






In my previous blog post, I covered the process and steps SnapLogic followed to become data-driven by building an in-house cloud data lake.
In this blog post, I will share best practices on creating a data lake architecture, tools required to build a comprehensive data lake, and our learnings from building our very own data lake.
The process of building an enterprise data cloud
It is imperative for organizations to understand their current and future needs in order to find the right data lake solution and follow the right data lake building process. At SnapLogic, we spent nearly four months building our cloud data lake solution based on the following considerations:
- Focus on query capabilities and not data storage. One of the main reasons why data lakes fail is because they over-prioritize on storage and not enough on query capabilities.
- Enforce a “query-driven” approach. We built models based on what we needed to query from the initial sources identified and eliminated the problem of looking for a needle in a haystack.
- Identify the personas who will use the data lake and know the type of data they look for. Queries are not generic; there are different personas, and they should be complemented by different data models.
Below is an overview of the data lake building process, including the steps we took to query this data lake to generate important business metrics, so various teams can take relevant actions.
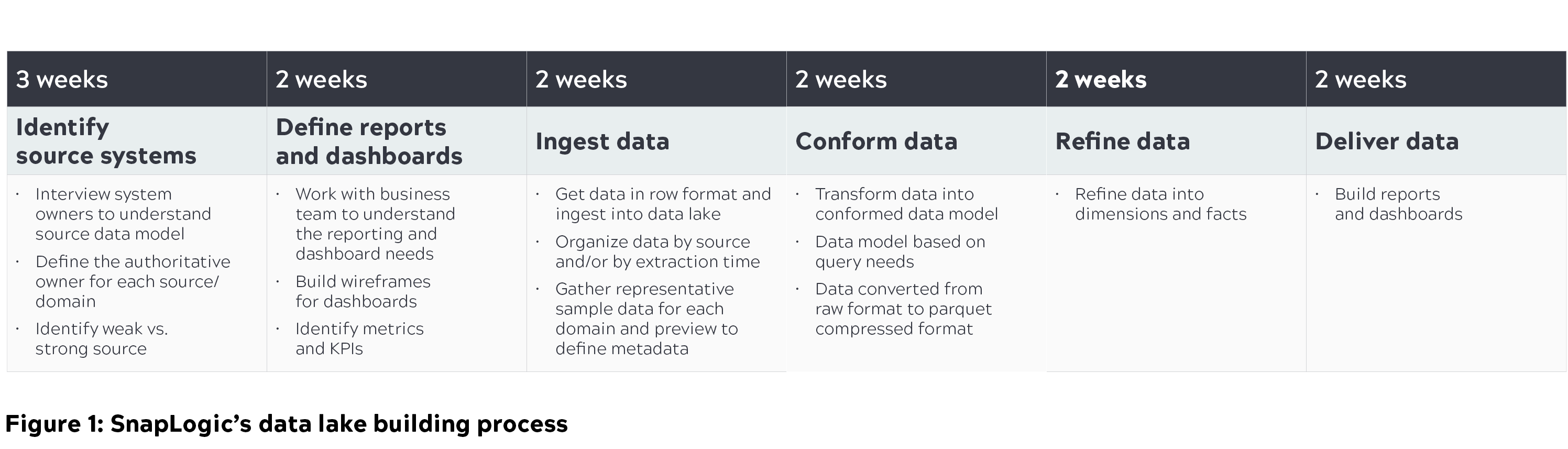
Cloud data lake architecture
A modular, scalable, and secure architecture with high performance is key for building and maintaining a data lake in an organization. At SnapLogic, we had various architecture discussions on how to build and scale data lakes. The diagram below explains the baseline architecture and our thought process on how we envisioned a cloud data lake that can scale.
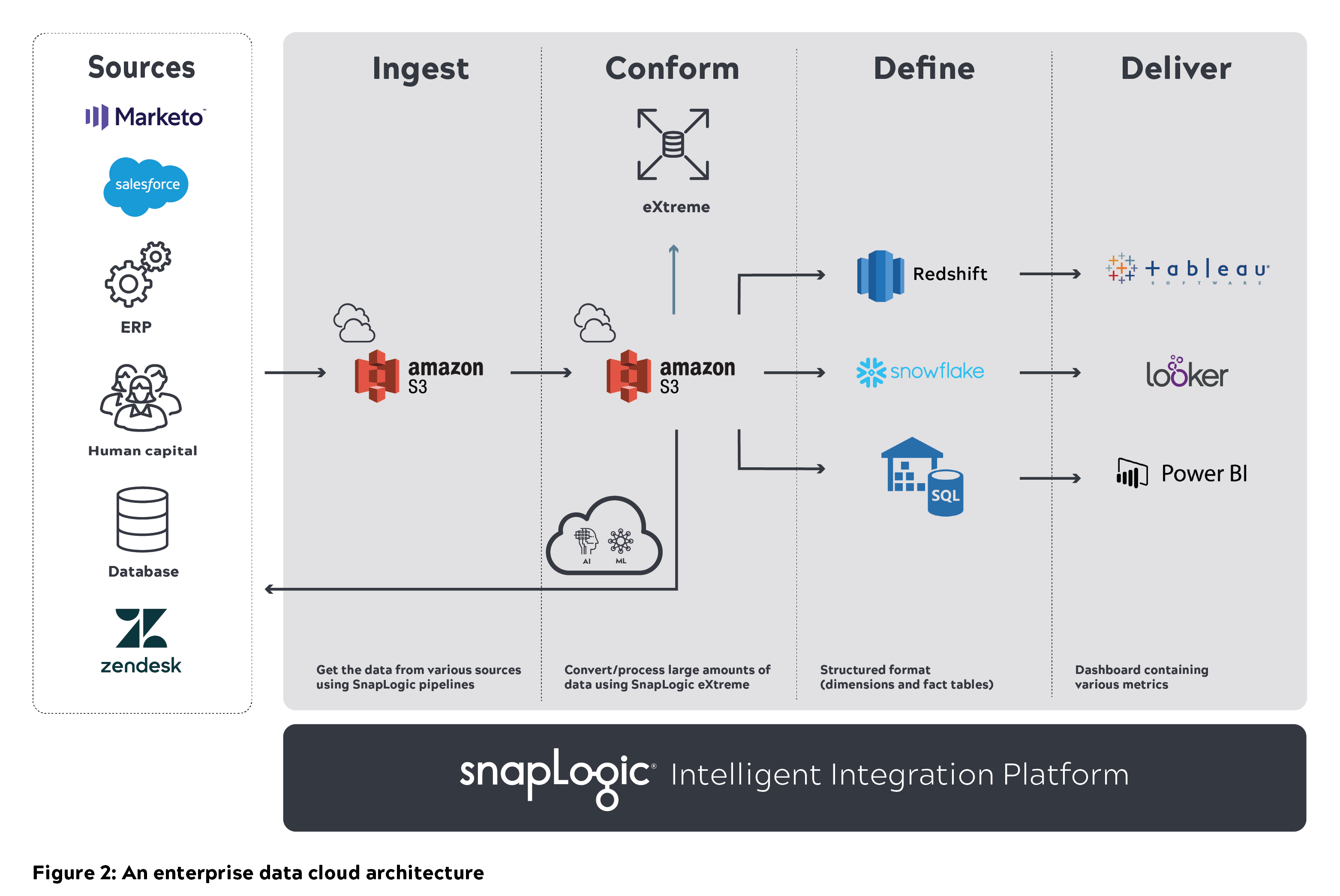
A generic cloud data lake architecture consists of various data sources on the left. The raw data from these systems and applications get ingested into a data lake (e.g., Amazon S3). This data needs to be cleansed and conformed so users can query directly. The processed data is later stored in a cloud data warehouse (e.g., Amazon Redshift, Snowflake, or Azure SQL data warehouse) that can also be queried. The refined data set can later be populated to BI tools such as Tableau, Looker, or Power BI.
Tools used to build SnapLogic’s data lake:
- Amazon S3 to store all the raw data
- SnapLogic Intelligent Integration Platform (IIP) for data integration and processing
- Snowflake data warehouse to store the refined data set
- Tableau for reporting
Infrastructure and user authorizations:
- Give proper access to users to build business logic and execute pipelines
- Give users access to IAM roles for AWS environment(s) and role-based access for other environments to be implemented
SnapLogic enterprise data cloud architecture
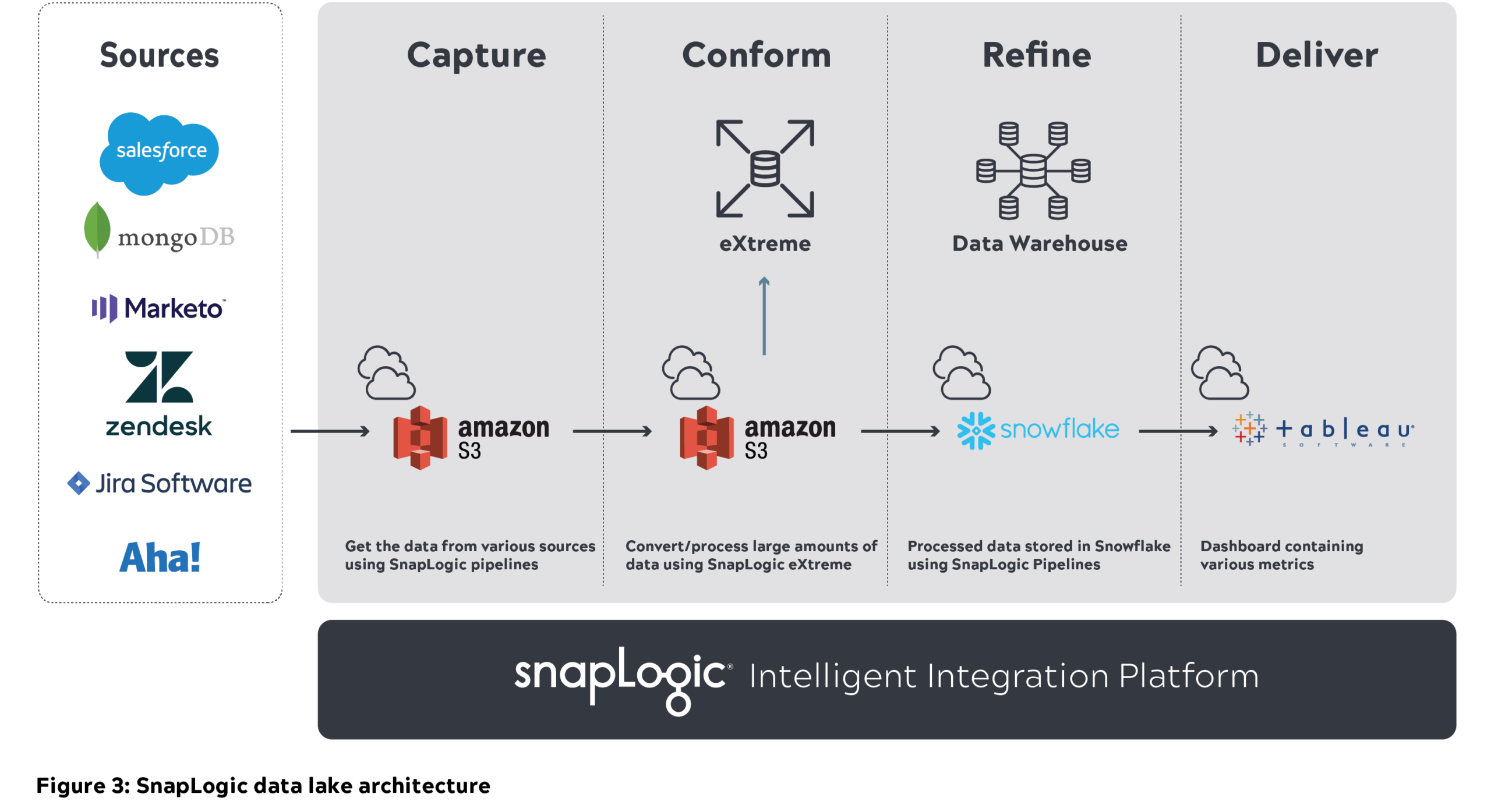
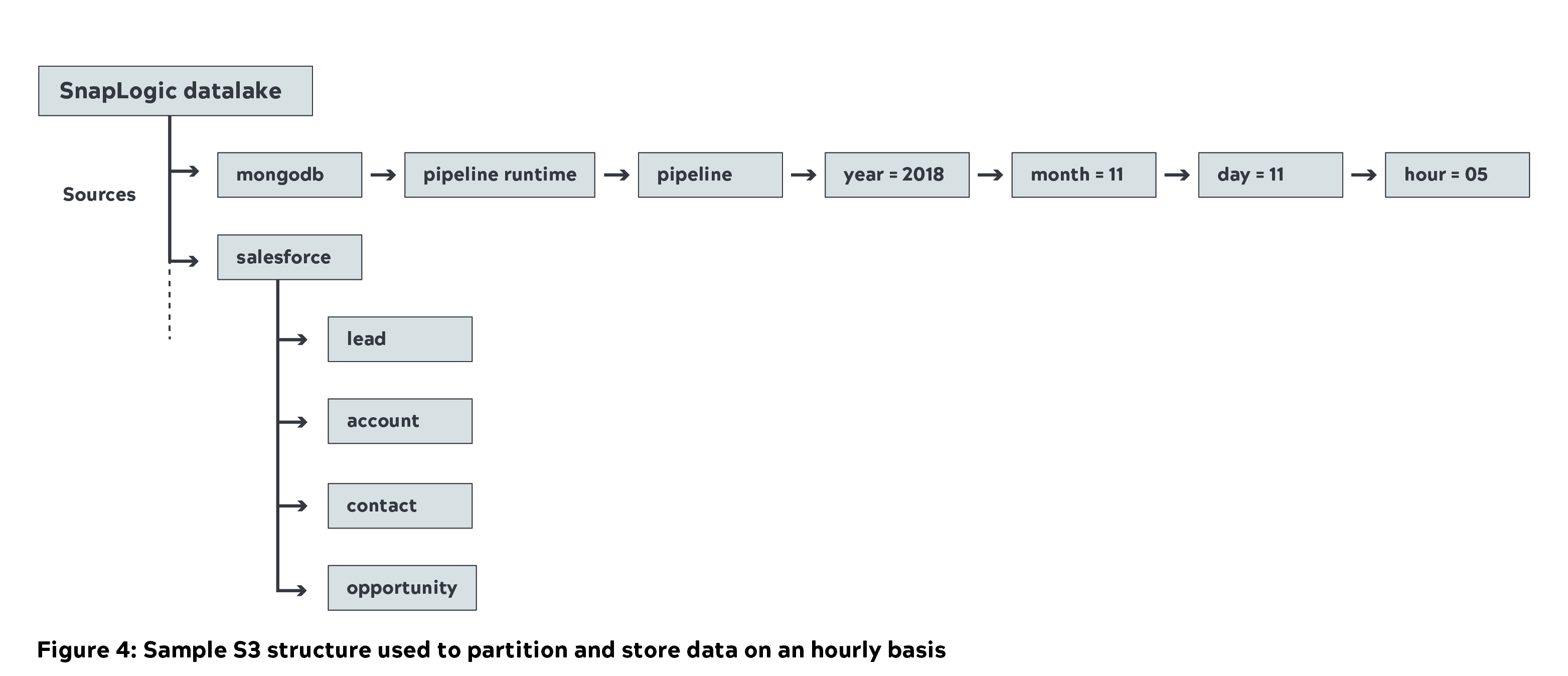
- We used SnapLogic’s unified integration platform to move nearly 1 Petabyte (uncompressed) of metadata from various internal sources into the Amazon S3 data lake (capture layer). Below is the sample S3 structure we use at SnapLogic where the source data is partitioned and stored on an hourly basis.
- Cleansing is an intermediate step once data ingestion happens. This involves removing duplicate and corrupt data. SnapLogic pipelines helped remove these duplicate pipeline IDs
- We later used Big Data Snaps to convert the raw data into a compressed parquet format as part of the conform layer (70 percent compression was achieved). Below is the sample S3 conformed layer and S3 structure

- Querying raw data and identifying the relevant data set for business metrics is not easy. We used SnapLogic’s Data Catalog to achieve this and also to query the metadata.
- We have also provided flexibility for users to query the conformed data set using Amazon Athena.
- SnapLogic eXtreme is used to process big data in the cloud and derive metrics (pipeline/Snap execution and document count) in the form of a fact table. The cluster is scaled up to 21 nodes (m4.16x large) to process the workload.
- Snowflake was utilized to store star schema (dimensions and fact tables) as part of the refine layer. We used a small instance to load data and medium instance to query.
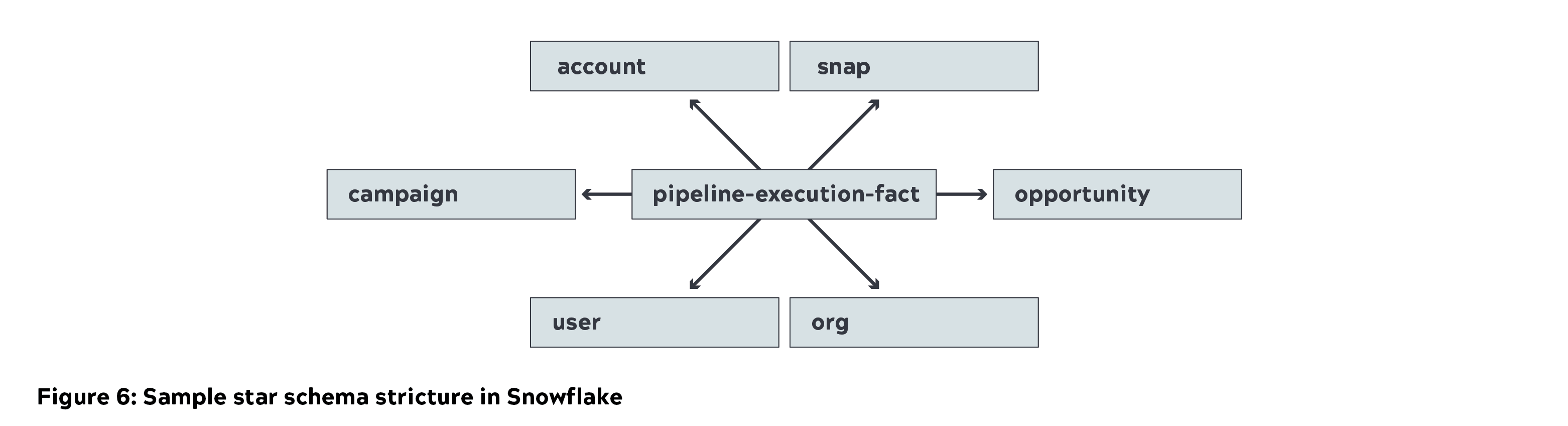
- Tableau was used for capturing and visualizing business metrics. The data was cached inside Tableau for generating important business metrics. Detailed reports were generated by directly querying Snowflake.
Audit
The data received in S3 (data lake) should be consistent compared to the source data. This required audit must be done on a regular basis to make sure there are no missing values or duplicates.
- We built an automated pipeline to validate the source data against the data stored in the data lake (ingest, conform, and refine).
- A Tableau dashboard was designed to monitor and audit near real-time load against the data stored in the data lake.
- Whenever duplicate or corrupt data was found, we alerted the team to fix it.
Challenges and learnings
Getting data from various sources – specifically, production-related metadata – was one of the biggest challenges we encountered due to the volume and complexity of the data. In addition, making the data available near real-time for analytics was an uphill challenge. The SnapLogic Engineering team was able to achieve this humongous feat and provided us near real-time production-related metadata.
Understanding the data required time and effort, including bringing in the relevant data sets for business metrics. A portion of the source data was corrupted, and we had to build pipeline logic to exclude it. We also observed duplicate pipeline IDs in the source and required additional cleanup in the conform layer.
Proper modeling of data is important with efficient design based on how the user would like to query the data. This needs to be factored in, and appropriate tables must be created in Snowflake.
Sizing exercise needs to be carefully planned and executed. This includes:
- SnapLogic nodes to process large data set (high-intensive memory and CPU initially).
- Big data processing in the cloud by SnapLogic eXtreme requiring high memory and CPU-intensive EC2 instances. This can also vary based on the use case and data size.
- Proper Snowflake compute and storage allocation. Data ingestion will initially require high compute medium-to-large instance.
- Tableau data to be cached for important business metrics (executive dashboard and summary level reports). Detailed report can be queried directly on Snowflake.
Within a few short months, we were able to build a data lake with careful planning and execution using key platforms like AWS, SnapLogic, Snowflake, and Tableau. And we are excited to share with other organizations our data lake journey. To learn more, please read our white paper, “Easing the pain of big data: modern enterprise data architecture.”








