






Nel campo in rapida evoluzione dell'IA generativa (GenAI), le conoscenze di base possono portarti lontano, ma è la padronanza dei modelli avanzati che ti consente davvero di creare applicazioni sofisticate, scalabili ed efficienti. Con l'aumentare della complessità delle attività basate sull'IA, cresce anche la necessità di strategie solide in grado di gestire scenari diversi, dal mantenimento del contesto nelle conversazioni multi-turno alla generazione dinamica di contenuti basati sugli input degli utenti.
Questa guida approfondisce questi modelli avanzati, offrendo un'analisi approfondita delle strategie che possono migliorare le vostre applicazioni GenAI. Che siate amministratori che cercano di ottimizzare i propri sistemi di IA o sviluppatori che mirano a superare i limiti del possibile, comprendere e implementare questi modelli vi consentirà di gestire e risolvere sfide complesse con sicurezza.
1. Ingegneria avanzata dei prompt
1.1 Controllo completo del formato di risposta
Nelle applicazioni GenAI, il controllo del formato di output è fondamentale per garantire che le risposte siano in linea con le specifiche esigenze degli utenti. L'ingegneria avanzata dei prompt consente di creare prompt che forniscono istruzioni precise su come l'IA dovrebbe strutturare il proprio output. Questo approccio non solo migliora la coerenza delle risposte, ma le rende anche più allineate agli obiettivi desiderati.
Ad esempio, è possibile progettare prompt con una struttura dettagliata che include più elementi come contesto, obiettivo, stile, pubblico e lunghezza della risposta desiderata. Questo metodo consente un controllo granulare sull'output. Un prompt di esempio potrebbe essere simile al seguente:
- Contesto: fornire informazioni di base sull'argomento per preparare il terreno.
- Obiettivo: definire chiaramente lo scopo della risposta.
- Stile: specificare se la risposta deve essere formale, informale, tecnica o creativa.
- Pubblico: Identificare il pubblico di destinazione, che influenza il linguaggio e la profondità della spiegazione.
- Formato della risposta: istruire l'IA a generare una risposta che richieda circa 3 minuti per essere letta, assicurando profondità e completezza, tipicamente composta da 4-5 paragrafi.
Questo livello di dettaglio nella progettazione dei prompt garantisce che i contenuti generati dall'IA soddisfino esigenze specifiche, rendendoli adatti a vari casi d'uso, come la generazione di materiale didattico, report dettagliati o comunicazioni con i clienti.
1.2 Apprendimento con pochi esempi (Few-Shot Learning)
L'apprendimento con pochiesempi è una tecnica avanzata in cui al modello di IA viene fornito un numero limitato di esempi (spesso solo pochi) all'interno del prompt per guidarne l'output. Questo metodo è particolarmente efficace quando si tratta di compiti che richiedono al modello di comprendere e replicare modelli o formati complessi con un input minimo. Apprendimento con pochi esempi (
) Incorporando gli esempi direttamente nel prompt, è possibile addestrare il modello a produrre risposte più accurate e contestualmente appropriate anche in scenari in cui non sono disponibili grandi quantità di dati di addestramento.
Questo approccio è prezioso per personalizzare il comportamento dell'IA in applicazioni di nicchia in cui i dati di addestramento generalizzati potrebbero non essere sufficienti.
Esempio di prompt:
"Genera una descrizione del prodotto per i seguenti articoli. La descrizione deve essere concisa, evidenziare le caratteristiche principali e attrarre un pubblico interessato alla qualità e all'innovazione.
Esempio 1:
- Nome del prodotto: Termostato WiFi SmartHome
- Descrizione: "Il termostato WiFi SmartHome è la soluzione definitiva per un controllo efficiente della temperatura. Grazie alla perfetta integrazione nel tuo ecosistema domestico intelligente, offre comandi intuitivi, impostazioni personalizzabili e report in tempo reale sul consumo energetico. Progettato per la vita moderna, garantisce il massimo comfort aiutandoti a risparmiare sulla bolletta energetica."
Esempio 2:
- Nome del prodotto: Caffettiera in acciaio inossidabile EcoBrew
- Descrizione: "La caffettiera in acciaio inossidabile EcoBrew combina sostenibilità e prestazioni di alto livello. Realizzata in resistente acciaio inossidabile, questa caffettiera ecologica prepara ogni volta una tazza di caffè perfetta, con un impatto ambientale minimo. Ideale per gli amanti del caffè attenti all'ambiente, offre una preparazione precisa e un design elegante che si adatta a qualsiasi cucina".
Nuovo articolo:
- Nome del prodotto: Zaino da viaggio ultraleggero
Descrizione:
Risultato generato dall'intelligenza artificiale:
“Zaino da viaggio ultraleggero: lo zaino da viaggio ultraleggero è progettato per l'avventuriero moderno. Con un peso inferiore a mezzo chilo, offre una portabilità senza pari senza sacrificare la capacità di stoccaggio. Caratterizzato da tessuto resistente all'acqua, scomparti multipli e spallacci ergonomici, questo zaino è progettato per chi ha bisogno di resistenza e praticità in viaggio. Perfetto per escursioni di un giorno, fughe nel fine settimana o uso quotidiano, lo zaino da viaggio ultraleggero è il tuo compagno affidabile in ogni viaggio."
Spiegazione:
In questo esempio, all'IA sono state fornite due descrizioni di prodotti che illustrano lo stile, il tono e la struttura desiderati dell'output. Quando è stato chiesto di generare una nuova descrizione per lo "Zaino da viaggio ultraleggero", l'IA ha utilizzato i modelli degli esempi forniti per creare una descrizione del prodotto simile e contestualmente appropriata. Nonostante gli siano stati mostrati solo due esempi, il modello ha efficacemente catturato gli elementi chiave necessari per generare un output nuovo e di alta qualità.
Questo approccio è molto utile quando è necessario che l'IA produca risultati coerenti in compiti simili, specialmente in scenari in cui la creazione di dati di addestramento estesi è poco pratica. Fornendo solo alcuni esempi, si guida la comprensione dell'IA, consentendole di applicare il modello appreso a compiti nuovi, ma correlati.
1.3 Catena di pensieri
La catena di schemi di pensiero incoraggia l'IA a generare risposte che seguono una sequenza logica, rispecchiando il ragionamento umano. Questa tecnica è particolarmente utile in scenari complessi in cui l'IA deve prendere decisioni, risolvere problemi o spiegare concetti passo dopo passo.
Strutturando prompt che guidano l'IA attraverso una serie di processi mentali, è possibile indirizzarla verso risultati più coerenti e razionali. Ciò è particolarmente efficace nelle applicazioni che richiedono spiegazioni dettagliate, come il ragionamento scientifico, la risoluzione di problemi tecnici o qualsiasi situazione in cui l'IA debba giustificare le proprie conclusioni. Ad esempio, un prompt potrebbe istruire l'IA a suddividere un problema complesso in parti più piccole e gestibili e ad affrontarle in modo sequenziale. L'IA identificherebbe innanzitutto i componenti chiave del problema, quindi li elaborerebbe uno per uno, spiegando il proprio ragionamento in ogni fase. Questo metodo non solo migliora la chiarezza della risposta, ma anche l'accuratezza e la pertinenza delle conclusioni dell'IA.
2. Elaborazione multimodale
L'elaborazione multimodale nell'IA generativa è un approccio all'avanguardia che consente ai sistemi di IA di integrare ed elaborare contemporaneamente più tipi di dati, come testo, immagini, audio e video. Questa capacità è fondamentale per le applicazioni che richiedono una comprensione approfondita dei contenuti in diverse modalità, consentendo di ottenere risultati più accurati e ricchi dal punto di vista contestuale.
Ad esempio, in uno scenario in cui un'IA ha il compito di generare una descrizione di una scena da un video, l'elaborazione multimodale le consente di analizzare sia gli elementi visivi che l'audio di accompagnamento per produrre una descrizione che rifletta non solo ciò che si vede, ma anche il contesto fornito dal suono. Allo stesso modo, quando si elaborano insieme testo e immagini, come in un'attività di sottotitolazione, l'IA può comprendere meglio la relazione tra le parole e il contenuto visivo, ottenendo sottotitoli più precisi e pertinenti.
Questo modello avanzato è particolarmente utile in ambienti complessi in cui la comprensione delle sfumature tra i diversi tipi di dati è fondamentale per fornire risultati di alta qualità. Ad esempio, nella diagnostica medica, i sistemi di IA che utilizzano l'elaborazione multimodale possono analizzare immagini mediche insieme alle cartelle cliniche dei pazienti e alle note vocali per offrire diagnosi più accurate. Nel servizio clienti, l'IA può interpretare e rispondere alle richieste dei clienti analizzando contemporaneamente il testo e il tono della voce, migliorando la qualità delle interazioni.
Inoltre, l'elaborazione multimodale migliora la capacità dell'IA di apprendere da diverse fonti di dati, consentendole di costruire modelli più robusti che si generalizzano meglio in compiti diversi. Ciò la rende uno strumento essenziale nello sviluppo di applicazioni di IA che devono operare in scenari reali in cui i dati sono raramente omogenei.
Sfruttando l'elaborazione multimodale, i sistemi di IA sono in grado di generare risposte non solo più complete, ma anche personalizzate in base alle esigenze specifiche dell'attività da svolgere, rendendoli altamente efficaci in un'ampia gamma di applicazioni. Con la continua evoluzione di questa tecnologia, si aprono nuove possibilità in settori diversi come l'intrattenimento, l'istruzione, la sanità e molti altri.
Esempio
In molte situazioni, i dati possono includere sia immagini che testo che devono essere analizzati insieme per ottenere informazioni complete. Per elaborare e integrare in modo efficace questi diversi tipi di dati, è possibile utilizzare una pipeline di elaborazione multimodale in SnapLogic. Questo approccio consente al modello di IA generativa di analizzare simultaneamente i dati provenienti da entrambe le fonti, mantenendo l'integrità di ciascuna modalità.

Questa pipeline è composta da due fasi distinte. La prima fase si concentra sull'estrazione delle immagini dai dati di origine e sulla loro conversione in formato base64. La seconda fase prevede la generazione di un prompt utilizzando tecniche avanzate di prompt engineering, che viene poi inserito nel Large Language Model (LLM). La rappresentazione visiva di questo processo è divisa in due parti, come mostrato nell'immagine sopra.
Estrai l'immagine dalla fonte
- Aggiungi lo Snap File Reader: trascina e rilascia lo Snap "File Reader" sul designer.
- Configurare lo Snap File Reader: Clicca sullo Snap "File Reader" per accedere al pannello delle impostazioni. Quindi, seleziona un file che contiene immagini. In questo caso, selezioniamo un file pdf.
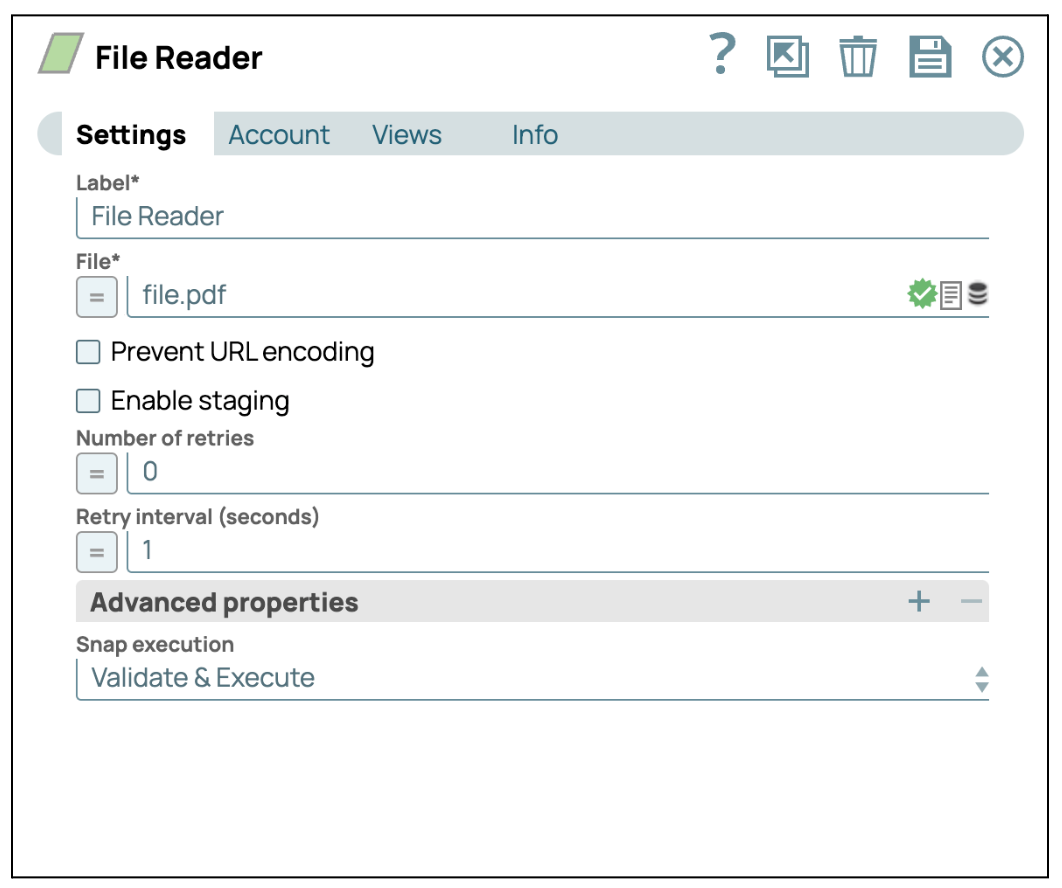
- Aggiungi lo Snap PDF Parser: Trascinare e rilasciare lo Snap "PDF Parser" sul designer e impostare il tipo di parser su "Convertitore da pagine a immagini".
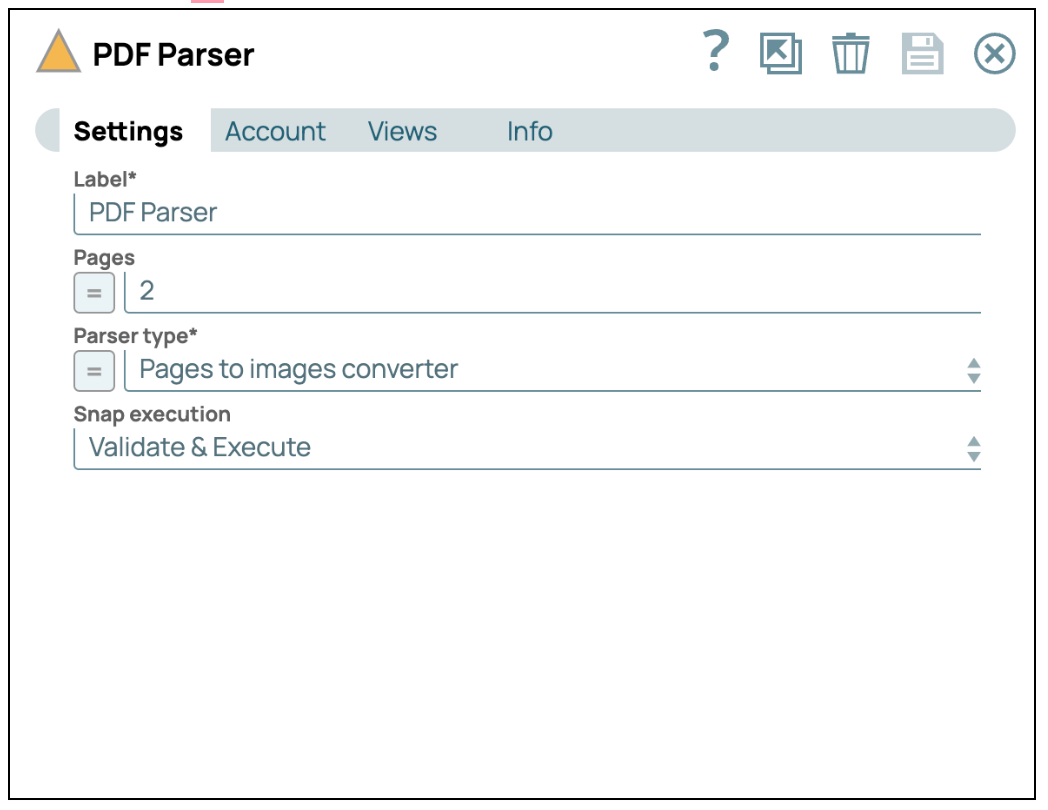
- Configura le visualizzazioni: Clicca sulla scheda "Visualizzazioni" e seleziona l'output "Binario".
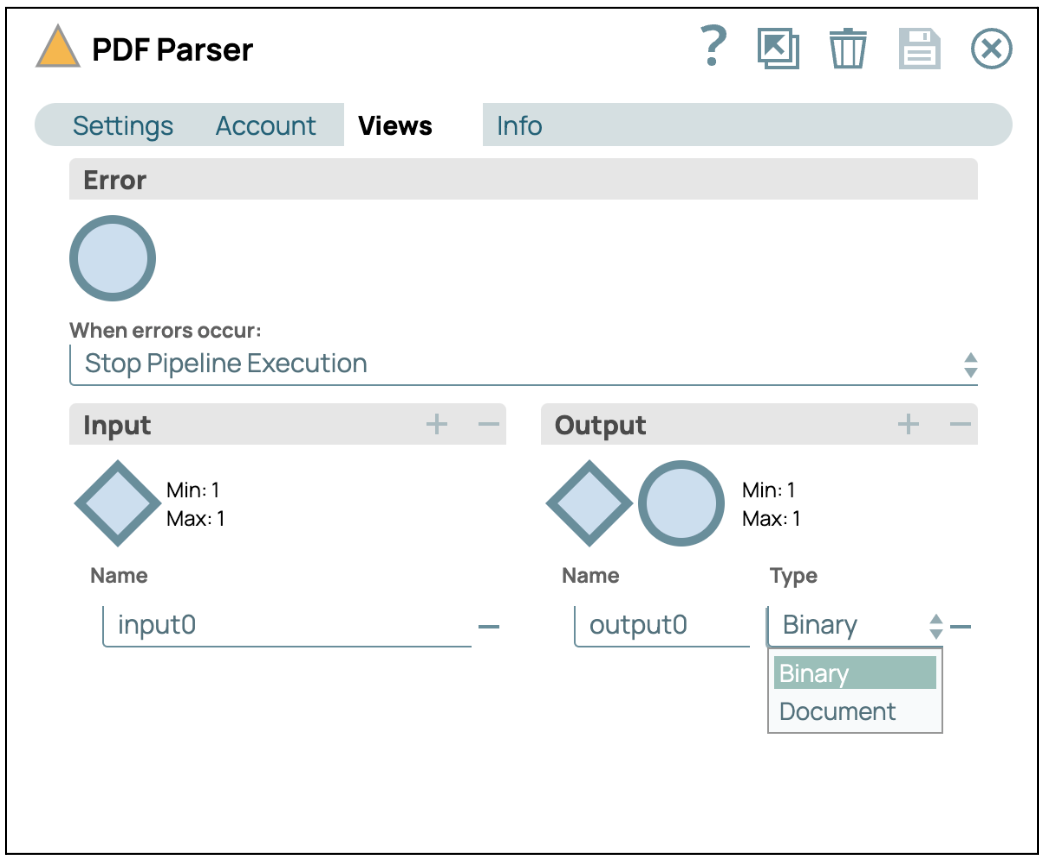
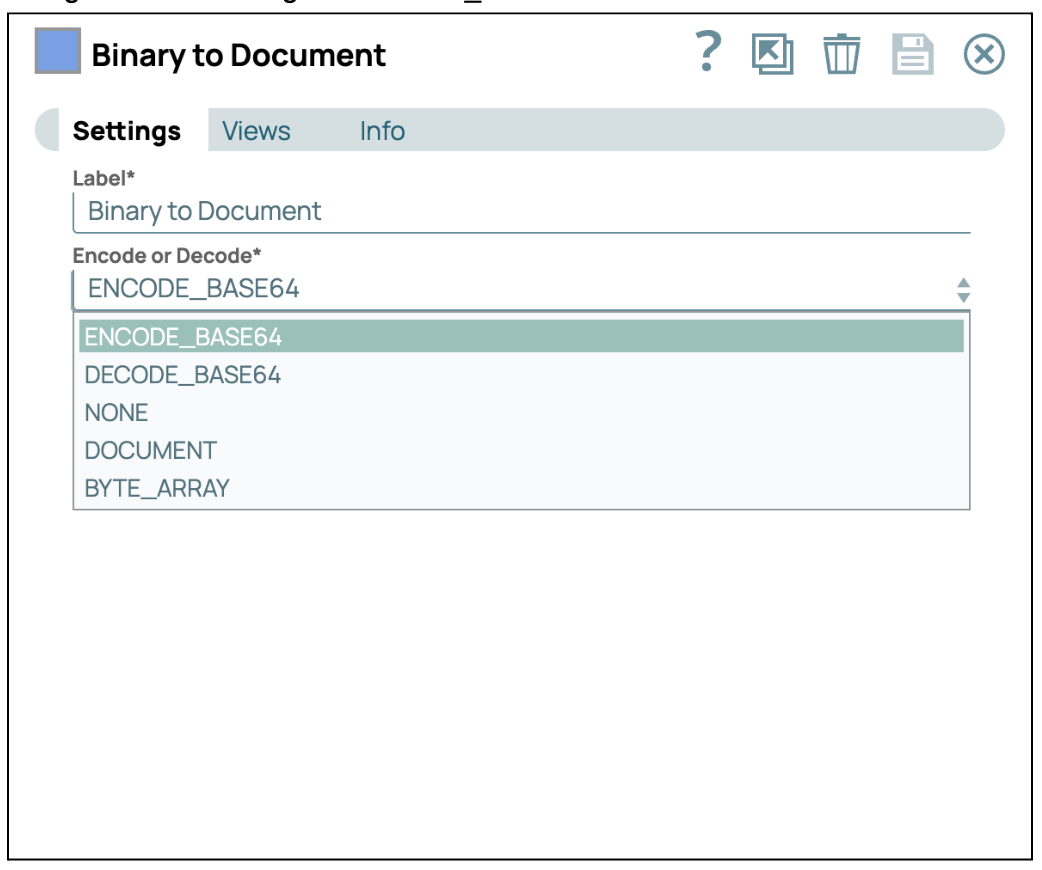
- Converti in Base64: Aggiungi e collega lo snap "Binary to Document" allo snap PDF Parser. Quindi, configura la codifica su ENCODE_BASE64.
Costruisci il prompt e invialo al GenAI
- Aggiungi uno Snap Generatore JSON: Trascinare lo Snap JSON Generator e collegarlo allo Snap Mapper precedente. Quindi, fare clic su "Modifica JSON" per modificare la stringa JSON nella modalità editor JSON. AWS Claude on Message consente di inviare immagini tramite il prompt configurando l'attributo sorgente all'interno del contenuto. È possibile costruire il prompt dell'immagine come mostrato nella schermata.

- Fornire istruzioni con Prompt Generator: Aggiungi lo Snap generatore di prompt e collegalo allo Snap generatore JSON. Quindi, seleziona la casella di controllo "Output prompt avanzato" per abilitare il payload avanzato del prompt. Infine, fai clic su "Modifica prompt" per inserire le tue istruzioni specifiche.
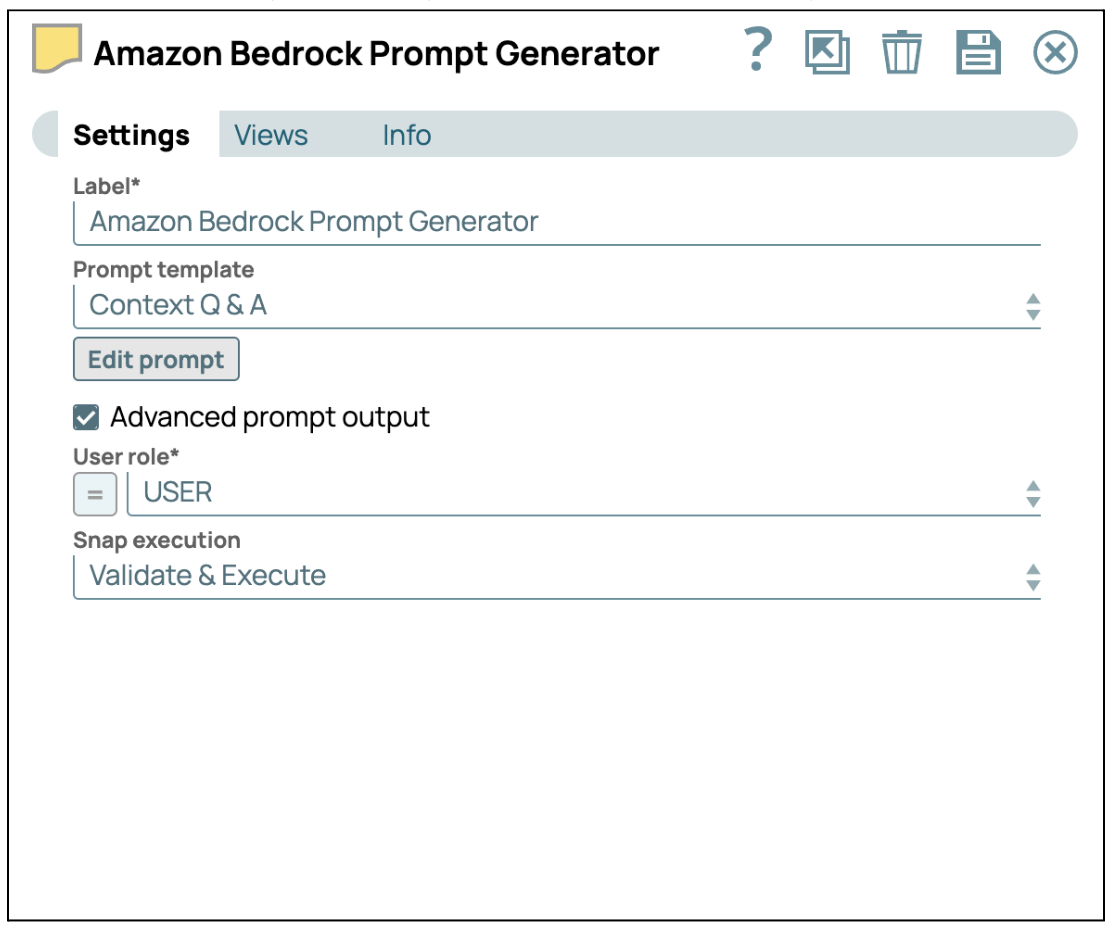
L'output avanzato del prompt sarà strutturato come un array di messaggi, come illustrato nella schermata sottostante.
- Invia a GenAI: Aggiungi AWS Claude su AWS Message Snap e inserisci le tue credenziali per accedere al servizio AWS Bedrock. Assicurati che la casella di controllo "Use Message Payload" sia selezionata, quindi configura il payload del messaggio utilizzando $messages, che è l'output dello Snap precedente.
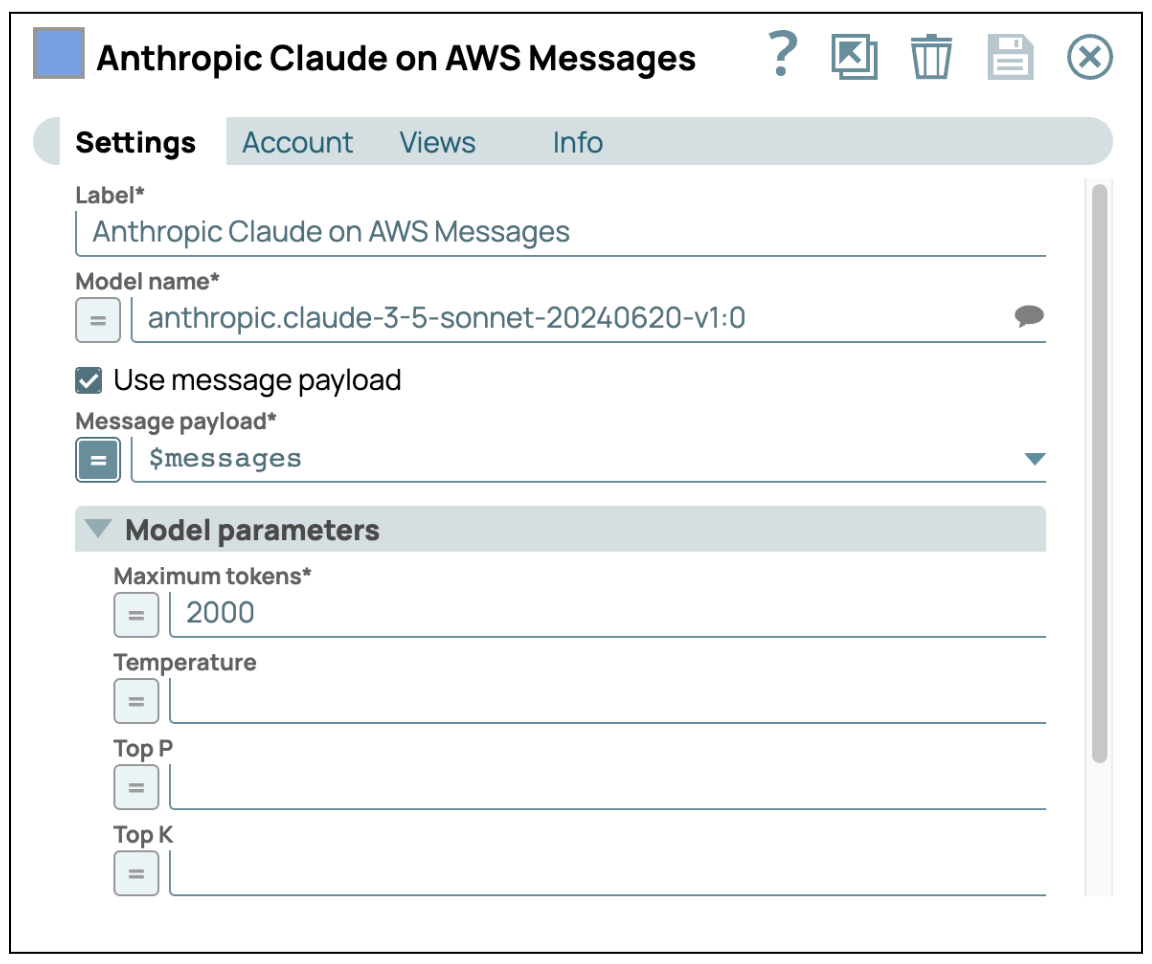
Dopo aver completato questi passaggi, è possibile elaborare l'immagine utilizzando il LLM in modo indipendente. Questo approccio consente al LLM di concentrarsi sull'estrazione di informazioni dettagliate dall'immagine. Una volta elaborata l'immagine, è possibile combinare questi dati con altre fonti, come testo o dati strutturati, per generare un'analisi più completa e accurata. Questa integrazione multimodale garantisce che le informazioni derivanti da diversi tipi di dati siano sintetizzate in modo efficace, portando a risultati più ricchi e precisi.
3. Caching semantico
Per ottimizzare sia i costi che i tempi di risposta associati all'utilizzo dei modelli linguistici di grandi dimensioni (LLM), l'implementazione di un meccanismo di caching semantico rappresenta una strategia altamente efficace. Il caching semantico consiste nel memorizzare le risposte generate dal modello e riutilizzarle quando il sistema incontra query con significati identici o simili. Questo approccio non solo migliora l'efficienza complessiva del sistema, ma riduce anche in modo significativo i costi operativi legati all'utilizzo del modello.
Il principio fondamentale alla base del caching semantico è che molte query degli utenti sono spesso semanticamente simili, anche se formulate in modo diverso. Identificando e memorizzando nella cache le risposte a queste query semanticamente equivalenti, il sistema può evitare la necessità di richiamare ripetutamente l'LLM, che richiede molte risorse. Il sistema può invece recuperare e restituire rapidamente la risposta memorizzata nella cache, garantendo tempi di risposta più rapidi e un'esperienza utente più fluida.
Dal punto di vista dei costi, il caching semantico si traduce direttamente in un risparmio. Ogni volta che il sistema fornisce una risposta dalla cache invece di interrogare l'LLM, evita il costo computazionale associato alla generazione di una nuova risposta. Questa riduzione del numero di invocazioni LLM è direttamente correlata a costi di servizio inferiori, rendendo la soluzione più economicamente vantaggiosa, in particolare in ambienti con volumi di query elevati.
Inoltre, la cache semantica contribuisce alla scalabilità del sistema. Con l'aumentare della domanda sull'LLM, il meccanismo di cache aiuta a gestire il carico in modo più efficace, garantendo che i tempi di risposta rimangano costanti anche quando il sistema viene scalato. Ciò è fondamentale per mantenere la qualità del servizio, soprattutto nelle applicazioni in tempo reale in cui la latenza è un fattore critico.
L'implementazione del caching semantico come parte della strategia di distribuzione LLM offre un duplice vantaggio: ottimizzazione dei tempi di risposta per gli utenti finali e riduzione al minimo dei costi operativi legati all'utilizzo del modello. Questo approccio non solo migliora le prestazioni e la scalabilità dei sistemi basati sull'intelligenza artificiale, ma garantisce anche che rimangano convenienti e reattivi all'aumentare della domanda da parte degli utenti.
Concetto di implementazione per il caching semantico
Il caching semantico è un approccio strategico progettato per ottimizzare sia i tempi di risposta che l'efficienza computazionale nei sistemi basati sull'intelligenza artificiale. L'implementazione del caching semantico prevede i seguenti passaggi chiave:
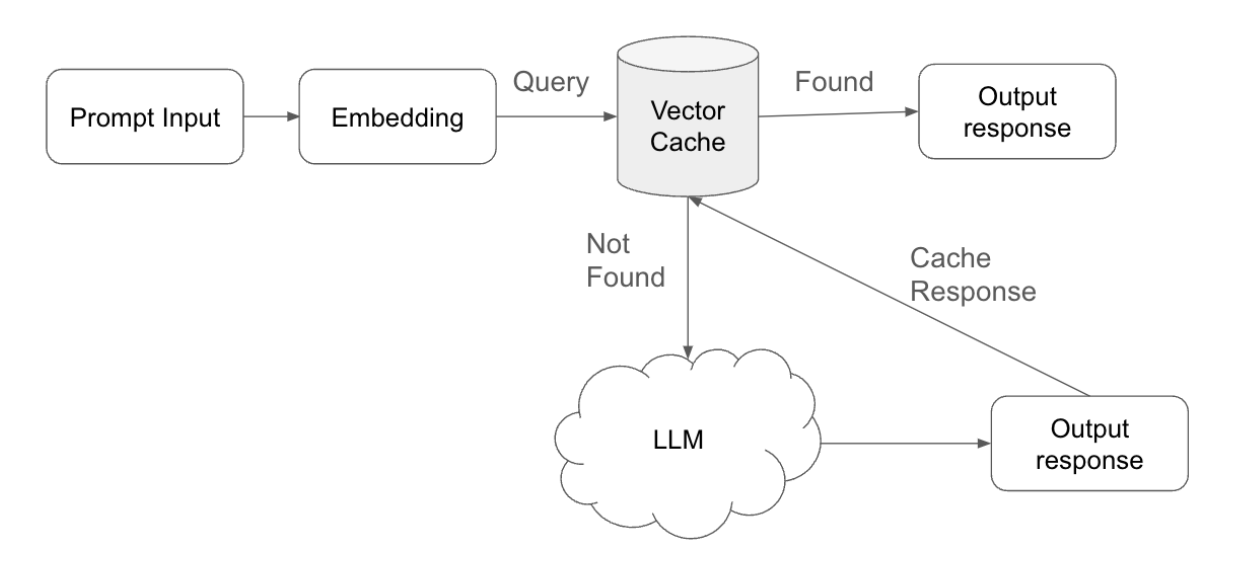
- Invio della query e vettorizzazione: quando un utente invia una query, il sistema elabora innanzitutto questo input convertendolo in un embedding, ovvero una rappresentazione vettorizzata della query. Questo embedding cattura il significato semantico della query, consentendo un confronto efficiente con i dati precedentemente memorizzati.
- Ricerca nella cache e corrispondenzaIl sistema esegue quindi una ricerca nella cache vettoriale, che contiene gli embedding delle query precedenti insieme alle relative risposte. Durante questa ricerca, il sistema cerca un embedding esistente che corrisponda il più possibile all'embedding della nuova query.
- Soglia di corrispondenza: una componente fondamentale di questo processo è la soglia di corrispondenza, che può essere regolata per controllare la sensibilità dell'algoritmo di corrispondenza. Questa soglia determina quanto la nuova query debba allinearsi con un embedding memorizzato affinché la cache la consideri una corrispondenza.
- Cache Hit e recupero della risposta: se il sistema identifica una corrispondenza entro la soglia definita, recupera la risposta corrispondente dalla cache. Questo "cache hit" consente al sistema di fornire rapidamente la risposta all'utente, evitando la necessità di ulteriori elaborazioni. Fornendo le risposte direttamente dalla cache, il sistema conserva le risorse computazionali e riduce i tempi di risposta.
- Cache Miss ed elaborazione LLM: nei casi in cui non viene trovata alcuna corrispondenza adeguata nella cache (un "cache miss"), il sistema inoltra la query al Large Language Model (LLM). L'LLM elabora la query e genera una nuova risposta, garantendo che l'utente riceva una risposta pertinente e accurata anche per query nuove.
- Gestione della memoria di risposta e della cache: Dopo che l'LLM ha generato una nuova risposta, il sistema non solo la invia all'utente, ma la memorizza anche insieme alla query associata nella cache vettoriale. Questo passaggio garantisce che, se in futuro verrà inviata una query simile, il sistema potrà fornire la risposta direttamente dalla cache, ottimizzando ulteriormente l'efficienza del sistema.
- Regolazione del Time-to-Live (TTL): per mantenere la pertinenza e l'accuratezza delle risposte memorizzate nella cache, il sistema può regolare il Time-to-Live (TTL) per ogni voce nella cache. Il TTL determina per quanto tempo una risposta rimane valida nella cache prima di essere considerata obsoleta e rimossa automaticamente. Ottimizzando le impostazioni TTL, il sistema garantisce che vengano fornite solo risposte aggiornate e contestualmente appropriate, impedendo così l'uso di dati obsoleti o irrilevanti.
Implementare il caching semantico in SnapLogic
Il concetto di cache semantica può essere implementato efficacemente all'interno di SnapLogic, sfruttando le sue solide funzionalità di pipeline. Di seguito è riportata una descrizione di come è possibile realizzare tale implementazione:

- Incorporamento della query: il processo inizia con l'incorporamento della query dell'utente (prompt). Utilizzando le funzionalità di SnapLogic, viene impiegato un incorporatore, come Amazon Titan Embedder, per convertire il prompt in una rappresentazione vettorializzata. Questo incorporamento cattura il significato semantico del prompt, rendendolo adatto al confronto con incorporamenti precedentemente memorizzati.
- Ricerca nella cache vettoriale: una volta incorporato il prompt, il sistema procede alla ricerca di una voce corrispondente nella cache vettoriale. In questa implementazione, il database vettoriale Snowflake funge da cache vettoriale, memorizzando gli embedding delle query passate insieme alle relative risposte. Questa ricerca è fondamentale per determinare se una query simile è già stata elaborata in precedenza.
- Instradamento del flusso con Router SnapDopo la ricerca, il sistema utilizza un Router Snap per gestire il flusso in base al fatto che sia stata trovata una corrispondenza (cache hit) o meno (cache miss). Il Router Snap indirizza il flusso di lavoro come segue:
- Cache Hit: se nella cache vettoriale viene trovato un embedding corrispondente, Router Snap instrada il processo in modo da restituire immediatamente all'utente la risposta memorizzata nella cache. Ciò garantisce tempi di risposta rapidi evitando elaborazioni inutili.
- Cache Miss: se non viene trovata alcuna corrispondenza, Router Snap indirizza il flusso di lavoro a richiedere una nuova risposta dal Large Language Model (LLM). L'LLM elabora il prompt e genera una nuova risposta pertinente.
- Memorizzazione e risposta: in caso di cache miss, dopo che l'LLM ha generato una nuova risposta, il sistema non solo invia questa risposta all'utente, ma memorizza anche il nuovo embedding e la risposta nel database vettoriale Snowflake per un utilizzo futuro. Questo passaggio migliora l'efficienza delle query successive, poiché prompt simili possono essere gestiti direttamente dalla cache.
4. Agenti AI multiplexing
Il multiplexing degli agenti AI si riferisce a una strategia in cui più modelli di IA generativa, ciascuno specializzato in un compito specifico, vengono utilizzati in parallelo per rispondere a query complesse. Questo approccio è simile alla costituzione di un gruppo di esperti, in cui ciascun agente contribuisce con la propria competenza per fornire una soluzione completa. Ecco la caratteristica principale dell'utilizzo del multiplexing degli agenti AI.
- Specializzazione: uno dei principali vantaggi del multiplexing degli agenti AI è la specializzazione di ciascun agente nella gestione di compiti o ambiti specifici. Il multiplexing garantisce risposte più pertinenti e accurate assegnando ciascun modello di IA a una particolare area di competenza. Ad esempio, un agente potrebbe essere ottimizzato per la comprensione del linguaggio naturale, un altro per la risoluzione di problemi tecnici e un terzo per la sintesi di dati complessi. Ciò consente al sistema di gestire efficacemente query multidimensionali, poiché ciascun agente si concentra su ciò che sa fare meglio. Questa specializzazione riduce significativamente la probabilità di errori o risposte irrilevanti, poiché gli agenti IA sono adattati ai loro compiti specifici.
In scenari in cui una query abbraccia più domini, come ad esempio una domanda tecnica con un aspetto commerciale, il sistema può indirizzare le diverse parti della query all'agente appropriato. Questo approccio strutturato consente di estrarre informazioni più pertinenti e accurate, portando a una soluzione che affronta tutti gli aspetti del problema. - Elaborazione parallela: gli agenti AI multiplexing sfruttano appieno le capacità di elaborazione parallela. Eseguendo più agenti contemporaneamente, il sistema è in grado di affrontare diversi aspetti di una query allo stesso tempo, accelerando i tempi di risposta complessivi. Questo approccio parallelo migliora sia le prestazioni che la scalabilità, poiché il carico di lavoro viene distribuito tra più agenti invece di affidarsi a un unico modello per elaborare l'intero compito.
Ad esempio, in un'applicazione di assistenza clienti, un agente potrebbe gestire l'analisi delle precedenti interazioni di un cliente, mentre un altro agente genera una risposta a un problema tecnico e un altro ancora crea un piano d'azione di follow-up. Ogni agente lavora in parallelo al proprio compito e il sistema integra i risultati in una risposta coerente. Questo metodo non solo accelera la risoluzione dei problemi, ma garantisce anche che le diverse dimensioni del problema vengano affrontate contemporaneamente. - Assegnazione dinamica dei compiti: in un sistema multiplexing, l'assegnazione dinamica dei compiti è fondamentale per distribuire in modo efficiente i compiti tra gli agenti specializzati. Un modello più grande e generico, come AWS Claude 3 Sonet, può fungere da orchestratore, valutando il contesto della query e determinando quali parti del compito devono essere delegate ad agenti più piccoli e specializzati. L'orchestratore garantisce che ogni compito sia assegnato al modello più adatto a gestirlo.
Ad esempio, se un utente invia una query complessa sulle normative legali e la sicurezza dei dati, il modello generale può suddividere la query, inviando le domande relative agli aspetti legali a un agente AI specializzato nell'analisi legale e quelle relative alla sicurezza a un agente incentrato sulla sicurezza come TinyLlama o un modello simile. Questa delega dinamica consente di utilizzare i modelli più pertinenti al momento giusto, migliorando sia l'efficienza che l'accuratezza della risposta complessiva. - Integrazione dei risultati: una volta che gli agenti specializzati hanno elaborato i rispettivi compiti, il sistema deve integrare i loro risultati per formare una risposta coerente e completa. Questa integrazione è una caratteristica fondamentale del multiplexing, poiché garantisce che tutti gli aspetti di una query siano affrontati senza sovrapposizioni o contraddizioni. Il sistema combina le intuizioni generate da ciascun agente, creando un output finale che riflette l'intero ambito della richiesta dell'utente.
In molti casi, il processo di integrazione include anche il filtraggio o il perfezionamento degli output per rimuovere eventuali incongruenze o ridondanze, garantendo che la risposta sia logica e coerente. Questo approccio collaborativo aumenta l'affidabilità del sistema, poiché consente a diversi agenti di integrare le reciproche conoscenze e competenze.
Inoltre, il multiplexing riduce la probabilità di allucinazioni, ovvero output errati o privi di senso che a volte possono verificarsi con modelli singoli su larga scala. Dividendo i compiti tra agenti specializzati, il sistema garantisce che ogni parte del problema sia gestita da un'IA specificamente addestrata per quel dominio, riducendo al minimo la possibilità di risposte errate o fuori contesto. - Maggiore accuratezza e comprensione contestuale: Gli agenti AI multiplexing contribuiscono a migliorare l'accuratezza complessiva distribuendo i compiti a modelli più accuratamente calibrati su contesti o argomenti specifici. Questo approccio garantisce che il sistema AI sia in grado di comprendere e affrontare meglio le sfumature di una query, in particolare quando l'input riguarda informazioni complesse o altamente specializzate. La profonda concentrazione di ciascun agente su un compito specifico porta a un livello di precisione più elevato, con un risultato finale più accurato.
Inoltre, il multiplexing consente al sistema di costruire una comprensione contestuale più dettagliata. Poiché diversi agenti sono responsabili di diversi elementi di un'attività, il sistema può sintetizzare risposte più dettagliate e sensibili al contesto. Questa visione olistica è fondamentale per garantire che la soluzione fornita non solo sia accurata, ma anche pertinente alla situazione specifica presentata dall'utente.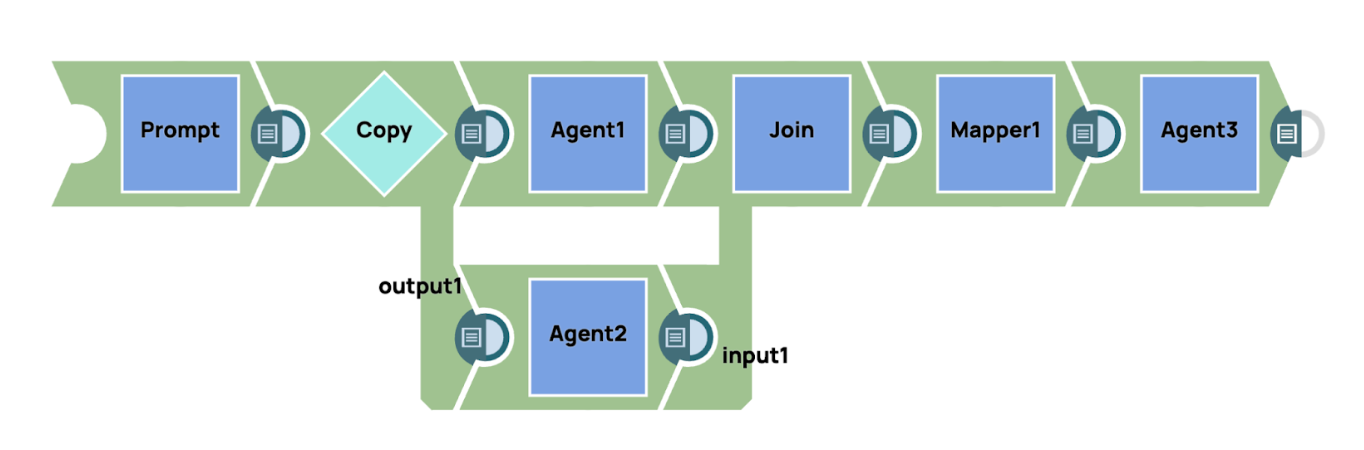
In SnapLogic, offriamo un supporto completo per la creazione di flussi di lavoro avanzati integrando il nostro GenAI Builder Snap. Questa funzione consente agli utenti di incorporare senza soluzione di continuità le capacità generative dell'IA nei loro processi di automazione del flusso di lavoro. Sfruttando il GenAI Builder Snap, gli utenti possono sfruttare la potenza dell'intelligenza artificiale per automatizzare complesse attività di decisione, elaborazione dei dati e generazione di contenuti all'interno dei loro flussi di lavoro esistenti. Questa integrazione fornisce un approccio semplificato per incorporare funzionalità basate sull'IA, migliorando sia l'efficienza che la precisione in vari ambiti operativi. Ad esempio, gli utenti possono progettare flussi di lavoro in cui GenAI Builder Snap collabora con altri componenti SnapLogic, come pipeline di dati e processi di trasformazione, per fornire un'automazione intelligente e sensibile al contesto, su misura per le loro esigenze aziendali specifiche.
Nelle pipeline di esempio, il sistema invia un prompt simultaneamente a più agenti AI, ciascuno con la propria area di competenza specialistica. Questi agenti elaborano in modo indipendente gli aspetti specifici del prompt relativi alla loro specializzazione. Una volta che gli agenti generano i rispettivi output, i risultati vengono uniti per formare una risposta coerente. Per migliorare ulteriormente la chiarezza e la concisione dell'output finale, viene impiegato un agente di sintesi. Questo agente di sintesi aggrega e perfeziona le risposte dettagliate di ciascun agente specializzato, distillando le informazioni in un riassunto conciso e unificato che cattura i punti chiave di tutti gli agenti, garantendo una risposta finale coerente e ben strutturata.
5. Conversazione multi-agente
La conversazione multi-agente si riferisce all'interazione e alla comunicazione tra più agenti autonomi, in genere sistemi di intelligenza artificiale, che collaborano per raggiungere un obiettivo comune. Questo framework è ampiamente utilizzato in settori quali la risoluzione collaborativa dei problemi, i sistemi multiutente e il coordinamento di attività complesse che richiedono molteplici prospettive o aree di competenza. A differenza di una conversazione a agente singolo, in cui un'unica IA gestisce tutti gli input e gli output, un sistema multi-agente divide i compiti tra diversi agenti specializzati, consentendo una maggiore efficienza, una comprensione contestuale più approfondita e migliori capacità di risoluzione dei problemi. Ecco le caratteristiche principali dell'utilizzo delle conversazioni multi-agente.
- Specializzazione e competenza: ogni agente in un sistema multi-agente è progettato con un ruolo specifico o un ambito di competenza. Ciò consente al sistema di sfruttare agenti con capacità specializzate per gestire diversi aspetti di un'attività. Ad esempio, un agente potrebbe concentrarsi sull'elaborazione del linguaggio naturale (NLP) per comprendere gli input, mentre un altro potrebbe gestire calcoli complessi o recuperare dati da fonti esterne. Questa divisione del lavoro garantisce che le attività siano elaborate dagli agenti più capaci, portando a risultati più accurati ed efficienti. La specializzazione riduce la probabilità di errori e consente una comprensione più approfondita e specifica del problema.
- Collaborazione e coordinamento: in una conversazione multi-agente, gli agenti non lavorano in modo isolato, ma collaborano per raggiungere un obiettivo comune. Ogni agente contribuisce con il proprio output alla conversazione più ampia, condividendo informazioni e coordinando le azioni per garantire che l'attività complessiva venga completata con successo. Questa collaborazione è fondamentale quando si affrontano problemi complessi che richiedono input da più domini. Un coordinamento efficace garantisce che gli agenti non duplicino il lavoro o causino conflitti. Attraverso protocolli predefiniti o meccanismi di negoziazione, gli agenti sono in grado di lavorare insieme in modo armonioso, producendo una soluzione coerente che integra i loro vari contributi.
- Scalabilità: i sistemi multi-agente sono intrinsecamente scalabili, il che li rende ideali per gestire compiti sempre più complessi. Man mano che il sistema diventa più complesso o incontra nuove sfide, è possibile introdurre agenti aggiuntivi con competenze specifiche senza sovraccaricare il sistema. Ogni agente può lavorare in modo indipendente e il design modulare del sistema consente un'espansione fluida. La scalabilità garantisce che il sistema sia in grado di gestire set di dati più grandi, input più diversificati o compiti più complessi man mano che l'ambiente evolve. Questa adattabilità è essenziale in ambienti dinamici in cui i carichi di lavoro o i requisiti cambiano nel tempo.
- Processo decisionale distribuito: in un sistema multi-agente, il processo decisionale è spesso decentralizzato, il che significa che ogni agente ha l'autonomia di prendere decisioni in base alla propria esperienza e alle informazioni a sua disposizione. Questo processo decisionale distribuito consente agli agenti di gestire le attività in parallelo, senza bisogno di una supervisione costante da parte di un controllore centrale. Poiché gli agenti possono operare in modo indipendente, le decisioni vengono prese più rapidamente e si evitano i colli di bottiglia. Questo approccio decentralizzato migliora anche la resilienza del sistema, poiché evita un eccessivo affidamento su un unico punto decisionale e consente una risoluzione dei problemi più adattiva e localizzata.
- Tolleranza ai guasti e ridondanza: i sistemi multi-agente sono naturalmente resistenti agli errori e ai guasti. Poiché ogni agente opera in modo indipendente, il guasto di un agente non compromette l'intero sistema. Gli altri agenti possono continuare a svolgere i propri compiti o, se necessario, assumere il lavoro dell'agente guasto. Questa ridondanza integrata garantisce che il sistema possa continuare a funzionare anche quando alcuni agenti incontrano problemi. La tolleranza ai guasti è particolarmente preziosa nei sistemi complessi, poiché migliora l'affidabilità e riduce al minimo i tempi di inattività, consentendo al sistema di mantenere le prestazioni anche in condizioni avverse.
SnapLogic offre solide funzionalità per l'integrazione dell'automazione del flusso di lavoro con l'intelligenza artificiale generativa (GenAI), consentendo agli utenti di creare senza soluzione di continuità sistemi avanzati di conversazione multi-agente combinando lo Snap GenAI con altri Snap all'interno della loro pipeline. Questa integrazione consente agli utenti di creare flussi di lavoro sofisticati in cui più agenti AI, ciascuno con la propria specializzazione, collaborano per elaborare query e attività complesse.
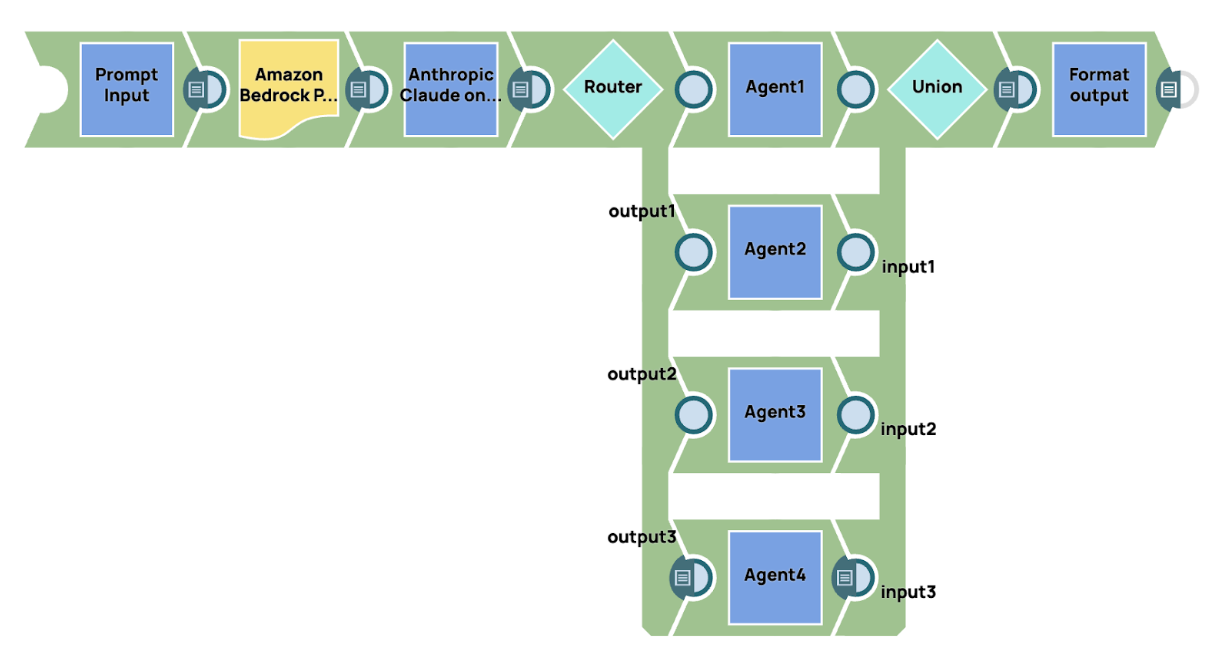
In questo esempio, mostriamo una semplice implementazione di un sistema di conversazione multi-agente, sfruttando un agente manager per supervisionare e controllare il flusso di lavoro. Il processo inizia con l'invio di un prompt a un grande modello di base, che in questo caso è AWS Claude 3 Sonet. Questo modello funge da agente manager responsabile dell'interpretazione del prompt e della determinazione dell'instradamento appropriato per le diverse parti dell'attività. In base al contenuto e al contesto del prompt, l'agente manager decide come distribuire il carico di lavoro tra gli agenti specializzati.
Dopo l'elaborazione del prompt iniziale, utilizziamo Router Snap per indirizzare dinamicamente l'output agli agenti specializzati corrispondenti. Ogni agente è personalizzato per gestire un dominio o un'attività specifica, come l'analisi dei dati, l'elaborazione del linguaggio naturale o il recupero delle conoscenze, garantendo che l'agente più pertinente e specializzato si occupi di ogni parte della query.
Una volta che gli agenti specializzati hanno completato i rispettivi compiti, i loro risultati vengono raccolti e consolidati. Il sistema invia quindi il risultato finale aggregato alla destinazione di output. Questo approccio garantisce che tutti gli aspetti della query siano affrontati in modo efficiente e accurato, con ogni agente che contribuisce con la propria esperienza alla soluzione complessiva.
La flessibilità della piattaforma SnapLogic, combinata con l'integrazione dei modelli GenAI e Snaps, consente agli utenti di progettare, scalare e ottimizzare facilmente flussi di lavoro conversazionali multi-agente complessi. Automatizzando l'instradamento delle attività e la collaborazione tra agenti, SnapLogic offre soluzioni più intelligenti, scalabili e sensibili al contesto per affrontare un'ampia gamma di casi d'uso, dall'automazione del servizio clienti all'elaborazione avanzata dei dati.
6. Generazione di recupero aumentato (RAG)
Per migliorare la specificità e la pertinenza delle risposte generate da un modello di IA generativa (GenAI), è fondamentale fornire al modello un contesto sufficiente. Le informazioni contestuali aiutano il modello a comprendere le sfumature del compito da svolgere, consentendogli di generare risultati più accurati e significativi. Tuttavia, in molti casi, la quantità di contesto necessaria per informare completamente il modello supera il limite di token che il modello può elaborare in un singolo prompt. È qui che una tecnica nota come Retrieval-Augmented Generation (RAG) diventa particolarmente preziosa.
RAG è progettato per ottimizzare il modo in cui il contesto viene inserito nel modello GenAI. Anziché cercare di inserire tutte le informazioni necessarie nello spazio di input limitato, RAG utilizza un meccanismo di recupero che attinge dinamicamente le informazioni rilevanti da una base di conoscenza esterna. Questo approccio consente agli utenti di superare la sfida del limite dei token recuperando solo le informazioni più pertinenti al momento della generazione della query, garantendo che il contesto fornito al modello rimanga mirato e conciso.
Il quadro RAG può essere suddiviso in due fasi principali:
- Incorporare la conoscenza in un database vettoriale: Nella fase iniziale, il contenuto pertinente viene incorporato in uno spazio vettoriale utilizzando un modello di apprendimento automatico che trasforma i dati testuali in un formato che favorisce la corrispondenza di similarità. Questo processo di incorporazione converte efficacemente il testo in vettori, rendendo più facile la memorizzazione e il recupero successivo in base al suo significato semantico. Una volta incorporata, la conoscenza viene memorizzata in un database vettoriale per un accesso futuro.
 In SnapLogic, l'integrazione delle conoscenze in un database vettoriale può essere realizzata attraverso una pipeline semplificata progettata per garantire efficienza e scalabilità. Il processo inizia con la lettura di un file PDF utilizzando il Lettore di file Snap, seguito dall'estrazione del contenuto con il comando Analizzatore PDF Snap, che converte il documento in un formato di testo strutturato. Una volta che il testo è disponibile, il Chunker Snap viene utilizzato per segmentare in modo intelligente il contenuto in blocchi più piccoli e gestibili. Questi blocchi sono dimensionati in modo specifico per allinearsi con i vincoli di input del modello, garantendo prestazioni ottimali durante le fasi successive del recupero.
In SnapLogic, l'integrazione delle conoscenze in un database vettoriale può essere realizzata attraverso una pipeline semplificata progettata per garantire efficienza e scalabilità. Il processo inizia con la lettura di un file PDF utilizzando il Lettore di file Snap, seguito dall'estrazione del contenuto con il comando Analizzatore PDF Snap, che converte il documento in un formato di testo strutturato. Una volta che il testo è disponibile, il Chunker Snap viene utilizzato per segmentare in modo intelligente il contenuto in blocchi più piccoli e gestibili. Questi blocchi sono dimensionati in modo specifico per allinearsi con i vincoli di input del modello, garantendo prestazioni ottimali durante le fasi successive del recupero.
Dopo aver suddiviso il testo in segmenti, ciascuno di essi viene elaborato e incorporato in una rappresentazione vettoriale, che viene poi memorizzata nel database vettoriale. Ciò consente un efficiente recupero basato sulla similarità, permettendo al sistema di accedere rapidamente alle informazioni rilevanti secondo necessità. Utilizzando questa pipeline in SnapLogic, gli utenti possono facilmente gestire e memorizzare grandi volumi di conoscenze in modo da supportare applicazioni AI ad alte prestazioni e basate sul contesto. - Recupero del contesto tramite corrispondenza di similarità: Quando viene ricevuta una query, il sistema esegue una corrispondenza di similarità per recuperare il contenuto più pertinente dal database vettoriale. Valutando la similarità tra la query incorporata e i vettori memorizzati, RAG identifica le informazioni più pertinenti, che vengono poi utilizzate per arricchire il prompt di input. Questo passaggio garantisce che il modello GenAI riceva dati mirati e contestualmente arricchiti, consentendogli di generare risposte più approfondite e accurate.

Per recuperare il contesto pertinente dal database vettoriale in SnapLogic, gli utenti possono sfruttare un incastro dell'embedder, come il AWS Titan Embedder, per trasformare il prompt in entrata in una rappresentazione vettoriale. Questo vettore funge da chiave per eseguire una ricerca basata sulla somiglianza all'interno del database vettoriale in cui è memorizzata la conoscenza precedentemente incorporata. Il meccanismo di ricerca vettoriale identifica in modo efficiente le informazioni più rilevanti, garantendo che venga recuperato solo il contenuto più appropriato dal punto di vista contestuale.
Una volta recuperate le conoscenze pertinenti, queste possono essere integrate senza soluzione di continuità nel processo complessivo di generazione dei prompt. Ciò si ottiene in genere inserendo il contesto recuperato in un generatore di prompt snap, che struttura le informazioni in un formato ottimizzato per l'utilizzo da parte del modello Generative AI. In questo caso, il prompt finale, arricchito con il contesto pertinente, viene inviato al GenAI Snap, come ad esempio Claude di Anthropic all'interno del Messaggi AWS SnapQuesto approccio garantisce che il modello riceva informazioni altamente specifiche e pertinenti, migliorando in ultima analisi l'accuratezza e la pertinenza delle risposte generate.
Implementando il RAG, gli utenti possono sfruttare appieno il potenziale dei modelli GenAI, anche quando si tratta di query complesse che richiedono una quantità significativa di contesto. Questo approccio non solo migliora l'accuratezza delle risposte del modello, ma garantisce anche che il modello rimanga efficiente e scalabile, rendendolo uno strumento potente per un'ampia gamma di applicazioni nel mondo reale.
7. Richiamo degli strumenti e istruzioni contestuali
I modelli GenAI tradizionali sono limitati dai dati su cui sono stati addestrati. Una volta addestrati, questi modelli non possono accedere a informazioni nuove o aggiornate a meno che non vengano riaddestrati. Questa limitazione significa che, senza input esterni, i modelli possono generare solo risposte basate sul contenuto statico all'interno del loro corpus di addestramento. Tuttavia, in un mondo in cui i dati sono in continua evoluzione, affidarsi a conoscenze statiche è spesso inadeguato, soprattutto per attività che richiedono informazioni aggiornate o in tempo reale. In molte applicazioni del mondo reale, i modelli di Generative AI (GenAI) necessitano di accedere a dati in tempo reale per generare risposte contestualmente accurate e pertinenti. Ad esempio, se un utente chiede il tempo attuale in una determinata località, il modello non può basarsi esclusivamente sulle conoscenze pre-addestrate, poiché questi dati sono dinamici e in costante evoluzione. In tali scenari, le tecniche tradizionali di prompt engineering sono insufficienti, poiché si basano principalmente su informazioni statiche disponibili al momento dell'addestramento del modello. È qui che la tecnica di tool-calling diventa preziosa.
Il tool calling si riferisce alla capacità di un modello GenAI di interagire con strumenti esterni, API o database per recuperare informazioni specifiche in tempo reale. Invece di fare affidamento sulle proprie conoscenze interne, che potrebbero essere obsolete o incomplete, il modello può richiedere dati aggiornati da fonti esterne e utilizzarli per generare una risposta accurata e contestualmente pertinente. Questo processo amplia notevolmente le capacità della GenAI, consentendole di andare oltre i contenuti statici e pre-addestrati e di incorporare nei propri risultati dati dinamici e reali.
Ad esempio, quando un utente richiede aggiornamenti meteo in tempo reale, quotazioni di borsa o condizioni del traffico, il modello GenAI può attivare una chiamata a un'API esterna, come un servizio meteo, un fornitore di dati finanziari o un servizio di mappatura, per recuperare i dati necessari. I dati recuperati vengono quindi integrati nella risposta del modello, consentendogli di fornire una risposta accurata e tempestiva che non sarebbe stata possibile utilizzando solo prompt statici.
L'istruzione contestuale svolge un ruolo fondamentale nel processo di richiamo degli strumenti. Prima di richiamare uno strumento esterno, il modello GenAI deve comprendere la natura della richiesta dell'utente e identificare quando sono necessari dati esterni. Ad esempio, se un utente chiede: "Com'è il tempo a Parigi in questo momento?", il modello riconosce che la domanda richiede informazioni meteorologiche in tempo reale e che non è possibile rispondere basandosi solo sulle conoscenze interne. Il modello è quindi programmato per attivare una chiamata allo strumento API del servizio meteorologico pertinente, recuperare i dati meteorologici in tempo reale per Parigi e incorporarli nella risposta finale. Questa capacità di comprendere e distinguere tra conoscenze statiche (a cui è possibile rispondere con dati pre-addestrati) e informazioni dinamiche in tempo reale (che richiedono la chiamata di strumenti esterni) è essenziale affinché i modelli GenAI funzionino in modo efficace in ambienti complessi e reali.
Casi d'uso per la chiamata di strumenti
- Recupero dati in tempo reale: i modelli GenAI possono richiamare API esterne per recuperare dati in tempo reale quali condizioni meteorologiche, quotazioni di borsa, aggiornamenti sulle notizie o risultati sportivi in diretta. Queste chiamate agli strumenti garantiscono che l'IA fornisca risposte aggiornate e accurate che riflettono le informazioni più recenti.
- Calcoli complessi e attività specializzate: il richiamo di strumenti consente ai modelli di IA di gestire attività che richiedono calcoli specifici o competenze specifiche nel settore. Ad esempio, un modello di IA che gestisce una query finanziaria può richiamare uno strumento di analisi finanziaria esterno per eseguire calcoli complessi o recuperare dati storici relativi al mercato azionario.
- Integrazione con i sistemi aziendali: negli ambienti aziendali, i modelli GenAI possono interagire con sistemi esterni quali piattaforme CRM, sistemi ERP o database per recuperare o aggiornare informazioni in tempo reale. Ad esempio, un bot di assistenza clienti basato su GenAI può estrarre informazioni sull'account da un sistema CRM o verificare lo stato degli ordini da uno strumento esterno di gestione degli ordini.
- Accesso a conoscenze specialistiche: il tool calling consente ai modelli di IA di recuperare informazioni specialistiche da database o archivi di conoscenze che esulano dal loro ambito di formazione. Ad esempio, un assistente medico basato sull'IA potrebbe richiamare un database esterno di articoli di ricerca medica per fornire le opzioni terapeutiche più aggiornate per una particolare patologia.
Implementazione della chiamata di strumenti nei sistemi di IA generativa
La chiamata di strumenti è diventata una caratteristica integrante di molti modelli avanzati di IA generativa (GenAI), consentendo loro di estendere le proprie funzionalità interagendo con sistemi e servizi esterni. Ad esempio, AWS Anthropic Claude supporta il richiamo di strumenti tramite l'API Message, fornendo agli sviluppatori un modo strutturato per integrare dati e funzionalità esterni direttamente nel flusso di lavoro di risposta del modello. Questa capacità consente al modello di migliorare le proprie risposte incorporando informazioni in tempo reale, eseguendo funzioni specifiche o utilizzando API esterne che forniscono dati specializzati oltre alla formazione del modello.
Per implementare la chiamata di strumenti con AWS Anthropic Claude, gli utenti possono sfruttare l'API Message, che consente una perfetta integrazione con sistemi esterni. Il meccanismo di chiamata dello strumento viene attivato inviando un messaggio con uno specifico parametro "tools". Questo parametro definisce come verrà chiamato lo strumento esterno o l'API, utilizzando uno schema JSON per strutturare la chiamata di funzione. Questo approccio consente al modello GenAI di riconoscere quando è necessario un input esterno e di avviare una chiamata dello strumento in base alle istruzioni fornite.
Processo di implementazione
- Definizione dello schema dello strumento: Per avviare una chiamata allo strumento, gli utenti devono inviare una richiesta con il "strumenti" parametro. Questo parametro è definito in uno schema JSON strutturato, che include dettagli sullo strumento esterno o sull'API che il modello GenAI chiamerà. Lo schema JSON delinea come lo strumento deve essere utilizzato, inclusi il nome della funzione, i parametri e tutti gli input necessari per effettuare la chiamata.

Ad esempio, se lo strumento è un'API meteorologica, lo schema potrebbe definire parametri quali la posizione e l'ora, consentendo al modello di interrogare l'API con questi input per recuperare i dati meteorologici attuali.
- Struttura del messaggio e avvio della richiesta: una volta definito lo schema dello strumento, l'utente può inviare un messaggio ad AWS Anthropic Claude contenente il parametro "tools" insieme al prompt o alla query. Il modello interpreterà quindi la richiesta e, in base al contesto della conversazione o dell'attività, determinerà se è necessario richiamare lo strumento esterno specificato nello schema. Se è necessario richiamare uno strumento, il modello risponderà con un valore "stop_reason" pari a "tool_use". Questa risposta indica che il modello sta mettendo in pausa la sua generazione per richiamare lo strumento esterno, anziché completare la risposta utilizzando solo le sue conoscenze interne.
- Esecuzione della chiamata allo strumento: quando il modello risponde con "stop_reason": "tool_use", segnala che l'API o la funzione esterna deve essere chiamata con gli input forniti. A questo punto, l'API esterna (come specificato nello schema JSON) viene attivata per recuperare i dati richiesti o eseguire l'attività designata. Ad esempio, se l'utente chiede "Che tempo fa a New York in questo momento?" e lo schema JSON definisce uno strumento API meteo, il modello si metterà in pausa e richiamerà l'API con il parametro di posizione impostato su "New York" e il parametro di tempo impostato su "attuale".
- Gestione della risposta API: dopo che lo strumento esterno ha elaborato la richiesta e restituito il risultato, l'utente (o il sistema) invia un messaggio di follow-up contenente il "tool_result". Questo messaggio include l'output della chiamata allo strumento, che può quindi essere integrato nella conversazione o nell'attività in corso. In pratica, potrebbe trattarsi di un'API meteo che restituisce un oggetto JSON con temperatura, umidità e condizioni meteorologiche. La risposta viene ritrasmessa al modello GenAI tramite un messaggio utente, che contiene i dati "tool_result".
- Generazione della risposta finale: una volta che il modello riceve il "tool_result", elabora i dati e completa la risposta. Ciò consente al modello GenAI di fornire una risposta finale che incorpora informazioni in tempo reale o specializzate recuperate dal sistema esterno. Nel nostro esempio meteorologico, la risposta finale potrebbe essere: "Il tempo attuale a New York è di 22 °C con cielo sereno".
Al momento, SnapLogic non offre ancora supporto nativo per la chiamata di strumenti all'interno del GenAI Snap Pack. Tuttavia, riconosciamo l'immenso potenziale e il valore che questa funzione può offrire agli utenti, consentendo una perfetta integrazione con sistemi e servizi esterni per dati in tempo reale e funzionalità avanzate. Stiamo lavorando attivamente per incorporare le funzionalità di chiamata degli strumenti nei futuri aggiornamenti della piattaforma. Questo miglioramento consentirà agli utenti di creare flussi di lavoro più dinamici e intelligenti, ampliando le possibilità di automazione e soluzioni basate sull'intelligenza artificiale. Siamo entusiasti del potenziale che racchiude e non vediamo l'ora di condividere presto queste innovazioni.
8. Cognizione della memoria per gli LLM
La maggior parte dei modelli linguistici di grandi dimensioni (LLM) opera entro i limiti di una finestra contestuale, il che significa che possono elaborare e analizzare solo un numero limitato di token (parole, frasi o simboli) in un dato momento. Questa limitazione pone sfide significative, in particolare quando si tratta di compiti complessi, dialoghi estesi o interazioni che richiedono una comprensione contestuale a lungo termine. Ad esempio, se una conversazione o un'attività supera il limite di token, il modello perde la consapevolezza delle parti precedenti dell'interazione, portando a risposte che possono diventare sconnesse, ripetitive o contestualmente irrilevanti.
Questa limitazione diventa particolarmente problematica nelle applicazioni in cui è fondamentale mantenere la continuità e la coerenza nel corso di interazioni prolungate. Negli scenari di assistenza clienti, negli strumenti di gestione dei progetti o nelle applicazioni didattiche, spesso è necessario ricordare informazioni dettagliate relative a scambi precedenti o monitorare i progressi nel tempo. Tuttavia, i modelli tradizionali vincolati da una finestra token fissa faticano a mantenere la loro rilevanza in tali situazioni, poiché non sono in grado di "ricordare" o accedere alle parti precedenti della conversazione una volta superata la finestra contestuale.
Per ovviare a queste limitazioni e consentire agli LLM di gestire interazioni più lunghe e complesse, utilizziamo una tecnica nota come cognizione della memoria. Questa tecnica amplia le capacità degli LLM introducendo meccanismi che consentono al modello di conservare, richiamare e integrare dinamicamente interazioni o informazioni passate, anche quando tali interazioni non rientrano nella finestra del contesto immediato.
Componenti della cognizione della memoria nelle applicazioni di IA generativa
Per implementare con successo la cognizione della memoria nelle applicazioni di Intelligenza Artificiale Generativa (GenAI), è necessario un approccio completo e strutturato. Ciò comporta l'integrazione di vari componenti di memoria che lavorano insieme per consentire al sistema di IA di conservare, recuperare e utilizzare le informazioni rilevanti in diverse interazioni. La cognizione della memoria consente al modello di IA di andare oltre l'elaborazione stateless e a breve termine, creando un sistema più consapevole del contesto, adattivo e intelligente, in grado di interagire e prendere decisioni a lungo termine. Ecco i componenti chiave della cognizione della memoria che devono essere presi in considerazione quando si sviluppa un'applicazione GenAI:
- Memoria a breve termine (memoria di sessione)
La memoria a breve termine, comunemente denominata memoria di sessione, comprende la capacità del modello di conservare il contesto e le informazioni durante una singola interazione o sessione. Questa componente è fondamentale per mantenere la coerenza nelle conversazioni a più turni e nelle attività a breve termine. Consente al modello di mantenere la continuità nelle sue risposte facendo riferimento alle parti precedenti della conversazione, evitando così all'utente di ripetere le informazioni fornite in precedenza.
In genere, la memoria a breve termine è limitata alla durata dell'interazione. Una volta conclusa la sessione o iniziata una nuova sessione, la memoria viene resettata o gradualmente cancellata. Ciò garantisce che il modello possa richiamare i dettagli rilevanti della stessa sessione, creando un'esperienza di conversazione più fluida e senza interruzioni. Ad esempio, in un chatbot di assistenza clienti, la memoria a breve termine consente all'IA di ricordare il problema di un cliente durante tutta la conversazione, garantendo che il problema venga affrontato in modo coerente senza che l'utente debba ripeterlo più volte.
Tuttavia, nei modelli linguistici di grandi dimensioni, la memoria a breve termine è spesso limitata dalla finestra di contesto del modello, che è vincolata dal numero massimo di token che può elaborare in un singolo prompt. Man mano che vengono aggiunti nuovi input durante la conversazione, le parti di dialogo più vecchie possono essere scartate o dimenticate, a seconda del limite di token. Ciò richiede un'attenta gestione della memoria a breve termine per garantire che le informazioni critiche vengano conservate per tutta la durata della sessione. - Memoria a lungo termine
La memoria a lungo termine migliora significativamente le capacità del modello consentendogli di conservare informazioni oltre l'ambito di una singola sessione. A differenza della memoria a breve termine, che è limitata a una singola interazione, la memoria a lungo termine persiste attraverso più interazioni, consentendo all'IA di richiamare informazioni importanti sugli utenti, le loro preferenze, le conversazioni passate o i dettagli specifici delle attività, indipendentemente dal tempo trascorso tra le sessioni. Questo tipo di memoria è tipicamente archiviato in un database esterno o in un repository di conoscenze, garantendo che rimanga accessibile nel tempo e non scada al termine di una sessione.
La memoria a lungo termine è particolarmente preziosa nelle applicazioni che richiedono la conservazione di informazioni critiche o personalizzate, come le preferenze degli utenti, la cronologia o le attività ricorrenti. Consente interazioni altamente personalizzate, poiché l'IA può fare riferimento alle informazioni memorizzate per adattare le sue risposte in base alle precedenti interazioni dell'utente. Ad esempio, nelle applicazioni di assistente virtuale, la memoria a lungo termine consente all'IA di ricordare le preferenze di un utente, come la sua musica preferita o gli orari regolari degli appuntamenti, e di utilizzare queste informazioni per fornire risposte e consigli personalizzati.
Negli ambienti aziendali, come i sistemi di assistenza clienti, la memoria a lungo termine consente all'IA di fare riferimento a problemi o richieste precedenti dello stesso utente, permettendole di offrire un'assistenza più informata e personalizzata. Questa capacità migliora l'esperienza dell'utente riducendo la necessità di ripetizioni e migliorando l'efficienza e l'efficacia complessive dell'interazione. La memoria a lungo termine, quindi, svolge un ruolo cruciale nel consentire ai sistemi di IA di fornire risposte coerenti, contestualizzate e personalizzate in più sessioni. - Gestione della memoria
La gestione dinamica della memoria si riferisce alla capacità del modello di IA di gestire e dare priorità in modo intelligente alle informazioni memorizzate, regolando continuamente ciò che viene conservato, scartato o recuperato in base alla sua rilevanza per l'attività da svolgere. Questa capacità è fondamentale per ottimizzare l'utilizzo della memoria sia a breve che a lungo termine, garantendo che il modello rimanga reattivo ed efficiente senza essere appesantito da informazioni irrilevanti o obsolete. Una gestione dinamica della memoria efficace consente al sistema di IA di adattare l'allocazione della memoria in tempo reale, in base alle esigenze immediate della conversazione o dell'attività.
In termini pratici, la gestione dinamica della memoria consente all'IA di dare priorità alle informazioni importanti, come fatti chiave, preferenze dell'utente o dati contestualmente critici, scartando o declassando i dettagli banali o obsoleti. Ad esempio, durante una conversazione in corso, il sistema può concentrarsi sulla conservazione delle informazioni essenziali che vengono frequentemente consultate o che sono altamente rilevanti per la query corrente dell'utente, consentendo al contempo che le informazioni meno pertinenti decadano o vengano rimosse. Questo processo garantisce che l'IA possa mantenere una chiara attenzione su ciò che conta di più, migliorando sia l'accuratezza che l'efficienza.
Per facilitare questo processo, il sistema utilizza spesso meccanismi di valutazione della rilevanza per valutare e classificare l'importanza dei ricordi memorizzati. A ogni elemento di memoria può essere assegnato un punteggio di priorità in base a fattori quali la frequenza con cui viene consultato o la sua importanza per l'attività corrente. I ricordi con priorità più alta vengono conservati per periodi più lunghi, mentre quelli con priorità più bassa o obsoleti possono essere contrassegnati per la rimozione. Questo sistema di punteggio aiuta a prevenire il sovraccarico di memoria, garantendo che solo le informazioni più pertinenti vengano conservate nel tempo.
La gestione dinamica della memoria include anche meccanismi di decadimento della memoria, in cui le informazioni più vecchie o meno rilevanti "svaniscono" gradualmente o vengono automaticamente rimosse dalla memoria, evitando il sovraccarico della memoria. Ciò garantisce che l'IA conservi solo i dati più critici, evitando inefficienze e assicurando prestazioni ottimali, soprattutto in applicazioni su larga scala che coinvolgono quantità significative di dati o operazioni che richiedono molta memoria.
Per ottimizzare ulteriormente l'utilizzo delle risorse, è possibile implementare processi automatizzati per "dimenticare" le voci di memoria che non sono state referenziate per un periodo di tempo significativo o che non sono più rilevanti per le attività in corso. Questi processi garantiscono che le risorse di memoria, come lo spazio di archiviazione e la potenza di elaborazione, siano allocate in modo efficiente, in particolare in ambienti con requisiti di memoria su larga scala. Gestendo dinamicamente la memoria, l'IA può continuare a fornire risposte contestualmente accurate e tempestive, mantenendo al contempo un sistema di memoria equilibrato ed efficiente.
Implementazione della cognizione della memoria in Snaplogic
SnapLogic offre solide funzionalità di integrazione con database e sistemi di archiviazione, rendendolo una piattaforma ideale per la creazione di flussi di lavoro per la gestione della cognizione della memoria nelle applicazioni di intelligenza artificiale. Nell'esempio seguente, illustriamo un modello di cognizione della memoria di base che utilizza SnapLogic per gestire sia la memoria a breve che quella a lungo termine.
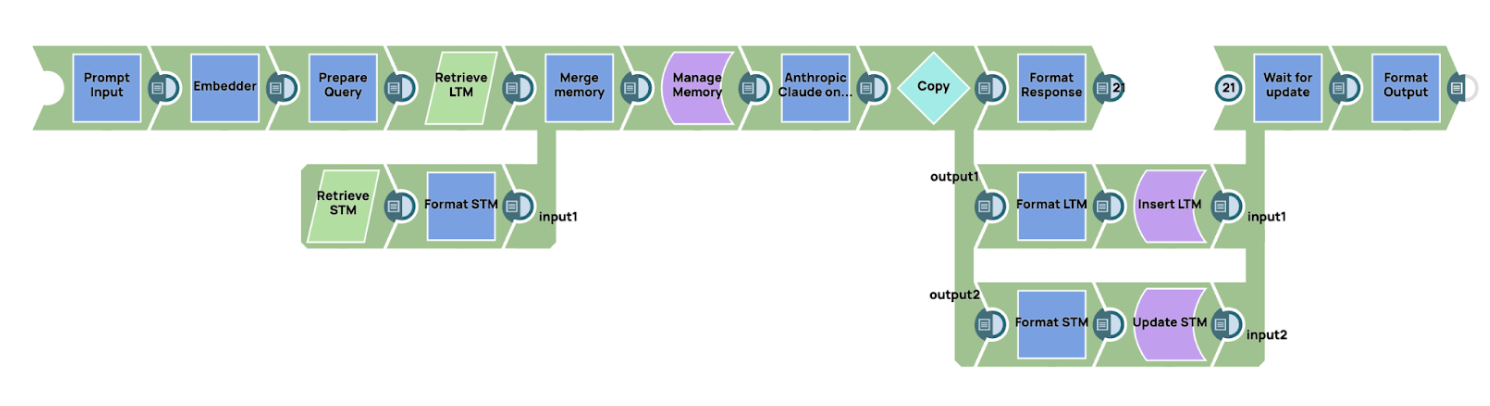
Panoramica del flusso di lavoro
Il flusso di lavoro inizia incorporando il prompt in una rappresentazione vettoriale. Questo vettore viene quindi utilizzato per recuperare i ricordi rilevanti dalla memoria a lungo termine. La memoria a lungo termine può essere archiviata in un database vettoriale, particolarmente adatto per il recupero basato sulla somiglianza, oppure in un database tradizionale o in un archivio chiave-valore, a seconda dei requisiti dell'applicazione. Allo stesso modo, la memoria a breve termine può essere archiviata in un database regolare o in un archivio chiave-valore per tenere traccia delle interazioni recenti.
- Recupero dei ricordi
Una volta incorporato il prompt, recuperiamo le informazioni rilevanti dai sistemi di memoria a breve e lungo termine. Il processo di recupero si basa su un punteggio di similarità, in cui il punteggio di similarità indica la rilevanza della memoria archiviata rispetto al prompt corrente. Per la memoria a lungo termine, ciò comporta in genere l'interrogazione di un database vettoriale, mentre la memoria a breve termine può essere recuperata da un database relazionale tradizionale o da un archivio chiave-valore. Dopo aver recuperato i ricordi rilevanti da entrambi i sistemi, i dati vengono inseriti in un modulo di gestione della memoria. In questo esempio, implementiamo un semplice meccanismo di gestione della memoria utilizzando uno script all'interno di SnapLogic. - Gestione della memoria
Il modulo di gestione della memoria utilizza una tecnica a finestra scorrevole, che è un modo semplice ma efficace per gestire la memoria. Man mano che viene aggiunta nuova memoria, quella più vecchia viene gradualmente eliminata fino a scomparire dallo stack di memoria. Ciò garantisce che l'IA conservi le informazioni più recenti e rilevanti, scartando quelle obsolete o meno utili. Il meccanismo a finestra scorrevole dà la priorità alle memorie più recenti o più rilevanti, posizionandole nella parte superiore dello stack di memoria, mentre quelle più vecchie vengono eliminate nel tempo. - Generazione del prompt finale e interazione con l'LLM
Una volta che il modulo di gestione della memoria ha costruito il contesto completo combinando la memoria a breve e a lungo termine, il sistema genera il prompt finale. Questo prompt viene quindi inviato al modello linguistico per l'elaborazione. In questo caso, utilizziamo AWS Claude tramite l'API Message come modello linguistico di grandi dimensioni (LLM) per generare una risposta basata sul contesto fornito. - Aggiornamento della memoria
Una volta ricevuta la risposta dall'LLM, il flusso di lavoro procede all'aggiornamento dei sistemi di memoria a breve e lungo termine per garantire continuità e pertinenza nelle interazioni future:- Memoria a lungo termine: la memoria a lungo termine viene aggiornata associando il prompt originale alla risposta dell'LLM. In questo contesto, la chiave di query corrisponde al prompt iniziale, mentre il valore è la risposta generata dal modello. Questo aggiornamento consente al sistema di memorizzare conoscenze pertinenti a cui è possibile accedere durante le interazioni future, consentendo risposte più informate e contestualizzate nel tempo.
- Memoria a breve termine: la memoria a breve termine viene aggiornata aggiungendo la risposta dell'LLM allo stack di memoria più recente. Questo processo garantisce il mantenimento del contesto immediato della conversazione corrente, consentendo transizioni fluide e coerenza nelle interazioni successive all'interno della sessione.
Questo esempio dimostra come SnapLogic possa essere utilizzato efficacemente per gestire la cognizione della memoria nelle applicazioni di IA. Integrando i database e sfruttando la potente automazione del flusso di lavoro di SnapLogic, è possibile creare un sistema di gestione della memoria intelligente in grado di gestire sia la memoria a breve che quella a lungo termine. Il meccanismo della finestra scorrevole garantisce che l'IA rimanga consapevole del contesto evitando il sovraccarico di memoria, mentre AWS Claude fornisce la potenza di elaborazione necessaria per generare risposte basate su una ricca comprensione contestuale. Questo approccio offre una soluzione scalabile e flessibile per la gestione della cognizione della memoria nei flussi di lavoro basati sull'IA.






