






Dans mon précédent article de blog, j‘ai décrit le processus et les étapes suivis par SnapLogic pour devenir axé sur les données en construisant un lac de données interne cloud .
Dans cet article de blog, je partagerai les meilleures pratiques pour créer une architecture de lac de données, les outils nécessaires pour construire un lac de données complet et les enseignements que nous avons tirés de la construction de notre propre lac de données.
Le processus de création d‘une base de données d‘entreprise cloud
Il est impératif pour les organisations de comprendre leurs besoins actuels et futurs afin de trouver la bonne solution de lac de données et de suivre le bon processus de construction de lac de données. Chez SnapLogic, nous avons passé près de quatre mois à construire notre solution de lac de données cloud en nous basant sur les considérations suivantes :
- Se concentrer sur les capacités d‘interrogation et non sur le stockage des données. L‘une des principales raisons pour lesquelles les lacs de données échouent est qu‘ils accordent trop d‘importance au stockage et pas assez aux capacités d‘interrogation.
- Appliquer une approche "axée sur les requêtes". Nous avons construit des modèles basés sur ce que nous devions interroger à partir des sources initiales identifiées et nous avons éliminé le problème de la recherche d‘une aiguille dans une botte de foin.
- Identifier les personas qui utiliseront le lac de données et connaître le type de données qu‘ils recherchent. Les requêtes ne sont pas génériques ; il existe différents personas et elles doivent être complétées par différents modèles de données.
Vous trouverez ci-dessous un aperçu du processus de construction du lac de données, y compris les étapes que nous avons suivies pour interroger ce lac de données afin de générer des mesures commerciales importantes, de sorte que les différentes équipes puissent prendre des mesures pertinentes.
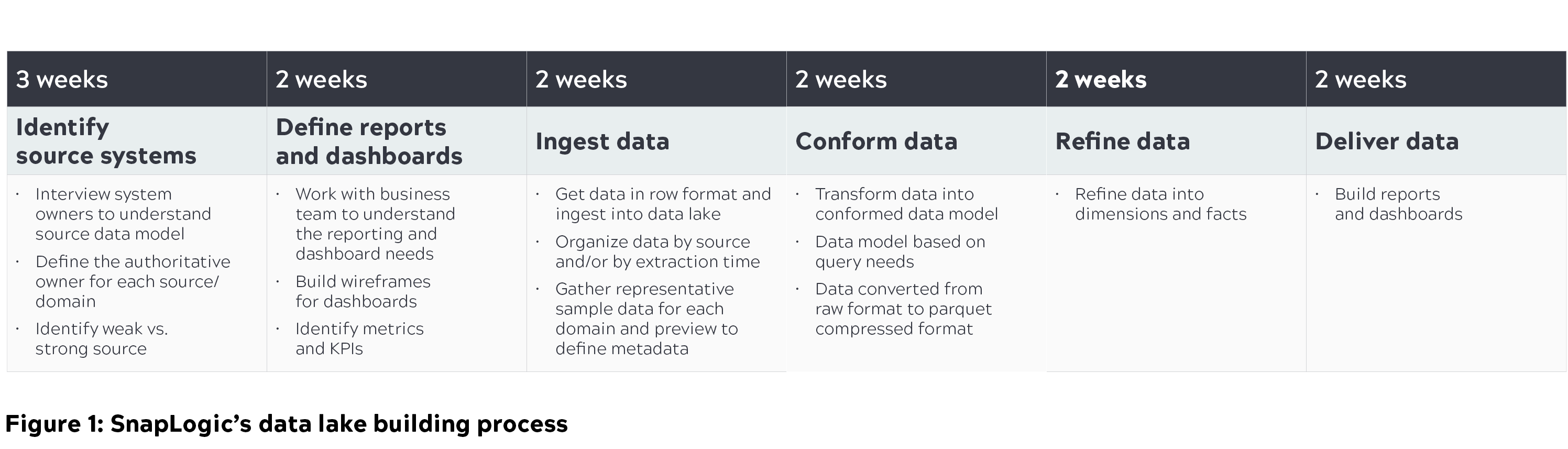
Cloud architecture du lac de données
Une architecture modulaire, évolutive et sécurisée avec des performances élevées est essentielle pour construire et maintenir un lac de données dans une organisation. Chez SnapLogic, nous avons eu plusieurs discussions d‘architecture sur la façon de construire et de faire évoluer les lacs de données. Le diagramme ci-dessous explique l‘architecture de base et notre processus de réflexion sur la façon dont nous envisageons un lac de données cloud évolutif.
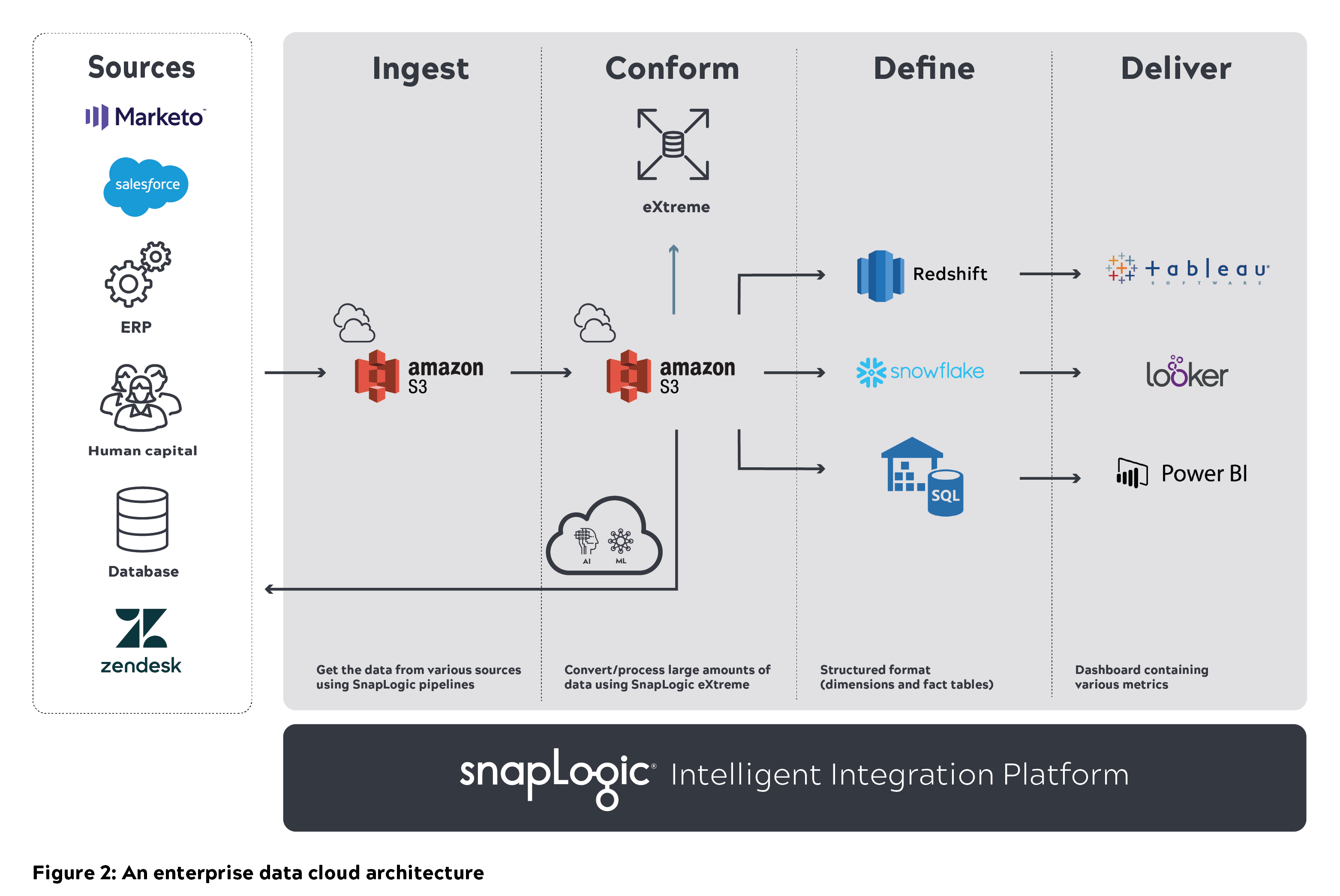
Une architecture générique de lac de données cloud se compose de diverses sources de données sur la gauche. Les données brutes provenant de ces systèmes et applications sont introduites dans un lac de données (par exemple, Amazon S3). Ces données doivent être nettoyées et conformées pour que les utilisateurs puissent les interroger directement. Les données traitées sont ensuite stockées dans un entrepôt de données cloud (par exemple, Amazon Redshift, Snowflake ou Azure SQL) qui peut également être interrogé. L‘ensemble de données affinées peut ensuite être intégré dans des outils de BI tels que Tableau, Looker ou Power BI.
Outils utilisés pour construire le lac de données de SnapLogic:
- Amazon S3 pour stocker toutes les données brutes
- SnapLogic Intelligent Integration Platform (IIP) pour l‘intégration et le traitement des données
- Entrepôt de données Snowflake pour stocker l‘ensemble de données affinées
- Tableau pour les rapports
Infrastructure et autorisations des utilisateurs :
- Donner l‘accès approprié aux utilisateurs pour construire la logique commerciale et exécuter les pipelines.
- Donner aux utilisateurs l‘accès aux rôles IAM pour le(s) environnement(s) AWS et l‘accès basé sur les rôles pour les autres environnements à mettre en œuvre.
Données d‘entreprise SnapLogic cloud architecture
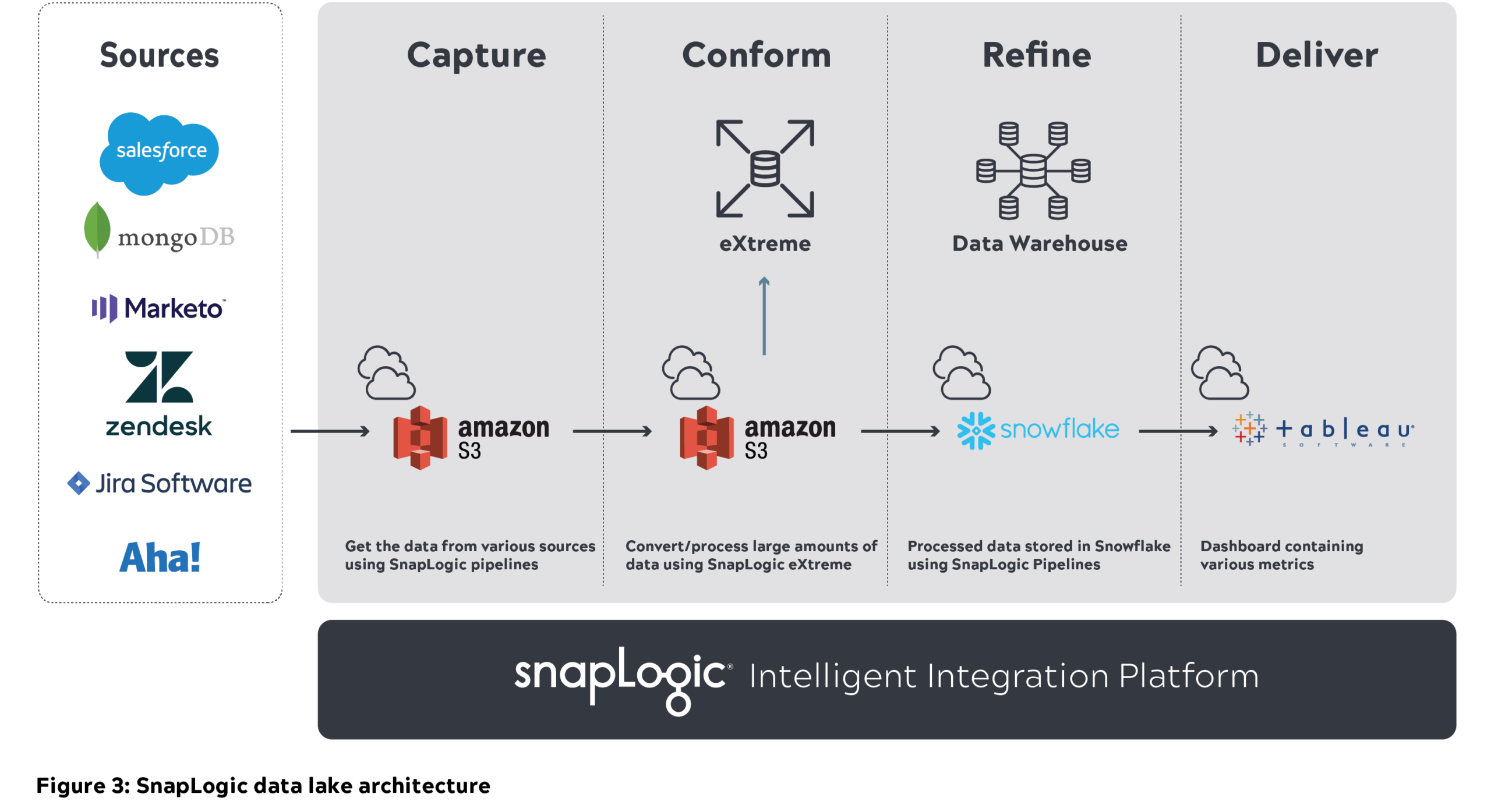
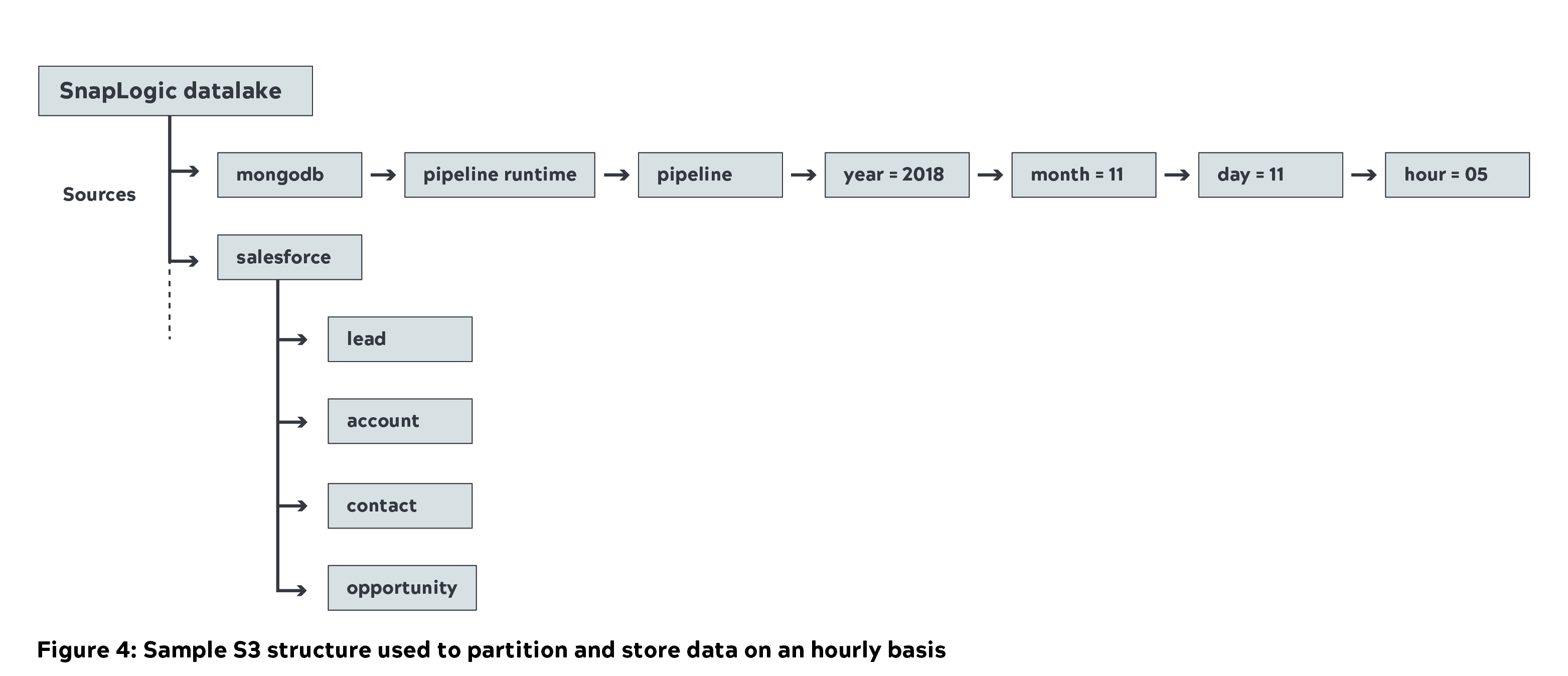
- Nous avons utilisé l‘intégration unifiée de SnapLogic plateforme pour déplacer près d‘un pétaoctet (non compressé) de métadonnées provenant de diverses sources internes vers le lac de données Amazon S3 (couche de capture). Vous trouverez ci-dessous l‘exemple de structure S3 que nous utilisons chez SnapLogic, où les données sources sont partitionnées et stockées toutes les heures.
- Le nettoyage est une étape intermédiaire après l‘ingestion des données. Il s‘agit de supprimer les doublons et les données corrompues. Les pipelines SnapLogic ont permis de supprimer ces doublons.
- Nous avons ensuite utilisé Big Data Snaps pour convertir les données brutes en un format parquet compressé dans le cadre de la couche conforme (une compression de 70 % a été réalisée). Voici un exemple de couche conforme S3 et de structure S3

- Il n‘est pas facile d‘interroger les données brutes et d‘identifier l‘ensemble de données pertinent pour les mesures commerciales. Nous avons utilisé le catalogue de données de SnapLogic pour y parvenir et pour interroger les métadonnées.
- Nous avons également offert aux utilisateurs la possibilité d‘interroger l‘ensemble des données conformes à l‘aide d‘Amazon Athena.
- SnapLogic eXtreme est utilisé pour traiter les données volumineuses sur le site cloud et en déduire des mesures (exécution du pipeline/Snap et nombre de documents) sous la forme d‘une table de faits. Le cluster est porté à 21 nœuds (m4.16x grand) pour traiter la charge de travail.
- Snowflake a été utilisé pour stocker le schéma en étoile (dimensions et tables de faits) dans le cadre de la couche d‘affinage. Nous avons utilisé une petite instance pour charger les données et une instance moyenne pour les interroger.
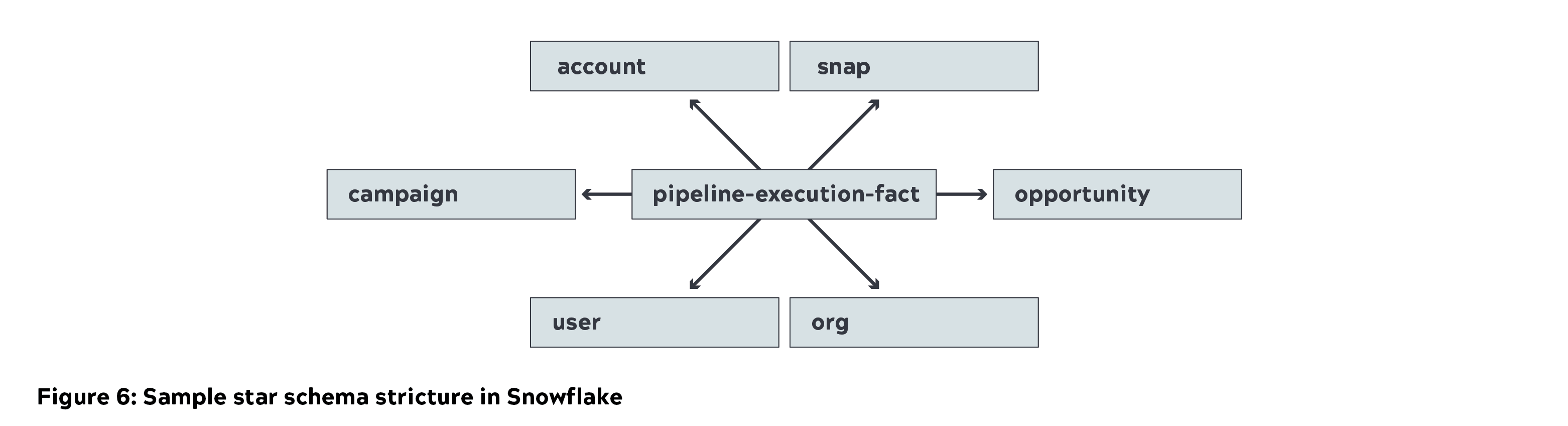
- Tableau a été utilisé pour capturer et visualiser les mesures de l‘entreprise. Les données ont été mises en cache dans Tableau pour générer des mesures commerciales importantes. Des rapports détaillés ont été générés en interrogeant directement Snowflake.
Audit
Les données reçues dans S3 (lac de données) doivent être cohérentes par rapport aux données sources. Cet audit doit être effectué régulièrement pour s‘assurer qu‘il n‘y a pas de valeurs manquantes ou de doublons.
- Nous avons construit un pipeline automatisé pour valider les données sources par rapport aux données stockées dans le lac de données (ingérer, conformer et affiner).
- Un tableau de bord Tableau a été conçu pour surveiller et auditer la charge en temps quasi réel par rapport aux données stockées dans le lac de données.
- Chaque fois que des données dupliquées ou corrompues ont été trouvées, nous avons alerté l‘équipe pour qu‘elle les corrige.
Défis et enseignements
L‘obtention de données à partir de diverses sources - en particulier les métadonnées liées à la production - a été l‘un des plus grands défis que nous ayons rencontrés en raison du volume et de la complexité des données. De plus, rendre les données disponibles en temps quasi réel pour l‘analyse était un défi de taille. L‘équipe d‘ingénieurs de SnapLogic a été en mesure de réaliser cet énorme exploit et de nous fournir des métadonnées liées à la production en temps quasi réel.
La compréhension des données a demandé du temps et des efforts, y compris l‘intégration des ensembles de données pertinents pour les mesures commerciales. Une partie des données sources était corrompue et nous avons dû développer une logique de pipeline pour l‘exclure. Nous avons également observé des identifiants de pipeline en double dans la source, ce qui a nécessité un nettoyage supplémentaire dans la couche conforme.
Il est important de modéliser correctement les données et de les concevoir efficacement en fonction de la manière dont l‘utilisateur souhaite interroger les données. Il faut en tenir compte et créer les tables appropriées dans Snowflake.
L‘exercice de dimensionnement doit être soigneusement planifié et exécuté. Il s‘agit notamment de
- Les nœuds SnapLogic pour traiter des ensembles de données volumineux (mémoire et CPU intensifs au départ).
- Traitement des Big Data sur cloud par SnapLogic eXtreme, nécessitant des instances EC2 à forte intensité de mémoire et de CPU. Cela peut également varier en fonction du cas d‘utilisation et de la taille des données.
- Allocation correcte de calcul et de stockage Snowflake. L‘ingestion de données nécessitera initialement une instance de calcul élevée, de taille moyenne à grande.
- Les données Tableau sont mises en cache pour les mesures importantes de l‘entreprise (tableau de bord exécutif et rapports de synthèse). Les rapports détaillés peuvent être consultés directement sur Snowflake.
En l‘espace de quelques mois, nous avons pu construire un lac de données grâce à une planification et une exécution minutieuses en utilisant des plateformes clés telles que AWS, SnapLogic, Snowflake et Tableau. Et nous sommes ravis de partager avec d‘autres organisations notre expérience en matière de lac de données. Pour en savoir plus, lisez notre livre blanc intitulé "Easing the pain of big data : modern enterprise data architecture".







