement stocké dans une base de données externe ou un référentiel de connaissances, ce qui garantit qu'il reste accessible au fil du temps et n'expire pas à la fin d'une session.
La mémoire à long terme est particulièrement utile dans les applications qui nécessitent la conservation d'informations critiques ou personnalisées, telles que les préférences des utilisateurs, l'historique ou les tâches récurrentes. Elle permet des interactions hautement personnalisées, car l'IA peut se référer aux informations stockées pour adapter ses réponses en fonction des interactions précédentes de l'utilisateur. Par exemple, dans les applications d'assistant virtuel, la mémoire à long terme permet à l'IA de se souvenir des préférences d'un utilisateur, telles que sa musique préférée ou ses rendez-vous réguliers, et d'utiliser ces informations pour fournir des réponses et des recommandations personnalisées.
Dans les environnements d'entreprise, tels que les systèmes d'assistance à la clientèle, la mémoire à long terme permet à l'IA de se référer aux problèmes ou aux demandes précédents du même utilisateur, ce qui lui permet d'offrir une assistance plus éclairée et mieux adaptée. Cette capacité améliore l'expérience utilisateur en réduisant le besoin de répétition et en améliorant l'efficacité et l'efficience globales de l'interaction. La mémoire à long terme joue donc un rôle crucial en permettant aux systèmes d'IA de fournir des réponses cohérentes, contextuelles et personnalisées au cours de plusieurs sessions.
de la gestion de la mémoireLa gestion dynamique de la mémoire fait référence à la capacité du modèle d'IA à gérer et hiérarchiser intelligemment les informations stockées, en ajustant en permanence ce qui est conservé, supprimé ou récupéré en fonction de sa pertinence par rapport à la tâche à accomplir. Cette capacité est essentielle pour optimiser l'utilisation de la mémoire à court et à long terme, garantissant que le modèle reste réactif et efficace sans être encombré par des informations non pertinentes ou obsolètes. Une gestion dynamique efficace de la mémoire permet au système d'IA d'adapter son allocation de mémoire en temps réel, en fonction des besoins immédiats de la conversation ou de la tâche.
Concrètement, la gestion dynamique de la mémoire permet à l'IA de hiérarchiser les informations importantes, telles que les faits clés, les préférences des utilisateurs ou les données contextuellement critiques, tout en supprimant ou en dépriorisant les détails insignifiants ou obsolètes. Par exemple, au cours d'une conversation, le système peut se concentrer sur la conservation des informations essentielles qui sont fréquemment référencées ou très pertinentes pour la requête actuelle de l'utilisateur, tout en permettant aux informations moins pertinentes de se dégrader ou d'être supprimées. Ce processus garantit que l'IA peut rester clairement concentrée sur ce qui importe le plus, améliorant ainsi à la fois la précision et l'efficacité.
Pour faciliter cela, le système utilise souvent des mécanismes de notation de la pertinence pour évaluer et classer l'importance des souvenirs stockés. Chaque élément de mémoire peut se voir attribuer un score de priorité en fonction de facteurs tels que la fréquence à laquelle il est référencé ou son importance pour la tâche en cours. Les mémoires à priorité élevée sont conservées plus longtemps, tandis que les entrées à priorité faible ou obsolètes peuvent être marquées pour suppression. Ce système de notation permet d'éviter la surcharge de mémoire en garantissant que seules les informations les plus pertinentes sont conservées au fil du temps.
La gestion dynamique de la mémoire comprend également des mécanismes de dégradation de la mémoire, dans lesquels les informations plus anciennes ou moins pertinentes « s'estompent » progressivement ou sont automatiquement supprimées du stockage, ce qui évite la saturation de la mémoire. Cela garantit que l'IA ne conserve que les données les plus critiques, évitant ainsi les inefficacités et assurant des performances optimales, en particulier dans les applications à grande échelle qui impliquent des quantités importantes de données ou des opérations gourmandes en mémoire.
Afin d'optimiser davantage l'utilisation des ressources, des processus automatisés peuvent être mis en œuvre pour « oublier » les entrées de mémoire qui n'ont pas été référencées depuis un certain temps ou qui ne sont plus pertinentes pour les tâches en cours. Ces processus garantissent une allocation efficace des ressources mémoire, telles que la capacité de stockage et la puissance de traitement, en particulier dans les environnements nécessitant une mémoire à grande échelle. Grâce à la gestion dynamique de la mémoire, l'IA peut continuer à fournir des réponses contextuellement précises et opportunes tout en maintenant un système de mémoire équilibré et efficace.
Mise en œuvre de la cognition mémorielle dans Snaplogic
SnapLogic offre des fonctionnalités robustes pour l'intégration avec les bases de données et les systèmes de stockage, ce qui en fait une plateforme idéale plateforme créer les workflows gérer la cognition mémorielle dans les applications d'IA. Dans l'exemple suivant, nous présentons un modèle de cognition mémorielle de base utilisant SnapLogic pour gérer à la fois la mémoire à court terme et la mémoire à long terme.
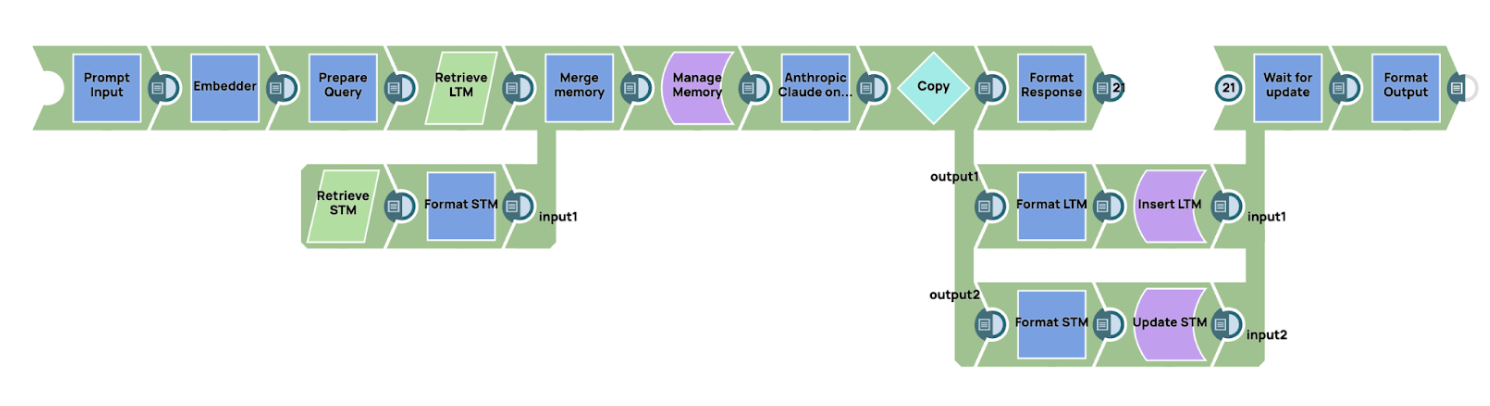
Aperçu du le workflow
le workflow par intégrer l'invite dans une représentation vectorielle. Ce vecteur est ensuite utilisé pour récupérer les souvenirs pertinents stockés dans la mémoire à long terme. La mémoire à long terme peut être stockée dans une base de données vectorielle, qui est bien adaptée à la recherche basée sur la similarité, ou dans une base de données traditionnelle ou un magasin clé-valeur, selon les exigences de l'application. De même, la mémoire à court terme peut être stockée dans une base de données classique ou un magasin clé-valeur afin de garder une trace des interactions récentes.
- Récupération des souvenirs
Une fois la requête intégrée, nous récupérons les informations pertinentes à partir des systèmes de mémoire à court et à long terme. Le processus de récupération est basé sur un score de similarité, qui indique la pertinence de la mémoire stockée par rapport à la requête actuelle. Pour la mémoire à long terme, cela implique généralement d'interroger une base de données vectorielle, tandis que la mémoire à court terme peut être récupérée à partir d'une base de données relationnelle traditionnelle ou d'un magasin clé-valeur. Après avoir récupéré les souvenirs pertinents dans les deux systèmes, les données sont transmises à un module de gestion de la mémoire. Dans cet exemple, nous mettons en œuvre un mécanisme simple de gestion de la mémoire à l'aide d'un script dans SnapLogic.
de gestion de la mémoireLe module de gestion de la mémoire utilise une technique de fenêtre glissante, qui est un moyen simple mais efficace de gérer la mémoire. À mesure que de nouvelles données sont ajoutées, les données plus anciennes s'estompent progressivement jusqu'à être supprimées de la pile mémoire. Cela garantit que l'IA conserve les informations les plus récentes et les plus pertinentes tout en supprimant les données obsolètes ou moins utiles. Le mécanisme de fenêtre glissante donne la priorité aux données les plus récentes ou les plus pertinentes, en les plaçant en haut de la pile mémoire, tandis que les données plus anciennes sont progressivement supprimées.- Génération de l'invite finale et interaction avec le LLM
Une fois que le module de gestion de la mémoire a construit le contexte complet en combinant la mémoire à court terme et la mémoire à long terme, le système génère l'invite finale. Cette invite est ensuite envoyée au modèle linguistique pour traitement. Dans ce cas, nous utilisons AWS Claude via l'API Message comme modèle linguistique à grande échelle (LLM) pour générer une réponse basée sur le contexte fourni. - Mise à jour de la mémoire
Après réception d'une réponse du LLM, le workflow à la mise à jour des systèmes de mémoire à court et à long terme afin d'assurer la continuité et la pertinence des interactions futures :- Mémoire à long terme : la mémoire à long terme est actualisée en associant la requête initiale à la réponse du LLM. Dans ce contexte, la clé de requête correspond à la requête initiale, tandis que la valeur correspond à la réponse générée par le modèle. Cette mise à jour permet au système de stocker des connaissances pertinentes qui pourront être consultées lors d'interactions futures, ce qui permet d'obtenir des réponses plus éclairées et mieux adaptées au contexte au fil du temps.
- Mémoire à court terme : la mémoire à court terme est mise à jour en ajoutant la réponse du LLM à la pile de mémoire la plus récente. Ce processus garantit le maintien du contexte immédiat de la conversation en cours, ce qui permet des transitions fluides et une cohérence dans les interactions suivantes au cours de la session.
Cet exemple montre comment SnapLogic peut être utilisé efficacement pour gérer la cognition mémorielle dans les applications d'IA. En intégrant des bases de données et en tirant parti de la puissante automatisation des flux de travail de SnapLogic, nous pouvons créer un système intelligent de gestion de la mémoire qui gère à la fois la mémoire à court terme et la mémoire à long terme. Le mécanisme de fenêtre glissante garantit que l'IA reste sensible au contexte tout en évitant la surcharge de mémoire, et AWS Claude fournit la puissance de traitement nécessaire pour générer des réponses basées sur une compréhension contextuelle riche. Cette approche offre une solution évolutive et flexible pour gérer la cognition de la mémoire dans les workflows basés sur l'IA.






